

ज़्यादातर लैंग्वेज मॉडल में एक बात सामान्य होती है: वे इंटरनेट पर ट्रांसफ़र किए जाने वाले किसी संसाधन के लिए काफ़ी बड़े होते हैं. MediaPipe ऑब्जेक्ट डिटेक्शन मॉडल (SSD MobileNetV2 float16) का सबसे छोटा वर्शन 5.6 एमबी का है और सबसे बड़ा वर्शन करीब 25 एमबी का है.
ओपन-सोर्स लार्ज लैंग्वेज मॉडल (एलएलएम) gemma-2b-it-gpu-int4.bin का साइज़ 1.35 जीबी है. एलएलएम के लिए, इसे बहुत छोटा माना जाता है.
जनरेटिव एआई मॉडल बहुत बड़े हो सकते हैं. इसलिए, आज एआई का ज़्यादातर इस्तेमाल क्लाउड में होता है. ज़्यादा से ज़्यादा ऐप्लिकेशन, सीधे तौर पर डिवाइस पर बेहतर तरीके से ऑप्टिमाइज़ किए गए मॉडल चला रहे हैं. ब्राउज़र में चलने वाले एलएलएम के डेमो उपलब्ध हैं. हालांकि, यहां ब्राउज़र में चलने वाले अन्य मॉडल के कुछ प्रोडक्शन-ग्रेड उदाहरण दिए गए हैं:
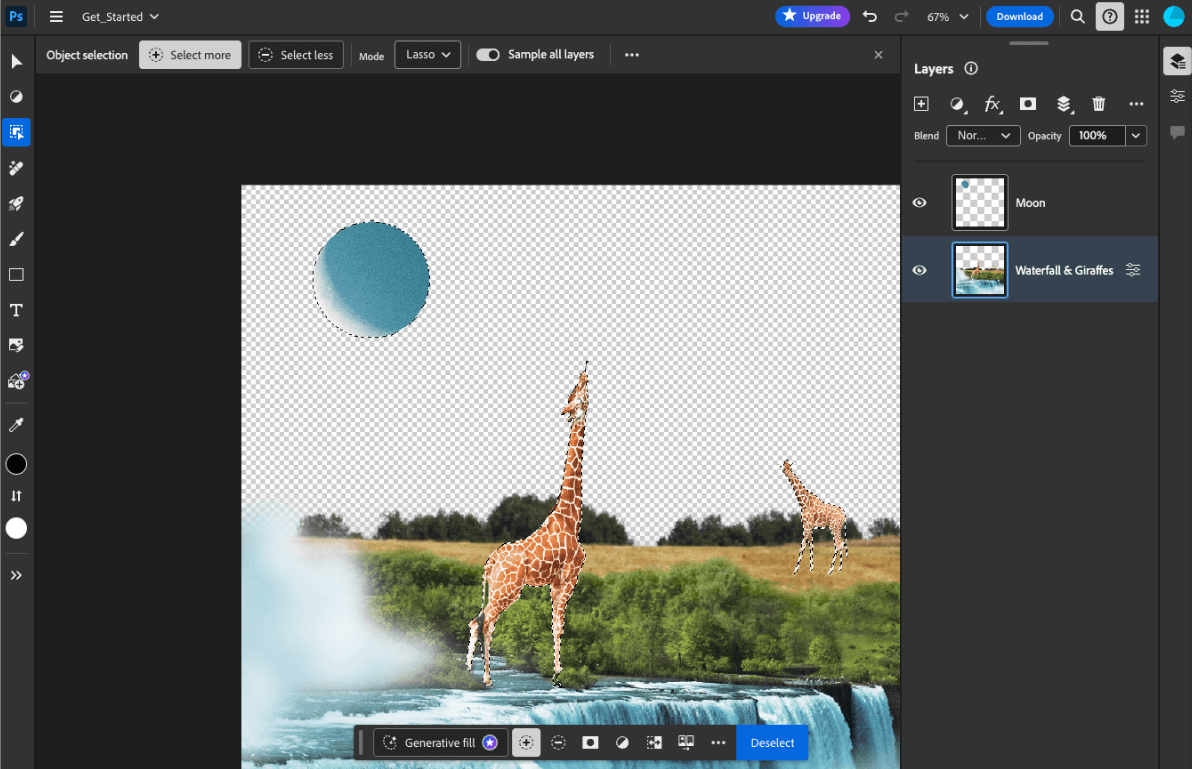
- Adobe Photoshop, ऑब्जेक्ट चुनने के लिए उपलब्ध स्मार्ट टूल के लिए, उपयोगकर्ता के डिवाइस पर
Conv2Dमॉडल का एक वैरिएंट इस्तेमाल करता है. - Google Meet, बैकग्राउंड धुंधला करने की सुविधा के लिए, व्यक्ति के हिसाब से सेगमेंट किए गए
MobileNetV3-smallमॉडल के ऑप्टिमाइज़ किए गए वर्शन का इस्तेमाल करता है. - Tokopedia,
MediaPipeFaceDetector-TFJSमॉडल का इस्तेमाल करता है. इससे, रीयल टाइम में चेहरे का पता लगाया जा सकता है. इससे, उसकी सेवा के लिए अमान्य साइनअप को रोका जा सकता है. - Google Colab, उपयोगकर्ताओं को Colab नोटबुक में अपनी हार्ड डिस्क से मॉडल इस्तेमाल करने की अनुमति देता है.
