


เผยแพร่: 12 ก.พ. 2025
Google Search เป็นหนึ่งในเว็บไซต์ที่ได้รับความนิยมมากที่สุดบนเว็บ และยังเป็นหนึ่งในเว็บไซต์ที่เร็วที่สุดด้วย ทีม Search ลงทุนอย่างต่อเนื่องเพื่อให้ประสบการณ์การค้นหารวดเร็วขึ้น ในหน้าเว็บที่ได้รับความนิยมอย่าง Google Search แม้การปรับปรุงเพียงมิลลิวินาทีก็ช่วยให้การทำงานเร็วขึ้นได้ ความสนใจในความเร็วรวมถึงหน้าแรกของ Google ที่เป็นที่รู้จักกันดี หน้าผลการค้นหา (SERP) และการคลิกไปยังเว็บไซต์อื่นๆ จากผลการค้นหาเหล่านั้น
Google Search ใช้ Speculation Rules API เพื่อปรับปรุงความเร็วในการไปยังส่วนต่างๆ จากหน้าผลการค้นหาไปยังลิงก์ผลการค้นหา และใช้ฟีเจอร์บางอย่างของ API ที่อาจเป็นประโยชน์ต่อเจ้าของเว็บไซต์รายอื่นๆ
เรียกข้อมูลล่วงหน้าสำหรับผลการค้นหา 2 รายการแรก
การใช้กฎการคาดการณ์ครั้งแรกๆ อย่างหนึ่งคือการดึงข้อมูลล่วงหน้าของผลการค้นหา 2 รายการแรก เช่น การค้นหาคำว่า "ทดสอบ" จะรวมกฎการคาดคะเนต่อไปนี้ในหน้าเว็บ
{
"prefetch": [{
"source": "list",
"requires": [
"anonymous-client-ip-when-cross-origin"
],
"referrer_policy": "strict-origin",
"urls": [
"https://www.merriam-webster.com/dictionary/test",
"https://dictionary.cambridge.org/dictionary/english/test"
]
}]
}
URL 2 รายการที่ด้านล่างคือผลการค้นหา 2 รายการแรก และระบบจะดึงข้อมูลล่วงหน้าทันที หากผู้ใช้คลิกรายการเหล่านั้น ผู้ใช้จะเริ่มต้นได้เร็วขึ้นเนื่องจากเอกสาร HTML ควรพร้อมใช้งานในเบราว์เซอร์อยู่แล้ว
