



Publié le 16 mai 2024
Les avis positifs et négatifs peuvent influencer la décision d'achat d'un acheteur.
Selon des études externes, 82 % des acheteurs en ligne recherchent activement les avis négatifs avant d'effectuer un achat. Ces avis négatifs sont utiles aux clients et aux entreprises, car ils peuvent contribuer à réduire les taux de retour et à aider les fabricants à améliorer leurs produits.
Voici quelques pistes pour améliorer la qualité des avis :
- Vérifiez que chaque avis ne contient pas de contenu toxique avant de l'envoyer. Nous pourrions encourager les utilisateurs à supprimer les propos offensants et les autres remarques inutiles afin que leur avis aide au mieux les autres utilisateurs à prendre une meilleure décision d'achat.
- Négatif : ce sac est nul, je le déteste.
- Négatif avec des commentaires utiles Les fermetures Éclair sont très rigides et le matériau semble bon marché. J'ai renvoyé ce sac.
- Générer automatiquement une note en fonction de la langue utilisée dans l'avis.
- Déterminez si l'avis est négatif ou positif.
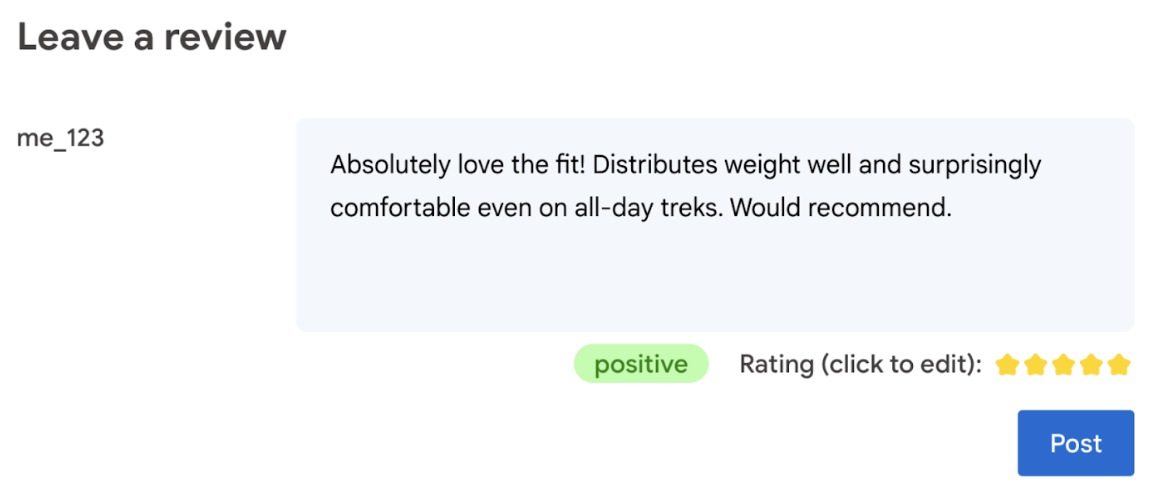
En fin de compte, l'utilisateur doit avoir le dernier mot sur la note du produit.
L'atelier de programmation suivant propose des solutions côté client, sur l'appareil et dans le navigateur. Aucune connaissance en développement d'IA, serveur ni clé API n'est requise.
Prérequis
Bien que l'IA côté serveur avec des solutions telles que l'API Gemini ou l'API OpenAI offre des solutions robustes pour de nombreuses applications, ce guide se concentre sur l'IA Web côté client. L'inférence de l'IA côté client se produit dans le navigateur, ce qui améliore l'expérience des utilisateurs Web en supprimant les allers-retours vers le serveur.
Dans cet atelier de programmation, nous utilisons différentes techniques pour vous montrer les outils dont vous disposez pour l'IA côté client.
Nous utilisons les bibliothèques et modèles suivants :
- TensforFlow.js pour l'analyse de la toxicité. TensorFlow.js est une bibliothèque de machine learning Open Source pour l'inférence et l'entraînement sur le Web.
- transformers.js pour l'analyse des sentiments. Transformers.js est une bibliothèque d'IA Web de Hugging Face.
- Gemma 2B pour les notes. Gemma est une famille de modèles ouverts et légers basés sur la recherche et la technologie que Google a utilisées pour créer les modèles Gemini. Pour exécuter Gemma dans le navigateur, nous l'utilisons avec l'API d'inférence LLM expérimentale de MediaPipe.
Points à prendre en compte concernant l'UX et la sécurité
Voici quelques points à prendre en compte pour garantir une expérience utilisateur et une sécurité optimales :
- Autoriser l'utilisateur à modifier la note. En fin de compte, l'utilisateur doit avoir le dernier mot sur la note du produit.
- Indiquez clairement à l'utilisateur que la note et les avis sont automatisés.
- Autoriser les utilisateurs à publier un avis classé comme toxique, mais effectuer une deuxième vérification sur le serveur. Cela permet d'éviter une expérience frustrante où un avis non toxique est classé à tort comme toxique (faux positif). Cela couvre également les cas où un utilisateur malveillant parvient à contourner la vérification côté client.
- Une vérification de la toxicité côté client est utile, mais peut être contournée. Assurez-vous également d'effectuer une vérification côté serveur.