अपने ऐप्लिकेशन को आने वाले समय में तेज़ी से लॉन्च करने के लिए, आपको मॉडल के डेटा को डिवाइस पर साफ़ तौर पर कैश मेमोरी में सेव करना चाहिए. इसके बजाय, आपको एचटीटीपी ब्राउज़र की कैश मेमोरी पर भरोसा नहीं करना चाहिए.
इस गाइड में, चैटबॉट बनाने के लिए gemma-2b-it-gpu-int4.bin मॉडल का इस्तेमाल किया गया है. हालांकि, इस तरीके का इस्तेमाल अन्य मॉडल और डिवाइस पर इस्तेमाल के अन्य उदाहरणों के लिए भी किया जा सकता है. किसी ऐप्लिकेशन को मॉडल से कनेक्ट करने का सबसे सामान्य तरीका यह है कि मॉडल को ऐप्लिकेशन के बाकी संसाधनों के साथ परोसा जाए. विज्ञापन दिखाने की प्रोसेस को ऑप्टिमाइज़ करना ज़रूरी है.
सही कैश हेडर कॉन्फ़िगर करना
अगर आपको अपने सर्वर से एआई मॉडल उपलब्ध कराने हैं, तो सही Cache-Control हेडर कॉन्फ़िगर करना ज़रूरी है. यहां डिफ़ॉल्ट सेटिंग का एक उदाहरण दिया गया है. इसे अपने ऐप्लिकेशन की ज़रूरतों के हिसाब से बनाया जा सकता है.
Cache-Control: public, max-age=31536000, immutable
एआई मॉडल का हर रिलीज़ किया गया वर्शन, स्टैटिक संसाधन होता है. ऐसे कॉन्टेंट के लिए, लंबे समय तक मान्य रहने वाला max-age इस्तेमाल करना चाहिए जिसमें कभी बदलाव नहीं होता. साथ ही, अनुरोध किए गए यूआरएल में कैश मेमोरी को खारिज करने की तकनीक का इस्तेमाल करना चाहिए. अगर आपको मॉडल अपडेट करना है, तो आपको इसे नया यूआरएल देना होगा.
