


Data publikacji: 12 marca 2025 r., ostatnia aktualizacja: 28 maja 2025 r.
| Wyjaśnienie | Sieć | Rozszerzenia | Stan Chrome | Intencja |
|---|---|---|---|---|
| MDN | Wyświetl | Zamiar wysłania |
Interfejs Summarizer API pomaga generować podsumowania informacji o różnej długości i w różnych formatach. Używaj go z modelem podstawowym w Chrome lub innymi modelami językowymi wbudowanymi w przeglądarki, aby zwięźle wyjaśniać długie lub skomplikowane teksty.
Gdy jest wykonywane po stronie klienta, możesz pracować z danymi lokalnie, co pozwala zachować bezpieczeństwo danych wrażliwych i zapewnić dostępność na dużą skalę. Jednak okno kontekstowe jest znacznie mniejsze niż w przypadku modeli po stronie serwera, co oznacza, że podsumowywanie bardzo dużych dokumentów może być trudne. Aby rozwiązać ten problem, możesz użyć techniki podsumowania podsumowań.
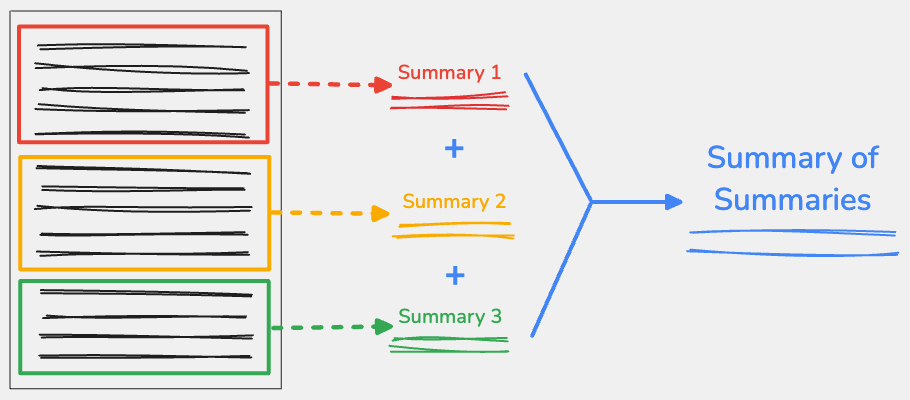
Czym jest podsumowanie podsumowań?
Aby użyć techniki podsumowania podsumowań, podziel treść wejściową na kluczowe punkty, a następnie podsumuj każdą część osobno. Możesz połączyć wyniki z każdej części, a następnie podsumować połączony tekst w jedno podsumowanie końcowe.
Rozważne dzielenie treści
Ważne jest, aby zastanowić się, jak podzielić duży fragment tekstu, ponieważ różne strategie mogą prowadzić do różnych wyników w przypadku dużych modeli językowych. Tekst należy dzielić, gdy zmienia się temat, np. w nowej sekcji artykułu lub na końcu akapitu. Ważne jest, aby nie dzielić tekstu w środku słowa lub zdania, co oznacza, że nie możesz używać liczby znaków jako jedynej wytycznej podziału.
Możesz to zrobić na wiele sposobów. W poniższym przykładzie użyliśmy rekurencyjnego rozdzielacza tekstu z biblioteki LangChain.js, który zapewnia równowagę między wydajnością a jakością danych wyjściowych. Powinno to działać w przypadku większości zadań.
Przy tworzeniu nowej instancji należy określić 2 kluczowe parametry:
chunkSizeto maksymalna dozwolona liczba znaków w każdym podziale.chunkOverlapto liczba znaków, które mają się nakładać między dwoma kolejnymi podziałami. Dzięki temu każdy fragment zawiera część kontekstu z poprzedniego fragmentu.
Podziel tekst za pomocą znaku splitText(), aby zwrócić tablicę ciągów znaków z poszczególnymi fragmentami.
Większość LLM ma okno kontekstu wyrażone jako liczba tokenów, a nie liczba znaków. Średnio token zawiera 4 znaki. W naszym przykładzie chunkSize ma 3000 znaków, co daje około 750 tokenów.
Określanie dostępności tokena
Aby określić liczbę tokenów dostępnych do użycia w danych wejściowych, użyj metody measureInputUsage() i właściwości inputQuota. W tym przypadku wdrożenie jest nieograniczone, ponieważ nie można przewidzieć, ile razy narzędzie do podsumowywania będzie musiało przetworzyć cały tekst.
Generowanie podsumowań dla każdego podziału
Po skonfigurowaniu sposobu podziału treści możesz wygenerować podsumowania każdej części za pomocą interfejsu Summarizer API.
Utwórz instancję narzędzia do podsumowywania za pomocą funkcji create(). Aby zachować jak najwięcej kontekstu, ustawiliśmy parametr format na plain-text, type na tldr i length na long.
Następnie wygeneruj podsumowanie dla każdego podziału utworzonego przez funkcję
RecursiveCharacterTextSplitter i połącz wyniki w nowy ciąg znaków.
Każde podsumowanie zostało oddzielone nowym wierszem, aby można było łatwo zidentyfikować podsumowanie każdej części.
Ta nowa linia nie ma znaczenia, gdy pętla jest wykonywana tylko raz, ale jest przydatna do określania, w jaki sposób każde podsumowanie zwiększa wartość tokena w przypadku podsumowania końcowego. W większości przypadków to rozwiązanie powinno działać w przypadku średnich i długich treści.