คุณดูกฎและความพยายามในการดึงข้อมูลล่วงหน้าได้ในแท็บ Application ของเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ -> แท็บ Speculation ตามที่ระบุไว้ก่อนหน้านี้
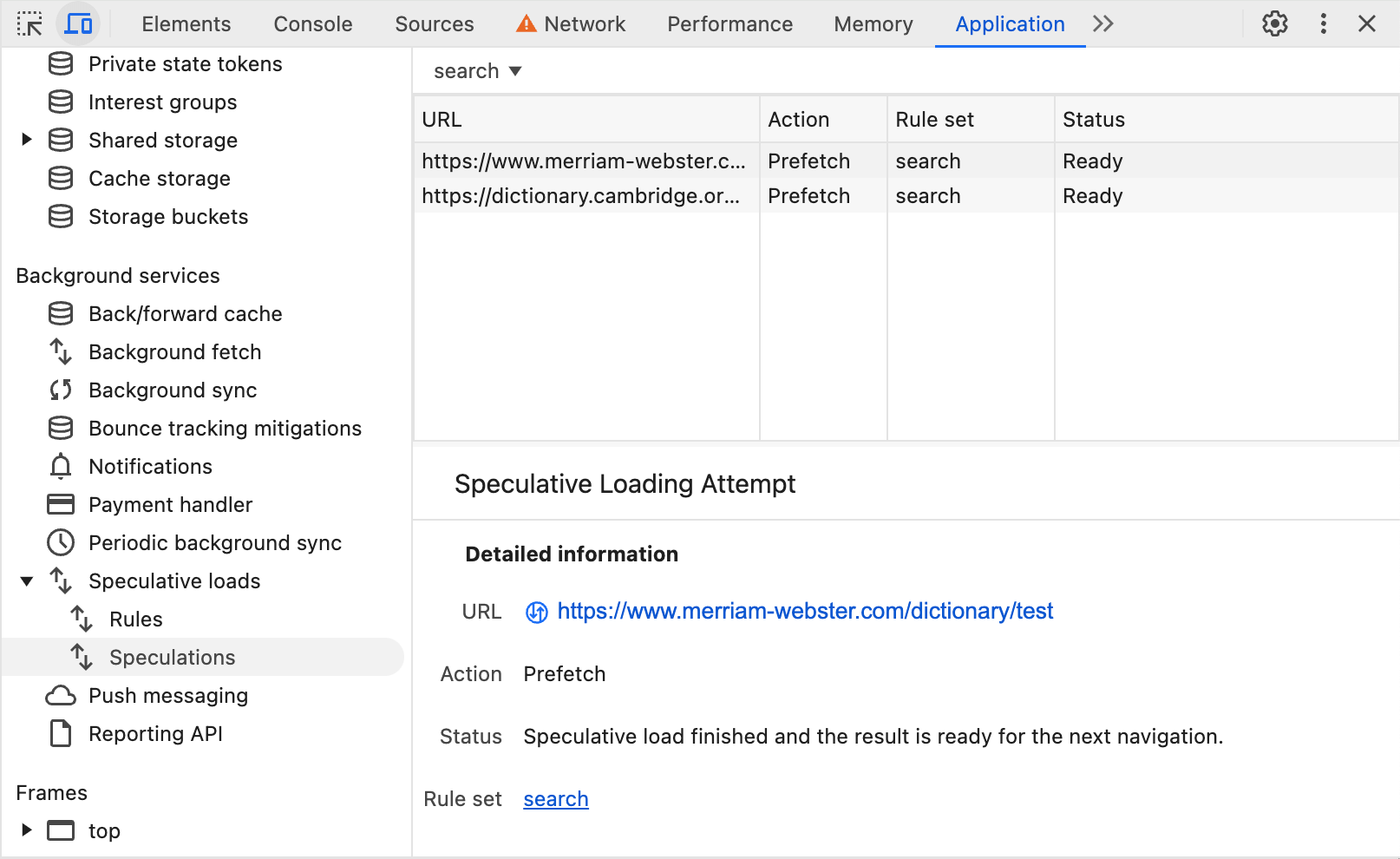
การดึงข้อมูลล่วงหน้าที่รักษาความเป็นส่วนตัว
เนื่องจากลิงก์เหล่านี้เป็นลิงก์ไปยังเนื้อหาในเว็บไซต์อื่น จึงมีข้อควรพิจารณาเพิ่มเติมเกี่ยวกับความเป็นส่วนตัวสำหรับการดึงข้อมูลล่วงหน้า เนื่องจากผู้ใช้ยังไม่ได้เข้าชมเว็บไซต์เหล่านั้น
โชคดีที่ API ออกแบบมาโดยคำนึงถึงเรื่องนี้ และ Google Search ก็ใช้ฟีเจอร์ 2 อย่างเพื่อรักษาความเป็นส่วนตัวของผู้ใช้
วิธีแรกคือการใช้requiresการกำหนดค่าเพื่อให้แน่ใจว่าการดึงข้อมูลล่วงหน้าใช้พร็อกซีการดึงข้อมูลล่วงหน้าแบบส่วนตัวใน Chrome
"requires": [
"anonymous-client-ip-when-cross-origin"
],
ซึ่งจะใช้พร็อกซีเพื่อให้แน่ใจว่าการเชื่อมต่อจะปกปิดที่อยู่ IP เพื่อไม่ให้เราเปิดเผย IP ของผู้ใช้ต่อเว็บไซต์ก่อนที่ผู้ใช้จะคลิกลิงก์เพื่อไปยังเว็บไซต์จากหน้าผลการค้นหา
ประการที่ 2 Google Search ใช้referrer_policy เพื่อให้มั่นใจว่าจะไม่มีการส่งรายละเอียดที่เข้ารหัสใน URL ของหน้าค้นหาไปยังเว็บไซต์ในreferer ส่วนหัว HTTP
"referrer_policy": "strict-origin",
