
Hier erfahren Sie, wie WebAssembly- und WebGPU-Erweiterungen die Leistung von Machine Learning im Web verbessern.



KI-Inferenz im Web
Wir alle haben davon gehört: KI verändert unsere Welt. Das Internet ist da keine Ausnahme.
In diesem Jahr wurden in Chrome Funktionen für generative KI hinzugefügt, darunter die Erstellung benutzerdefinierter Designs und die Unterstützung beim Verfassen eines ersten Textentwurfs. Aber KI kann noch viel mehr: Sie kann Webanwendungen selbst bereichern.
Webseiten können intelligente Komponenten für die Bilderkennung einbetten, z. B. zur Erkennung von Gesichtern oder Gesten, zur Audioklassifizierung oder zur Spracherkennung. Im letzten Jahr hat sich die generative KI durchgesetzt, einschließlich einiger wirklich beeindruckender Demos von Large Language Models im Web. Sehen Sie sich auch den Artikel Praktische On-Device-KI für Webentwickler an.
KI-Inferenzen im Web sind heute auf einem großen Teil der Geräte verfügbar. Die KI-Verarbeitung kann direkt auf der Webseite erfolgen, wobei die Hardware des Nutzergeräts genutzt wird.
Das hat mehrere Vorteile:
- Reduzierte Kosten: Wenn die Inferenz auf dem Browserclient ausgeführt wird, werden die Serverkosten erheblich gesenkt. Dies kann besonders nützlich sein für GenAI-Abfragen, die um ein Vielfaches teurer sein können als normale Abfragen.
- Latenz: Bei Anwendungen, die besonders empfindlich auf Latenz reagieren, z. B. Audio- oder Videoanwendungen, führt die Verarbeitung direkt auf dem Gerät zu einer geringeren Latenz.
- Datenschutz: Die Ausführung auf der Clientseite kann auch eine neue Klasse von Anwendungen ermöglichen, für die ein höherer Datenschutz erforderlich ist und bei denen Daten nicht an den Server gesendet werden können.
So werden KI-Arbeitslasten derzeit im Web ausgeführt
Heutzutage erstellen Anwendungsentwickler und Forscher Modelle mithilfe von Frameworks. Diese werden im Browser mit einer Laufzeit wie Tensorflow.js oder ONNX Runtime Web ausgeführt. Für die Ausführung werden Web-APIs verwendet.
Alle diese Laufzeiten werden letztendlich über JavaScript oder WebAssembly auf der CPU oder über WebGL oder WebGPU auf der GPU ausgeführt.
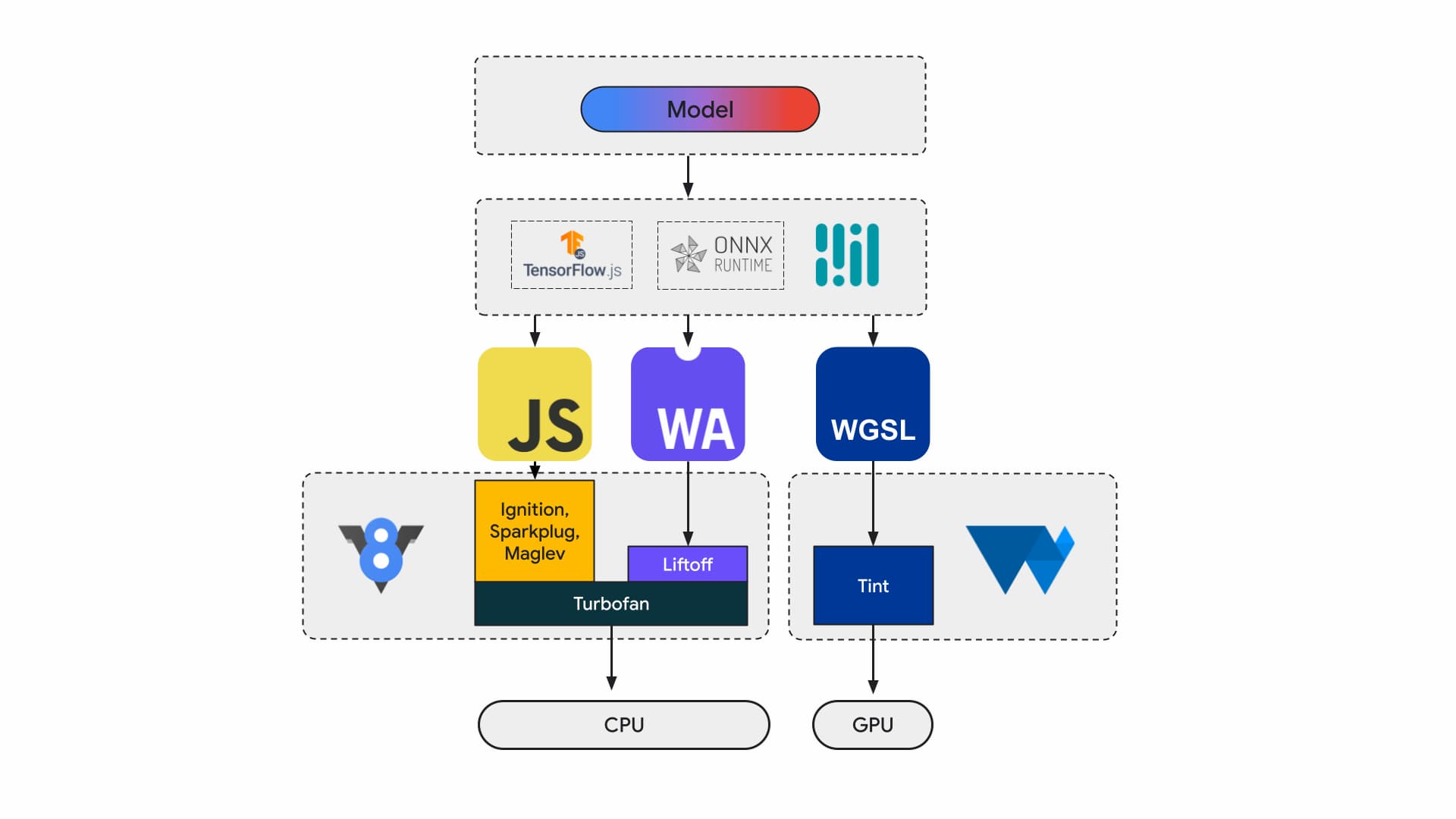
Machine-Learning-Arbeitslasten
Bei Arbeitslasten für maschinelles Lernen (ML) werden Tensoren durch ein Graphen von Rechenknoten geschoben. Tensoren sind die Eingaben und Ausgaben dieser Knoten, die eine große Menge an Berechnungen an den Daten ausführen.
Das ist wichtig, weil:
