

โมเดลภาษาส่วนใหญ่มีสิ่งหนึ่งที่เหมือนกัน นั่นคือมีขนาดค่อนข้างใหญ่สำหรับทรัพยากรที่
โอนผ่านอินเทอร์เน็ต โมเดลการตรวจหาออบเจ็กต์ MediaPipe ที่เล็กที่สุด
(SSD MobileNetV2 float16) มีขนาด 5.6 MB
และโมเดลที่ใหญ่ที่สุดมีขนาดประมาณ 25 MB
โมเดลภาษาขนาดใหญ่ (LLM) แบบโอเพนซอร์ส
gemma-2b-it-gpu-int4.bin
มีขนาด 1.35 GB ซึ่งถือว่าเล็กมากสำหรับ LLM
โมเดล Generative AI อาจมีขนาดใหญ่มาก ด้วยเหตุนี้ การใช้งาน AI จำนวนมากในปัจจุบันจึงเกิดขึ้น
ในระบบคลาวด์ ปัจจุบันแอปต่างๆ เรียกใช้โมเดลที่มีการเพิ่มประสิทธิภาพสูงโดยตรงในอุปกรณ์มากขึ้นเรื่อยๆ
แม้ว่าจะมีการสาธิต LLM ที่ทำงานในเบราว์เซอร์
แต่ต่อไปนี้คือตัวอย่างระดับโปรดักชันของโมเดลอื่นๆ ที่ทำงานใน
เบราว์เซอร์
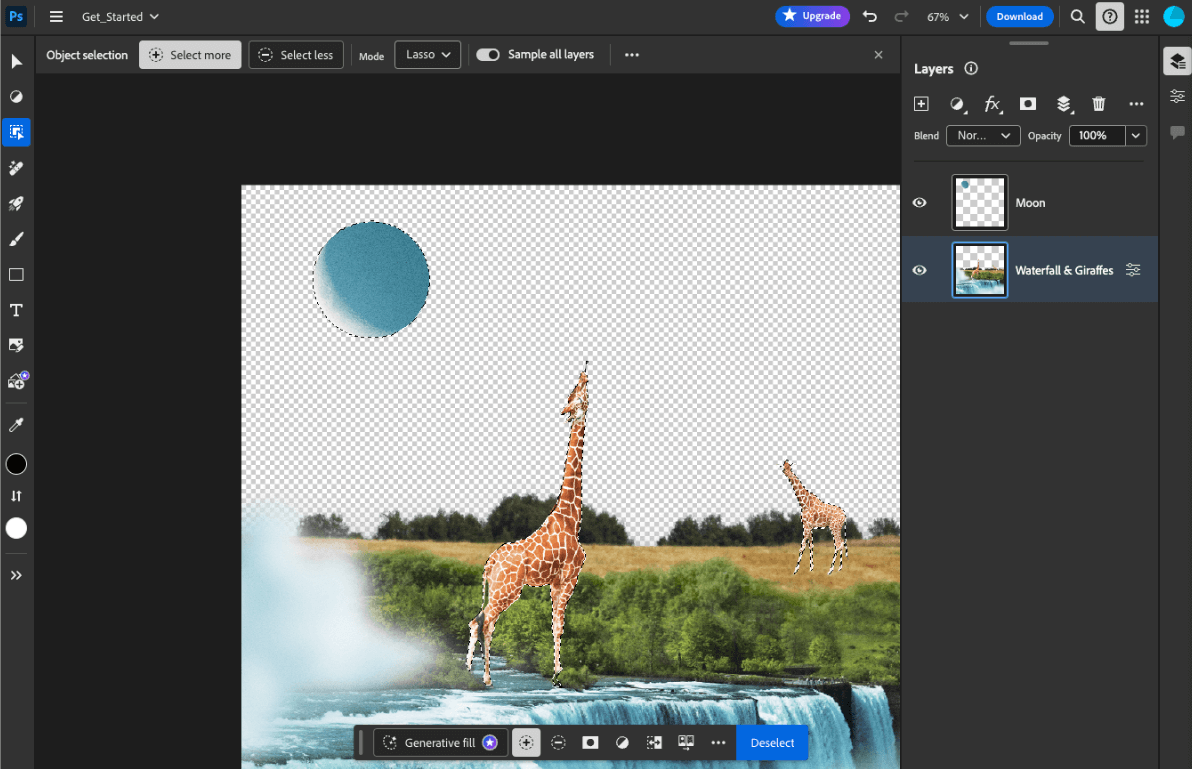
- Adobe Photoshop เรียกใช้โมเดล
Conv2Dเวอร์ชันหนึ่งในอุปกรณ์สำหรับเครื่องมือการเลือกออบเจ็กต์อัจฉริยะ - Google Meet ใช้
MobileNetV3-smallโมเดลเวอร์ชันที่ได้รับการเพิ่มประสิทธิภาพ สำหรับการแบ่งกลุ่มบุคคลสำหรับฟีเจอร์เบลอพื้นหลัง - Tokopedia ใช้โมเดล
MediaPipeFaceDetector-TFJSเพื่อตรวจจับใบหน้าแบบเรียลไทม์เพื่อป้องกันการลงชื่อสมัครใช้บริการที่ไม่ถูกต้อง - Google Colab ช่วยให้ผู้ใช้สามารถใช้โมเดลจากฮาร์ดดิสก์ ใน Colab Notebook ได้
หากต้องการให้การเปิดตัวแอปพลิเคชันในอนาคตเร็วขึ้น คุณควรแคชข้อมูลโมเดลในอุปกรณ์อย่างชัดเจนแทนที่จะพึ่งแคช HTTP ของเบราว์เซอร์โดยนัย
แม้ว่าคู่มือนี้จะใช้โมเดล gemma-2b-it-gpu-int4.bin ในการสร้างแชทบ็อต
แต่ก็สามารถนำแนวทางนี้ไปใช้กับโมเดลอื่นๆ และกรณีการใช้งานอื่นๆ
ในอุปกรณ์ได้ วิธีที่พบบ่อยที่สุดในการเชื่อมต่อแอปกับโมเดลคือการแสดงโมเดลควบคู่ไปกับทรัพยากรอื่นๆ ของแอป การเพิ่มประสิทธิภาพ
การแสดงผลเป็นสิ่งสำคัญ
กำหนดค่าส่วนหัวแคชที่เหมาะสม
หากคุณให้บริการโมเดล AI จากเซิร์ฟเวอร์ คุณต้องกำหนดค่าส่วนหัว Cache-Control
