


Published: March 12, 2025, Last updated: May 28, 2025
| Explainer | Web | Extensions | Chrome Status | Intent |
|---|---|---|---|---|
| MDN | View | Intent to Ship |
The Summarizer API helps you generate summaries of information in various lengths and formats. Use it with Gemini Nano in Chrome, or other language models built into browsers, to concisely explain long or complicated text.
When performed client-side, you can work with data locally, which lets you keep sensitive data safe and can offer availability at scale. However, the context window is much smaller than with server-side models, which means very large documents could be challenging to summarize. To solve this problem, you can use the summary of summaries technique.
What is summary of summaries?
To use the summary of summaries technique, split the input content at key points, then summarize each part independently. You can concatenate the outputs from each part, then summarize this concatenated text into one final summary.
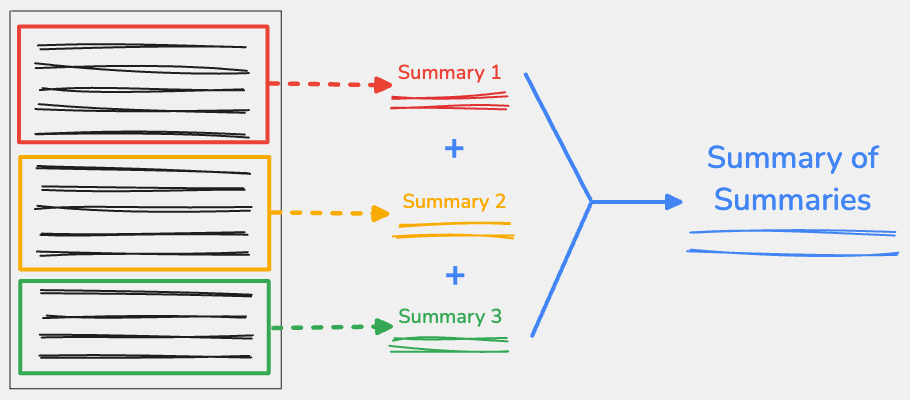
Thoughtfully split your content
It's important to consider how you'll split up a large piece of text, as different strategies can lead to different outputs across LLMs. Ideally, text should be split when there's a change of topic, such as a new section of an article or at a paragraph. It's important to avoid splitting the text in the middle of a word or sentence, which means you cannot use a character count as your only split guideline.
There are many ways you can do this. In the following example, we used the Recursive Text Splitter from LangChain.js, which balances performance and output quality. This should work for most workloads.
When creating a new instance, there are two key parameters:
chunkSizeis the maximum number of characters allowed in each split.chunkOverlapis the amount of characters to overlap between two consecutive splits. This ensures that each chunk has some of the context from the previous chunk.
Split the text with splitText() to return an array of strings with each chunk.
Most LLMs have their context window expressed as a number of tokens, rather than
a number of characters. On average, a token contains 4 characters. In our
example, the chunkSize is 3000 characters and that's approximately
750 tokens.
Determine token availability
To determine how many tokens are available to use for an input, use the
measureInputUsage()
method and inputQuota
property. In this case, the implementation is limitless, as you cannot know
how many times the summarizer will run to process all of the text.
Generate summaries for each split
Once you've set up how the content is split, you can generate summaries for each part with the Summarizer API.
Create an instance of the summarizer with the
create() function. To keep as much
context as possible, we've set the format parameter to plain-text, type
to tldr,
and length to long.
Then, generate the summary for each split created by the
RecursiveCharacterTextSplitter and concatenate the results into a new string.
We separated each summary with a new line to clearly identify the summary for
each part.
While this new line doesn't matter when executing this loop just once, it's useful for determining how each summary adds to the token value for the final summary. In most cases, this solution should work for medium and long content.
Recursive summary of summaries
When you've got an exceedingly long amount of text, the length of the concatenated summary may be larger than the available context window, thus causing the summarization to fail. To address this, you can recursively summarize the summaries.
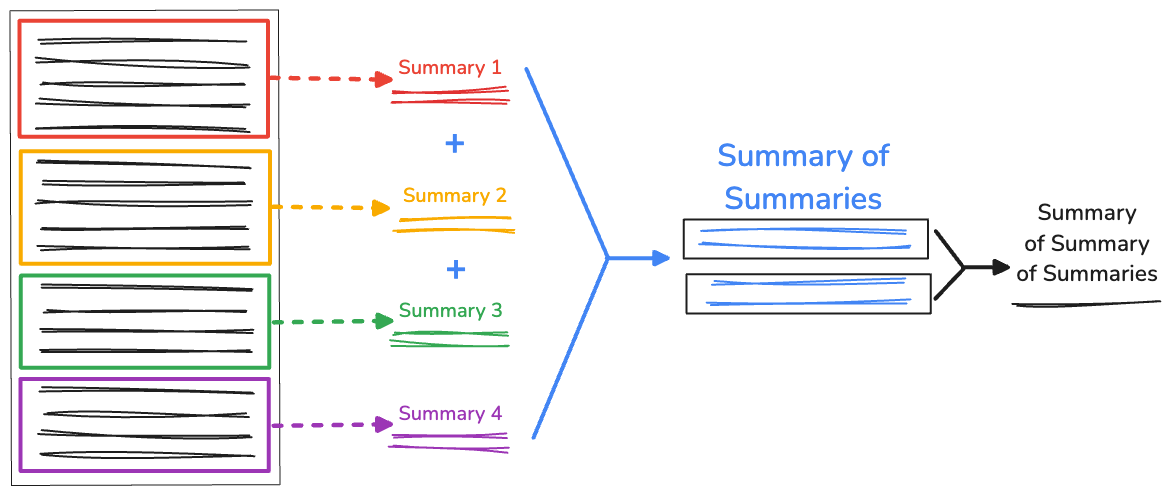
We still collect the initial splits generated by
RecursiveCharacterTextSplitter. Then, in the recursiveSummarizer() function,
we loop the summarization process based on the character length of the
concatenated splits. If the character length of the summaries exceeds 3000,
then we concatenate into fullSummaries. If the limit isn't reached, the
summary is saved as partialSummaries.
Once all of the summaries are generated, the final partial summaries are added
to the full summary. If there's just 1 summary in fullSummaries, no additional
recursion is needed. The function returns a final summary. If there's more than
one summary present, the function repeats and continues summarizing the partial
summaries.
We tested this solution with Internet Relay Chat (IRC) RFC, which has a whopping 110,030 characters that include 17,560 words. The Summarizer API provided the following summary:
Internet Relay Chat (IRC) is a way to communicate online in real-time using text messages. You can chat in channels or send private messages, and you can use commands to control the chat and interact with the server. It's like a chat room on the internet where you can type and see others' messages instantly.
That's pretty effective! And, it's only 309 characters.
Limitations
The summary of summaries technique helps you operate within a client-size model's context window. Though there are many benefits for client-side AI, you may encounter the following:
- Less accurate summaries: With recursion, the summary process repetition is possibly infinite, and each summary is farther from the original text. This means the model may generate a final summary that is too shallow to be useful.
- Slower performance: Each summary takes time to generate. Again, with an infinite possible number of summaries in larger texts, this approach may take several minutes to finish.
We have a summarizer demo available, and you can view the full source code.
Share your feedback
Try to use the summary of summaries technique with different lengths of input text, different split sizes, and different overlap lengths, with the Summarizer API.
- For feedback on Chrome's implementation, file a bug report or a feature request.
- Read the documentation on MDN
- Chat with the Chrome AI team about your summarization process or any other built-in AI questions.