ปัจจุบันเบราว์เซอร์ส่วนใหญ่ใช้strict-origin-when-cross-origin เป็นค่าเริ่มต้น แต่การตั้งค่านี้จะใช้การตั้งค่าที่เข้มงวดกว่าเพื่อใช้นโยบาย URL ที่มาของ strict-origin แม้แต่สำหรับการดึงข้อมูลล่วงหน้าจากต้นทางเดียวกัน
การป้องกันที่ 3 จะเกิดขึ้นโดยอัตโนมัติหากผู้ใช้มีคุกกี้สำหรับเว็บไซต์ ในกรณีนี้ ผู้ใช้จะได้รับผลลัพธ์ที่แตกต่างกันตามคุกกี้เหล่านั้น และ Chrome จะไม่ใช้ HTML ที่ดึงข้อมูลล่วงหน้า
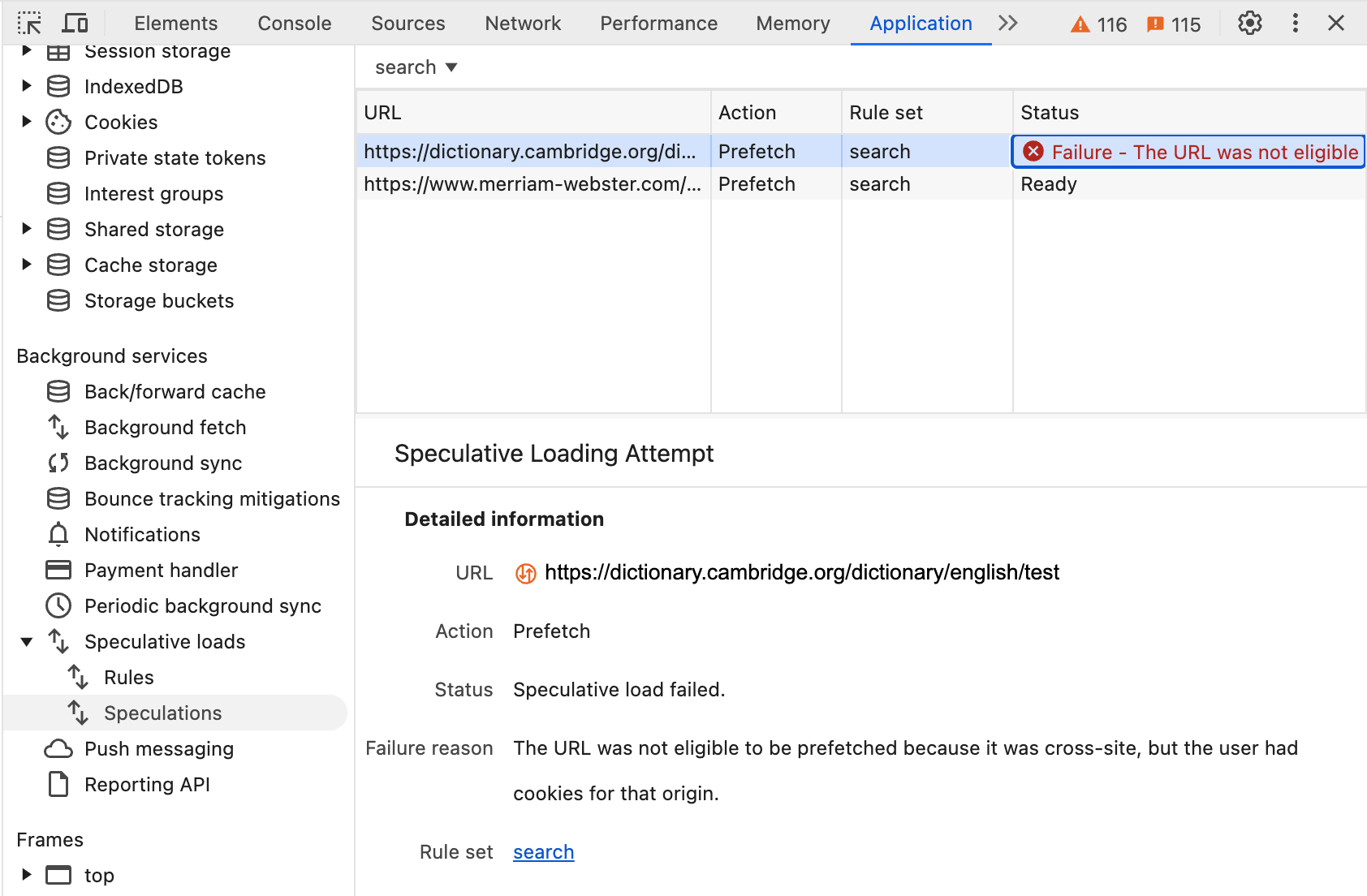
ซึ่งหมายความว่าผู้ใช้ที่มีคุกกี้จะไม่ได้รับประโยชน์จากประสิทธิภาพที่ได้รับการปรับปรุงซึ่งการดึงข้อมูลล่วงหน้ามีให้เมื่อคลิกเว็บไซต์นั้น แต่ระบบจะให้ความสำคัญกับการปกป้องความเป็นส่วนตัวและการโหลดหน้าเว็บที่ถูกต้อง นอกจากนี้ หากผู้ใช้เคยเข้าชมเว็บไซต์และมีคุกกี้สำหรับเว็บไซต์นั้นแล้ว ก็มีแนวโน้มที่จะมีชิ้นงานบางอย่างจากเว็บไซต์นั้นที่แคชไว้ และน่าจะได้รับประสบการณ์การโหลดหน้าเว็บที่เร็วขึ้นแม้ว่าจะไม่มีการดึงข้อมูลล่วงหน้าก็ตาม
ผลกระทบต่อผู้ใช้จากการดึงข้อมูลล่วงหน้าของผลการค้นหา 2 รายการแรก
เช่นเดียวกับการเปลี่ยนแปลงส่วนใหญ่ Google Search ได้เปิดตัวการดึงข้อมูลล่วงหน้าในการทดสอบ A/B และวัดผลกระทบ โดยพบว่า Largest Contentful Paint (LCP) ดีขึ้นอย่างเห็นได้ชัด ใน Chrome สำหรับ Android ระบบลด LCP สำหรับการคลิกจาก Google Search ลง 67 มิลลิวินาที การเปิดตัวใน Chrome สำหรับเดสก์ท็อปในภายหลังส่งผลให้ LCP ดีขึ้นในระดับเดียวกันที่ 58.6 มิลลิวินาที การปรับปรุงเหล่านี้มีไว้สำหรับเว็บไซต์ที่ผู้ใช้ไปยัง ไม่ใช่เว็บไซต์ Google Search เอง แต่ก็เป็นประโยชน์ต่อผู้ใช้ Google Search