ที่ถูกต้อง ตัวอย่างต่อไปนี้แสดงการตั้งค่าเริ่มต้นที่มั่นคง ซึ่งคุณสามารถสร้าง
ต่อยอดให้เหมาะกับความต้องการของแอปได้
Cache-Control: public, max-age=31536000, immutable
โมเดล AI แต่ละเวอร์ชันที่เผยแพร่แล้วเป็นทรัพยากรแบบคงที่ เนื้อหาที่ไม่เคยเปลี่ยนแปลงควรมีmax-age
การล้างแคช
ใน URL ของคำขอ หากจำเป็นต้องอัปเดตรุ่น คุณต้องระบุ URL ใหม่
เมื่อผู้ใช้โหลดหน้าเว็บซ้ำ ไคลเอ็นต์จะส่งคำขอให้ตรวจสอบซ้ำ แม้ว่าเซิร์ฟเวอร์จะทราบว่าเนื้อหามีความเสถียรก็ตาม คำสั่ง
immutable
ระบุอย่างชัดเจนว่าไม่จำเป็นต้องตรวจสอบซ้ำ เนื่องจากเนื้อหาจะไม่เปลี่ยนแปลง เบราว์เซอร์และแคชตัวกลางหรือพร็อกซีเซิร์ฟเวอร์ไม่รองรับคำสั่ง immutable อย่างแพร่หลาย แต่การรวมคำสั่งนี้เข้ากับคำสั่ง max-age ที่เป็นที่เข้าใจกันโดยทั่วไปจะช่วยให้มั่นใจได้ถึงความเข้ากันได้สูงสุด คำสั่ง public
การตอบกลับระบุว่าสามารถจัดเก็บการตอบกลับไว้ในแคชที่แชร์ได้
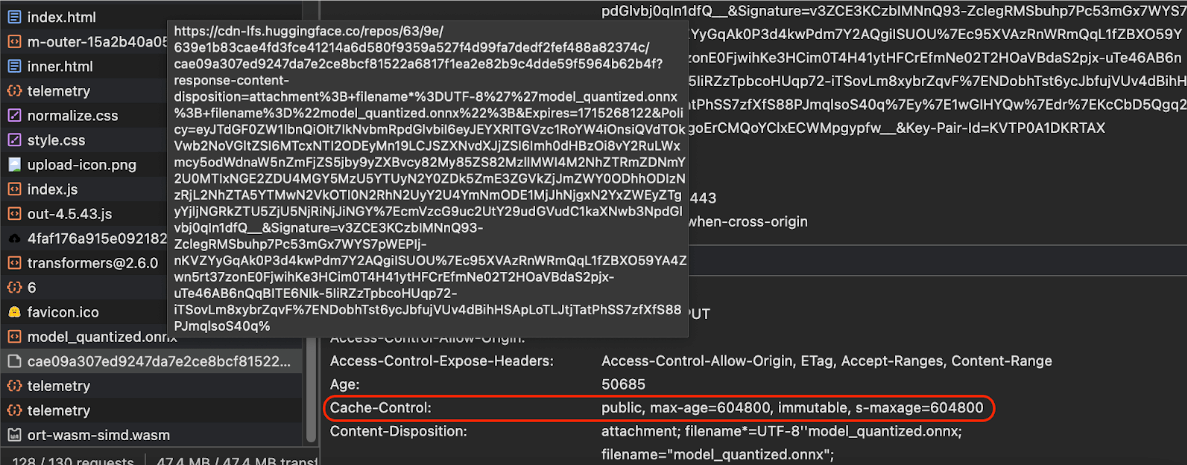
Cache-Control
ส่วนหัวของการผลิตที่ Hugging Face ส่งเมื่อขอโมเดล AI
(แหล่งที่มา)
แคชโมเดล AI ฝั่งไคลเอ็นต์
เมื่อแสดงโมเดล AI คุณควรแคชโมเดลอย่างชัดเจนในเบราว์เซอร์ ซึ่งจะช่วยให้มั่นใจได้ว่าข้อมูลโมเดลพร้อมใช้งานทันทีหลังจากที่ผู้ใช้โหลดแอปซ้ำ
คุณใช้เทคนิคต่างๆ ได้หลายวิธีเพื่อให้บรรลุเป้าหมายนี้ สำหรับตัวอย่างโค้ดต่อไปนี้ ให้ถือว่าไฟล์โมเดลแต่ละไฟล์จัดเก็บไว้ในออบเจ็กต์ Blob ชื่อ blob
ในหน่วยความจำ
หากต้องการทำความเข้าใจประสิทธิภาพ โค้ดตัวอย่างแต่ละรายการจะมีคำอธิบายประกอบด้วยเมธอด
performance.mark()
และ performance.measure()
มาตรการเหล่านี้ขึ้นอยู่กับอุปกรณ์และไม่สามารถนำไปใช้กับอุปกรณ์อื่นๆ ได้

คุณเลือกใช้ API อย่างใดอย่างหนึ่งต่อไปนี้เพื่อแคชโมเดล AI ในเบราว์เซอร์ได้ Cache API, Origin Private File System API และ IndexedDB API คำแนะนำทั่วไปคือการใช้ Cache API แต่คู่มือนี้จะกล่าวถึงข้อดีและข้อเสียของ ตัวเลือกทั้งหมด
Cache API
Cache API มี
