

Większość modeli językowych ma jedną wspólną cechę: są dość duże jak na zasób przesyłany przez internet. Najmniejszy model wykrywania obiektów MediaPipe (SSD MobileNetV2 float16) waży 5,6 MB, a największy – około 25 MB.
Ten duży model językowy (LLM) o otwartym kodzie źródłowymgemma-2b-it-gpu-int4.bin zajmuje 1,35 GB, co w przypadku LLM jest bardzo małą wartością.
Modele generatywnej AI mogą być ogromne. Dlatego wiele zastosowań AI ma obecnie miejsce w chmurze. Coraz częściej aplikacje uruchamiają wysoce zoptymalizowane modele bezpośrednio na urządzeniu. Istnieją wersje demonstracyjne dużych modeli językowych działających w przeglądarce, ale oto kilka przykładów innych modeli działających w przeglądarce w wersji produkcyjnej:
- Adobe Photoshop uruchamia na urządzeniu wariant
Conv2Dna potrzeby inteligentnego narzędzia do zaznaczania obiektów. - Google Meet używa zoptymalizowanej wersji
MobileNetV3-smallmodelu do segmentacji osób na potrzeby funkcji rozmycia tła. - Tokopedia korzysta z
MediaPipeFaceDetector-TFJSmodelu do wykrywania twarzy w czasie rzeczywistym, aby zapobiegać nieprawidłowym rejestracjom w swojej usłudze. - Google Colab umożliwia użytkownikom korzystanie z modeli z dysku twardego w notatnikach Colab.
Aby przyspieszyć przyszłe uruchamianie aplikacji, musisz jawnie zapisywać w pamięci podręcznej dane modelu na urządzeniu, zamiast polegać na domyślnej pamięci podręcznej przeglądarki HTTP.
W tym przewodniku do utworzenia czatbota używamy modelu gemma-2b-it-gpu-int4.bin, ale to podejście można uogólnić, aby dostosować je do innych modeli i innych przypadków użycia na urządzeniu. Najczęstszym sposobem połączenia aplikacji z modelem jest udostępnienie modelu wraz z pozostałymi zasobami aplikacji. Kluczowe znaczenie ma optymalizacja wyświetlania.
Skonfiguruj odpowiednie nagłówki pamięci podręcznej
Jeśli udostępniasz modele AI z serwera, musisz skonfigurować prawidłowy nagłówek Cache-Control. Poniższy przykład pokazuje solidne ustawienie domyślne, które możesz dostosować do potrzeb swojej aplikacji.
Cache-Control: public, max-age=31536000, immutable
Każda opublikowana wersja modelu AI jest zasobem statycznym. Treści, które nigdy się nie zmieniają, powinny mieć długi okres ważności max-age w połączeniu z pomijaniem pamięci podręcznej w adresie URL żądania. Jeśli musisz zaktualizować model, musisz nadać mu nowy adres URL.
Gdy użytkownik ponownie wczytuje stronę, klient wysyła żądanie ponownej weryfikacji, mimo że serwer wie, że treść jest stabilna. Dyrektywa
immutable
wyraźnie wskazuje, że ponowna weryfikacja nie jest konieczna, ponieważ treść nie ulegnie zmianie. Dyrektywa immutable jest słabo obsługiwana przez przeglądarki i pośrednie serwery pamięci podręcznej lub serwery proxy, ale łącząc ją z powszechnie rozumianą dyrektywą max-age, możesz zapewnić maksymalną zgodność. Dyrektywa odpowiedzi public
wskazuje, że odpowiedź może być przechowywana w pamięci podręcznej współdzielonej.
