

La maggior parte dei modelli linguistici ha una cosa in comune: sono
piuttosto grandi per una risorsa che viene
trasferita su internet. Il modello di rilevamento di oggetti MediaPipe più piccolo
(SSD MobileNetV2 float16) pesa 5,6 MB
e il più grande circa 25 MB.
Il modello linguistico di grandi dimensioni (LLM) open source
gemma-2b-it-gpu-int4.bin
pesa 1,35 GB, una dimensione considerata molto ridotta per un LLM.
I modelli di AI generativa possono essere enormi. Per questo motivo, oggi gran parte dell'utilizzo dell'AI avviene
nel cloud. Sempre più spesso, le app eseguono modelli altamente ottimizzati direttamente
sul dispositivo. Sebbene esistano demo di LLM in esecuzione nel browser, ecco alcuni esempi di altri modelli di livello di produzione in esecuzione nel browser:
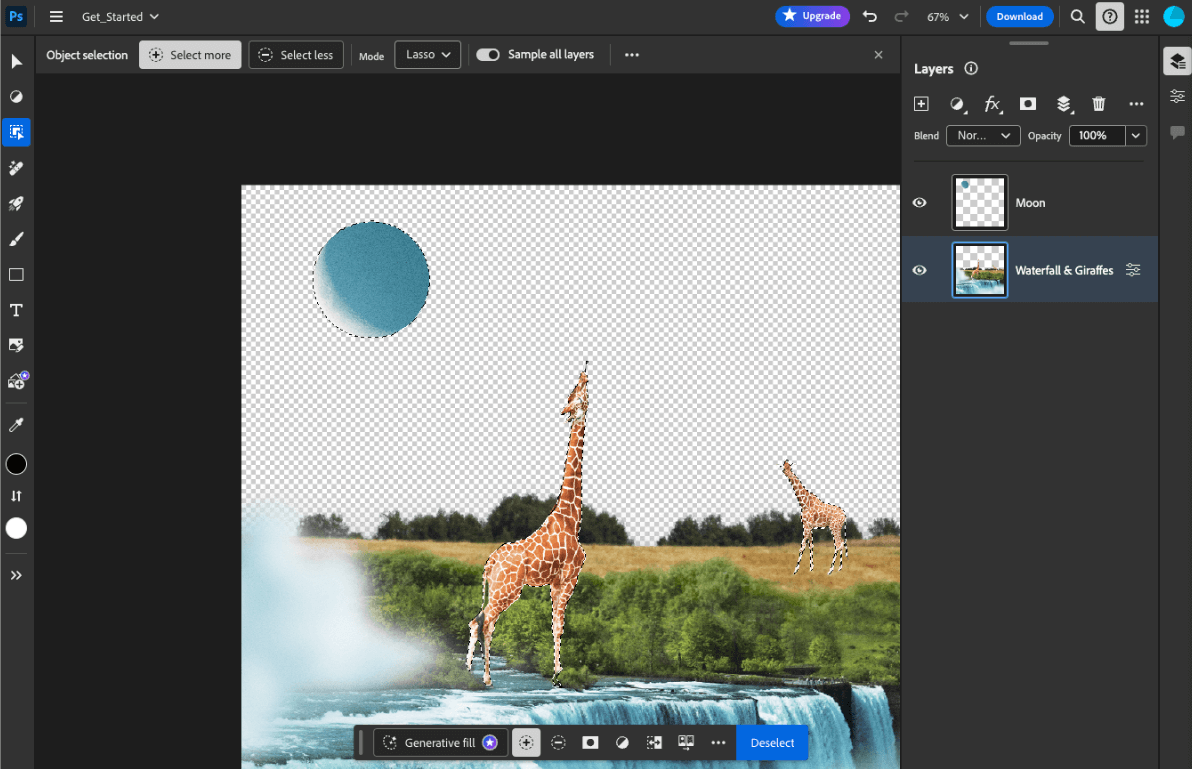
- Adobe Photoshop esegue una variante del
Conv2Dmodello sul dispositivo per lo strumento di selezione intelligente degli oggetti. - Google Meet esegue una versione ottimizzata del
MobileNetV3-smallmodello per la segmentazione delle persone per la funzionalità di sfocatura dello sfondo. - Tokopedia utilizza il
MediaPipeFaceDetector-TFJSper il rilevamento del volto in tempo reale per impedire registrazioni non valide al suo servizio. - Google Colab consente agli utenti di utilizzare modelli dal proprio disco rigido nei notebook Colab.
Per velocizzare i futuri avvii delle tue applicazioni, devi memorizzare nella cache in modo esplicito i dati del modello sul dispositivo, anziché fare affidamento sulla cache HTTP implicita del browser.
Sebbene questa guida utilizzi il modello gemma-2b-it-gpu-int4.bin per creare un chatbot, l'approccio può essere generalizzato per adattarsi ad altri modelli e altri casi d'uso sul dispositivo. Il modo più comune per connettere un'app a un modello è pubblicare il modello insieme al resto delle risorse dell'app. È fondamentale ottimizzare la
pubblicazione.