พื้นที่เก็บข้อมูลแบบถาวรสำหรับคู่
ออบเจ็กต์ Request
และ Response
ที่แคชไว้ในหน่วยความจำที่มีอายุการใช้งานยาวนาน แม้ว่า จะกำหนดไว้ในข้อกำหนดของ Service Worker
แต่คุณก็ใช้ API นี้จากเทรดหลักหรือ Worker ปกติได้ หากต้องการใช้นอกบริบทของ Service Worker ให้เรียกใช้เมธอด Cache.put()
ด้วยออบเจ็กต์ Response สังเคราะห์ที่จับคู่กับ URL สังเคราะห์แทนออบเจ็กต์ Request
คู่มือนี้จะถือว่าคุณใช้ blob ในหน่วยความจำ ใช้ URL ปลอมเป็นคีย์แคชและResponseสังเคราะห์ตาม blob หากต้องการดาวน์โหลดโมเดลโดยตรง คุณจะต้องใช้ Response ที่ได้รับจากการส่งคำขอ fetch()
ตัวอย่างเช่น วิธีจัดเก็บและกู้คืนไฟล์โมเดลด้วย Cache API มีดังนี้
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
Origin Private File System (OPFS) เป็นมาตรฐานที่ค่อนข้างใหม่สำหรับ ปลายทางการจัดเก็บข้อมูล โดยจะเป็นแบบส่วนตัวสำหรับต้นทางของหน้าเว็บ จึงไม่ปรากฏต่อผู้ใช้ ซึ่งต่างจากระบบไฟล์ปกติ โดยจะให้สิทธิ์เข้าถึง ไฟล์พิเศษที่ได้รับการเพิ่มประสิทธิภาพอย่างมากเพื่อประสิทธิภาพ และให้สิทธิ์การเขียนไปยัง เนื้อหาของไฟล์
เช่น วิธีจัดเก็บและกู้คืนไฟล์โมเดลใน OPFS มีดังนี้
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB เป็นมาตรฐานที่ได้รับการยอมรับอย่างดีสำหรับการจัดเก็บข้อมูลที่กำหนดเองในลักษณะที่ถาวร ในเบราว์เซอร์ IndexedDB มีชื่อเสียงในด้าน API ที่ค่อนข้างซับซ้อน แต่การใช้ ไลบรารี Wrapper เช่น idb-keyval จะช่วยให้คุณใช้ IndexedDB เหมือนกับที่เก็บคีย์-ค่าแบบคลาสสิกได้
เช่น
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
ทำเครื่องหมายที่เก็บข้อมูลว่าคงอยู่
เรียกใช้ navigator.storage.persist()
ที่ส่วนท้ายของวิธีการแคชเหล่านี้เพื่อขอสิทธิ์ใช้
พื้นที่เก็บข้อมูลแบบถาวร เมธอดนี้จะแสดงผล Promise ที่เปลี่ยนเป็น true หากได้รับ
สิทธิ์ และ false ในกรณีอื่นๆ เบราว์เซอร์อาจหรือไม่ปฏิบัติตามคำขอ
ขึ้นอยู่กับกฎเฉพาะของเบราว์เซอร์
