



פורסם: 16 במאי 2024
ביקורות חיוביות ושליליות יכולות לעזור לקונים לקבל החלטה לגבי רכישה.
על פי מחקר חיצוני, 82% מהקונים באינטרנט מחפשים באופן פעיל ביקורות שליליות לפני שהם מבצעים רכישה. הביקורות השליליות האלה מועילות ללקוחות ולעסקים, כי הזמינות של ביקורות שליליות יכולה לעזור להפחית את שיעורי ההחזרים ולעזור ליצרנים לשפר את המוצרים שלהם.
הנה כמה דרכים לשפר את איכות הביקורות:
- לפני ששולחים ביקורת, כדאי לבדוק אם היא רעילה. אנחנו יכולים לעודד משתמשים להסיר שפה פוגעת, וגם הערות אחרות שלא מועילות, כדי שהביקורת שלהם תעזור למשתמשים אחרים לקבל החלטה מושכלת יותר לגבי קנייה.
- שלילי: התיק הזה גרוע ואני שונא אותו.
- שלילי עם משוב מועיל הרוכסנים קשים מאוד והחומר מרגיש זול. החזרתי את התיק הזה.
- יצירת דירוג באופן אוטומטי על סמך השפה שבה נעשה שימוש בביקורת.
- האם הביקורת חיובית או שלילית?
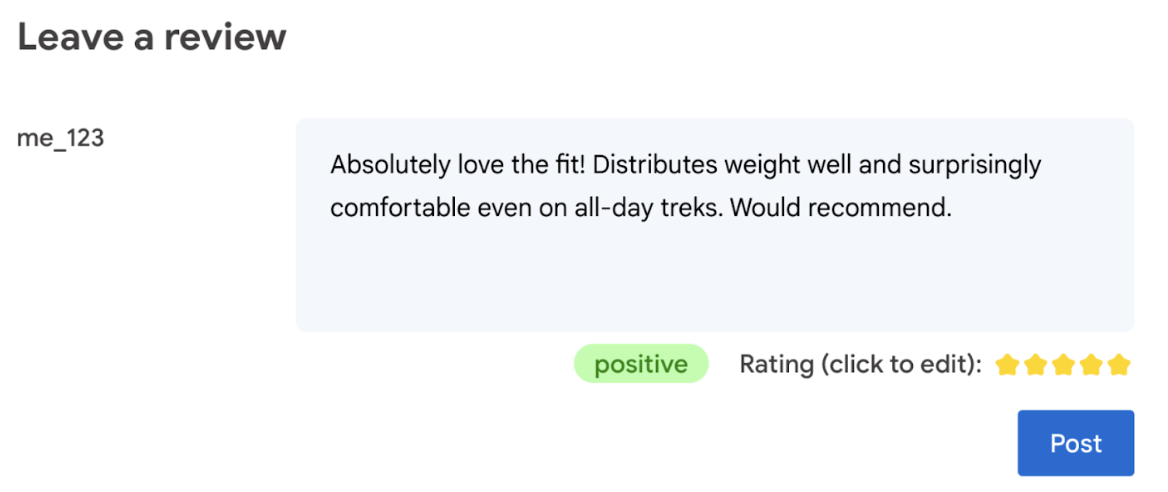
בסופו של דבר, למשתמש צריכה להיות המילה האחרונה לגבי דירוג המוצר.
ב-codelab הבא מוצעים פתרונות בצד הלקוח, במכשיר ובדפדפן. לא נדרש ידע בפיתוח AI, שרתים או מפתחות API.
דרישות מוקדמות
בעוד ש-AI בצד השרת עם פתרונות (כמו Gemini API או OpenAI API) מציע פתרונות חזקים להרבה אפליקציות, במדריך הזה אנחנו מתמקדים ב-AI באינטרנט בצד הלקוח. הסקת מסקנות מבוססת-AI בצד הלקוח מתבצעת בדפדפן, כדי לשפר את חוויית המשתמש של משתמשי האינטרנט על ידי הסרת נסיעות הלוך ושוב לשרת.
ב-codelab הזה אנחנו משתמשים בשילוב של טכניקות כדי להראות לכם מה יש בארגז הכלים שלכם ל-AI בצד הלקוח.