Configurare le intestazioni della cache corrette
Se pubblichi modelli di AI dal tuo server, è importante configurare l'intestazione
Cache-Control
corretta. L'esempio seguente mostra un'impostazione predefinita solida, su cui puoi basarti
per le esigenze della tua app.
Cache-Control: public, max-age=31536000, immutable
Ogni versione rilasciata di un modello di AI è una risorsa statica. I contenuti che non cambiano mai devono avere un valore max-age lungo combinato con l'aggiornamento della cache nell'URL della richiesta. Se devi aggiornare il modello, devi
fornire un nuovo URL.
Quando l'utente ricarica la pagina, il client invia una richiesta di convalida, anche
se il server sa che i contenuti sono stabili. La direttiva
immutable
indica esplicitamente che la convalida non è necessaria, perché
i contenuti non cambieranno. La direttiva immutable
non è ampiamente supportata
da browser e server proxy o cache intermedi, ma
combinandola con la
direttiva max-age universalmente compresa, puoi garantire la massima
compatibilità. La direttiva di risposta public
indica che la risposta può essere archiviata in una cache condivisa.
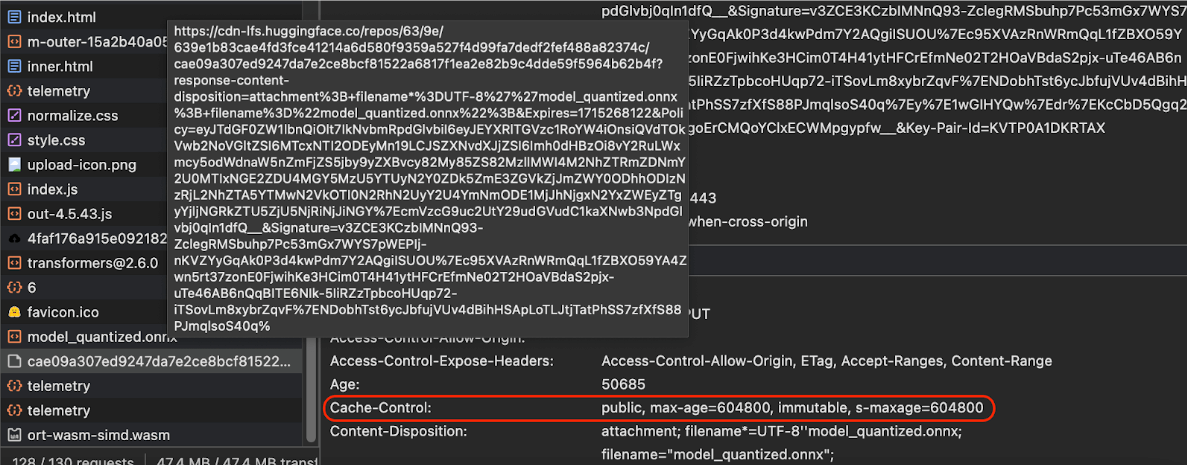
Cache-Control
di produzione inviate da Hugging Face quando viene richiesto un modello di AI.
(Fonte)
Memorizzare nella cache i modelli di AI lato client
Quando pubblichi un modello di AI, è importante memorizzarlo esplicitamente nella cache del browser. In questo modo, i dati del modello sono immediatamente disponibili dopo che un utente ricarica l'app.
Esistono diverse tecniche che puoi utilizzare per raggiungere questo obiettivo. Per i seguenti
esempi di codice, supponi che ogni file del modello sia archiviato in un
oggetto Blob denominato blob
in memoria.
Per comprendere le prestazioni, ogni esempio di codice è annotato con i metodi
performance.mark()
e performance.measure(). Queste misure dipendono dal dispositivo e non sono generalizzabili.

Puoi scegliere di utilizzare una delle seguenti API per memorizzare nella cache i modelli di AI nel browser: API Cache, l'API Origin Private File System e l'API IndexedDB. Il suggerimento generale è di utilizzare l'API Cache, ma questa guida illustra i vantaggi e gli svantaggi di tutte le opzioni.
API Cache
L'API Cache fornisce
spazio di archiviazione persistente per le coppie di oggetti
Request e Response memorizzate nella cache nella memoria a lunga durata. Sebbene sia
definita nella specifica dei service worker,
puoi utilizzare questa API dal thread principale o da un worker normale. Per utilizzarlo al di fuori
di un contesto di service worker, chiama il metodo
Cache.put() con un oggetto Response sintetico, abbinato a un URL sintetico anziché a un oggetto
Request.
Questa guida presuppone un blob in memoria. Utilizza un URL falso come chiave di cache e un
Response sintetico basato su blob. Se scarichi direttamente il modello, utilizzerai Response che otterrai effettuando una richiesta fetch().
Ad esempio, ecco come archiviare e ripristinare un file modello con l'API Cache.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
API Origin Private File System
L'Origin Private File System (OPFS) è uno standard relativamente recente per un endpoint di archiviazione. È privato per l'origine della pagina e quindi invisibile all'utente, a differenza del normale file system. Fornisce l'accesso a un file speciale altamente ottimizzato per le prestazioni e offre l'accesso in scrittura ai suoi contenuti.
