


게시일: 2025년 3월 12일, 최종 업데이트: 2025년 5월 28일
| 설명하듯이 | 웹 | 확장 프로그램 | Chrome 상태 | 의도 |
|---|---|---|---|---|
| MDN | View | 배송 의도 |
요약자 API를 사용하면 다양한 길이와 형식으로 정보 요약을 생성할 수 있습니다. Chrome의 기반 모델 또는 브라우저에 내장된 다른 언어 모델과 함께 사용하여 길거나 복잡한 텍스트를 간결하게 설명하세요.
클라이언트 측에서 실행하면 데이터를 로컬에서 사용할 수 있으므로 민감한 데이터를 안전하게 보호하고 대규모로 가용성을 제공할 수 있습니다. 하지만 컨텍스트 윈도우가 서버 측 모델보다 훨씬 작으므로 매우 큰 문서를 요약하기 어려울 수 있습니다. 이 문제를 해결하려면 요약의 요약 기법을 사용하면 됩니다.
요약의 요약이란 무엇인가요?
요약의 요약 기법을 사용하려면 입력 콘텐츠를 주요 지점에서 분할한 다음 각 부분을 독립적으로 요약하세요. 각 부분의 출력을 연결한 다음 이 연결된 텍스트를 하나의 최종 요약으로 요약할 수 있습니다.
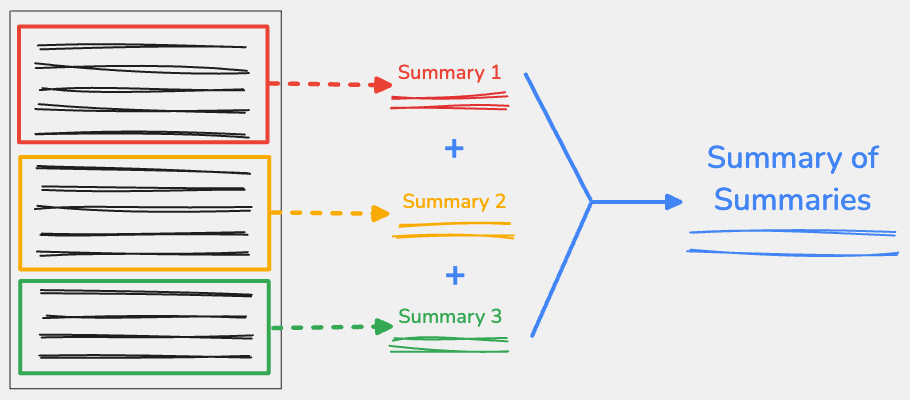
콘텐츠를 신중하게 분할
대규모 텍스트를 분할하는 방법을 고려하는 것이 중요합니다. 다양한 전략이 LLM 전반에서 다양한 출력을 생성할 수 있기 때문입니다. 이상적으로는 텍스트를 주제가 변경될 때, 예를 들어 기사의 새 섹션이나 단락에서 분할해야 합니다. 단어 또는 문장의 중간에서 텍스트를 분할하지 않는 것이 중요합니다. 즉, 문자 수를 유일한 분할 가이드라인으로 사용할 수 없습니다.
이 작업을 실행하는 방법은 다양합니다. 다음 예에서는 성능과 출력 품질의 균형을 맞추는 LangChain.js의 재귀 텍스트 분할기 를 사용했습니다. 이 방법은 대부분의 워크로드에 적합합니다.
새 인스턴스를 만들 때 두 가지 주요 매개변수가 있습니다.
chunkSize는 각 분할에서 허용되는 최대 문자 수입니다.chunkOverlap은 연속된 두 분할 간에 겹치는 문자 수입니다. 이렇게 하면 각 청크에 이전 청크의 컨텍스트가 일부 포함됩니다.
splitText()로 텍스트를 분할하여 각 청크가 포함된 문자열 배열을 반환합니다.
대부분의 LLM은 컨텍스트 윈도우를 문자 수가 아닌 토큰 수로 표현합니다. 토큰은 평균적으로 4개의 문자를 포함합니다. 이 예에서 chunkSize는 3, 000자이며 이는 약 750개의 토큰입니다.
토큰 가용성 확인
입력에 사용할 수 있는 토큰 수를 확인하려면
measureInputUsage()
메서드와 inputQuota
속성을 사용하세요. 이 경우 요약자가 모든 텍스트를 처리하기 위해 실행되는 횟수를 알 수 없으므로 구현은 무제한입니다.
각 분할의 요약 생성
콘텐츠 분할 방법을 설정한 후 요약자 API를 사용하여 각 부분의 요약을 생성할 수 있습니다.
`create()create()` 함수를 사용하여 요약자의 인스턴스를 만듭니다. 가능한 한 많은
컨텍스트를 유지하기 위해 format 매개변수를 plain-text, type
을 tldr,
및 length을 long으로 설정했습니다.
그런 다음 RecursiveCharacterTextSplitter에서 만든 각 분할의 요약을 생성하고 결과를 새 문자열로 연결합니다.
각 부분의 요약을 명확하게 식별하기 위해 각 요약을 새 줄로 구분했습니다.
