



Data di pubblicazione: 16 maggio 2024
Le recensioni positive e negative possono influenzare la decisione di acquisto di un acquirente.
Secondo una ricerca esterna, l'82% degli acquirenti online cerca attivamente recensioni negative prima di effettuare un acquisto. Queste recensioni negative sono utili per i clienti e per le attività, in quanto la loro disponibilità può contribuire a ridurre i tassi di reso e aiutare i produttori a migliorare i propri prodotti.
Ecco alcuni modi per migliorare la qualità delle recensioni:
- Controlla ogni recensione per rilevare eventuali contenuti tossici prima dell'invio. Potremmo incoraggiare
gli utenti a rimuovere un linguaggio offensivo, nonché altri commenti inutili, in modo che
la loro recensione aiuti al meglio gli altri utenti a prendere una decisione di acquisto migliore.
- Negativo: questa borsa fa schifo e la odio.
- Negativo con feedback utile Le cerniere sono molto rigide e il materiale sembra economico. Ho restituito questa borsa.
- Generare automaticamente una classificazione in base alla lingua utilizzata nella recensione.
- Stabilisci se la recensione è negativa o positiva.
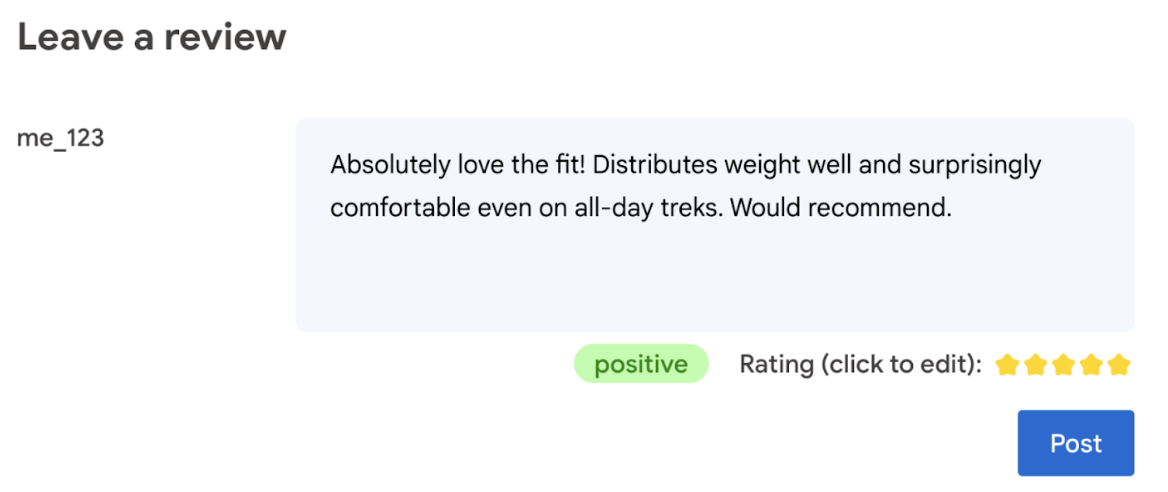
In definitiva, l'utente deve avere l'ultima parola sulla valutazione del prodotto.
Il seguente codelab offre soluzioni lato client, sul dispositivo e nel browser. Non sono richieste conoscenze di sviluppo dell'AI, server o chiavi API.
Prerequisiti
Sebbene l'AI lato server con soluzioni (come l'API Gemini o l'API OpenAI) offra soluzioni robuste per molte applicazioni, in questa guida ci concentriamo sull'AI web lato client. L'inferenza dell'AI lato client viene eseguita nel browser per migliorare l'esperienza degli utenti web eliminando i round trip del server.
In questo codelab, utilizziamo un mix di tecniche per mostrarti cosa c'è nella tua cassetta degli attrezzi per l'AI lato client.
Utilizziamo le seguenti librerie e modelli:
- TensforFlow.js per l'analisi della tossicità. TensorFlow.js è una libreria di machine learning open source per l'inferenza e l'addestramento sul web.
- transformers.js per l'analisi del sentiment. Transformers.js è una libreria di AI web di Hugging Face.
- Gemma 2B per le valutazioni a stelle. Gemma è una famiglia di modelli aperti leggeri creati sulla base della ricerca e della tecnologia che Google ha utilizzato per creare i modelli Gemini. Per eseguire Gemma nel browser, lo utilizziamo con l'API LLM Inference sperimentale di MediaPipe.
Considerazioni relative all'esperienza utente e alla sicurezza
Per garantire un'esperienza utente e una sicurezza ottimali, è necessario tenere in considerazione alcuni aspetti:
- Consenti all'utente di modificare la valutazione. In definitiva, l'utente deve avere l'ultima parola sulla valutazione del prodotto.
- Indica chiaramente all'utente che la valutazione e le recensioni sono automatizzate.
- Consenti agli utenti di pubblicare una recensione classificata come tossica, ma esegui un secondo controllo sul server. In questo modo si evita un'esperienza frustrante in cui una recensione non tossica viene classificata erroneamente come tossica (un falso positivo). Ciò include anche i casi in cui un utente malintenzionato riesce a bypassare il controllo lato client.
- Un controllo della tossicità lato client è utile, ma può essere aggirato. Assicurati di eseguire un controllo anche lato server.