- Tensoren sind sehr große Datenstrukturen, mit denen Berechnungen für Modelle durchgeführt werden, die Milliarden von Gewichten haben können.
- Skalierung und Inferenz können zu Datenparallelität führen. Das bedeutet, dass dieselben Vorgänge auf alle Elemente in den Tensoren angewendet werden.
- Für die ML-Technologie ist keine Genauigkeit erforderlich. Für die Mondlandung benötigen Sie möglicherweise eine 64‑Bit-Gleitkommazahl, für die Gesichtserkennung aber nur eine Menge von 8‑Bit-Zahlen oder weniger.
Glücklicherweise haben Chipdesigner Funktionen hinzugefügt, die dafür sorgen, dass Modelle schneller und kühler laufen und sogar überhaupt funktionieren.
In der Zwischenzeit arbeiten die WebAssembly- und WebGPU-Teams daran, diese neuen Funktionen für Webentwickler verfügbar zu machen. Wenn Sie Webanwendungen entwickeln, werden Sie diese Low-Level-Primitiven wahrscheinlich nicht häufig verwenden. Wir gehen davon aus, dass die von Ihnen verwendeten Toolchains oder Frameworks neue Funktionen und Erweiterungen unterstützen. Daher können Sie mit minimalen Änderungen an Ihrer Infrastruktur davon profitieren. Wenn Sie Ihre Anwendungen jedoch manuell auf die Leistung hin optimieren möchten, sind diese Funktionen für Sie relevant.
WebAssembly
WebAssembly (Wasm) ist ein kompaktes, effizientes Bytecode-Format, das von Laufzeiten verstanden und ausgeführt werden kann. Es wurde entwickelt, um die zugrunde liegenden Hardwarefunktionen zu nutzen, sodass es mit nahezu nativer Geschwindigkeit ausgeführt werden kann. Der Code wird in einer speichersicheren Sandbox-Umgebung validiert und ausgeführt.
Informationen zu Wasm-Modulen werden mit einer dichten Binärcodierung dargestellt. Im Vergleich zu einem textbasierten Format bedeutet das eine schnellere Dekodierung, ein schnelleres Laden und eine geringere Speichernutzung. Sie ist portabel, da sie keine Annahmen über die zugrunde liegende Architektur trifft, die nicht bereits für moderne Architekturen üblich sind.
Die WebAssembly-Spezifikation ist iterativ und wird in einer offenen W3C-Communitygruppe entwickelt.
Das Binärformat macht keine Annahmen über die Hostumgebung und funktioniert daher auch gut in nicht webbasierten Einbettungen.
Ihre Anwendung kann einmal kompiliert und überall ausgeführt werden: auf einem Computer, Laptop, Smartphone oder einem anderen Gerät mit einem Browser. Weitere Informationen finden Sie unter Write Once, Run Anywhere finally realized with WebAssembly.