जब उपयोगकर्ता पेज को फिर से लोड करता है, तो क्लाइंट फिर से पुष्टि करने का अनुरोध भेजता है. भले ही, सर्वर को पता हो कि कॉन्टेंट स्थिर है. immutable
निर्देश साफ़ तौर पर यह बताता है कि दोबारा पुष्टि करने की ज़रूरत नहीं है, क्योंकि कॉन्टेंट में कोई बदलाव नहीं होगा. immutable डायरेक्टिव, ब्राउज़र और इंटरमीडियरी कैश या प्रॉक्सी सर्वर के साथ ज़्यादातर काम नहीं करता. हालांकि, इसे max-age डायरेक्टिव के साथ इस्तेमाल करके, यह पक्का किया जा सकता है कि यह ज़्यादा से ज़्यादा ब्राउज़र के साथ काम करे. public
रिस्पॉन्स डायरेक्टिव से पता चलता है कि रिस्पॉन्स को शेयर की गई कैश मेमोरी में सेव किया जा सकता है.
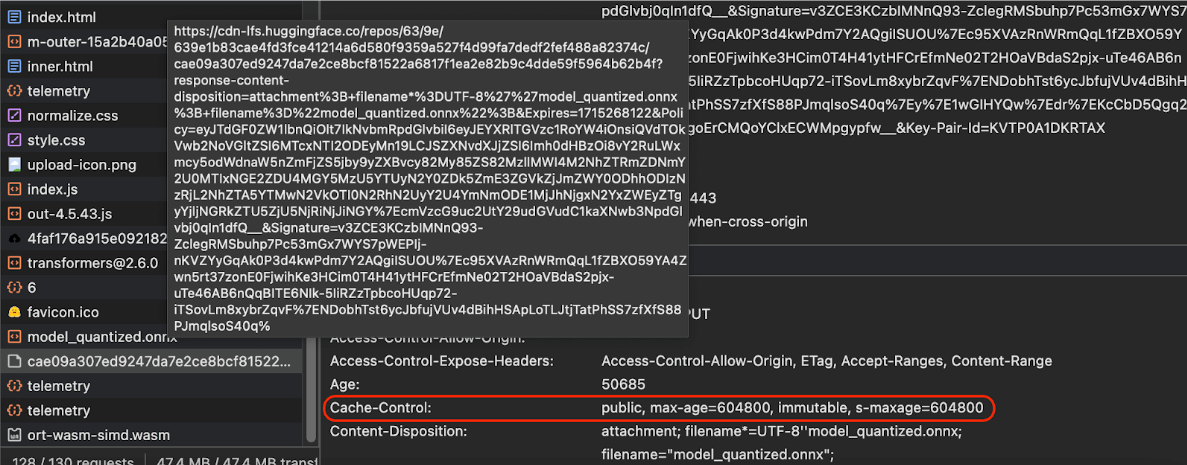
Cache-Control
हेडर दिखाता है.
(सोर्स)
एआई मॉडल को क्लाइंट-साइड पर कैश मेमोरी में सेव करना
एआई मॉडल को सर्व करते समय, मॉडल को ब्राउज़र में साफ़ तौर पर कैश मेमोरी में सेव करना ज़रूरी है. इससे यह पक्का होता है कि उपयोगकर्ता के ऐप्लिकेशन को फिर से लोड करने के बाद, मॉडल का डेटा तुरंत उपलब्ध हो जाए.
ऐसा करने के लिए, कई तकनीकों का इस्तेमाल किया जा सकता है. यहां दिए गए कोड के उदाहरणों के लिए, मान लें कि हर मॉडल फ़ाइल को मेमोरी में blob नाम के Blob ऑब्जेक्ट में सेव किया गया है.
परफ़ॉर्मेंस को समझने के लिए, हर कोड सैंपल को performance.mark() और performance.measure() तरीकों से एनोटेट किया गया है. ये तरीके, डिवाइस पर निर्भर होते हैं और इन्हें सामान्य तौर पर लागू नहीं किया जा सकता.

