



Veröffentlicht: 16. Mai 2024
Positive und negative Rezensionen können die Kaufentscheidung eines Käufers beeinflussen.
Laut externen Studien suchen 82% der Onlinekäufer aktiv nach negativen Rezensionen, bevor sie einen Kauf tätigen. Diese negativen Rezensionen sind für Kunden und Unternehmen nützlich, da sie dazu beitragen können, die Rückgabequoten zu senken und Herstellern helfen, ihre Produkte zu verbessern.
Hier sind einige Möglichkeiten, wie Sie die Qualität von Rezensionen verbessern können:
- Jede Rezension wird vor dem Einreichen auf Toxizität geprüft. Wir könnten Nutzer dazu anregen, beleidigende Sprache und andere nicht hilfreiche Bemerkungen zu entfernen, damit ihre Rezension anderen Nutzern am besten bei der Kaufentscheidung helfen kann.
- Negativ: Diese Tasche ist schlecht und ich hasse sie.
- Negativ mit nützlichem Feedback Die Reißverschlüsse sind sehr steif und das Material fühlt sich billig an. Ich habe diese Tasche zurückgegeben.
- Automatische Generierung einer Bewertung basierend auf der in der Rezension verwendeten Sprache.
- Stellen Sie fest, ob die Rezension negativ oder positiv ist.
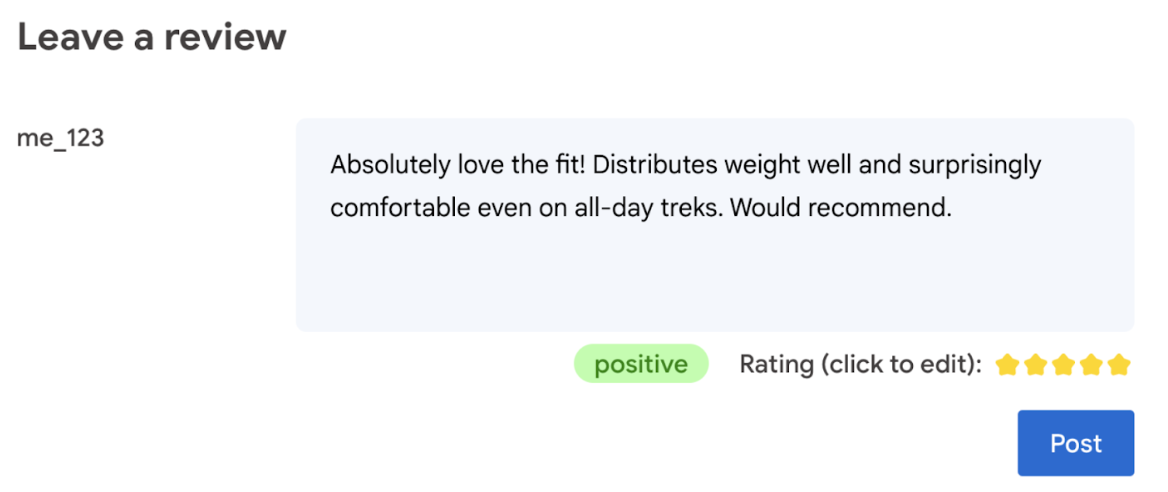
Letztendlich sollte der Nutzer das letzte Wort bei der Produktbewertung haben.
Das folgende Codelab bietet clientseitige Lösungen auf dem Gerät und im Browser. Es sind keine Kenntnisse in der KI-Entwicklung, Server oder API-Schlüssel erforderlich.
Vorbereitung
Serverseitige KI mit Lösungen wie der Gemini API oder der OpenAI API bietet zwar robuste Lösungen für viele Anwendungen, in diesem Leitfaden konzentrieren wir uns jedoch auf clientseitige Web-KI. Die KI-Inferenz auf Clientseite erfolgt im Browser, um die Nutzerfreundlichkeit für Webnutzer zu verbessern, da keine Server-Roundtrips erforderlich sind.