Ad esempio, ecco come archiviare e ripristinare un file del modello in OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
API IndexedDB
IndexedDB è uno standard consolidato per l'archiviazione di dati arbitrari in modo permanente nel browser. È nota per la sua API piuttosto complessa, ma utilizzando una libreria wrapper come idb-keyval puoi trattare IndexedDB come un classico archivio chiave-valore.
Ad esempio:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Contrassegna l'archiviazione come persistente
Chiama navigator.storage.persist()
alla fine di uno di questi metodi di memorizzazione nella cache per richiedere l'autorizzazione all'utilizzo
dello spazio di archiviazione permanente. Questo metodo restituisce una promessa che si risolve in true se
l'autorizzazione viene concessa e in false in caso contrario. Il browser
potrebbe o meno rispettare la richiesta,
a seconda delle regole specifiche del browser.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Caso speciale: utilizza un modello su un disco rigido
Puoi fare riferimento ai modelli di AI direttamente dal disco rigido di un utente come alternativa all'archiviazione del browser. Questa tecnica può aiutare le app incentrate sulla ricerca a dimostrare la fattibilità dell'esecuzione di determinati modelli nel browser o consentire agli artisti di utilizzare modelli autoaddestrati in app di creatività esperta.
API File System Access
Con l'API File System Access, puoi aprire file dal disco rigido e ottenere un FileSystemFileHandle che puoi salvare in IndexedDB.
Con questo pattern, l'utente deve concedere l'accesso al file del modello
una sola volta. Grazie alle autorizzazioni persistenti,
l'utente può scegliere di concedere l'accesso al file in modo permanente. Dopo aver ricaricato l'app e un gesto dell'utente richiesto, ad esempio un clic del mouse, il
FileSystemFileHandle può essere ripristinato da IndexedDB con accesso al file
sul disco rigido.
Le autorizzazioni di accesso ai file vengono richieste e interrogate, se necessario, il che rende questa operazione semplice per i ricaricamenti futuri. L'esempio seguente mostra come ottenere un handle per un file dal disco rigido, quindi archiviarlo e ripristinarlo.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Questi metodi non si escludono a vicenda. Potrebbe verificarsi un caso in cui memorizzi esplicitamente nella cache un modello nel browser e utilizzi un modello dal disco rigido di un utente.
Demo
Puoi vedere tutti e tre i metodi di archiviazione regolari e il metodo del disco rigido implementati nella demo di MediaPipe LLM.
Bonus: scaricare un file di grandi dimensioni in blocchi
Se devi scaricare un modello di AI di grandi dimensioni da internet, parallelizza il download in blocchi separati, quindi ricomponili sul client.
Il pacchetto fetch-in-chunks fornisce una
funzione helper che puoi utilizzare nel codice. Devi solo passargli
il url. maxParallelRequests (valore predefinito: 6), chunkSize
(valore predefinito: dimensioni del file da scaricare divise per maxParallelRequests), la
funzione progressCallback (che genera report su
downloadedBytes e sul fileSize totale) e signal per un
segnale AbortSignal sono tutti facoltativi.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Scegli il metodo più adatto a te
Questa guida ha esplorato vari metodi per memorizzare in modo efficace nella cache i modelli di AI nel browser, un'attività fondamentale per migliorare l'esperienza utente e le prestazioni della tua app. Il team di archiviazione di Chrome consiglia l'API Cache per prestazioni ottimali, per garantire un rapido accesso ai modelli di AI, ridurre i tempi di caricamento e migliorare la reattività.
OPFS e IndexedDB sono opzioni meno utilizzabili. Le API OPFS e IndexedDB devono serializzare i dati prima di poterli archiviare. Inoltre, IndexedDB deve deserializzare i dati quando vengono recuperati, il che lo rende il posto peggiore per archiviare modelli di grandi dimensioni.
Per le applicazioni di nicchia, l'API File System Access offre l'accesso diretto ai file sul dispositivo di un utente, ideale per gli utenti che gestiscono i propri modelli di AI.
Se devi proteggere il tuo modello di AI, mantienilo sul server. Una volta memorizzati sul client, è banale estrarre i dati sia dalla cache sia da IndexedDB con DevTools o con l'estensione OFPS DevTools. Queste API di archiviazione sono intrinsecamente uguali in termini di sicurezza. Potresti essere tentato di memorizzare una versione criptata del modello, ma poi devi fornire la chiave di decrittografia al client, che potrebbe essere intercettata. Ciò significa che il tentativo di un malintenzionato di rubare il tuo modello è leggermente più difficile, ma non impossibile.
Ti consigliamo di scegliere una strategia di memorizzazione nella cache in linea con i requisiti della tua app, il comportamento del pubblico di destinazione e le caratteristiche dei modelli di AI utilizzati. In questo modo, le tue applicazioni sono reattive e robuste in varie condizioni di rete e vincoli di sistema.
Ringraziamenti
La revisione è stata eseguita da Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan e Rachel Andrew.