

У большинства языковых моделей есть одна общая черта: они довольно велики для ресурса, передаваемого через Интернет. Наименьшая модель обнаружения объектов MediaPipe ( SSD MobileNetV2 float16 ) весит 5,6 МБ, а самая большая — около 25 МБ.
Модель большого языка программирования (LLM) с открытым исходным кодом gemma-2b-it-gpu-int4.bin занимает 1,35 ГБ, что считается очень небольшим показателем для LLM. Генеративные модели ИИ могут быть огромными. Именно поэтому сегодня ИИ часто используется в облаке. Всё чаще приложения запускают высокооптимизированные модели непосредственно на устройствах. Хотя существуют демонстрационные версии LLM, работающие в браузере , вот несколько примеров других моделей, работающих в продакшн-режиме:
- Adobe Photoshop запускает вариант модели
Conv2Dна устройстве для своего интеллектуального инструмента выбора объектов. - Google Meet использует оптимизированную версию модели
MobileNetV3-smallдля сегментации людей с целью реализации функции размытия фона. - Tokopedia использует модель
MediaPipeFaceDetector-TFJSдля распознавания лиц в реальном времени, чтобы предотвратить недействительные регистрации на своем сервисе. - Google Colab позволяет пользователям использовать модели со своего жесткого диска в блокнотах Colab.
Чтобы ускорить будущие запуски ваших приложений, следует явно кэшировать данные модели на устройстве, а не полагаться на неявный HTTP-кеш браузера.
Хотя в этом руководстве для создания чат-бота используется модель gemma-2b-it-gpu-int4.bin , этот подход можно адаптировать для других моделей и других вариантов использования на устройстве. Наиболее распространённый способ подключения приложения к модели — это предоставление модели вместе с остальными ресурсами приложения. Крайне важно оптимизировать доставку.
Настройте правильные заголовки кэша
Если вы обслуживаете модели ИИ на своём сервере, важно правильно настроить заголовок Cache-Control . В следующем примере показана надёжная настройка по умолчанию, которую вы можете адаптировать под нужды своего приложения.
Cache-Control: public, max-age=31536000, immutable
Каждая выпущенная версия модели ИИ представляет собой статический ресурс. Контенту, который никогда не меняется, следует задать длительный max-age в сочетании с очисткой кэша в URL-адресе запроса. Если вам необходимо обновить модель, необходимо указать для неё новый URL-адрес .
Когда пользователь перезагружает страницу, клиент отправляет запрос на повторную валидацию, хотя сервер знает, что контент не изменился. Директива immutable явно указывает на необходимость повторной валидации, поскольку контент не изменится. Директива immutable не поддерживается браузерами, промежуточными кэширующими серверами или прокси-серверами в широких масштабах , но сочетание её с общеизвестной директивой max-age позволяет обеспечить максимальную совместимость. Директива public response указывает на возможность сохранения ответа в общем кэше.
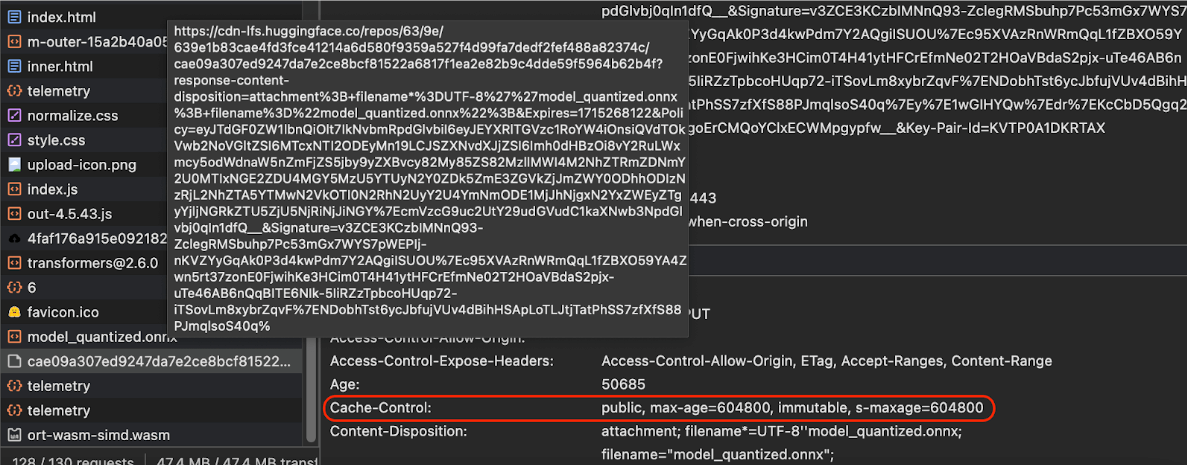
Cache-Control отправленные Hugging Face при запросе модели ИИ. ( Источник ) Кэширование моделей ИИ на стороне клиента
При использовании модели ИИ важно явно кэшировать её в браузере. Это гарантирует доступность данных модели после перезагрузки приложения пользователем.
Для этого можно использовать несколько методов. В следующих примерах кода предполагается, что каждый файл модели хранится в Blob -объекте с именем blob в памяти.
Для оценки производительности каждый пример кода аннотируется методами performance.mark() и performance.measure() . Эти показатели зависят от устройства и не подлежат обобщению.

Для кэширования моделей ИИ в браузере вы можете использовать один из следующих API: Cache API , Origin Private File System API и IndexedDB API . Мы рекомендуем использовать Cache API , но в этом руководстве рассматриваются преимущества и недостатки всех вариантов.