In diesem Codelab verwenden wir eine Mischung aus Techniken, um Ihnen zu zeigen, welche Tools für clientseitige KI zur Verfügung stehen.
Wir verwenden die folgenden Bibliotheken und Modelle:
- TensforFlow.js für die Analyse der Toxizität. TensorFlow.js ist eine Open-Source-Bibliothek für maschinelles Lernen für Inferenz und Training im Web.
- transformers.js für die Stimmungsanalyse. Transformers.js ist eine Web-KI-Bibliothek von Hugging Face.
- Gemma 2B für Sternebewertungen. Gemma ist eine Familie einfacher, offener Modelle, die auf Forschung und Technologie basieren, mit denen Google die Gemini-Modelle erstellt hat. Um Gemma im Browser auszuführen, verwenden wir es mit der experimentellen LLM Inference API von MediaPipe.
UX- und Sicherheitsaspekte
Hier sind einige Aspekte, die für eine optimale Nutzerfreundlichkeit und Sicherheit zu berücksichtigen sind:
- Der Nutzer darf die Bewertung bearbeiten. Letztendlich sollte der Nutzer das letzte Wort bei der Produktbewertung haben.
- Machen Sie dem Nutzer deutlich, dass die Bewertung und die Rezensionen automatisch generiert werden.
- Nutzern erlauben, eine als toxisch eingestufte Rezension zu posten, aber eine zweite Prüfung auf dem Server durchführen. So wird verhindert, dass eine nicht toxische Rezension fälschlicherweise als toxisch eingestuft wird (falsch positiv). Dies gilt auch für Fälle, in denen ein böswilliger Nutzer die clientseitige Prüfung umgehen kann.
- Eine clientseitige Prüfung auf schädliche Inhalte ist hilfreich, kann aber umgangen werden. Führen Sie die Prüfung auch serverseitig durch.
Toxizität mit TensorFlow.js analysieren
Mit TensorFlow.js lässt sich die Toxizität einer Nutzerrezension schnell analysieren.
- Installieren und importieren Sie die TensorFlow.js-Bibliothek und das Modell für toxische Sprache.
- Mindestkonfidenz für Vorhersagen festlegen Der Standardwert ist 0, 85. In unserem Beispiel haben wir ihn auf 0,9 festgelegt.
- Laden Sie das Modell asynchron.
- Rezension asynchron klassifizieren. Unser Code identifiziert Vorhersagen, die für eine beliebige Kategorie einen Schwellenwert von 0,9 überschreiten.
Dieses Modell kann Unangemessenheit in den Kategorien „Identitätsangriff“, „Beleidigung“, „Obszönität“ und mehr einteilen.
Beispiel:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Sentiment mit Transformers.js bestimmen
Installieren Sie die Transformers.js-Bibliothek und importieren Sie sie.
Richten Sie die Aufgabe für die Sentimentanalyse mit einer dedizierten Pipeline ein. Wenn eine Pipeline zum ersten Mal verwendet wird, wird das Modell heruntergeladen und im Cache gespeichert. Ab diesem Zeitpunkt sollte die Sentimentanalyse viel schneller erfolgen.
Rezension asynchron klassifizieren. Mit einem benutzerdefinierten Schwellenwert können Sie das Konfidenzniveau festlegen, das Sie für Ihre Anwendung als brauchbar erachten.
Beispiel:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Mit Gemma und MediaPipe eine Sternebewertung vorschlagen
Mit der LLM Inference API können Sie Large Language Models (LLMs) vollständig im Browser ausführen.
Diese neue Funktion ist besonders bahnbrechend, wenn man die Speicher- und Rechenanforderungen von LLMs berücksichtigt, die mehr als hundertmal höher sind als die von clientseitigen Modellen. Dies wird durch Optimierungen im gesamten Web-Stack ermöglicht, darunter neue Operationen, Quantisierung, Caching und die gemeinsame Nutzung von Gewichten. Quelle: „Large Language Models On-Device with MediaPipe and TensorFlow Lite“.