ब्राउज़र में एआई मॉडल को कैश मेमोरी में सेव करने के लिए, इनमें से किसी एक एपीआई का इस्तेमाल किया जा सकता है: Cache API, Origin Private File System API, और IndexedDB API. हमारा सुझाव है कि Cache API का इस्तेमाल करें. हालांकि, इस गाइड में सभी विकल्पों के फ़ायदे और नुकसान के बारे में बताया गया है.
Cache API
Cache API, Request और Response ऑब्जेक्ट पेयर के लिए परसिस्टेंट स्टोरेज उपलब्ध कराता है. ये ऑब्जेक्ट पेयर, लंबे समय तक चलने वाली मेमोरी में कैश किए जाते हैं. हालांकि, इसे Service Workers स्पेसिफ़िकेशन में तय किया गया है, लेकिन इस एपीआई का इस्तेमाल मुख्य थ्रेड या रेगुलर वर्कर से किया जा सकता है. इसे सर्विस वर्कर के कॉन्टेक्स्ट से बाहर इस्तेमाल करने के लिए, सिंथेटिक Response ऑब्जेक्ट के साथ Cache.put() तरीके को कॉल करें. इसे Request ऑब्जेक्ट के बजाय, सिंथेटिक यूआरएल के साथ जोड़ा जाता है.
इस गाइड में, इन-मेमोरी blob का इस्तेमाल किया गया है. कैश मेमोरी की कुंजी के तौर पर फ़र्ज़ी यूआरएल का इस्तेमाल करें. साथ ही, blob के आधार पर सिंथेटिक Response का इस्तेमाल करें. अगर आपको मॉडल सीधे तौर पर डाउनलोड करना है, तो आपको Response का इस्तेमाल करना होगा. यह fetch() अनुरोध करने पर मिलेगा.
उदाहरण के लिए, यहां Cache API की मदद से मॉडल फ़ाइल को सेव करने और वापस लाने का तरीका बताया गया है.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
ओरिजिन प्राइवेट फ़ाइल सिस्टम (ओपीएफ़एस), स्टोरेज एंडपॉइंट के लिए एक नया स्टैंडर्ड है. यह पेज के ऑरिजिन के लिए निजी होता है. इसलिए, यह उपयोगकर्ता को नहीं दिखता. हालांकि, सामान्य फ़ाइल सिस्टम में ऐसा नहीं होता. यह एक खास फ़ाइल को ऐक्सेस करने की सुविधा देता है. इस फ़ाइल को परफ़ॉर्मेंस के लिए काफ़ी हद तक ऑप्टिमाइज़ किया गया है. साथ ही, इसके कॉन्टेंट को लिखने की सुविधा भी मिलती है.
उदाहरण के लिए, यहां बताया गया है कि OPFS में मॉडल फ़ाइल को कैसे सेव और वापस लाया जा सकता है.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB, ब्राउज़र में किसी भी तरह के डेटा को लगातार सेव करने का एक स्टैंडर्ड तरीका है. यह अपने कुछ हद तक जटिल एपीआई के लिए कुख्यात है. हालांकि, idb-keyval जैसी रैपर लाइब्रेरी का इस्तेमाल करके, IndexedDB को क्लासिक की-वैल्यू स्टोर की तरह इस्तेमाल किया जा सकता है.