การปรับปรุง LCP เหล่านี้อาจดูเหมือนไม่มีนัยสำคัญ แต่สำหรับเว็บไซต์ที่ได้รับการเพิ่มประสิทธิภาพอย่างยิ่งยวดอย่าง Google Search เรายินดีกับการปรับปรุงแม้เพียงมิลลิวินาทีเดียวเพื่อผู้ใช้ของเรา ดังนั้นการปรับปรุงในช่วงหลายสิบมิลลิวินาทีจึงเป็นเรื่องที่น่าตื่นเต้น เว็บไซต์ของคุณอาจได้รับประโยชน์มากขึ้นอย่างมาก คุณควรลองใช้เพื่อดูว่าจะเป็นอย่างไร
ระบบได้เปิดใช้การดึงข้อมูลล่วงหน้าโดยใช้กฎการคาดคะเนใน Search บน Android โดยค่าเริ่มต้นตั้งแต่เดือนตุลาคม 2022 และจะเปิดตัวในเดสก์ท็อปภายในเดือนกันยายน 2024
นอกเหนือจากผลการค้นหา 2 รายการแรก
นับตั้งแต่การเปิดตัว Speculation Rules API ครั้งแรก เราได้ปรับปรุงด้วยพร็อพเพอร์ตี้ความกระตือรือร้นที่อนุญาตให้คาดการณ์ได้เฉพาะเมื่อผู้ใช้วางเมาส์เหนือหรือเริ่มคลิกลิงก์
Google Search จึงตัดสินใจที่จะแสดงผลการค้นหามากกว่า 2 รายการแรก และยังดึงข้อมูลผลการค้นหาที่เหลือล่วงหน้าด้วย แต่จะทำก็ต่อเมื่อผู้ใช้เลื่อนเมาส์เหนือลิงก์โดยใช้moderateการตั้งค่าความกระตือรือร้น ซึ่งจะช่วยป้องกันการสิ้นเปลืองทรัพยากรโดยไม่จำเป็นสำหรับลิงก์ที่มีโอกาสคลิกน้อยกว่า
อีกครั้งที่กฎนี้จะปรากฏในเครื่องมือสำหรับนักพัฒนาเว็บเมื่อคุณค้นหาใน Chrome และจะเหมือนกับกฎก่อนหน้าทุกประการ แต่คราวนี้มีการตั้งค่าตัวเลือก "eagerness": "moderate" ดังนี้