- Installieren und importieren Sie die MediaPipe LLM Inference API.
- Modell herunterladen Hier verwenden wir Gemma 2B, das von Kaggle heruntergeladen wurde. Gemma 2B ist das kleinste der Modelle mit offenem Gewicht von Google.
- Verweisen Sie den Code mit
FilesetResolverauf die richtigen Modelldateien. Das ist wichtig, da generative KI-Modelle möglicherweise eine bestimmte Verzeichnisstruktur für ihre Assets haben. - Laden und konfigurieren Sie das Modell mit der LLM-Schnittstelle von MediaPipe. Bereiten Sie das Modell für die Verwendung vor: Geben Sie den Modellstandort, die bevorzugte Länge der Antworten und den bevorzugten Grad der Kreativität mit der Temperatur an.
- Geben Sie dem Modell einen Prompt (Beispiel).
- Warten Sie auf die Antwort des Modells.
- Bewertung parsen: Extrahieren Sie die Sternebewertung aus der Antwort des Modells.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Beispielaussage
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Fazit
Keine KI-/ML-Expertise erforderlich: Das Erstellen eines Prompts erfordert Iterationen, der restliche Code ist jedoch Standard-Webentwicklung.
Clientseitige Modelle sind relativ genau. Wenn Sie die Snippets aus diesem Dokument ausführen, werden Sie feststellen, dass sowohl die Toxizitäts- als auch die Sentimentanalyse genaue Ergebnisse liefern. Die Gemma-Bewertungen stimmten größtenteils mit den Gemini-Modellbewertungen für einige getestete Referenzrezensionen überein. Um die Genauigkeit zu bestätigen, sind weitere Tests erforderlich.
Das Erstellen des Prompts für Gemma 2B ist jedoch mit Aufwand verbunden. Da Gemma 2B ein kleines LLM ist, benötigt es einen detaillierten Prompt, um zufriedenstellende Ergebnisse zu liefern – deutlich detaillierter als bei der Gemini API.
Die Inferenz kann blitzschnell erfolgen. Wenn Sie die Snippets aus diesem Dokument ausführen, werden Sie feststellen, dass die Inferenz auf einer Reihe von Geräten schnell sein kann, möglicherweise schneller als Server-Roundtrips. Die Inferenzgeschwindigkeit kann jedoch stark variieren. Es sind gründliche Benchmarks auf Zielgeräten erforderlich. Wir gehen davon aus, dass die Browserinferenz mit WebGPU, WebAssembly und Bibliotheksupdates immer schneller wird. Transformers.js bietet beispielsweise Web-GPU-Unterstützung in Version 3, wodurch die Inferenz auf dem Gerät um ein Vielfaches beschleunigt werden kann.
Die Downloadgrößen können sehr groß sein. Die Inferenz im Browser ist schnell, aber das Laden von KI-Modellen kann eine Herausforderung sein. Für die KI-Ausführung im Browser benötigen Sie in der Regel sowohl eine Bibliothek als auch ein Modell, was die Downloadgröße Ihrer Web-App erhöht.
Das Tensorflow-Modell für toxische Sprache (ein klassisches Natural Language Processing-Modell) ist nur wenige Kilobyte groß, während generative KI-Modelle wie das Standardmodell für die Sentimentanalyse von Transformers.js 60 MB erreichen. Large Language Models wie Gemma können bis zu 1,3 GB groß sein. Das ist weit mehr als die Webseitengröße von 2, 2 MB, die bereits viel größer ist als für eine optimale Leistung empfohlen. Clientseitige generative KI ist in bestimmten Szenarien sinnvoll.
Der Bereich der generativen KI im Web entwickelt sich rasant weiter. Es wird erwartet, dass in Zukunft kleinere, weboptimierte Modelle auf den Markt kommen werden.
Nächste Schritte
In Chrome wird eine weitere Möglichkeit getestet, generative KI im Browser auszuführen. Sie können sich für das Early-Access-Programm registrieren, um es zu testen.