API кэша
API кэширования обеспечивает постоянное хранение пар объектов Request и Response , кэшируемых в долгоживущей памяти. Хотя он определён в спецификации Service Workers , вы можете использовать этот API из основного потока или обычного воркера. Чтобы использовать его вне контекста сервис-воркера, вызовите метод Cache.put() с синтетическим объектом Response в паре с синтетическим URL вместо объекта Request .
В этом руководстве предполагается наличие blob в памяти. Используйте поддельный URL в качестве ключа кэша и синтетический Response на основе blob . Если вы хотите напрямую загрузить модель, используйте Response полученный при выполнении запроса fetch() .
Например, вот как сохранить и восстановить файл модели с помощью API кэширования.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
API частной файловой системы Origin
Файловая система Origin Private File System (OPFS) — сравнительно молодой стандарт для конечной точки хранения данных. Она приватна для источника страницы и, следовательно, невидима для пользователя, в отличие от обычной файловой системы. Она предоставляет доступ к специальному файлу, оптимизированному для высокой производительности, и предоставляет право записи к его содержимому.
Например, вот как сохранить и восстановить файл модели в OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
API IndexedDB
IndexedDB — это устоявшийся стандарт для постоянного хранения произвольных данных в браузере. Он известен своим довольно сложным API, но с помощью библиотеки-обёртки, например idb-keyval, IndexedDB можно использовать как классическое хранилище типа «ключ-значение».
Например:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Отметить хранилище как сохраненное
Вызовите navigator.storage.persist() в конце любого из этих методов кэширования, чтобы запросить разрешение на использование постоянного хранилища. Этот метод возвращает обещание, которое принимает значение true если разрешение предоставлено, и false в противном случае. Браузер может выполнить запрос или нет , в зависимости от правил, установленных браузером.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Особый случай: использование модели на жестком диске
Вы можете ссылаться на модели ИИ непосредственно с жёсткого диска пользователя, используя их как альтернативу хранилищу в браузере. Этот метод может помочь приложениям, ориентированным на исследования, продемонстрировать возможность запуска моделей в браузере или позволить художникам использовать самообучающиеся модели в приложениях для профессионального творчества.
API доступа к файловой системе
С помощью API доступа к файловой системе вы можете открывать файлы на жестком диске и получать FileSystemFileHandle , который можно сохранить в IndexedDB.
При использовании этого шаблона пользователю достаточно предоставить доступ к файлу модели только один раз. Благодаря постоянным разрешениям пользователь может предоставить доступ к файлу навсегда. После перезагрузки приложения и выполнения необходимого действия, например щелчка мышью, FileSystemFileHandle можно восстановить из IndexedDB с доступом к файлу на жёстком диске.
При необходимости запрашиваются разрешения на доступ к файлу, что упрощает последующие перезагрузки. В следующем примере показано, как получить дескриптор файла с жёсткого диска, а затем сохранить и восстановить его.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Эти методы не являются взаимоисключающими. Может возникнуть ситуация, когда вы одновременно явно кэшируете модель в браузере и используете модель с жёсткого диска пользователя.
Демо
Все три стандартных метода хранения кейсов и метод жесткого диска, реализованные в демонстрации MediaPipe LLM, можно увидеть.
Бонус: загрузка большого файла по частям
Если вам необходимо загрузить большую модель ИИ из Интернета, распараллеливайте загрузку на отдельные фрагменты, а затем снова сшейте их на клиенте.
Пакет fetch-in-chunks предоставляет вспомогательную функцию, которую можно использовать в коде. Достаточно передать ей url . maxParallelRequests (по умолчанию: 6), chunkSize (по умолчанию: размер загружаемого файла, делённый на maxParallelRequests ), функция progressCallback (сообщающая количество downloadedBytes и общий fileSize ) и signal AbortSignal являются необязательными.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Выберите подходящий для вас метод
В этом руководстве рассматриваются различные методы эффективного кэширования моделей ИИ в браузере, что критически важно для улучшения пользовательского опыта и производительности вашего приложения. Команда разработчиков хранилища Chrome рекомендует использовать API кэширования для оптимальной производительности, чтобы обеспечить быстрый доступ к моделям ИИ, сократить время загрузки и повысить отзывчивость.
OPFS и IndexedDB — менее удобные варианты. API OPFS и IndexedDB требуют сериализации данных перед сохранением. IndexedDB также требует десериализации данных при их извлечении, что делает его неподходящим местом для хранения больших моделей.
Для узкоспециализированных приложений API доступа к файловой системе обеспечивает прямой доступ к файлам на устройстве пользователя, что идеально подходит для пользователей, управляющих собственными моделями ИИ.
Если вам нужно защитить свою модель ИИ, храните её на сервере. После сохранения на клиенте данные легко извлечь из кэша и IndexedDB с помощью DevTools или расширения OFPS DevTools . Эти API хранилища по своей сути одинаковы по уровню безопасности. У вас может возникнуть соблазн сохранить зашифрованную версию модели, но тогда вам потребуется передать клиенту ключ дешифрования, который может быть перехвачен. Это означает, что попытка злоумышленника украсть вашу модель немного сложнее, но не невозможна.
Мы рекомендуем вам выбрать стратегию кэширования, соответствующую требованиям вашего приложения, поведению целевой аудитории и характеристикам используемых моделей ИИ. Это обеспечит отзывчивость и надёжность ваших приложений в различных сетевых условиях и при различных системных ограничениях.
Благодарности
Его рецензировали Джошуа Белл, Рейли Грант, Эван Стэйд, Натан Меммотт, Остин Салливан, Этьен Ноэль, Андре Бандарра, Александра Клеппер, Франсуа Бофорт, Пол Кинлан и Рэйчел Эндрю.