


Publié le 12 mars 2025, dernière mise à jour le 28 mai 2025
| Présentateur | Web | Extensions | État de Chrome | Intention |
|---|---|---|---|---|
| MDN | Afficher | Intention d'expédier |
L'API Summarizer vous aide à générer des résumés d'informations de différentes longueurs et dans différents formats. Utilisez-le avec le modèle de fondation dans Chrome ou d'autres modèles de langage intégrés aux navigateurs pour expliquer de manière concise des textes longs ou complexes.
Lorsqu'il est effectué côté client, vous pouvez travailler avec des données en local, ce qui vous permet de protéger les données sensibles et d'offrir une disponibilité à grande échelle. Toutefois, la fenêtre de contexte est beaucoup plus petite qu'avec les modèles côté serveur, ce qui signifie qu'il peut être difficile de résumer des documents très volumineux. Pour résoudre ce problème, vous pouvez utiliser la technique de résumé des résumés.
Qu'est-ce qu'un résumé de résumés ?
Pour utiliser la technique du résumé des résumés, divisez le contenu d'entrée en points clés, puis résumez chaque partie indépendamment. Vous pouvez concaténer les sorties de chaque partie, puis résumer ce texte concaténé en un résumé final.
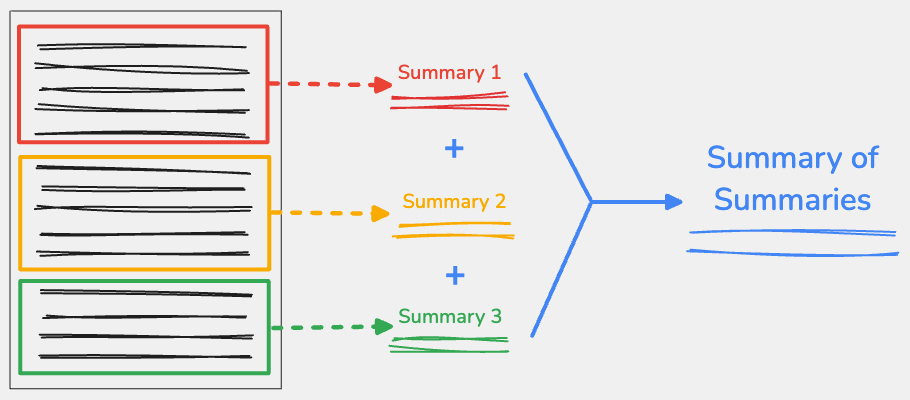
Répartissez judicieusement votre contenu
Il est important de réfléchir à la manière dont vous allez diviser un long texte, car différentes stratégies peuvent entraîner des résultats différents selon les LLM. Dans l'idéal, le texte doit être divisé lorsqu'il y a un changement de sujet, par exemple une nouvelle section d'un article ou un nouveau paragraphe. Il est important d'éviter de scinder le texte au milieu d'un mot ou d'une phrase. Vous ne pouvez donc pas utiliser le nombre de caractères comme seule règle de fractionnement.
Pour ce faire, vous pouvez utiliser différentes méthodes. Dans l'exemple suivant, nous avons utilisé le Recursive Text Splitter de LangChain.js, qui équilibre les performances et la qualité de la sortie. Cela devrait fonctionner pour la plupart des charges de travail.
Lorsque vous créez une instance, deux paramètres clés sont à prendre en compte :
chunkSizeest le nombre maximal de caractères autorisé dans chaque fraction.chunkOverlapcorrespond au nombre de caractères à chevaucher entre deux fractionnements consécutifs. Cela garantit que chaque bloc contient une partie du contexte du bloc précédent.
Divisez le texte avec splitText() pour renvoyer un tableau de chaînes avec chaque bloc.
La fenêtre de contexte de la plupart des LLM est exprimée en nombre de jetons plutôt qu'en nombre de caractères. En moyenne, un jeton contient quatre caractères. Dans notre exemple, chunkSize comporte 3 000 caractères, ce qui correspond à environ 750 jetons.
Déterminer la disponibilité des jetons
Pour déterminer le nombre de jetons disponibles pour une entrée, utilisez la méthode measureInputUsage() et la propriété inputQuota. Dans ce cas, l'implémentation est illimitée, car vous ne pouvez pas savoir combien de fois le résumeur s'exécutera pour traiter tout le texte.
Générer des résumés pour chaque fraction
Une fois que vous avez configuré la façon dont le contenu est divisé, vous pouvez générer des résumés pour chaque partie avec l'API Summarizer.
Créez une instance du résumeur avec la fonction create(). Pour conserver le plus de contexte possible, nous avons défini le paramètre format sur plain-text, type sur tldr et length sur long.
Générez ensuite le résumé pour chaque fraction créée par RecursiveCharacterTextSplitter et concaténez les résultats dans une nouvelle chaîne.
Nous avons séparé chaque résumé par une nouvelle ligne pour identifier clairement le résumé de chaque partie.
