


पब्लिश करने की तारीख: 12 मार्च, 2025, पिछली बार अपडेट करने की तारीख: 28 मई, 2025
| ज़्यादा जानकारी देने वाला वीडियो | वेब | एक्सटेंशन | Chrome स्टेटस | मकसद |
|---|---|---|---|---|
| एमडीएन | देखें | शिपिंग की इच्छा |
Summarizer API की मदद से, अलग-अलग लंबाई और फ़ॉर्मैट में जानकारी की खास जानकारी जनरेट की जा सकती है. इसका इस्तेमाल Chrome में मौजूद फ़ाउंडेशन मॉडल या ब्राउज़र में पहले से मौजूद अन्य भाषा मॉडल के साथ करें. इससे लंबे या मुश्किल टेक्स्ट को कम शब्दों में समझाया जा सकता है.
क्लाइंट-साइड पर किए जाने वाले एन्क्रिप्शन से, डेटा को स्थानीय तौर पर प्रोसेस किया जा सकता है. इससे संवेदनशील डेटा को सुरक्षित रखा जा सकता है और इसे बड़े पैमाने पर उपलब्ध कराया जा सकता है. हालांकि, सर्वर साइड मॉडल की तुलना में कॉन्टेक्स्ट विंडो का साइज़ बहुत छोटा होता है. इसका मतलब है कि बहुत बड़े दस्तावेज़ों की खास जानकारी जनरेट करना मुश्किल हो सकता है. इस समस्या को हल करने के लिए, जवाबों की खास जानकारी देने वाली तकनीक का इस्तेमाल किया जा सकता है.
खास जानकारी की खास जानकारी क्या है?
अलग-अलग हिस्सों के सारांश बनाने की तकनीक का इस्तेमाल करने के लिए, इनपुट कॉन्टेंट को मुख्य बिंदुओं के हिसाब से अलग-अलग हिस्सों में बाँटें. इसके बाद, हर हिस्से का अलग-अलग सारांश बनाएँ. हर हिस्से से मिले आउटपुट को एक साथ जोड़ा जा सकता है. इसके बाद, इस जोड़े गए टेक्स्ट की खास जानकारी को एक फ़ाइनल जवाब में शामिल किया जा सकता है.
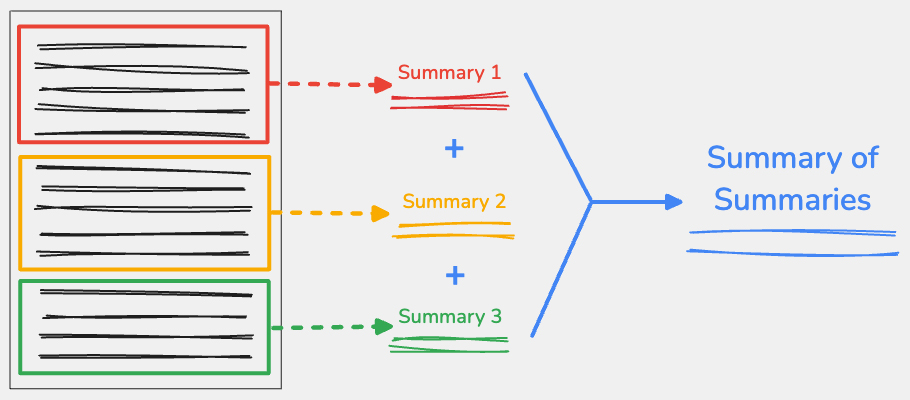
अपने कॉन्टेंट को सोच-समझकर अलग-अलग हिस्सों में बांटना
यह जानना ज़रूरी है कि बड़े टेक्स्ट को कैसे बांटा जाएगा, क्योंकि अलग-अलग रणनीतियों से एलएलएम के अलग-अलग आउटपुट मिल सकते हैं. टेक्स्ट को तब अलग-अलग हिस्सों में बांटना चाहिए, जब विषय बदल रहा हो. जैसे, लेख का नया सेक्शन या पैराग्राफ़. किसी शब्द या वाक्य के बीच में टेक्स्ट को न तोड़ना ज़रूरी है. इसका मतलब है कि सिर्फ़ वर्णों की संख्या के आधार पर टेक्स्ट को नहीं तोड़ा जा सकता.
ऐसा करने के कई तरीके हैं. नीचे दिए गए उदाहरण में, हमने LangChain.js से Recursive Text Splitter का इस्तेमाल किया है. यह परफ़ॉर्मेंस और आउटपुट क्वालिटी को बेहतर बनाता है. यह तरीका ज़्यादातर वर्कलोड के लिए काम करता है.
