


Pubblicato: 12 marzo 2025, ultimo aggiornamento: 28 maggio 2025
| Spiegazione | Web | Estensioni | Stato di Chrome | Intenzione |
|---|---|---|---|---|
| MDN | Visualizza | Intenzione di spedizione |
L'API Summarizer ti aiuta a generare riepiloghi di informazioni in varie lunghezze e formati. Utilizzalo con il modello di base in Chrome o con altri modelli linguistici integrati nei browser per spiegare in modo conciso testi lunghi o complicati.
Se eseguita lato client, puoi lavorare con i dati in locale, il che ti consente di mantenere al sicuro i dati sensibili e di offrire disponibilità su larga scala. Tuttavia, la finestra di contesto è molto più piccola rispetto ai modelli lato server, il che significa che i documenti molto grandi potrebbero essere difficili da riassumere. Per risolvere questo problema, puoi utilizzare la tecnica del riepilogo dei riepiloghi.
Che cos'è il riepilogo dei riepiloghi?
Per utilizzare la tecnica del riassunto dei riassunti, dividi i contenuti di input in punti chiave, quindi riassumi ogni parte in modo indipendente. Puoi concatenare gli output di ogni parte, quindi riassumere questo testo concatenato in un unico riepilogo finale.
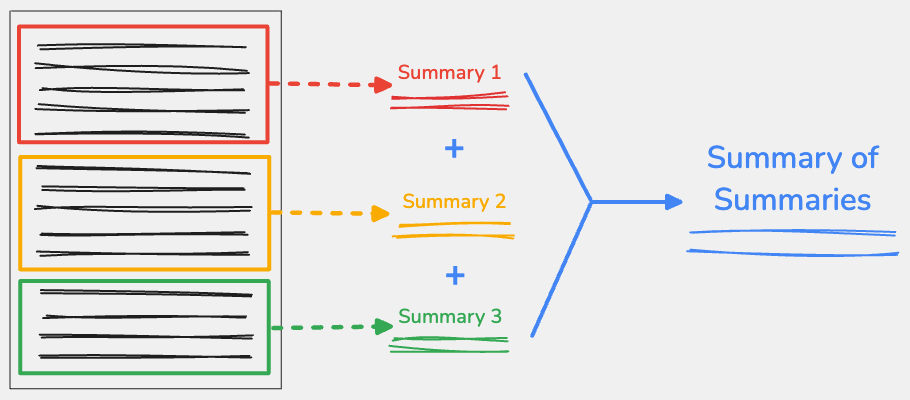
Dividere i contenuti in modo ponderato
È importante considerare come dividere un testo lungo, in quanto strategie diverse possono portare a risultati diversi nei vari LLM. Idealmente, il testo deve essere suddiviso quando cambia l'argomento, ad esempio in una nuova sezione di un articolo o in un paragrafo. È importante evitare di dividere il testo a metà di una parola o di una frase, il che significa che non puoi utilizzare un conteggio dei caratteri come unica linea guida per la suddivisione.
Esistono molti modi per farlo. Nel seguente esempio, abbiamo utilizzato lo strumento di suddivisione del testo ricorsivo di LangChain.js, che bilancia prestazioni e qualità dell'output. Questa soluzione dovrebbe funzionare per la maggior parte dei carichi di lavoro.
Quando crei una nuova istanza, ci sono due parametri chiave:
chunkSizeè il numero massimo di caratteri consentiti in ogni suddivisione.chunkOverlapè la quantità di caratteri da sovrapporre tra due divisioni consecutive. In questo modo, ogni blocco contiene parte del contesto del blocco precedente.
Dividi il testo con splitText() per restituire una matrice di stringhe con ogni blocco.
La finestra contestuale della maggior parte degli LLM è espressa come numero di token, anziché
come numero di caratteri. In media, un token contiene 4 caratteri. Nel nostro
esempio, chunkSize è composto da 3000 caratteri, ovvero circa
750 token.
Determinare la disponibilità dei token
Per determinare il numero di token disponibili per un input, utilizza il metodo
measureInputUsage()
e la proprietà inputQuota. In questo caso, l'implementazione è illimitata, in quanto non puoi sapere
quante volte verrà eseguito il riepilogo per elaborare tutto il testo.
Generare riepiloghi per ogni divisione
Una volta configurata la suddivisione dei contenuti, puoi generare riepiloghi per ogni parte con l'API Summarizer.
Crea un'istanza del riepilogatore con la
funzione create(). Per mantenere il maggior numero possibile di
contesto, abbiamo impostato il parametro format su plain-text, type
su tldr
e length su long.
Quindi, genera il riepilogo per ogni suddivisione creata da
RecursiveCharacterTextSplitter e concatena i risultati in una nuova stringa.
Abbiamo separato ogni riepilogo con una nuova riga per identificare chiaramente il riepilogo di
ogni parte.
Sebbene questa nuova riga non sia importante quando si esegue questo ciclo una sola volta, è utile per determinare in che modo ogni riepilogo contribuisce al valore del token per il riepilogo finale. Nella maggior parte dei casi, questa soluzione dovrebbe funzionare per i contenuti di media e lunga durata.