Die meisten Produktionsanwendungen, die KI-Inferenzen im Web ausführen, nutzen WebAssembly, sowohl für die CPU-Rechenleistung als auch für die Schnittstelle zu Spezialrechensystemen. Bei nativen Anwendungen können Sie sowohl auf allgemeine als auch auf spezielle Computing-Ressourcen zugreifen, da die Anwendung auf Gerätefunktionen zugreifen kann.
Im Web prüfen wir aus Gründen der Portabilität und Sicherheit sorgfältig, welche Primitiven freigegeben werden. So wird die Barrierefreiheit des Webs mit der maximalen Leistung der Hardware in Einklang gebracht.
WebAssembly ist eine portable Abstraktion von CPUs. Daher wird die gesamte Wasm-Inferenz auf der CPU ausgeführt. Dies ist zwar nicht die leistungsstärkste Option, aber CPUs sind weit verbreitet und funktionieren auf den meisten Geräten für die meisten Arbeitslasten.
Für kleinere Arbeitslasten wie Text- oder Audiolasten wäre eine GPU zu teuer. Es gibt eine Reihe aktueller Beispiele, in denen Wasm die richtige Wahl ist:
- Adobe nutzt TensorFlow.js, um Photoshop für das Web zu optimieren.
- In Google Meet wurde die Hintergrundunschärfe hinzugefügt, einer der ersten Wasm-basierten Videoeffekte im Web.
- Auf YouTube gibt es mehrere Augmented Reality-Effekte.
- In Google Fotos können Sie Fotos online bearbeiten.
In Open-Source-Demos wie whisper-tiny, llama.cpp und Gemma2B, die im Browser ausgeführt wird, können Sie noch mehr entdecken.
Ganzheitlicher Ansatz für Ihre Anwendungen
Sie sollten Primitive basierend auf dem jeweiligen ML-Modell, der Anwendungsinfrastruktur und der beabsichtigten Nutzererfahrung auswählen.
Bei der Gesichtsmarkierungserkennung von MediaPipe sind beispielsweise CPU- und GPU-Inferenzen vergleichbar (auf einem Apple M1-Gerät ausgeführt). Es gibt jedoch Modelle, bei denen die Abweichung deutlich höher sein kann.
Bei ML-Arbeitslasten berücksichtigen wir eine ganzheitliche Anwendungsansicht und hören den Framework-Entwicklern und Anwendungspartnern zu, um die am häufigsten nachgefragten Verbesserungen zu entwickeln und bereitzustellen. Sie lassen sich grob in drei Kategorien unterteilen:
- Leistungskritische CPU-Erweiterungen freigeben
- Ausführen größerer Modelle aktivieren
- Nahtlose Interoperabilität mit anderen Web-APIs ermöglichen
Schnellere Rechenleistung
Derzeit enthält die WebAssembly-Spezifikation nur eine bestimmte Anzahl von Anweisungen, die für das Web freigegeben werden. Aber die Hardware wird ständig um neue Anweisungen erweitert, was die Lücke zwischen nativer und WebAssembly-Leistung vergrößert.
Denken Sie daran, dass für ML-Modelle nicht immer eine hohe Genauigkeit erforderlich ist. Relaxed SIMD ist ein Vorschlag, der einige der strengen, nicht deterministischen Anforderungen reduziert. Dies führt zu einer schnelleren Codegenerierung für einige Vektoroperationen, die Leistungs-Hotspots sind. Außerdem führt Relaxed SIMD neue Punktprodukt- und FMA-Befehle ein, mit denen sich vorhandene Arbeitslasten um eineinhalb bis dreifache beschleunigen lassen. Diese Funktion wurde in Chrome 114 eingeführt.
Beim Gleitkommaformat mit halber Genauigkeit werden 16 Bit für IEEE FP16 anstelle der 32 Bit verwendet, die für Werte mit einfacher Genauigkeit verwendet werden. Im Vergleich zu Werten mit einfacher Genauigkeit bieten Werte mit halber Genauigkeit mehrere Vorteile: reduzierte Arbeitsspeicheranforderungen, die das Training und die Bereitstellung größerer neuronaler Netze ermöglichen, sowie eine reduzierte Arbeitsspeicherbandbreite. Eine geringere Genauigkeit beschleunigt die Datenübertragung und mathematischen Vorgänge.
Größere Modelle
Pointer in den linearen Wasm-Speicher werden als 32‑Bit-Ganzzahlen dargestellt. Das hat zwei Konsequenzen: Heap-Größen sind auf 4 GB begrenzt (auch wenn Computer viel mehr physischen RAM haben) und Anwendungscode, der auf Wasm ausgerichtet ist, muss mit einer 32‑Bit-Zeigergröße kompatibel sein.
