


Gepubliceerd: 12 maart 2025
| Uitlegger | Web | Extensies | Chrome-status | Intentie |
|---|---|---|---|---|
| GitHub | Weergave | Intentie om te experimenteren |
Met de Summarizer API kunt u samenvattingen van informatie in verschillende lengtes en formaten genereren. Gebruik het met Gemini Nano in Chrome om gevolgtrekkingen aan de clientzijde uit te voeren en ingewikkelde of lange teksten beknopt uit te leggen.
Wanneer dit aan de clientzijde wordt uitgevoerd, kunt u lokaal met gegevens werken, waardoor u gevoelige gegevens veilig kunt houden en beschikbaarheid op schaal kunt bieden. Het contextvenster is echter veel kleiner dan bij server-side modellen, wat betekent dat het lastig kan zijn om zeer grote documenten samen te vatten. Om dit probleem op te lossen, kunt u de techniek van de samenvatting van samenvattingen gebruiken.
Wat is een samenvatting van samenvattingen?
Om de techniek van samenvatting van samenvattingen te gebruiken, splitst u de invoerinhoud op belangrijke punten en vat u vervolgens elk onderdeel afzonderlijk samen. U kunt de resultaten van elk deel samenvoegen en deze samengevoegde tekst vervolgens samenvatten in één definitieve samenvatting.

Splits uw inhoud zorgvuldig
Het is belangrijk om te bedenken hoe je een groot stuk tekst gaat opsplitsen, omdat het opsplitsen op verschillende locaties kan leiden tot radicaal verschillende resultaten van Gemini Nano of andere LLM's. Idealiter zouden teksten moeten worden gesplitst als er van onderwerp verandert, zoals bij een nieuw gedeelte van een artikel of bij een paragraaf. Het is belangrijk om te voorkomen dat de tekst midden in een woord of zin wordt gesplitst, wat betekent dat u niet een aantal tekens als enige splitsingsrichtlijn kunt instellen.
Er zijn veel manieren waarop u dit kunt doen, zonder handmatige inspanning. In het volgende voorbeeld hebben we de recursieve tekstsplitter van LangChain.js gebruikt, die de prestaties en de uitvoerkwaliteit in evenwicht brengt. Dit zou voor de meeste werkbelastingen moeten werken.
Bij het maken van een nieuw exemplaar zijn er twee belangrijke parameters:
-
chunkSizeis het maximale aantal toegestane tekens in elke splitsing. -
chunkOverlapis het aantal tekens dat tussen twee opeenvolgende splitsingen moet overlappen. Dit zorgt ervoor dat elk deel een deel van de context van het vorige deel bevat.
Splits de tekst met splitText() om bij elk stuk een reeks tekenreeksen terug te geven.
Bij de meeste LLM's wordt het contextvenster uitgedrukt in een aantal tokens, in plaats van in een aantal tekens. Gemiddeld bevat een token 4 tekens, dus u kunt het aantal tokens dat door een invoer wordt gebruikt, schatten door het aantal tekens door 4 te delen.
In ons voorbeeld is de chunkSize 3000 tekens en dat zijn ongeveer 750 tokens.
Genereer samenvattingen voor elke splitsing
Nadat u heeft ingesteld hoe de inhoud wordt gesplitst, kunt u voor elk onderdeel samenvattingen genereren met de Summarizer API.
Maak een instantie van de samenvatter met de create() functie . Om zoveel mogelijk context te behouden, hebben we de format ingesteld op plain-text , het type op tl;dr en de length op long .
Genereer vervolgens de samenvatting voor elke splitsing die is gemaakt door de RecursiveCharacterTextSplitter en voeg de resultaten samen in een nieuwe tekenreeks. We hebben elke samenvatting gescheiden met een nieuwe regel om de samenvatting voor elk onderdeel duidelijk te identificeren.
Hoewel deze nieuwe regel er niet toe doet wanneer deze lus slechts één keer wordt uitgevoerd, is deze wel handig om te bepalen hoe elke samenvatting bijdraagt aan de tokenwaarde voor de uiteindelijke samenvatting. In de meeste gevallen zou deze oplossing moeten werken voor middellange en lange inhoud.
Recursieve samenvatting van samenvattingen
Als u een buitengewoon lange hoeveelheid tekst heeft, kan de lengte van de samengevoegde samenvatting groter zijn dan het beschikbare contextvenster, waardoor de samenvatting mislukt. Om dit aan te pakken, kunt u de samenvattingen recursief samenvatten.