Cette nouvelle ligne n'a pas d'importance lorsque cette boucle n'est exécutée qu'une seule fois, mais elle est utile pour déterminer comment chaque récapitulatif contribue à la valeur en jetons du récapitulatif final. Dans la plupart des cas, cette solution devrait fonctionner pour les contenus de taille moyenne et longue.
Résumé récursif des résumés
Lorsque vous avez une quantité de texte extrêmement longue, la longueur du résumé concaténé peut être supérieure à la fenêtre de contexte disponible, ce qui entraîne l'échec de la synthèse. Pour résoudre ce problème, vous pouvez résumer les résumés de manière récursive.
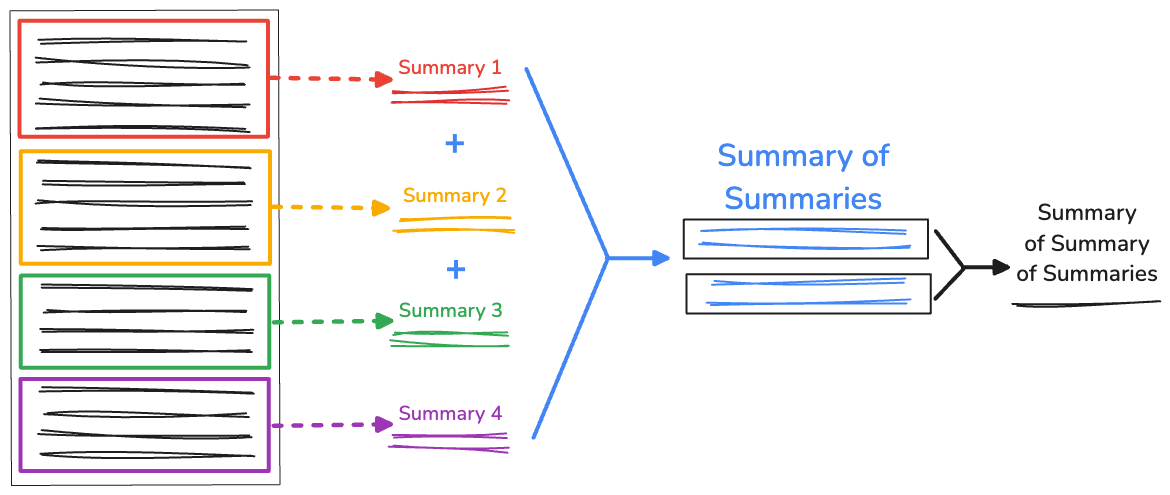
Nous continuons de collecter les divisions initiales générées par RecursiveCharacterTextSplitter. Ensuite, dans la fonction recursiveSummarizer(), nous bouclons le processus de synthèse en fonction de la longueur des caractères des divisions concaténées. Si la longueur des résumés en caractères dépasse 3000, nous les concaténons en fullSummaries. Si la limite n'est pas atteinte, le résumé est enregistré sous le nom partialSummaries.
Une fois tous les résumés partiels générés, ils sont ajoutés au résumé complet. S'il n'y a qu'un seul résumé dans fullSummaries, aucune récursivité supplémentaire n'est nécessaire. La fonction renvoie un récapitulatif final. S'il existe plusieurs résumés, la fonction se répète et continue de résumer les résumés partiels.
Nous avons testé cette solution avec la RFC Internet Relay Chat (IRC), qui contient pas moins de 110 030 caractères, dont 17 560 mots. L'API Summarizer a fourni le résumé suivant :
Internet Relay Chat (IRC) est un moyen de communiquer en ligne en temps réel à l'aide de messages texte. Vous pouvez discuter dans des chaînes ou envoyer des messages privés, et vous pouvez utiliser des commandes pour contrôler la discussion et interagir avec le serveur. C'est comme un salon de discussion sur Internet où vous pouvez taper des messages et voir ceux des autres utilisateurs instantanément.
C'est plutôt efficace ! Et il ne comporte que 309 caractères.
Limites
La technique de résumé des résumés vous aide à opérer dans la fenêtre de contexte d'un modèle de taille client. Bien que l'IA côté client présente de nombreux avantages, vous pouvez rencontrer les problèmes suivants :
- Résumés moins précis : avec la récursivité, la répétition du processus de résumé est potentiellement infinie, et chaque résumé s'éloigne de plus en plus du texte d'origine. Cela signifie que le modèle peut générer un résumé final trop superficiel pour être utile.
- Performances plus lentes : la génération de chaque résumé prend du temps. Là encore, comme le nombre de résumés possibles est infini dans les textes longs, cette approche peut prendre plusieurs minutes.
Une démonstration du résumeur est disponible. Vous pouvez également consulter le code source complet.
Envoyer des commentaires
Essayez d'utiliser la technique de résumé des résumés avec différentes longueurs de texte d'entrée, différentes tailles de fractionnement et différentes longueurs de chevauchement, avec l'API Summarizer.
- Pour envoyer des commentaires sur l'implémentation de Chrome, signalez un bug ou demandez une fonctionnalité.
- Consultez la documentation sur MDN.
- Discutez avec l'équipe Chrome IA de votre processus de synthèse ou de toute autre question concernant l'IA intégrée.