이 새 줄은 이 루프를 한 번만 실행할 때는 중요하지 않지만 각 요약이 최종 요약의 토큰 값에 어떻게 추가되는지 확인하는 데 유용합니다. 대부분의 경우 이 솔루션은 중간 길이 및 긴 콘텐츠에 적합합니다.
요약의 재귀 요약
텍스트의 양이 매우 긴 경우 연결된 요약의 길이가 사용 가능한 컨텍스트 윈도우보다 클 수 있으므로 요약이 실패합니다. 이 문제를 해결하려면 요약을 재귀적으로 요약하면 됩니다.
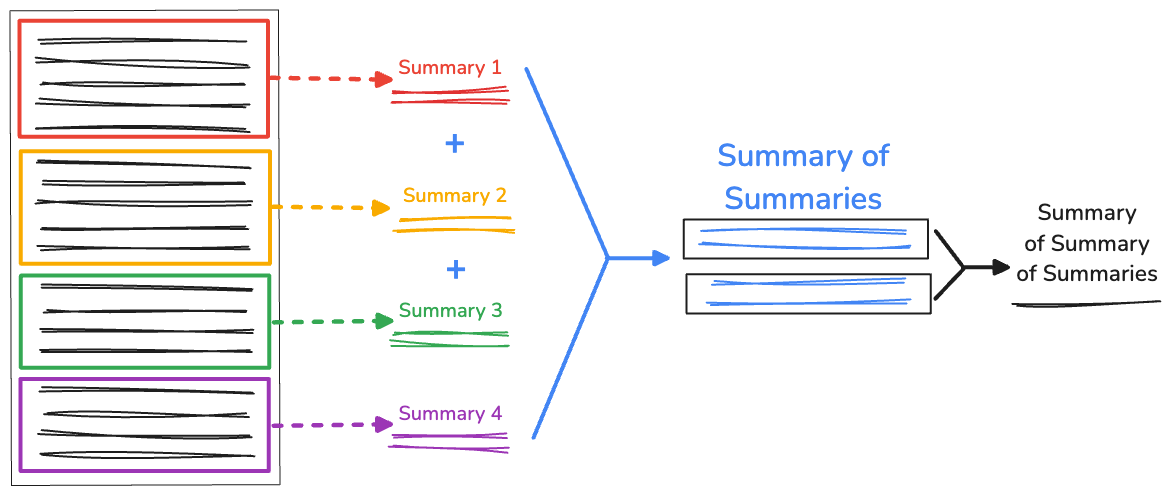
RecursiveCharacterTextSplitter에서 생성된 초기 분할은 계속 수집합니다. 그런 다음 recursiveSummarizer() 함수에서 연결된 분할의 문자 길이를 기준으로 요약 프로세스를 반복합니다. 요약의 문자 길이가 3000을 초과하면 fullSummaries로 연결합니다. 한도에 도달하지 않으면 요약이 partialSummaries로 저장됩니다.
모든 요약이 생성되면 최종 부분 요약이 전체 요약에 추가됩니다. fullSummaries에 요약이 하나만 있는 경우 추가 재귀가 필요하지 않습니다. 함수는 최종 요약을 반환합니다. 요약이 두 개 이상 있는 경우 함수가 반복되고 부분 요약이 계속 요약됩니다.
단어 17,560개를 포함하는 110,030자의 인터넷 릴레이 채팅 (IRC) RFC로 이 솔루션을 테스트했습니다. 요약자 API는 다음 요약을 제공했습니다.
인터넷 릴레이 채팅 (IRC)은 텍스트 메시지를 사용하여 실시간으로 온라인에서 소통하는 방법입니다. 채널에서 채팅하거나 비공개 메시지를 보낼 수 있으며 명령어를 사용하여 채팅을 제어하고 서버와 상호작용할 수 있습니다. 인터넷의 채팅 방과 비슷하며, 여기서 메시지를 입력하고 다른 사용자의 메시지를 즉시 확인할 수 있습니다.
매우 효과적입니다! 그리고 309자밖에 되지 않습니다.
제한사항
요약의 요약 기법을 사용하면 클라이언트 측 모델의 컨텍스트 윈도우 내에서 작동할 수 있습니다. 클라이언트 측 AI에는 많은 이점이 있지만 다음과 같은 문제가 발생할 수 있습니다.
- 요약의 정확성 저하: 재귀를 사용하면 요약 프로세스 반복이 무한할 수 있으며 각 요약이 원본 텍스트에서 더 멀어집니다. 즉, 모델이 유용하기에는 너무 얕은 최종 요약을 생성할 수 있습니다.
- 성능 저하: 각 요약을 생성하는 데 시간이 걸립니다. 또한 텍스트가 길수록 요약의 수가 무한할 수 있으므로 이 접근 방식을 완료하는 데 몇 분이 걸릴 수 있습니다.
요약자 데모를 사용할 수 있으며 전체 소스 코드를 볼 수 있습니다.
의견 공유
요약자 API를 사용하여 다양한 길이의 입력 텍스트, 다양한 분할 크기, 다양한 겹침 길이로 요약의 요약 기법을 사용해 보세요.
- Chrome의 구현에 관한 의견이 있으면 버그 신고 또는 기능 요청을 제출하세요.
- MDN의 문서 읽기
- 요약 프로세스 또는 기타 내장 AI 질문에 관해 Chrome AI팀과 채팅하세요.