नया इंस्टेंस बनाते समय, दो मुख्य पैरामीटर होते हैं:
- हर स्प्लिट में ज़्यादा से ज़्यादा
chunkSizeवर्ण हो सकते हैं. chunkOverlap, दो लगातार स्प्लिट के बीच ओवरलैप होने वाले वर्णों की संख्या है. इससे यह पक्का होता है कि हर चंक में, पिछले चंक का कुछ कॉन्टेक्स्ट शामिल हो.
टेक्स्ट को splitText() से अलग करें, ताकि हर हिस्से के साथ स्ट्रिंग की एक कैटगरी दिखे.
ज़्यादातर एलएलएम की कॉन्टेक्स्ट विंडो को वर्णों की संख्या के बजाय, टोकन की संख्या के तौर पर दिखाया जाता है. औसतन, एक टोकन में चार वर्ण होते हैं. हमारे उदाहरण में, chunkSize 3,000 वर्णों का है और यह करीब 750 टोकन है.
टोकन की उपलब्धता का पता लगाना
किसी इनपुट के लिए कितने टोकन उपलब्ध हैं, यह पता लगाने के लिए measureInputUsage() तरीके और inputQuota प्रॉपर्टी का इस्तेमाल करें. इस मामले में, लागू करने की कोई सीमा नहीं है, क्योंकि आपको यह नहीं पता कि पूरे टेक्स्ट को प्रोसेस करने के लिए, खास जानकारी देने वाला टूल कितनी बार चलेगा.
हर स्प्लिट के लिए खास जानकारी जनरेट करना
कॉन्टेंट को अलग-अलग हिस्सों में बांटने का तरीका सेट अप करने के बाद, Summarizer API की मदद से हर हिस्से के लिए खास जानकारी जनरेट की जा सकती है.
create() फ़ंक्शन की मदद से, खास जानकारी देने वाले टूल का इंस्टेंस बनाएं. ज़्यादा से ज़्यादा कॉन्टेक्स्ट बनाए रखने के लिए, हमने format पैरामीटर को plain-text पर, type को tldr पर, और length को long पर सेट किया है.
इसके बाद, RecursiveCharacterTextSplitter से बनाए गए हर स्प्लिट के लिए खास जानकारी जनरेट करें और नतीजों को एक नई स्ट्रिंग में जोड़ें.
हमने हर जवाब को नई लाइन में लिखा है, ताकि हर हिस्से के जवाब को आसानी से पहचाना जा सके.
इस लूप को सिर्फ़ एक बार चलाने पर, इस नई लाइन से कोई फ़र्क़ नहीं पड़ता. हालांकि, यह इस बात का पता लगाने के लिए काम की है कि हर खास जानकारी, फ़ाइनल खास जानकारी के लिए टोकन वैल्यू में कैसे जुड़ती है. ज़्यादातर मामलों में, यह समाधान मध्यम और लंबी अवधि के कॉन्टेंट के लिए काम करना चाहिए.
खास जानकारी की खास जानकारी
अगर टेक्स्ट बहुत ज़्यादा लंबा है, तो हो सकता है कि कॉन्टेंट को जोड़कर बनाए गए जवाब की लंबाई, उपलब्ध कॉन्टेक्स्ट विंडो से ज़्यादा हो. इस वजह से, जवाब बनाने की प्रोसेस पूरी नहीं हो पाती. इसे ठीक करने के लिए, बार-बार जवाबों की खास जानकारी जनरेट की जा सकती है.
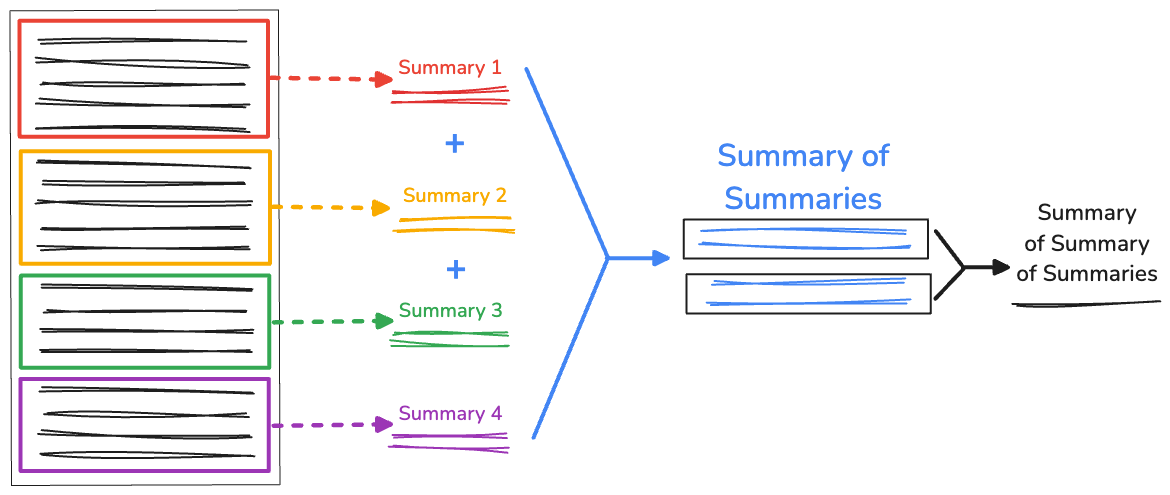
हम अब भी RecursiveCharacterTextSplitter से जनरेट किए गए शुरुआती स्प्लिट इकट्ठा करते हैं. इसके बाद, recursiveSummarizer() फ़ंक्शन में, हम एक साथ जोड़े गए स्प्लिट की वर्ण संख्या के आधार पर, खास जानकारी तैयार करने की प्रोसेस को लूप करते हैं. अगर जवाब में 3000 से ज़्यादा वर्ण हैं, तो हम उन्हें fullSummaries में जोड़ देते हैं. अगर सीमा पूरी नहीं हुई है, तो खास जानकारी को partialSummaries के तौर पर सेव किया जाता है.