אנחנו משתמשים בספריות ובמודלים הבאים:
- TensforFlow.js לניתוח רמת הרעילות. TensorFlow.js היא ספרייה בקוד פתוח של למידת מכונה, שמאפשרת הסקה ואימון באינטרנט.
- transformers.js לניתוח סנטימנט. Transformers.js היא ספריית AI לאינטרנט מבית Hugging Face.
- Gemma 2B לדירוגי כוכבים. Gemma הוא משפחה של מודלים קלי משקל ופתוחים, שמבוססים על המחקר והטכנולוגיה שבהם Google השתמשה כדי ליצור את מודלי Gemini. כדי להריץ את Gemma בדפדפן, אנחנו משתמשים בו עם ממשק ה-API הניסיוני של MediaPipe להסקת מסקנות של LLM.
שיקולים לגבי חוויית המשתמש והבטיחות
כדי להבטיח חוויית משתמש אופטימלית ובטוחה, חשוב לשים לב לכמה דברים:
- המשתמש יכול לערוך את הדירוג. בסופו של דבר, המשתמש צריך להיות זה שמחליט מה יהיה דירוג המוצר.
- חשוב להבהיר למשתמש שהדירוג והביקורות הם אוטומטיים.
- המשתמשים יכולים לפרסם ביקורת שסווגה כרעילה, אבל תתבצע בדיקה שנייה בשרת. כך נמנעת חוויה מתסכלת שבה ביקורת לא רעילה מסווגת בטעות כרעילה (תוצאה חיובית כוזבת). ההגנה הזו חלה גם על מקרים שבהם משתמש זדוני מצליח לעקוף את הבדיקה בצד הלקוח.
- בדיקת רעילות בצד הלקוח מועילה, אבל אפשר לעקוף אותה. חשוב לוודא שאתם מריצים בדיקה גם בצד השרת.
ניתוח רעילות באמצעות TensorFlow.js
קל ומהיר להתחיל לנתח את רמת הרעילות של ביקורת משתמש באמצעות TensorFlow.js.
- מתקינים ומייבאים את ספריית TensorFlow.js ואת מודל הרעילות.
- הגדרת ודאות מינימלית של התחזית. ערך ברירת המחדל הוא 0.85, ובדוגמה שלנו הגדרנו אותו ל-0.9.
- טוענים את המודל באופן אסינכרוני.
- סיווג הביקורת באופן אסינכרוני. הקוד שלנו מזהה חיזויים שחורגים מסף של 0.9 בכל קטגוריה.
המודל הזה יכול לסווג רעילות לפי קטגוריות כמו התקפה על זהות, עלבון, גסות ועוד.
לדוגמה:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
קביעת סנטימנט באמצעות Transformers.js
מתקינים ומייבאים את הספרייה Transformers.js.
מגדירים את המשימה של ניתוח הסנטימנטים באמצעות צינור ייעודי. כשמשתמשים בצינור בפעם הראשונה, המודל מורד ונשמר במטמון. מעכשיו, ניתוח הסנטימנט יהיה מהיר הרבה יותר.
סיווג הביקורת באופן אסינכרוני. אפשר להשתמש בסף מותאם אישית כדי להגדיר את רמת הביטחון שאתם רואים כרלוונטית לשימוש באפליקציה שלכם.
לדוגמה:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
הצעת דירוג כוכבים באמצעות Gemma ו-MediaPipe
באמצעות LLM Inference API, אפשר להריץ מודלים גדולים של שפה (LLM) ישירות בדפדפן.
היכולת החדשה הזו משמעותית במיוחד בהתחשב בדרישות הזיכרון והמחשוב של מודלים גדולים של שפה (LLM), שהן גדולות פי מאה יותר מאלה של מודלים בצד הלקוח. האופטימיזציות שמתבצעות בכל שכבות האינטרנט מאפשרות זאת, כולל פעולות חדשות, קוונטיזציה, שמירת נתונים במטמון ושיתוף משקלים. מקור: Large Language Models On-Device with MediaPipe and TensorFlow Lite
- מתקינים ומייבאים את MediaPipe LLM inference API.