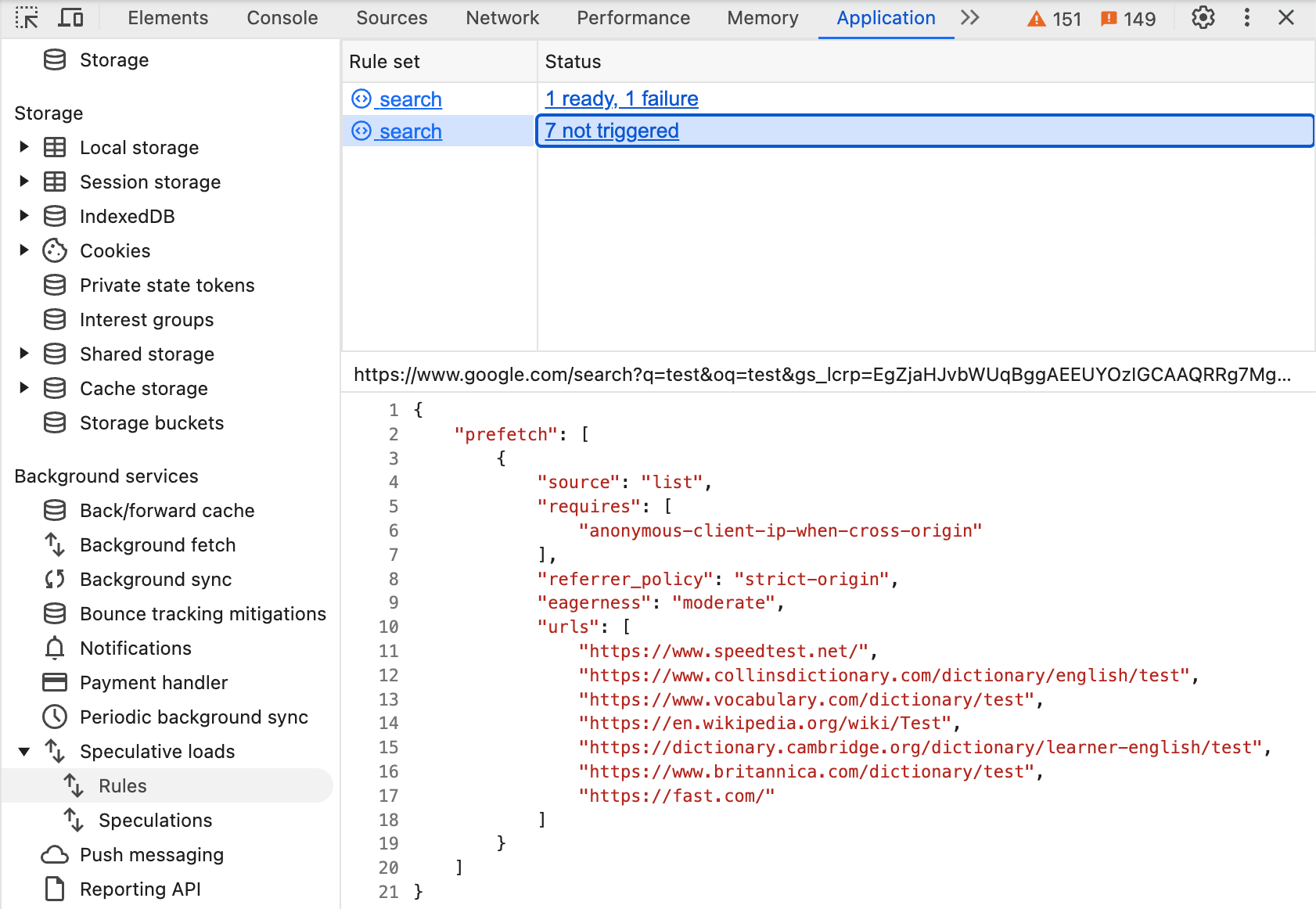
การวางเมาส์เหนือลิงก์เหล่านี้จะทริกเกอร์การดึงข้อมูลล่วงหน้า โปรดทราบว่า Google Search จะแสดง URL อย่างชัดเจนแทนที่จะใช้ฟีเจอร์กฎของเอกสารของ Speculation Rules API เนื่องจากไม่ต้องการดึงข้อมูล URL อื่นๆ เช่น โฆษณา มาล่วงหน้า
ผลกระทบต่อผู้ใช้ในการดึงข้อมูลล่วงหน้าของผลการค้นหาที่อยู่นอกเหนือจาก 2 รายการแรก
Chrome บนเดสก์ท็อปลด First Contentful Paint (FCP) สำหรับการไปยังส่วนต่างๆ จาก Google Search ลง 7.6 มิลลิวินาที และ LCP ลง 9.5 มิลลิวินาที (ตามที่แสดงในการทดสอบ A/B) ซึ่งแสดงถึงการเพิ่มขึ้นที่น้อยกว่าเมื่อเทียบกับการปรับปรุง 58.6 มิลลิวินาทีที่เห็นในผลลัพธ์ 2 รายการแรก แต่ก็ไม่น่าแปลกใจเนื่องจากเวลานำที่สั้นกว่าเนื่องจากไม่ได้ดึงข้อมูลล่วงหน้าอย่างกระตือรือร้น อย่างไรก็ตาม การเพิ่มขึ้นเหล่านี้ยังคงเป็นผลลัพธ์ที่ดีด้วยเหตุผลเดียวกันกับที่กล่าวไว้ก่อนหน้านี้
การดึงข้อมูลล่วงหน้าของผลการค้นหาที่เหลือบนเดสก์ท็อปเปิดตัวโดยค่าเริ่มต้นในเดือนธันวาคม 2024
สำหรับอุปกรณ์เคลื่อนที่ซึ่งโดยปกติแล้วจะไม่มีการวางเมาส์ เราไม่เห็นการปรับปรุงที่แท้จริง ดังนั้นแม้ว่าจะไม่มีการถดถอย แต่เราก็ไม่ได้เปิดใช้การดึงข้อมูลล่วงหน้าเพิ่มเติมเหล่านี้ในอุปกรณ์เคลื่อนที่
การใช้การคาดเดาเพิ่มเติมสำหรับ Google Search
Google ยังคงทดสอบ API ใหม่ที่น่าสนใจนี้ต่อไป และหวังว่าจะทำให้การท่องเว็บเร็วที่สุดเท่าที่จะเป็นไปได้ เรายังมีเคล็ดลับอื่นๆ ที่กำลังพัฒนาอยู่อีกด้วย
