

La plupart des modèles de langage ont un point commun : ils sont assez volumineux pour une ressource transférée sur Internet. Le plus petit modèle de détection d'objets MediaPipe (SSD MobileNetV2 float16) pèse 5,6 Mo, et le plus grand environ 25 Mo.
Le grand modèle de langage (LLM) Open Source gemma-2b-it-gpu-int4.bin pèse 1,35 Go, ce qui est considéré comme très petit pour un LLM.
Les modèles d'IA générative peuvent être énormes. C'est pourquoi une grande partie de l'utilisation de l'IA aujourd'hui se fait dans le cloud. De plus en plus d'applications exécutent des modèles hautement optimisés directement sur l'appareil. Bien qu'il existe des démonstrations de LLM s'exécutant dans le navigateur, voici quelques exemples de modèles de qualité production s'exécutant dans le navigateur :
- Adobe Photoshop exécute une variante du modèle
Conv2Dsur l'appareil pour son outil de sélection d'objets intelligent. - Google Meet exécute une version optimisée du modèle
MobileNetV3-smallpour la segmentation des personnes dans sa fonctionnalité de floutage de l'arrière-plan. - Tokopedia exécute le modèle
MediaPipeFaceDetector-TFJSpour la détection des visages en temps réel afin d'empêcher les inscriptions non valides à son service. - Google Colab permet aux utilisateurs d'utiliser des modèles depuis leur disque dur dans les notebooks Colab.
Pour accélérer les futurs lancements de vos applications, vous devez mettre en cache explicitement les données du modèle sur l'appareil, plutôt que de vous fier au cache HTTP implicite du navigateur.
Bien que ce guide utilise le modèle gemma-2b-it-gpu-int4.bin pour créer un chatbot, l'approche peut être généralisée pour s'adapter à d'autres modèles et à d'autres cas d'utilisation sur l'appareil. La façon la plus courante de connecter une application à un modèle consiste à diffuser le modèle en même temps que le reste des ressources de l'application. Il est essentiel d'optimiser la diffusion.
Configurer les bons en-têtes de cache
Si vous diffusez des modèles d'IA à partir de votre serveur, il est important de configurer l'en-tête Cache-Control approprié. L'exemple suivant montre un paramètre par défaut solide, sur lequel vous pouvez vous appuyer pour répondre aux besoins de votre application.
Cache-Control: public, max-age=31536000, immutable
Chaque version publiée d'un modèle d'IA est une ressource statique. Le contenu qui ne change jamais doit être associé à un max-age long et à une invalidation du cache dans l'URL de la requête. Si vous devez mettre à jour le modèle, vous devez lui attribuer une nouvelle URL.
Lorsque l'utilisateur recharge la page, le client envoie une demande de revalidation, même si le serveur sait que le contenu est stable. La directive immutable indique explicitement que la revalidation n'est pas nécessaire, car le contenu ne changera pas. L'instruction immutable n'est pas largement prise en charge par les navigateurs et les serveurs proxy ou de cache intermédiaires. Toutefois, en la combinant avec l'instruction max-age, qui est universellement comprise, vous pouvez assurer une compatibilité maximale. La directive de réponse public indique que la réponse peut être stockée dans un cache partagé.