Riepilogo ricorsivo dei riepiloghi
Quando hai una quantità di testo eccessivamente lunga, la lunghezza del riepilogo concatenato potrebbe essere maggiore della finestra contestuale disponibile, causando il mancato riepilogo. Per risolvere il problema, puoi riassumere in modo ricorsivo i riepiloghi.
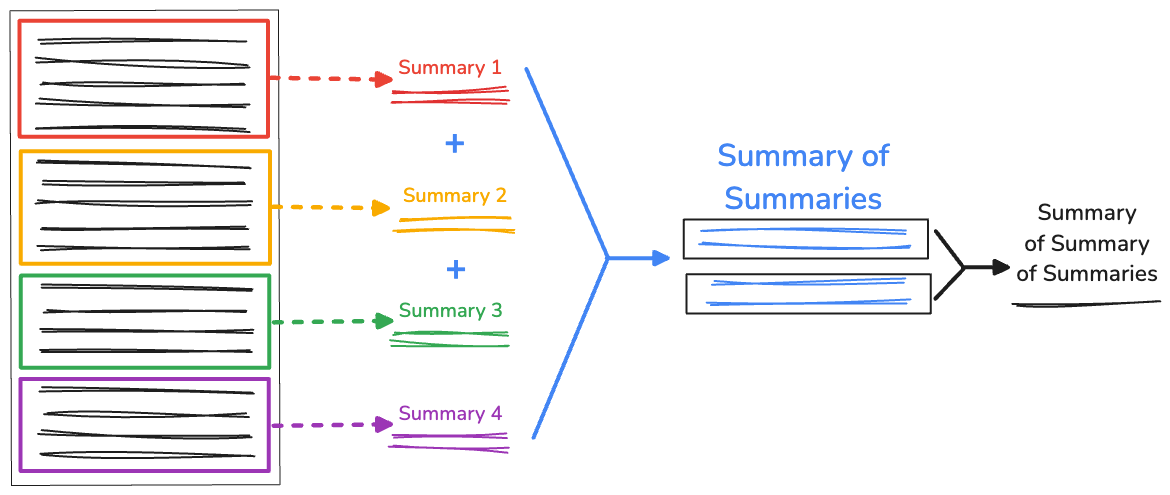
Continuiamo a raccogliere gli split iniziali generati da
RecursiveCharacterTextSplitter. Poi, nella funzione recursiveSummarizer(),
eseguiamo un ciclo del processo di riepilogo in base alla lunghezza in caratteri delle
divisioni concatenate. Se la lunghezza dei caratteri dei riepiloghi supera 3000,
vengono concatenati in fullSummaries. Se il limite non viene raggiunto, il riepilogo viene salvato come partialSummaries.
Una volta generati tutti i riepiloghi, i riepiloghi parziali finali vengono aggiunti
al riepilogo completo. Se in fullSummaries è presente un solo riepilogo, non è necessaria
un'ulteriore ricorsione. La funzione restituisce un riepilogo finale. Se è presente più di un riepilogo, la funzione si ripete e continua a riepilogare i riepiloghi parziali.
Abbiamo testato questa soluzione con Internet Relay Chat (IRC) RFC, che contiene ben 110.030 caratteri, tra cui 17.560 parole. L'API Summarizer ha fornito il seguente riepilogo:
Internet Relay Chat (IRC) è un modo per comunicare online in tempo reale utilizzando messaggi di testo. Puoi chattare nei canali o inviare messaggi privati e utilizzare i comandi per controllare la chat e interagire con il server. È come una chat su internet in cui puoi digitare e vedere immediatamente i messaggi degli altri.
È piuttosto efficace. Inoltre, contiene solo 309 caratteri.
Limitazioni
La tecnica del riepilogo dei riepiloghi ti aiuta a operare all'interno della finestra contestuale di un modello di dimensioni client. Sebbene l'AI lato client offra molti vantaggi, potresti riscontrare i seguenti problemi:
- Riepiloghi meno accurati: con la ricorsione, la ripetizione del processo di riepilogo è potenzialmente infinita e ogni riepilogo è più lontano dal testo originale. Ciò significa che il modello potrebbe generare un riepilogo finale troppo superficiale per essere utile.
- Rendimento più lento: la generazione di ogni riepilogo richiede tempo. Anche in questo caso, con un numero infinito di riepiloghi possibili in testi più lunghi, questo approccio potrebbe richiedere diversi minuti per essere completato.
Abbiamo a disposizione una demo di riepilogo e puoi visualizzare il codice sorgente completo.
Condividi il tuo feedback
Prova a utilizzare la tecnica del riepilogo dei riepiloghi con input di testo di diversa lunghezza, diverse dimensioni di suddivisione e diverse lunghezze di sovrapposizione con l'API Summarizer.
- Per inviare feedback sull'implementazione di Chrome, compila una segnalazione di bug o una richiesta di funzionalità.
- Leggi la documentazione su MDN
- Contatta il team di Chrome AI per informazioni sul processo di riepilogo o su qualsiasi altra domanda sull'AI integrata.