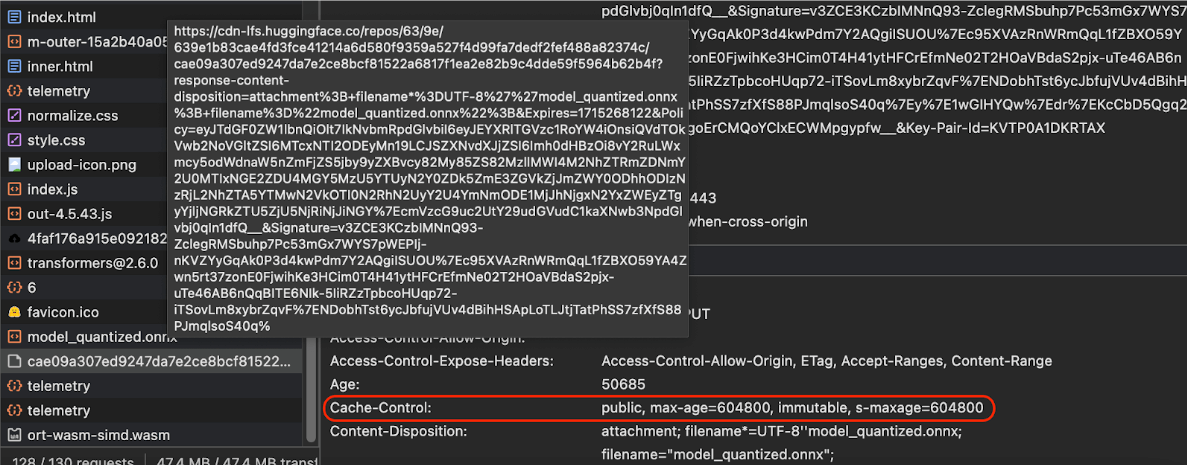
Cache-Control
wysyłane przez Hugging Face podczas żądania modelu AI.
(Źródło)
Buforowanie modeli AI po stronie klienta
Podczas udostępniania modelu AI ważne jest, aby jawnie zapisać go w pamięci podręcznej przeglądarki. Dzięki temu dane modelu są łatwo dostępne po ponownym wczytaniu aplikacji przez użytkownika.
Możesz to zrobić na kilka sposobów. W przypadku poniższych przykładów kodu załóżmy, że każdy plik modelu jest przechowywany w obiekcie Blob o nazwie blob w pamięci.
Aby ułatwić zrozumienie wydajności, każdy przykładowy kod jest opatrzony adnotacjami z metodami performance.mark() i performance.measure(). Te środki zależą od urządzenia i nie można ich uogólniać.

Do buforowania modeli AI w przeglądarce możesz użyć jednego z tych interfejsów API: Cache API, Origin Private File System API i IndexedDB API. Ogólne zalecenie to korzystanie z interfejsu Cache API, ale w tym przewodniku omawiamy zalety i wady wszystkich opcji.
Cache API
Cache API zapewnia trwałe miejsce na pary obiektów Request i Response, które są przechowywane w pamięci długotrwałej. Chociaż jest on zdefiniowany w specyfikacji Service Workers, możesz używać tego interfejsu API w głównym wątku lub w zwykłym procesie roboczym. Aby używać go poza kontekstem skryptu service worker, wywołaj metodę Cache.put() z syntetycznym obiektem Response w parze z syntetycznym adresem URL zamiast obiektu Request.
W tym przewodniku przyjęto założenie, że używasz blob w pamięci. Użyj fałszywego adresu URL jako klucza pamięci podręcznej i syntetycznego Response na podstawie blob. Jeśli chcesz pobrać model bezpośrednio, użyj Response, które otrzymasz po wysłaniu fetch()
żądania.
Oto przykład przechowywania i przywracania pliku modelu za pomocą interfejsu Cache API.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
Prywatny system plików źródła (OPFS) to stosunkowo nowy standard punktu końcowego pamięci masowej. Jest on prywatny dla źródła strony, a tym samym niewidoczny dla użytkownika, w przeciwieństwie do zwykłego systemu plików. Zapewnia dostęp do specjalnego pliku, który jest wysoce zoptymalizowany pod kątem wydajności i umożliwia zapisywanie jego zawartości.
Na przykład poniżej opisano, jak przechowywać i przywracać plik modelu w OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB to sprawdzony standard przechowywania dowolnych danych w sposób trwały w przeglądarce. Jest on znany z dość złożonego interfejsu API, ale za pomocą biblioteki otoki, takiej jak idb-keyval, możesz traktować IndexedDB jak klasyczny magazyn klucz-wartość.
Na przykład:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Oznaczanie pamięci jako trwałej
Na końcu każdej z tych metod buforowania wywołaj funkcję navigator.storage.persist(), aby poprosić o zezwolenie na korzystanie z pamięci trwałej. Ta metoda zwraca obietnicę, która w przypadku przyznania uprawnień jest rozwiązywana jako true, a w przeciwnym razie jako false. Przeglądarka może uwzględnić lub nie uwzględnić żądania w zależności od reguł obowiązujących w danej przeglądarce.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Przypadek specjalny: używanie modelu na dysku twardym
Modele AI możesz odwoływać się bezpośrednio z dysku twardego użytkownika jako alternatywę dla pamięci przeglądarki. Ta technika może pomóc aplikacjom badawczym w wyświetlaniu informacji o możliwości uruchamiania określonych modeli w przeglądarce lub umożliwić artystom korzystanie z samodzielnie wytrenowanych modeli w aplikacjach dla profesjonalistów.