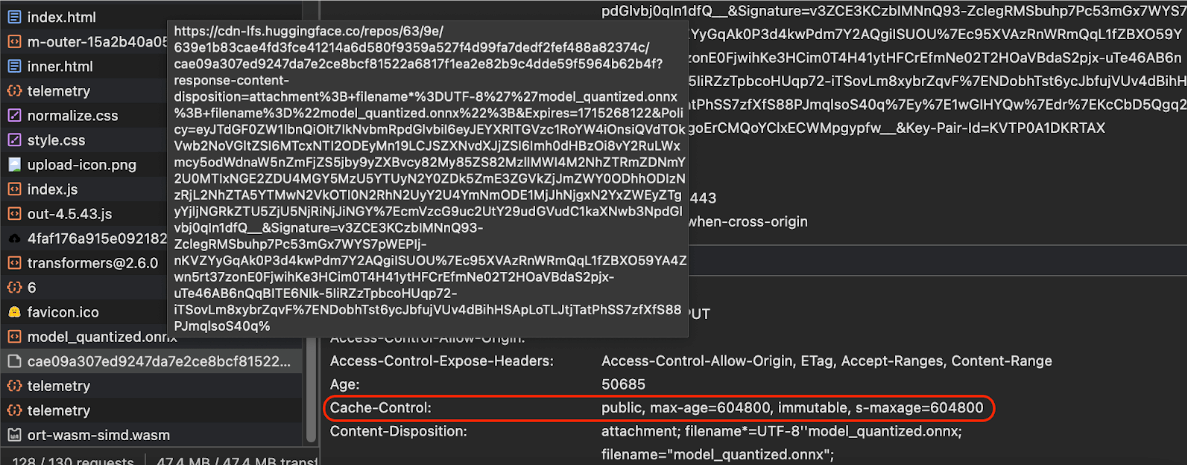
Cache-Control envoyés par Hugging Face lors de la demande d'un modèle d'IA.
(Source)
Mettre en cache les modèles d'IA côté client
Lorsque vous diffusez un modèle d'IA, il est important de le mettre explicitement en cache dans le navigateur. Cela garantit que les données du modèle sont facilement disponibles après qu'un utilisateur a rechargé l'application.
Pour ce faire, plusieurs techniques s'offrent à vous. Pour les exemples de code suivants, supposons que chaque fichier de modèle est stocké dans un objet Blob nommé blob en mémoire.
Pour comprendre les performances, chaque exemple de code est annoté avec les méthodes performance.mark() et performance.measure(). Ces mesures dépendent de l'appareil et ne sont pas généralisables.

Vous pouvez choisir d'utiliser l'une des API suivantes pour mettre en cache les modèles d'IA dans le navigateur : l'API Cache, l'API Origin Private File System et l'API IndexedDB. La recommandation générale est d'utiliser l'API Cache, mais ce guide aborde les avantages et les inconvénients de toutes les options.
API Cache
L'API Cache fournit un stockage persistant pour les paires d'objets Request et Response mises en cache dans une mémoire à long terme. Bien qu'elle soit définie dans la spécification des service workers, vous pouvez utiliser cette API à partir du thread principal ou d'un worker normal. Pour l'utiliser en dehors d'un contexte de service worker, appelez la méthode Cache.put() avec un objet Response synthétique, associé à une URL synthétique au lieu d'un objet Request.
Ce guide suppose que vous utilisez un blob en mémoire. Utilisez une URL fictive comme clé de cache et un Response synthétique basé sur le blob. Si vous souhaitez télécharger directement le modèle, vous devez utiliser le Response que vous obtenez en envoyant une requête fetch().
Par exemple, voici comment stocker et restaurer un fichier de modèle avec l'API Cache.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
API Origin Private File System
L'Origin Private File System (OPFS) est une norme relativement récente pour un point de terminaison de stockage. Il est privé à l'origine de la page et donc invisible pour l'utilisateur, contrairement au système de fichiers habituel. Il donne accès à un fichier spécial hautement optimisé pour les performances et offre un accès en écriture à son contenu.
Voici par exemple comment stocker et restaurer un fichier de modèle dans l'OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
API IndexedDB
IndexedDB est une norme bien établie pour stocker des données arbitraires de manière persistante dans le navigateur. Elle est tristement célèbre pour son API quelque peu complexe, mais en utilisant une bibliothèque wrapper telle que idb-keyval, vous pouvez traiter IndexedDB comme un magasin clé-valeur classique.
Exemple :
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Marquer le stockage comme persistant
Appelez navigator.storage.persist() à la fin de l'une de ces méthodes de mise en cache pour demander l'autorisation d'utiliser le stockage persistant. Cette méthode renvoie une promesse qui renvoie vers true si l'autorisation est accordée et false dans le cas contraire. Le navigateur peut ou non honorer la requête, selon les règles spécifiques au navigateur.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Cas particulier : utiliser un modèle sur un disque dur
Vous pouvez référencer des modèles d'IA directement à partir du disque dur d'un utilisateur au lieu du stockage du navigateur. Cette technique peut aider les applications axées sur la recherche à démontrer la faisabilité de l'exécution de modèles donnés dans le navigateur, ou permettre aux artistes d'utiliser des modèles auto-entraînés dans des applications de créativité expertes.
