

A maioria dos modelos de linguagem tem uma coisa em comum: eles são bem grandes para um recurso transferido pela Internet. O menor modelo de detecção de objetos do MediaPipe (SSD MobileNetV2 float16) pesa 5,6 MB, e o maior tem cerca de 25 MB.
O modelo de linguagem grande (LLM) de código aberto
gemma-2b-it-gpu-int4.bin
tem 1,35 GB, o que é considerado muito pequeno para um LLM.
Os modelos de IA generativa podem ser enormes. É por isso que muito do uso de IA hoje em dia acontece na nuvem. Cada vez mais, os apps estão executando modelos altamente otimizados diretamente
no dispositivo. Embora existam demonstrações de LLMs executados no navegador, confira alguns exemplos de outros modelos de nível de produção executados no navegador:
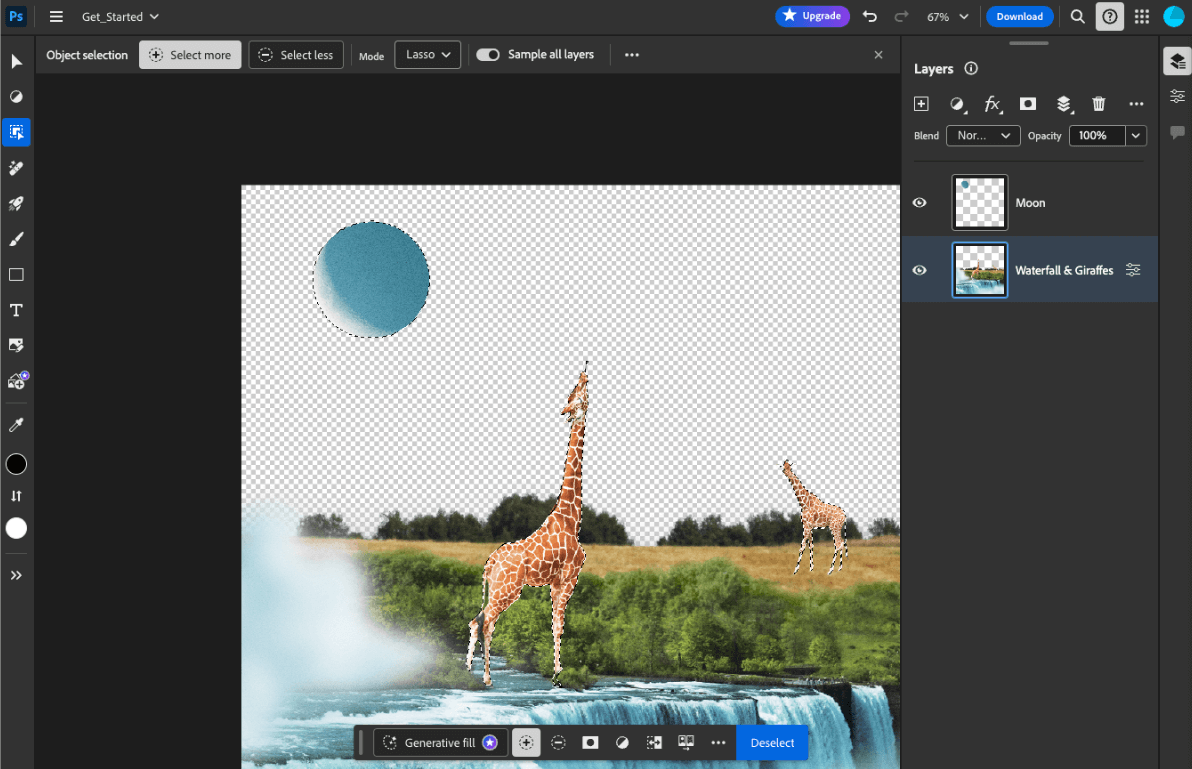
- O Adobe Photoshop executa uma variante do modelo
Conv2Dno dispositivo para a ferramenta de seleção inteligente de objetos. - O Google Meet executa uma versão otimizada do
MobileNetV3-smallpara segmentação de pessoas no recurso de desfoque de plano de fundo. - A Tokopedia executa o modelo
MediaPipeFaceDetector-TFJSpara detecção facial em tempo real e evitar inscrições inválidas no serviço. - O Google Colab permite que os usuários usem modelos do disco rígido em notebooks do Colab.