Insbesondere bei großen Modellen wie denen, die wir heute haben, kann das Laden dieser Modelle in WebAssembly einschränkend sein. Das Memory64-Angebot hebt diese Einschränkungen auf, indem der lineare Arbeitsspeicher größer als 4 GB sein und dem Adressraum nativer Plattformen entsprechen muss.
Wir haben eine voll funktionsfähige Implementierung in Chrome, die voraussichtlich im Laufe des Jahres eingeführt wird. Bis dahin können Sie Tests mit dem Flag chrome://flags/#enable-experimental-webassembly-features durchführen und uns Feedback senden.
Bessere Web-Interoperabilität
WebAssembly könnte der Einstiegspunkt für Computing-Anwendungen im Web sein.
Mit WebAssembly können GPU-Anwendungen im Web ausgeführt werden. Das bedeutet, dass dieselbe C++-Anwendung, die auf dem Gerät ausgeführt werden kann, mit kleinen Änderungen auch im Web ausgeführt werden kann.
Emscripten, die Wasm-Compiler-Toolchain, bietet bereits Bindungen für WebGPU. Es ist der Einstiegspunkt für KI-Inferenzen im Web. Daher ist es wichtig, dass Wasm nahtlos mit dem Rest der Webplattform interagieren kann. Wir arbeiten an mehreren Vorschlägen in diesem Bereich.
JavaScript Promise Integration (JSPI)
Typische C- und C++-Anwendungen (sowie viele andere Sprachen) werden in der Regel für eine synchrone API geschrieben. Das bedeutet, dass die Anwendung die Ausführung anhält, bis der Vorgang abgeschlossen ist. Solche blockierenden Anwendungen sind in der Regel intuitiver zu schreiben als Anwendungen, die asynchron sind.
Wenn ressourcenintensive Vorgänge den Hauptthread blockieren, können sie auch die E/A-Vorgänge blockieren und die Ruckler sind für die Nutzer sichtbar. Es gibt eine Diskrepanz zwischen dem synchronen Programmiermodell nativer Anwendungen und dem asynchronen Modell des Webs. Das ist besonders problematisch für ältere Anwendungen, deren Portierung teuer wäre. Emscripten bietet mit Asyncify eine Möglichkeit dazu, aber das ist nicht immer die beste Option – größere Codegröße und nicht so effizient.
Im folgenden Beispiel wird die Fibonacci-Folge berechnet, wobei JavaScript-Versprechen für die Addition verwendet werden.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
Achten Sie in diesem Beispiel auf Folgendes:
- Das
EM_ASYNC_JS-Makro generiert den gesamten erforderlichen Glue-Code, damit wir wie bei einer normalen Funktion mit JSPI auf das Ergebnis des Promises zugreifen können. - Die spezielle Befehlszeilenoption
-s ASYNCIFY=2. Dadurch wird die Option zum Generieren von Code aufgerufen, der JSPI verwendet, um mit JavaScript-Importen zu kommunizieren, die Versprechen zurückgeben.
Weitere Informationen zu JSPI, zur Verwendung und zu den Vorteilen finden Sie im Artikel Introducing the WebAssembly JavaScript Promise Integration API on v8.dev (Einführung in die WebAssembly JavaScript Promise Integration API auf v8. dev). Informationen zum aktuellen Ursprungstest
Speicherverwaltung
Entwickler haben nur sehr wenig Kontrolle über den Wasm-Speicher, da das Modul seinen eigenen Speicher hat. Alle APIs, die auf diesen Arbeitsspeicher zugreifen müssen, müssen Daten hinein- oder herauskopieren. Diese Nutzung kann sich wirklich summieren. Beispielsweise muss eine Grafikanwendung möglicherweise für jeden Frame Daten ein- und auskopieren.
Der Vorschlag zur Speichersteuerung zielt darauf ab, eine detailliertere Steuerung des linearen Wasm-Speichers zu ermöglichen und die Anzahl der Kopien in der Anwendungspipeline zu reduzieren. Dieser Vorschlag befindet sich in Phase 1. Wir erstellen einen Prototyp in V8, der JavaScript-Engine von Chrome, um die Entwicklung des Standards zu unterstützen.
Entscheiden, welches Backend für Sie geeignet ist
Die CPU ist zwar allgegenwärtig, aber nicht immer die beste Option. Die GPU oder Accelerators können eine um Größenordnungen höhere Leistung bieten, insbesondere bei größeren Modellen und auf High-End-Geräten. Das gilt sowohl für native als auch für Webanwendungen.
Welches Backend Sie auswählen, hängt von der Anwendung, dem Framework oder der Toolchain sowie von anderen Faktoren ab, die die Leistung beeinflussen. Wir investieren jedoch weiterhin in Vorschläge, die es ermöglichen, dass Core Wasm gut mit dem Rest der Webplattform und insbesondere mit WebGPU funktioniert.