सभी खास जानकारी जनरेट होने के बाद, खास जानकारी के कुछ हिस्सों को पूरी खास जानकारी में जोड़ दिया जाता है. अगर fullSummaries में सिर्फ़ एक जवाब है, तो आपको कुछ और करने की ज़रूरत नहीं है. यह फ़ंक्शन, खास जानकारी दिखाता है. अगर एक से ज़्यादा जवाब मौजूद हैं, तो फ़ंक्शन दोहराता है और कुछ जवाबों की खास जानकारी देना जारी रखता है.
हमने इस समाधान को इंटरनेट रिले चैट (आईआरसी) आरएफ़सी के साथ टेस्ट किया है. इसमें 1,10,030 वर्ण हैं, जिनमें 17,560 शब्द शामिल हैं. Summarizer API ने यह खास जानकारी दी है:
इंटरनेट रिले चैट (आईआरसी), टेक्स्ट मैसेज का इस्तेमाल करके रीयल-टाइम में ऑनलाइन बातचीत करने का एक तरीका है. चैनल में चैट की जा सकती है या निजी मैसेज भेजे जा सकते हैं. साथ ही, चैट को कंट्रोल करने और सर्वर से इंटरैक्ट करने के लिए, कमांड का इस्तेमाल किया जा सकता है. यह इंटरनेट पर एक चैट रूम की तरह होता है, जहां टाइप करके मैसेज भेजे जा सकते हैं और दूसरों के मैसेज तुरंत देखे जा सकते हैं.
यह काफ़ी असरदार है! साथ ही, इसमें सिर्फ़ 309 वर्ण हैं.
सीमाएं
'खास जानकारी की खास जानकारी' तकनीक की मदद से, क्लाइंट-साइज़ मॉडल की कॉन्टेक्स्ट विंडो में काम किया जा सकता है. क्लाइंट-साइड एआई के कई फ़ायदे हैं. हालांकि, आपको ये समस्याएं आ सकती हैं:
- जवाब में दी गई जानकारी का सटीक न होना: रिकर्सन की वजह से, जवाब देने की प्रोसेस बार-बार दोहराई जा सकती है. साथ ही, हर जवाब में दी गई जानकारी, ओरिजनल टेक्स्ट से अलग हो सकती है. इसका मतलब है कि मॉडल ऐसी खास जानकारी जनरेट कर सकता है जो बहुत कम जानकारी वाली हो और आपके काम की न हो.
- परफ़ॉर्मेंस धीमी होना: हर जवाब को जनरेट होने में समय लगता है. बड़े टेक्स्ट में कई तरह की खास जानकारी हो सकती है. इसलिए, इस तरीके से खास जानकारी जनरेट होने में कई मिनट लग सकते हैं.
हमारे पास जवाब को छोटा करने वाले टूल का डेमो उपलब्ध है. साथ ही, पूरा सोर्स कोड देखा जा सकता है.
सुझाव/राय दें या शिकायत करें
Summarizer API के साथ, अलग-अलग लंबाई वाले इनपुट टेक्स्ट, अलग-अलग स्प्लिट साइज़, और अलग-अलग ओवरलैप लंबाई का इस्तेमाल करके, खास जानकारी की खास जानकारी देने की तकनीक आज़माएं.
- Chrome में लागू किए गए बदलावों के बारे में सुझाव/राय देने या शिकायत करने के लिए, गड़बड़ी की रिपोर्ट सबमिट करें या सुविधा का अनुरोध करें.
- MDN पर मौजूद दस्तावेज़ पढ़ें
- जवाब को छोटा करने की प्रोसेस या पहले से मौजूद एआई से जुड़े किसी अन्य सवाल के बारे में जानने के लिए, Chrome की एआई टीम से चैट करें.