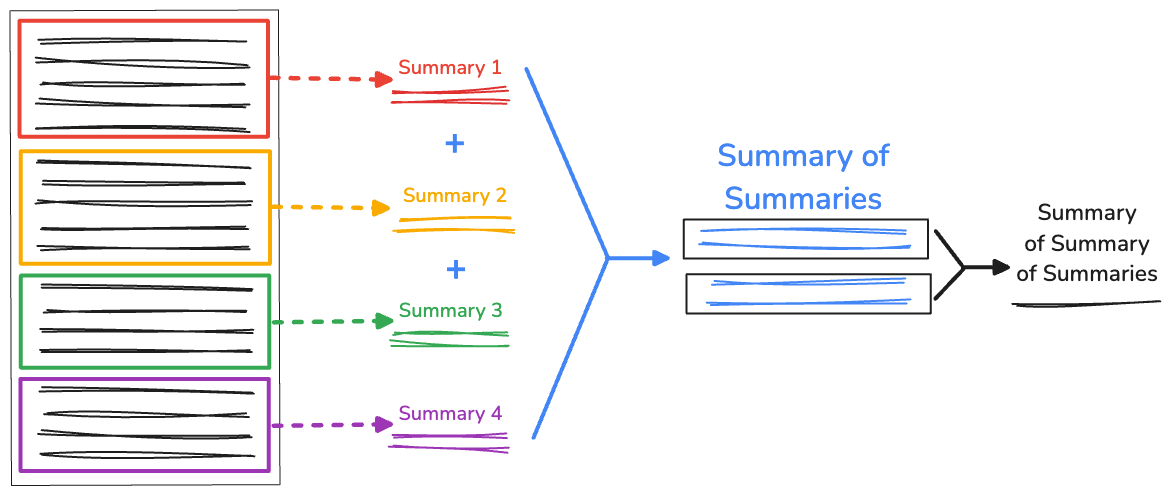
We verzamelen nog steeds de initiële splitsingen die zijn gegenereerd door RecursiveCharacterTextSplitter . Vervolgens herhalen we in de functie recursiveSummarizer() het samenvattingsproces op basis van de tekenlengte van de aaneengeschakelde splitsingen. Als de tekenlengte van de samenvattingen groter is dan 3000 , voegen we ze samen tot fullSummaries . Als de limiet niet wordt bereikt, wordt de samenvatting opgeslagen als partialSummaries .
Zodra alle samenvattingen zijn gegenereerd, worden de laatste gedeeltelijke samenvattingen toegevoegd aan de volledige samenvatting. Als er slechts 1 samenvatting in fullSummaries is, is er geen aanvullende recursie nodig. De functie retourneert een definitieve samenvatting. Als er meer dan één samenvatting aanwezig is, herhaalt de functie en gaat door met het samenvatten van de gedeeltelijke samenvattingen.
We hebben deze oplossing getest met Internet Relay Chat (IRC) RFC , dat maar liefst 110.030 tekens bevat, waarvan 17.560 woorden. De Summarizer API leverde de volgende samenvatting:
Internet Relay Chat (IRC) is een manier om in realtime online te communiceren via sms-berichten. U kunt in kanalen chatten of privéberichten verzenden, en u kunt opdrachten gebruiken om de chat te besturen en met de server te communiceren. Het is net een chatroom op internet waar u de berichten van anderen direct kunt typen en bekijken.
Dat is behoorlijk effectief! En het zijn slechts 309 tekens.
Beperkingen
De techniek van de samenvatting van samenvattingen helpt u te werken binnen het contextvenster van een model op klantgrootte. Hoewel er veel voordelen zijn voor AI aan de clientzijde , kunt u het volgende tegenkomen:
- Minder nauwkeurige samenvattingen : bij recursie is de herhaling van het samenvattingsproces mogelijk oneindig, en elke samenvatting is verder verwijderd van de originele tekst. Dit betekent dat het model een uiteindelijke samenvatting kan genereren die te oppervlakkig is om bruikbaar te zijn.
- Tragere prestaties : het genereren van elke samenvatting kost tijd. Nogmaals, met een oneindig mogelijk aantal samenvattingen in grotere teksten kan het enkele minuten duren voordat deze aanpak is voltooid.
We hebben een samenvattende demo beschikbaar , waarin u de volledige broncode kunt bekijken.
Deel uw feedback
Probeer de techniek van de samenvatting van samenvattingen te gebruiken met verschillende lengtes invoertekst, verschillende gesplitste formaten en verschillende overlappingslengtes, om te bepalen wat het beste werkt voor uw gebruiksscenario's.
Begin nu met het testen van de Summarizer API door deel te nemen aan de origin-proefperiode en deel uw feedback. Uw input kan rechtstreeks van invloed zijn op de manier waarop we toekomstige versies van deze API en alle ingebouwde AI API's bouwen en implementeren.
- Voor feedback over de implementatie van Chrome kunt u een bugrapport of een functieverzoek indienen.
- Bespreek het Summarizer API-ontwerp op GitHub door commentaar te geven op een bestaand probleem of een nieuw probleem te openen.
- Neem deel aan de inspanningen op het gebied van standaarden door lid te worden van de Web Incubator Community Group .
- Chat met het Chrome AI-team over uw samenvattingsproces of andere ingebouwde AI-vragen.