Analizzare la tossicità con TensorFlow.js
È facile iniziare ad analizzare la tossicità di una recensione utente con TensorFlow.js.
- Installa e importa la libreria TensorFlow.js e il modello di tossicità.
- Imposta una confidenza minima della previsione. Il valore predefinito è 0, 85 e nel nostro esempio l'abbiamo impostato su 0,9.
- Carica il modello in modo asincrono.
- Classifica la recensione in modo asincrono. Il nostro codice identifica le previsioni che superano una soglia di 0,9 per qualsiasi categoria.
Questo modello può classificare la tossicità in base ad attacchi all'identità, insulti, oscenità e altro ancora.
Ad esempio:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Determinare il sentiment con Transformers.js
Installa e importa la libreria Transformers.js.
Configura l'attività di analisi del sentiment con una pipeline dedicata. Quando una pipeline viene utilizzata per la prima volta, il modello viene scaricato e memorizzato nella cache. Da quel momento in poi, l'analisi del sentiment dovrebbe essere molto più veloce.
Classifica la recensione in modo asincrono. Utilizza una soglia personalizzata per impostare il livello di confidenza che consideri utilizzabile per la tua applicazione.
Ad esempio:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Suggerire una valutazione a stelle con Gemma e MediaPipe
Con l'API LLM Inference, puoi eseguire modelli linguistici di grandi dimensioni (LLM) completamente nel browser.
Questa nuova funzionalità è particolarmente trasformativa se si considerano i requisiti di memoria e di calcolo degli LLM, che sono oltre cento volte più grandi dei modelli lato client. Le ottimizzazioni dello stack web lo rendono possibile, tra cui nuove operazioni, quantizzazione, memorizzazione nella cache e condivisione dei pesi. Fonte: "Large Language Models On-Device with MediaPipe and TensorFlow Lite".
- Installa e importa l'API MediaPipe LLM Inference.
- Scaricare un modello. Qui utilizziamo Gemma 2B, scaricato da Kaggle. Gemma 2B è il più piccolo dei modelli open-weight di Google.
- Punta il codice ai file del modello corretti, con
FilesetResolver. Ciò è importante perché i modelli di AI generativa potrebbero avere una struttura di directory specifica per i loro asset. - Carica e configura il modello con l'interfaccia LLM di MediaPipe. Prepara il modello per l'uso: specifica la posizione del modello, la lunghezza preferita delle risposte e il livello di creatività preferito con la temperatura.
- Fornisci un prompt al modello (vedi un esempio).
- Attendi la risposta del modello.
- Analizza la valutazione: estrai la valutazione a stelle dalla risposta del modello.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Testo di esempio
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Concetti principali
Non sono richieste competenze di AI/ML. La progettazione di un prompt richiede iterazioni, ma il resto del codice è uno sviluppo web standard.
I modelli lato client sono piuttosto precisi. Se esegui gli snippet di questo documento, noterai che sia l'analisi della tossicità che quella del sentiment forniscono risultati accurati. Le valutazioni di Gemma, per la maggior parte, corrispondevano a quelle del modello Gemini per alcune recensioni di riferimento testate. Per convalidare l'accuratezza, sono necessari ulteriori test.
Detto questo, la progettazione del prompt per Gemma 2B richiede lavoro. Poiché Gemma 2B è un LLM di piccole dimensioni, ha bisogno di un prompt dettagliato per produrre risultati soddisfacenti, in particolare più dettagliati di quelli richiesti con l'API Gemini.
L'inferenza può essere velocissima. Se esegui gli snippet di questo documento, dovresti notare che l'inferenza può diventare veloce, potenzialmente più veloce dei round trip del server, su diversi dispositivi. Detto questo, la velocità di inferenza può variare notevolmente. È necessario un benchmarking approfondito sui dispositivi di destinazione. Prevediamo che l'inferenza del browser diventerà sempre più veloce con WebGPU, WebAssembly e gli aggiornamenti delle librerie. Ad esempio, Transformers.js aggiunge il supporto di Web GPU nella versione 3, che può velocizzare di molto l'inferenza sul dispositivo.
Le dimensioni dei download possono essere molto grandi. L'inferenza nel browser è veloce, ma il caricamento dei modelli di AI può essere una sfida. Per eseguire l'AI nel browser, in genere sono necessari sia una libreria che un modello, che aumentano le dimensioni del download della tua app web.
Mentre il modello di tossicità di TensorFlow (un classico modello di elaborazione del linguaggio naturale) pesa solo pochi kilobyte, i modelli di AI generativa come il modello di analisi del sentiment predefinito di Transformers.js raggiungono i 60 MB. I modelli linguistici di grandi dimensioni come Gemma possono avere una dimensione massima di 1,3 GB. Supera di gran lunga le dimensioni medie di 2, 2 MB di una pagina web, che sono già molto più grandi di quelle consigliate per ottenere prestazioni ottimali. L'AI generativa lato client è fattibile in scenari specifici.
Il campo dell'AI generativa sul web è in rapida evoluzione. In futuro dovrebbero emergere modelli più piccoli e ottimizzati per il web.
Passaggi successivi
Chrome sta sperimentando un altro modo per eseguire l'AI generativa nel browser. Puoi registrarti al programma di anteprima anticipata per provarlo.