Rekurencyjne podsumowanie podsumowań
Jeśli masz bardzo długi tekst, długość połączonego podsumowania może być większa niż dostępne okno kontekstu, co spowoduje niepowodzenie podsumowania. Aby rozwiązać ten problem, możesz rekurencyjnie podsumowywać podsumowania.
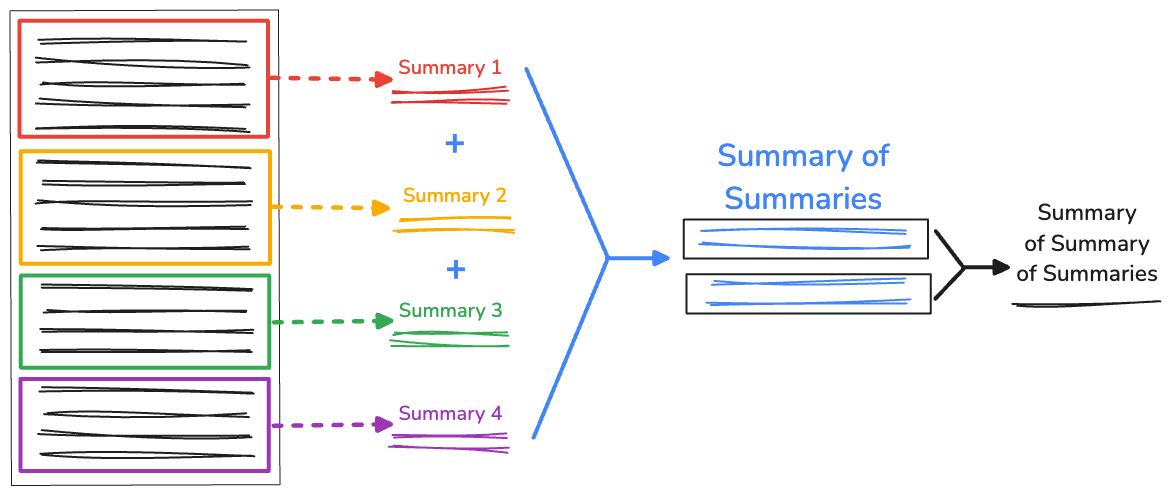
Nadal zbieramy wstępne podziały wygenerowane przez RecursiveCharacterTextSplitter. Następnie w funkcji recursiveSummarizer() powtarzamy proces podsumowywania na podstawie długości znaków połączonych fragmentów. Jeśli długość znaków w podsumowaniach przekracza 3000, łączymy je w fullSummaries. Jeśli limit nie zostanie osiągnięty, podsumowanie zostanie zapisane jako partialSummaries.
Gdy wszystkie podsumowania zostaną wygenerowane, ostateczne podsumowania częściowe zostaną dodane do pełnego podsumowania. Jeśli w fullSummaries jest tylko 1 podsumowanie, nie jest potrzebna dodatkowa rekurencja. Funkcja zwraca ostateczne podsumowanie. Jeśli jest więcej niż jedno podsumowanie, funkcja powtarza się i kontynuuje podsumowywanie częściowych podsumowań.
Przetestowaliśmy to rozwiązanie na RFC dotyczącym protokołu IRC, który zawiera aż 110 030 znaków, w tym 17 560 słów. Interfejs Summarizer API podał to podsumowanie:
Internet Relay Chat (IRC) to sposób komunikacji online w czasie rzeczywistym za pomocą wiadomości tekstowych. Możesz rozmawiać na kanałach lub wysyłać wiadomości prywatne, a także używać poleceń do sterowania czatem i interakcji z serwerem. To jak czat w internecie, na którym możesz pisać i natychmiast widzieć wiadomości innych osób.
To całkiem skuteczne. Ma tylko 309 znaków.
Ograniczenia
Technika podsumowania podsumowań pomaga działać w ramach okna kontekstu modelu o rozmiarze klienta. Chociaż AI po stronie klienta ma wiele zalet, możesz napotkać te problemy:
- Mniej dokładne podsumowania: w przypadku rekursji powtarzanie procesu podsumowywania może być nieskończone, a każde podsumowanie jest coraz bardziej oddalone od oryginalnego tekstu. Oznacza to, że model może wygenerować zbyt ogólne podsumowanie, które nie będzie przydatne.
- Wolniejsze działanie: wygenerowanie każdego podsumowania zajmuje trochę czasu. W przypadku dłuższych tekstów, w których można utworzyć nieskończenie wiele podsumowań, ukończenie tego procesu może potrwać kilka minut.
Dostępna jest wersja demonstracyjna narzędzia do podsumowywania, a pełny kod źródłowy możesz wyświetlić.
Prześlij opinię
Wypróbuj technikę podsumowania podsumowań z tekstem wejściowym o różnej długości, różnymi rozmiarami podziału i różnymi długościami nakładania się, korzystając z interfejsu Summarizer API.
- Jeśli chcesz przesłać opinię na temat implementacji Chrome, zgłoś błąd lub poproś o dodanie funkcji.
- Zapoznaj się z dokumentacją w MDN
- Porozmawiaj z zespołem AI w Chrome o procesie podsumowywania lub innych pytaniach dotyczących wbudowanej AI.