उदाहरण के लिए:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
स्टोरेज को 'बनाए रखा गया' के तौर पर मार्क करना
इनमें से किसी भी कैश मेमोरी को सेव करने के तरीके के आखिर में, navigator.storage.persist() को कॉल करें, ताकि परसिस्टेंट स्टोरेज का इस्तेमाल करने की अनुमति मांगी जा सके. यह तरीका एक प्रॉमिस दिखाता है. अगर अनुमति दी जाती है, तो यह true पर रिज़ॉल्व होता है. अगर अनुमति नहीं दी जाती है, तो यह false पर रिज़ॉल्व होता है. ब्राउज़र के नियमों के हिसाब से, ब्राउज़र अनुरोध को स्वीकार कर भी सकता है और नहीं भी.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
खास मामला: हार्ड डिस्क पर मौजूद मॉडल का इस्तेमाल करना
ब्राउज़र स्टोरेज के विकल्प के तौर पर, किसी उपयोगकर्ता की हार्ड डिस्क से सीधे तौर पर एआई मॉडल का रेफ़रंस दिया जा सकता है. इस तकनीक से, रिसर्च पर फ़ोकस करने वाले ऐप्लिकेशन को यह दिखाने में मदद मिल सकती है कि ब्राउज़र में दिए गए मॉडल को चलाना मुमकिन है या नहीं. इसके अलावा, इससे कलाकारों को क्रिएटिविटी से जुड़े ऐप्लिकेशन में, खुद से ट्रेन किए गए मॉडल इस्तेमाल करने की अनुमति मिल सकती है.
फ़ाइल सिस्टम को ऐक्सेस करने का एपीआई
File System Access API की मदद से, हार्ड डिस्क से फ़ाइलें खोली जा सकती हैं. साथ ही, FileSystemFileHandle हासिल किया जा सकता है, जिसे IndexedDB में सेव किया जा सकता है.
इस पैटर्न में, उपयोगकर्ता को मॉडल फ़ाइल का ऐक्सेस सिर्फ़ एक बार देना होता है. अनुमतियों को सेव करने की सुविधा की मदद से, उपयोगकर्ता के पास फ़ाइल का ऐक्सेस हमेशा के लिए देने का विकल्प होता है. ऐप्लिकेशन को फिर से लोड करने और उपयोगकर्ता के ज़रूरी जेस्चर, जैसे कि माउस क्लिक के बाद, FileSystemFileHandle को IndexedDB से वापस लाया जा सकता है. साथ ही, हार्ड डिस्क पर मौजूद फ़ाइल को ऐक्सेस किया जा सकता है.
अगर ज़रूरी हो, तो फ़ाइल ऐक्सेस करने की अनुमतियों के बारे में पूछा जाता है और उनके लिए अनुरोध किया जाता है. इससे, आने वाले समय में फ़ाइल को फिर से लोड करने में आसानी होती है. यहां दिए गए उदाहरण में, हार्ड डिस्क से किसी फ़ाइल का हैंडल पाने का तरीका बताया गया है. इसके बाद, हैंडल को सेव और वापस लाने का तरीका बताया गया है.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
ये तरीके एक-दूसरे से अलग नहीं हैं. ऐसा हो सकता है कि आपने ब्राउज़र में किसी मॉडल को साफ़ तौर पर कैश मेमोरी में सेव किया हो और उपयोगकर्ता की हार्ड डिस्क से किसी मॉडल का इस्तेमाल किया हो.
डेमो
MediaPipe LLM डेमो में, केस को सेव करने के तीन सामान्य तरीके और हार्ड डिस्क का इस्तेमाल करने का तरीका दिखाया गया है.
बोनस: किसी बड़ी फ़ाइल को हिस्सों में डाउनलोड करना
अगर आपको इंटरनेट से कोई बड़ा एआई मॉडल डाउनलोड करना है, तो डाउनलोड को अलग-अलग हिस्सों में बांटें. इसके बाद, क्लाइंट पर उन्हें फिर से एक साथ जोड़ें.