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
กรณีพิเศษ: ใช้โมเดลในฮาร์ดดิสก์
คุณอ้างอิงโมเดล AI จากฮาร์ดดิสก์ของผู้ใช้ได้โดยตรงเพื่อเป็นทางเลือกแทน พื้นที่เก็บข้อมูลในเบราว์เซอร์ เทคนิคนี้ช่วยให้แอปที่เน้นการวิจัยแสดงให้เห็นถึง ความเป็นไปได้ในการเรียกใช้โมเดลที่กำหนดในเบราว์เซอร์ หรือช่วยให้ศิลปินใช้ โมเดลที่ฝึกด้วยตนเองในแอปความคิดสร้างสรรค์สำหรับผู้เชี่ยวชาญได้
File System Access API
เมื่อใช้ File System Access API คุณจะเปิดไฟล์จากฮาร์ดดิสก์และรับ FileSystemFileHandle ที่บันทึกไว้ใน IndexedDB ได้
เมื่อใช้รูปแบบนี้ ผู้ใช้จะต้องให้สิทธิ์เข้าถึงไฟล์โมเดลเพียงครั้งเดียว
สิทธิ์ที่คงอยู่ช่วยให้ผู้ใช้เลือกให้สิทธิ์เข้าถึงไฟล์อย่างถาวรได้
หลังจากโหลดแอปซ้ำและท่าทางของผู้ใช้ที่จำเป็น เช่น การคลิกเมาส์ คุณจะกู้คืน FileSystemFileHandle จาก IndexedDB พร้อมสิทธิ์เข้าถึงไฟล์ในฮาร์ดดิสก์ได้
ระบบจะค้นหาและขอสิทธิ์เข้าถึงไฟล์หากจำเป็น ซึ่งจะทำให้การโหลดซ้ำในอนาคตเป็นไปอย่างราบรื่น ตัวอย่างต่อไปนี้แสดงวิธีรับแฮนเดิลสำหรับไฟล์จากฮาร์ดดิสก์ จากนั้นจัดเก็บและกู้คืนแฮนเดิล
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
วิธีการเหล่านี้ไม่ได้แยกจากกันโดยสิ้นเชิง อาจมีกรณีที่คุณทั้ง แคชโมเดลอย่างชัดเจนในเบราว์เซอร์และใช้โมเดลจากฮาร์ดดิสก์ของผู้ใช้
สาธิต
คุณสามารถดูวิธีการจัดเก็บเคสปกติทั้ง 3 วิธีและวิธีการฮาร์ดดิสก์ ที่ใช้ในการสาธิต LLM ของ MediaPipe
โบนัส: ดาวน์โหลดไฟล์ขนาดใหญ่เป็นส่วนๆ
หากต้องการดาวน์โหลดโมเดล AI ขนาดใหญ่จากอินเทอร์เน็ต ให้ดาวน์โหลดแบบขนานเป็นหลายๆ ชิ้น แล้วต่อกลับเข้าด้วยกันอีกครั้งในไคลเอ็นต์
แพ็กเกจ fetch-in-chunks มี
ฟังก์ชันตัวช่วยที่คุณใช้ในโค้ดได้ คุณเพียงแค่ต้องส่ง url ให้กับฟังก์ชัน maxParallelRequests (ค่าเริ่มต้น: 6), chunkSize
(ค่าเริ่มต้น: ขนาดไฟล์ที่จะดาวน์โหลดหารด้วย maxParallelRequests),
ฟังก์ชัน progressCallback (ซึ่งรายงานเกี่ยวกับ