Analyser la toxicité avec TensorFlow.js
Il est facile de commencer à analyser la toxicité d'un avis d'utilisateur avec TensorFlow.js.
- Installez et importez la bibliothèque TensorFlow.js et le modèle de toxicité.
- Définissez un niveau de confiance minimal pour les prédictions. La valeur par défaut est 0,85. Dans notre exemple, nous l'avons définie sur 0,9.
- Chargez le modèle de manière asynchrone.
- Classifiez l'avis de manière asynchrone. Notre code identifie les prédictions dépassant un seuil de 0,9 pour n'importe quelle catégorie.
Ce modèle peut catégoriser la toxicité en fonction des attaques identitaires, des insultes, de l'obscénité et plus encore.
Exemple :
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Déterminer le sentiment avec Transformers.js
Installez et importez la bibliothèque Transformers.js.
Configurez la tâche d'analyse des sentiments avec un pipeline dédié. Lorsqu'un pipeline est utilisé pour la première fois, le modèle est téléchargé et mis en cache. L'analyse des sentiments devrait alors être beaucoup plus rapide.
Classifiez l'avis de manière asynchrone. Utilisez un seuil personnalisé pour définir le niveau de confiance que vous jugez utilisable pour votre application.
Exemple :
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Suggérer une note avec Gemma et MediaPipe
L'API LLM Inference vous permet d'exécuter des grands modèles de langage (LLM) entièrement dans le navigateur.
Cette nouvelle fonctionnalité est particulièrement révolutionnaire compte tenu des besoins en mémoire et en calcul des LLM, qui sont plus de cent fois supérieurs à ceux des modèles côté client. Les optimisations de la pile Web le permettent, y compris les nouvelles opérations, la quantification, la mise en cache et le partage de poids. Source : "Grands modèles de langage sur l'appareil avec MediaPipe et TensorFlow Lite".
- Installez et importez l'API d'inférence LLM MediaPipe.
- Téléchargez un modèle. Ici, nous utilisons Gemma 2B, téléchargé depuis Kaggle. Gemma 2B est le plus petit des modèles à pondération ouverte de Google.
- Faites pointer le code vers les bons fichiers de modèle, avec
FilesetResolver. C'est important, car les modèles d'IA générative peuvent avoir une structure de répertoire spécifique pour leurs composants. - Chargez et configurez le modèle avec l'interface LLM de MediaPipe. Préparez le modèle à l'utilisation : spécifiez l'emplacement du modèle, la longueur de réponse souhaitée et le niveau de créativité souhaité avec la température.
- Donnez une requête au modèle (voir un exemple).
- Attendez la réponse du modèle.
- Analysez la réponse pour trouver la note : extrayez la note étoilée de la réponse du modèle.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Exemple de requête
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Points à retenir
Aucune expertise en IA/ML n'est requise. La conception d'une requête nécessite des itérations, mais le reste du code est un développement Web standard.
Les modèles côté client sont assez précis. Si vous exécutez les extraits de ce document, vous constaterez que l'analyse de la toxicité et des sentiments donne des résultats précis. Les notes Gemma correspondaient, pour la plupart, à celles du modèle Gemini pour quelques avis de référence testés. Pour valider cette précision, des tests supplémentaires sont nécessaires.
Cela dit, concevoir la requête pour Gemma 2B demande du travail. Comme Gemma 2B est un petit LLM, il a besoin d'une requête détaillée pour produire des résultats satisfaisants, notamment plus détaillée que celle requise avec l'API Gemini.
L'inférence peut être extrêmement rapide. Si vous exécutez les extraits de code de ce document, vous devriez constater que l'inférence peut être rapide, potentiellement plus rapide que les allers-retours du serveur, sur un certain nombre d'appareils. Cela dit, la vitesse d'inférence peut varier considérablement. Il est nécessaire de réaliser des benchmarks approfondis sur les appareils cibles. Nous nous attendons à ce que l'inférence du navigateur continue de s'accélérer avec WebGPU, WebAssembly et les mises à jour de la bibliothèque. Par exemple, Transformers.js ajoute la compatibilité avec WebGPU dans la version 3, ce qui peut accélérer considérablement l'inférence sur l'appareil.
La taille des téléchargements peut être très importante. L'inférence dans le navigateur est rapide, mais le chargement des modèles d'IA peut être difficile. Pour effectuer de l'IA dans le navigateur, vous avez généralement besoin d'une bibliothèque et d'un modèle, ce qui augmente la taille de téléchargement de votre application Web.
Alors que le modèle de toxicité TensorFlow (un modèle classique de traitement du langage naturel) ne pèse que quelques kilo-octets, les modèles d'IA générative comme le modèle d'analyse des sentiments par défaut de Transformers.js atteignent 60 Mo. Les grands modèles de langage comme Gemma peuvent atteindre 1,3 Go. Cette taille dépasse de loin la taille médiane de 2, 2 Mo des pages Web, qui est déjà beaucoup plus grande que celle recommandée pour des performances optimales. L'IA générative côté client est viable dans des scénarios spécifiques.
Le domaine de l'IA générative sur le Web évolue rapidement. Des modèles plus petits et optimisés pour le Web devraient émerger à l'avenir.
Étapes suivantes
Chrome teste une autre façon d'exécuter l'IA générative dans le navigateur. Vous pouvez vous inscrire au programme Preview pour le tester.