API File System Access
L'API File System Access vous permet d'ouvrir des fichiers à partir du disque dur et d'obtenir un FileSystemFileHandle que vous pouvez conserver dans IndexedDB.
Avec ce modèle, l'utilisateur n'a besoin d'accorder l'accès au fichier de modèle qu'une seule fois. Grâce aux autorisations persistantes, l'utilisateur peut choisir d'accorder un accès permanent au fichier. Après le rechargement de l'application et un geste utilisateur requis, tel qu'un clic de souris, le FileSystemFileHandle peut être restauré à partir d'IndexedDB avec accès au fichier sur le disque dur.
Les autorisations d'accès aux fichiers sont demandées si nécessaire, ce qui permet un rechargement fluide à l'avenir. L'exemple suivant montre comment obtenir un handle pour un fichier à partir du disque dur, puis comment stocker et restaurer le handle.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Ces méthodes ne s'excluent pas mutuellement. Il peut arriver que vous mettiez explicitement en cache un modèle dans le navigateur et que vous utilisiez un modèle à partir du disque dur d'un utilisateur.
Démo
Vous pouvez voir les trois méthodes de stockage de cas réguliers et la méthode du disque dur implémentées dans la démonstration LLM MediaPipe.
Bonus : Télécharger un fichier volumineux par fragments
Si vous devez télécharger un grand modèle d'IA depuis Internet, parallélisez le téléchargement en plusieurs blocs distincts, puis rassemblez-les sur le client.
Le package fetch-in-chunks fournit une fonction d'assistance que vous pouvez utiliser dans votre code. Il vous suffit de lui transmettre le url. Les fonctions maxParallelRequests (par défaut : 6), chunkSize (par défaut : taille du fichier à télécharger divisée par maxParallelRequests), progressCallback (qui indique downloadedBytes et le fileSize total) et signal pour un signal AbortSignal sont toutes facultatives.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Choisissez la méthode qui vous convient
Ce guide a exploré différentes méthodes pour mettre en cache efficacement les modèles d'IA dans le navigateur. Cette tâche est essentielle pour améliorer l'expérience utilisateur et les performances de votre application. L'équipe de stockage Chrome recommande l'API Cache pour des performances optimales. Elle permet d'accéder rapidement aux modèles d'IA, de réduire les temps de chargement et d'améliorer la réactivité.
OPFS et IndexedDB sont des options moins utilisables. Les API OPFS et IndexedDB doivent sérialiser les données avant de pouvoir les stocker. IndexedDB doit également désérialiser les données lorsqu'elles sont récupérées, ce qui en fait le pire endroit pour stocker de grands modèles.
Pour les applications de niche, l'API File System Access offre un accès direct aux fichiers sur l'appareil d'un utilisateur, ce qui est idéal pour les utilisateurs qui gèrent leurs propres modèles d'IA.
Si vous devez sécuriser votre modèle d'IA, conservez-le sur le serveur. Une fois stockées sur le client, il est facile d'extraire les données du cache et d'IndexedDB avec les outils de développement ou l'extension OFPS DevTools. Ces API de stockage sont intrinsèquement équivalentes en termes de sécurité. Vous pouvez être tenté de stocker une version chiffrée du modèle, mais vous devez ensuite fournir la clé de déchiffrement au client, qui pourrait être interceptée. Cela signifie qu'il est légèrement plus difficile, mais pas impossible, pour un acteur malveillant de voler votre modèle.
Nous vous encourageons à choisir une stratégie de mise en cache qui correspond aux exigences de votre application, au comportement de votre audience cible et aux caractéristiques des modèles d'IA utilisés. Cela garantit que vos applications sont réactives et robustes dans diverses conditions de réseau et contraintes système.
Remerciements
Cet article a été relu par Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan et Rachel Andrew.