पैकेज fetch-in-chunks एक हेल्पर फ़ंक्शन उपलब्ध कराता है, जिसका इस्तेमाल अपने कोड में किया जा सकता है. आपको सिर्फ़ url पास करना होगा. maxParallelRequests (डिफ़ॉल्ट: 6), chunkSize
(डिफ़ॉल्ट: डाउनलोड की जाने वाली फ़ाइल का साइज़, maxParallelRequests से भाग देने पर मिलने वाली संख्या), progressCallback फ़ंक्शन (जो downloadedBytes और कुल fileSize के बारे में बताता है), और AbortSignal सिग्नल के लिए signal, ये सभी पैरामीटर ज़रूरी नहीं हैं.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
अपनी ज़रूरत के हिसाब से सही तरीका चुनें
इस गाइड में, ब्राउज़र में एआई मॉडल को असरदार तरीके से कैश मेमोरी में सेव करने के अलग-अलग तरीकों के बारे में बताया गया है. यह काम, आपके ऐप्लिकेशन की परफ़ॉर्मेंस को बेहतर बनाने और उपयोगकर्ता के अनुभव को बेहतर बनाने के लिए ज़रूरी है. Chrome स्टोरेज टीम, बेहतर परफ़ॉर्मेंस के लिए Cache API का इस्तेमाल करने का सुझाव देती है. इससे एआई मॉडल को तुरंत ऐक्सेस किया जा सकता है, लोड होने में लगने वाला समय कम हो जाता है, और रिस्पॉन्स देने की क्षमता बेहतर हो जाती है.
OPFS और IndexedDB, कम इस्तेमाल किए जाने वाले विकल्प हैं. OPFS और IndexedDB API को डेटा सेव करने से पहले, उसे क्रम से लगाना होता है. IndexedDB को डेटा वापस पाने के लिए, उसे डीसीरियलाइज़ भी करना पड़ता है. इसलिए, बड़े मॉडल को सेव करने के लिए यह सबसे खराब जगह है.
खास ऐप्लिकेशन के लिए, फ़ाइल सिस्टम ऐक्सेस एपीआई, उपयोगकर्ता के डिवाइस पर मौजूद फ़ाइलों को सीधे तौर पर ऐक्सेस करने की सुविधा देता है. यह उन उपयोगकर्ताओं के लिए सबसे सही है जो अपने एआई मॉडल मैनेज करते हैं.
अगर आपको अपने एआई मॉडल को सुरक्षित रखना है, तो उसे सर्वर पर रखें. क्लाइंट पर सेव होने के बाद, DevTools या OFPS DevTools एक्सटेंशन की मदद से, कैश मेमोरी और IndexedDB, दोनों से डेटा निकालना आसान होता है. ये स्टोरेज एपीआई, सुरक्षा के मामले में एक जैसे होते हैं. आपके पास मॉडल के एन्क्रिप्ट (सुरक्षित) किए गए वर्शन को सेव करने का विकल्प होता है. हालांकि, इसके बाद आपको क्लाइंट को डिक्रिप्ट (सुरक्षित) करने की कुंजी देनी होगी. इसे इंटरसेप्ट किया जा सकता है. इसका मतलब है कि बुरे इरादे से काम करने वाले व्यक्ति के लिए, आपके मॉडल को चुराने की कोशिश करना थोड़ा मुश्किल हो जाएगा. हालांकि, ऐसा करना पूरी तरह से नामुमकिन नहीं होगा.
हमारा सुझाव है कि आप ऐसी कैश मेमोरी की रणनीति चुनें जो आपके ऐप्लिकेशन की ज़रूरतों, टारगेट ऑडियंस के व्यवहार, और इस्तेमाल किए गए एआई मॉडल की विशेषताओं के मुताबिक हो. इससे यह पक्का किया जाता है कि आपके ऐप्लिकेशन, नेटवर्क की अलग-अलग स्थितियों और सिस्टम की सीमाओं के हिसाब से रिस्पॉन्सिव और मज़बूत हों.
Acknowledgements
इसकी समीक्षा जोशुआ बेल, रेली ग्रांट, इवान स्टेड, नेथन मेमॉट, ऑस्टिन सुलिवन, एटियेन नोएल, आंद्रे बंदारा, एलेक्ज़ेंड्रा क्लेपर, फ़्रांस्वा बोफ़ोर्ट, पॉल किनलन, और राशेल ऐंड्र्यू ने की है.