ตัวอย่างหนึ่งคือ Chrome กำลังเปิดตัวหน้าผลการค้นหาที่แสดงผลล่วงหน้าสำหรับผู้ใช้ที่เปิดใช้การโหลดล่วงหน้า เมื่อผู้ใช้พิมพ์คำค้นหาในแถบที่อยู่ของ Chrome และในที่อื่นๆ เช่น ช่องค้นหาใน Android นอกจากนี้ เครื่องมือค้นหาอื่นๆ ก็สามารถนำไปใช้ได้เช่นกัน ไม่ใช่แค่ Google Search แต่เรายังไม่ทราบว่าเครื่องมือค้นหาอื่นๆ มีการนำไปใช้หรือไม่ในขณะนี้
Google Search ไม่ได้ต้องการที่จะดำเนินการต่อและใช้การแสดงผลล่วงหน้าสำหรับลิงก์ผลการค้นหาเอง เนื่องจากฟีเจอร์นี้ไม่พร้อมใช้งานสำหรับการไปยังส่วนต่างๆ ในเว็บไซต์ (และต้องเลือกใช้สำหรับการแสดงผลล่วงหน้าแบบข้ามต้นทางในเว็บไซต์เดียวกันด้วย)
หมายเหตุเกี่ยวกับการรองรับเบราว์เซอร์
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)

ขณะนี้เราได้ติดตั้งใช้งาน Speculation Rules API ในเบราว์เซอร์ที่ใช้ Chromium แต่ Chrome กำลังเผยแพร่ข้อกำหนด API ผ่านกระบวนการมาตรฐาน W3C และต้องการให้เบราว์เซอร์อื่นๆ ติดตั้งใช้งาน API นี้
ปัจจุบันพร็อกซีการดึงข้อมูลล่วงหน้าแบบส่วนตัวใช้งานได้ใน Chrome เท่านั้น และยังไม่พร้อมใช้งานในเบราว์เซอร์อื่นๆ ที่ใช้ Chromium แต่หากเบราว์เซอร์อื่นๆ ใช้พร็อกซีการดึงข้อมูลล่วงหน้าแบบส่วนตัวของตนเอง Google Search ก็อาจพิจารณาใช้การปรับปรุงเหล่านี้ในเบราว์เซอร์เหล่านั้นด้วย