- הורדת מודל בדוגמה הזו אנחנו משתמשים ב-Gemma 2B, שהורד מ-Kaggle. Gemma 2B הוא הקטן ביותר מבין המודלים של Google עם משקלים פתוחים.
- מכוונים את הקוד לקובצי המודל הנכונים, באמצעות
FilesetResolver. הפעולה הזו חשובה כי יכול להיות שלמודלים של AI גנרטיבי יש מבנה ספציפי של ספריות לנכסים שלהם. - טוענים את המודל ומגדירים אותו באמצעות ממשק ה-LLM של MediaPipe. הכנת המודל לשימוש: מציינים את המיקום של המודל, את אורך התשובות המועדף ואת רמת היצירתיות המועדפת באמצעות הטמפרטורה.
- נותנים למודל הנחיה (לדוגמה).
- מחכים לתשובה של המודל.
- ניתוח כדי לקבל את הדירוג: חילוץ דירוג הכוכבים מהתגובה של המודל.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
הנחיה לדוגמה
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
חטיפות דסקית
לא נדרשת מומחיות ב-AI/ML. כדי לעצב הנחיה צריך לבצע איטרציות, אבל שאר הקוד הוא קוד סטנדרטי לפיתוח אתרים.
המודלים בצד הלקוח די מדויקים. אם מריצים את קטעי הקוד מהמסמך הזה, אפשר לראות שגם ניתוח הרעילות וגם ניתוח הסנטימנט מניבים תוצאות מדויקות. ברוב המקרים, הדירוגים של Gemma תאמו לדירוגים של מודל Gemini בכמה ביקורות לדוגמה שנבדקו. כדי לוודא שהמידע מדויק, נדרשות בדיקות נוספות.
עם זאת, צריך להשקיע מאמץ בעיצוב ההנחיה ל-Gemma 2B. מכיוון ש-Gemma 2B הוא מודל שפה גדול (LLM) קטן, הוא צריך הנחיה מפורטת כדי להפיק תוצאות משביעות רצון – מפורטת יותר מזו שנדרשת ב-Gemini API.
הסקת מסקנות יכולה להיות מהירה מאוד. אם מריצים את קטעי הקוד מהמסמך הזה, אפשר לראות שההסקה יכולה להיות מהירה, ואולי מהירה יותר מהזמן של הלוך ושוב לשרת, במספר מכשירים. עם זאת, מהירות ההסקה יכולה להשתנות מאוד. צריך לבצע השוואה מקיפה בין ביצועים במכשירי היעד. אנחנו צופים שההסקה בדפדפן תהיה מהירה יותר ויותר בעזרת WebGPU, WebAssembly ועדכוני ספריות. לדוגמה, בספריית Transformers.js נוספה תמיכה ב-Web GPU בגרסה 3, שיכולה להאיץ משמעותית את ההסקות במכשיר.
הגודל של ההורדות יכול להיות מאוד גדול. הסקת מסקנות בדפדפן היא מהירה, אבל טעינת מודלים של AI יכולה להיות מאתגרת. כדי להפעיל AI בדפדפן, בדרך כלל צריך גם ספרייה וגם מודל, שמוסיפים לגודל ההורדה של אפליקציית האינטרנט.
מודל הרעילות של Tensorflow (מודל קלאסי לעיבוד שפה טבעית) הוא רק כמה קילובייט, אבל מודלים של AI גנרטיבי כמו מודל ברירת המחדל של ניתוח הסנטימנט של Transformers.js מגיע ל-60MB. מודלים גדולים של שפה כמו Gemma יכולים להגיע לגודל של 1.3GB. הגודל הזה גדול בהרבה מהגודל המומלץ לביצועים אופטימליים, והוא חורג מהגודל החציוני של 2.2MB לדף אינטרנט. AI גנרטיבי בצד הלקוח הוא פתרון אפשרי בתרחישים ספציפיים.
תחום ה-AI הגנרטיבי באינטרנט מתפתח במהירות! צפויים להופיע בעתיד מודלים קטנים יותר שעברו אופטימיזציה לאינטרנט.
השלבים הבאים
אנחנו ב-Chrome מנסים דרך נוספת להפעיל AI גנרטיבי בדפדפן. אתם יכולים להירשם לתוכנית הגישה המוקדמת כדי לבדוק את התכונה.