File System Access API
Za pomocą File System Access API możesz otwierać pliki z dysku twardego i uzyskiwać FileSystemFileHandle, który możesz zapisać w IndexedDB.
W tym wzorcu użytkownik musi przyznać dostęp do pliku modelu tylko raz. Dzięki trwałym uprawnieniom użytkownik może trwale przyznać dostęp do pliku. Po ponownym wczytaniu aplikacji i wykonaniu wymaganego gestu użytkownika, np. kliknięcia myszą, można przywrócić FileSystemFileHandle z IndexedDB z dostępem do pliku na dysku twardym.
Uprawnienia dostępu do plików są sprawdzane i w razie potrzeby przesyłane, co zapewnia płynność działania w przypadku przyszłych ponownych załadowań. Poniższy przykład pokazuje, jak uzyskać uchwyt pliku z dysku twardego, a następnie go zapisać i przywrócić.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Te metody nie wykluczają się wzajemnie. Może się zdarzyć, że model zostanie jawnie zapisany w pamięci podręcznej przeglądarki i będzie używany z dysku twardego użytkownika.
Prezentacja
Wszystkie 3 metody przechowywania w pamięci podręcznej i metodę dysku twardego możesz zobaczyć w demonstracji modelu LLM MediaPipe.
Dodatkowo: pobieranie dużego pliku w częściach
Jeśli musisz pobrać z internetu duży model AI, podziel pobieranie na osobne części, a następnie połącz je ponownie na urządzeniu klienta.
Pakiet fetch-in-chunks zawiera funkcję pomocniczą, której możesz używać w kodzie. Wystarczy przekazać do niego url. Parametry maxParallelRequests (domyślnie: 6), chunkSize (domyślnie: rozmiar pobieranego pliku podzielony przez maxParallelRequests), funkcja progressCallback (która raportuje downloadedBytes i całkowitą wartość fileSize) oraz signal dla sygnału AbortSignal są opcjonalne.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Wybierz odpowiednią metodę
W tym przewodniku omówiliśmy różne metody skutecznego buforowania modeli AI w przeglądarce. Jest to kluczowe zadanie, które pozwala zwiększyć komfort użytkownika i wydajność aplikacji. Zespół Chrome Storage zaleca korzystanie z interfejsu Cache API, aby zapewnić optymalną wydajność, szybki dostęp do modeli AI, krótszy czas wczytywania i lepszą responsywność.
OPFS i IndexedDB są mniej przydatne. Interfejsy OPFS i IndexedDB muszą serializować dane, zanim będzie można je zapisać. Podczas pobierania danych z IndexedDB trzeba je też deserializować, co sprawia, że jest to najgorsze miejsce do przechowywania dużych modeli.
W przypadku aplikacji niszowych interfejs File System Access API zapewnia bezpośredni dostęp do plików na urządzeniu użytkownika, co jest idealne dla osób, które zarządzają własnymi modelami AI.
Jeśli chcesz zabezpieczyć model AI, przechowuj go na serwerze. Po zapisaniu danych na urządzeniu klienta można je łatwo wyodrębnić z pamięci podręcznej i IndexedDB za pomocą Narzędzi deweloperskich lub rozszerzenia Narzędzia deweloperskie OFPS. Te interfejsy API do przechowywania danych są z założenia tak samo bezpieczne. Możesz pokusić się o przechowywanie zaszyfrowanej wersji modelu, ale wtedy musisz przekazać klucz odszyfrowywania klientowi, co może zostać przechwycone. Oznacza to, że próba kradzieży modelu przez nieuczciwego podmiotu jest nieco trudniejsza, ale nie niemożliwa.
Zachęcamy do wybrania strategii buforowania, która jest zgodna z wymaganiami aplikacji, zachowaniem odbiorców docelowych i charakterystyką używanych modeli AI. Dzięki temu aplikacje będą działać sprawnie i niezawodnie w różnych warunkach sieciowych i ograniczeniach systemowych.
Podziękowania
Recenzentami byli Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan i Rachel Andrew.