เนื่องจากผลกระทบด้านความเป็นส่วนตัวของการดึงข้อมูลล่วงหน้าโดยไม่มีพร็อกซีการดึงข้อมูลล่วงหน้าแบบส่วนตัว Google Search จึงไม่ดึงข้อมูลล่วงหน้าในเบราว์เซอร์ที่ไม่รองรับเทคโนโลยีนี้ และไม่ได้ใช้การสำรองข้อมูลโดยใช้เทคโนโลยีอื่นๆ สำหรับเบราว์เซอร์อื่นๆ อย่างไรก็ตาม การปรับปรุงแบบค่อยเป็นค่อยไปนี้หมายความว่าผู้ใช้ในเบราว์เซอร์เหล่านั้นจะไม่ได้รับประโยชน์จากการเพิ่มความเร็วเพียงเล็กน้อยนี้
ลองใช้ในเว็บไซต์ของคุณ
API กฎการคาดการณ์พร้อมให้ทุกเว็บไซต์ใช้งาน ไม่ใช่แค่ Google Search นอกเหนือจากความสามารถในการดึงข้อมูลล่วงหน้าที่กล่าวถึงในที่นี้แล้ว การแสดงผลล่วงหน้ายังมีประโยชน์เพิ่มเติมเมื่อและในกรณีที่ใช้ได้ เนื่องจากเว็บไซต์ขนาดใหญ่อย่าง Google Search แสดงให้เห็นถึงประโยชน์ที่ชัดเจนของ API นี้ต่อประสบการณ์ของผู้ใช้ เราจึงขอแนะนำให้เจ้าของเว็บไซต์ทุกรายพิจารณาวิธีการใช้ API นี้และอาจได้รับประโยชน์จาก API นี้
นอกจากนี้ การปกป้องความเป็นส่วนตัวที่อธิบายไว้ในโพสต์นี้ยังพร้อมให้บริการแก่เว็บไซต์อื่นๆ ด้วย โดยมีข้อแม้ว่าผู้ใช้ต้องเปิดใช้การรองรับการโหลดล่วงหน้าแบบขยายในการตั้งค่าเพื่อให้เว็บไซต์ที่ไม่ใช่ของ Google สามารถกำหนดเส้นทางการเข้าชมโดยใช้พร็อกซีการดึงข้อมูลล่วงหน้าแบบส่วนตัวของ Google เนื่องจากวิธีนี้จะทำให้ Google เป็นบุคคลที่สามระหว่างผู้ใช้กับเว็บไซต์ ซึ่งไม่จำเป็นสำหรับเว็บไซต์ของ Google เนื่องจาก Google เป็นหนึ่งในบุคคลที่เกี่ยวข้องอยู่แล้ว