downloadedBytes และ fileSize ทั้งหมด) และ signal สำหรับสัญญาณ AbortSignal เป็นตัวเลือกทั้งหมด
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
เลือกวิธีที่เหมาะกับคุณ
คู่มือนี้ได้สำรวจวิธีการต่างๆ ในการแคชโมเดล AI ในเบราว์เซอร์อย่างมีประสิทธิภาพ ซึ่งเป็นงานที่สำคัญอย่างยิ่งในการปรับปรุงประสบการณ์ของผู้ใช้และประสิทธิภาพของแอป ทีมพื้นที่เก็บข้อมูลของ Chrome ขอแนะนำให้ใช้ Cache API เพื่อประสิทธิภาพสูงสุด เพื่อให้มั่นใจว่าเข้าถึงโมเดล AI ได้อย่างรวดเร็ว ลดเวลาในการโหลด และปรับปรุงการตอบสนอง
OPFS และ IndexedDB เป็นตัวเลือกที่ใช้งานได้น้อยกว่า OPFS และ IndexedDB API ต้องจัดรูปแบบข้อมูลก่อนจึงจะจัดเก็บได้ นอกจากนี้ IndexedDB ยังต้อง ยกเลิกการซีเรียลไลซ์ข้อมูลเมื่อมีการเรียกข้อมูล ซึ่งทำให้เป็นที่เก็บ โมเดลขนาดใหญ่ที่แย่ที่สุด
สำหรับแอปพลิเคชันเฉพาะกลุ่ม File System Access API จะให้สิทธิ์เข้าถึงไฟล์โดยตรงในอุปกรณ์ของผู้ใช้ ซึ่งเหมาะสำหรับผู้ใช้ที่จัดการโมเดล AI ของตนเอง
หากต้องการรักษาความปลอดภัยของโมเดล AI ให้เก็บไว้ในเซิร์ฟเวอร์ เมื่อจัดเก็บไว้ในไคลเอ็นต์แล้ว การดึงข้อมูลจากทั้งแคชและ IndexedDB จะเป็นเรื่องง่ายด้วย DevTools หรือส่วนขยาย OFPS DevTools API พื้นที่เก็บข้อมูลเหล่านี้มีความปลอดภัยเท่ากันโดยธรรมชาติ คุณอาจต้องการ จัดเก็บโมเดลเวอร์ชันที่เข้ารหัส แต่จากนั้นคุณจะต้องรับคีย์ถอดรหัส ไปยังไคลเอ็นต์ ซึ่งอาจถูกดักฟังได้ ซึ่งหมายความว่าความพยายามของผู้ไม่ประสงค์ดี ที่จะขโมยโมเดลของคุณจะยากขึ้นเล็กน้อย แต่ก็ไม่ได้เป็นไปไม่ได้
เราขอแนะนำให้คุณเลือกกลยุทธ์การแคชที่สอดคล้องกับข้อกำหนดของแอป พฤติกรรมของกลุ่มเป้าหมาย และลักษณะของโมเดล AI ที่ใช้ ซึ่งจะช่วยให้มั่นใจว่าแอปพลิเคชันของคุณจะตอบสนองและมีประสิทธิภาพภายใต้ สภาพเครือข่ายและข้อจำกัดของระบบต่างๆ
คำขอบคุณ
โดยได้รับการตรวจสอบจาก Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan และ Rachel Andrew