Para acelerar os futuros lançamentos dos seus aplicativos, armazene explicitamente em cache os dados do modelo no dispositivo, em vez de depender do cache implícito do navegador HTTP.
Embora este guia use o modelo gemma-2b-it-gpu-int4.bin para criar um chatbot, a abordagem pode ser generalizada para se adequar a outros modelos e casos de uso no dispositivo. A maneira mais comum de conectar um app a um modelo é veicular o
modelo junto com o restante dos recursos do app. É crucial otimizar a veiculação.
Configurar os cabeçalhos de cache corretos
Se você veicula modelos de IA do seu servidor, é importante configurar o cabeçalho Cache-Control correto. O exemplo a seguir mostra uma configuração padrão sólida, que você pode usar
para as necessidades do seu app.
Cache-Control: public, max-age=31536000, immutable
Cada versão lançada de um modelo de IA é um recurso estático. O conteúdo que nunca muda deve receber um max-age longo combinado com eliminação de cache no URL da solicitação. Se você precisar atualizar o modelo, dê a ele um novo URL.
Quando o usuário recarrega a página, o cliente envia uma solicitação de revalidação, mesmo
que o servidor saiba que o conteúdo está estável. A diretiva
immutable
indica explicitamente que a revalidação é desnecessária, porque o
conteúdo não vai mudar. A diretiva immutable não é amplamente compatível com navegadores e servidores proxy ou de cache intermediários, mas combinando com a diretiva max-age, que é universalmente compreendida, é possível garantir a máxima compatibilidade. A diretiva de resposta public
indica que a resposta pode ser armazenada em um cache compartilhado.

Cache-Control
enviados pelo Hugging Face ao solicitar um modelo de IA.
(Fonte)
Fazer cache de modelos de IA no lado do cliente
Ao veicular um modelo de IA, é importante armazenar explicitamente o modelo em cache no navegador. Isso garante que os dados do modelo estejam disponíveis depois que um usuário recarregar o app.
Há várias técnicas que podem ser usadas para isso. Para os exemplos de código a seguir, suponha que cada arquivo de modelo esteja armazenado em um objeto Blob chamado blob na memória.
Para entender o desempenho, cada exemplo de código é anotado com os métodos
performance.mark()
e performance.measure(). Essas medidas dependem do dispositivo e não podem ser generalizadas.

É possível usar uma das seguintes APIs para armazenar modelos de IA em cache no navegador: API Cache, a API Origin Private File System e a API IndexedDB. A recomendação geral é usar a API Cache, mas este guia discute as vantagens e desvantagens de todas as opções.
Cache API
A API Cache oferece
armazenamento persistente para pares de objetos Request
e Response
armazenados em cache na memória de longa duração. Embora esteja definida na especificação de service workers, é possível usar essa API na linha de execução principal ou em um worker comum. Para usar fora de um contexto de service worker, chame o método Cache.put() com um objeto Response sintético, pareado com um URL sintético em vez de um objeto Request.
Este guia pressupõe um blob na memória. Use um URL falso como a chave de cache e um
Response sintético com base no blob. Se você fizesse o download direto do modelo, usaria o Response que receberia ao fazer uma solicitação fetch().
Por exemplo, veja como armazenar e restaurar um arquivo de modelo com a API Cache.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
API Origin Private File System
O Origin Private File System (OPFS) é um padrão relativamente novo para um endpoint de armazenamento. Ele é privado para a origem da página e, portanto, invisível para o usuário, ao contrário do sistema de arquivos regular. Ele fornece acesso a um arquivo especial altamente otimizado para desempenho e oferece acesso de gravação ao conteúdo dele.
Por exemplo, veja como armazenar e restaurar um arquivo de modelo no OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
API IndexedDB
O IndexedDB é um padrão bem estabelecido para armazenar dados arbitrários de maneira persistente no navegador. Ela é conhecida por ter uma API um pouco complexa, mas, ao usar uma biblioteca de wrapper, como idb-keyval, é possível tratar o IndexedDB como um armazenamento de chave-valor clássico.
Exemplo:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Marcar o armazenamento como persistente
Chame navigator.storage.persist()
no final de qualquer um desses métodos de armazenamento em cache para pedir permissão de uso
do armazenamento persistente. Esse método retorna uma promessa que é resolvida como true se a permissão for concedida e false caso contrário. O navegador
pode ou não atender à solicitação,
dependendo das regras específicas do navegador.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Caso especial: usar um modelo em um disco rígido
Você pode fazer referência a modelos de IA diretamente do disco rígido de um usuário como alternativa ao armazenamento do navegador. Essa técnica pode ajudar apps focados em pesquisa a mostrar a viabilidade de executar determinados modelos no navegador ou permitir que artistas usem modelos autotreinados em apps de criatividade especializada.
API File System Access
Com a API File System Access, é possível abrir arquivos do disco rígido e receber um FileSystemFileHandle que pode ser mantido no IndexedDB.
Com esse padrão, o usuário só precisa conceder acesso ao arquivo do modelo uma vez. Graças às permissões persistentes,
o usuário pode conceder acesso permanente ao arquivo. Depois de recarregar o
app e um gesto necessário do usuário, como um clique do mouse, o
FileSystemFileHandle pode ser restaurado do IndexedDB com acesso ao arquivo
no disco rígido.
As permissões de acesso ao arquivo são consultadas e solicitadas, se necessário, o que torna esse processo perfeito para recarregamentos futuros. O exemplo a seguir mostra como receber um handle para um arquivo do disco rígido e, em seguida, armazenar e restaurar o handle.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Esses métodos não são mutuamente exclusivos. Pode haver um caso em que você armazena explicitamente um modelo em cache no navegador e usa um modelo do disco rígido de um usuário.
Demonstração
Você pode conferir os três métodos de armazenamento de casos regulares e o método de disco rígido implementados na demonstração do LLM do MediaPipe.
Bônus: fazer o download de um arquivo grande em partes
Se você precisar baixar um modelo de IA grande da Internet, faça o download em paralelo em partes separadas e depois junte tudo novamente no cliente.
O pacote fetch-in-chunks fornece uma função auxiliar que pode ser usada no código. Basta transmitir o url. O maxParallelRequests (padrão: 6), o chunkSize (padrão: tamanho do arquivo a ser baixado dividido por maxParallelRequests), a função progressCallback (que gera relatórios sobre o downloadedBytes e o fileSize total) e o signal para um indicador AbortSignal são opcionais.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Escolha o método certo para você
Este guia abordou vários métodos para armazenar em cache modelos de IA de maneira eficaz no navegador, uma tarefa crucial para melhorar a experiência do usuário e o desempenho do app. A equipe de armazenamento do Chrome recomenda a API Cache para um desempenho ideal, garantindo acesso rápido aos modelos de IA, reduzindo os tempos de carregamento e melhorando a capacidade de resposta.
O OPFS e o IndexedDB são opções menos utilizáveis. As APIs OPFS e IndexedDB precisam serializar os dados antes de serem armazenados. O IndexedDB também precisa desserializar os dados quando eles são recuperados, o que o torna o pior lugar para armazenar modelos grandes.
Para aplicativos de nicho, a API File System Access oferece acesso direto aos arquivos no dispositivo de um usuário, ideal para quem gerencia os próprios modelos de IA.
Se você precisar proteger seu modelo de IA, mantenha-o no servidor. Depois de armazenados no cliente, é fácil extrair os dados do cache e do IndexedDB com o DevTools ou a extensão OFPS DevTools. Essas APIs de armazenamento são inerentemente iguais em segurança. Você pode ser tentado a armazenar uma versão criptografada do modelo, mas precisará fornecer a chave de descriptografia ao cliente, o que pode ser interceptado. Isso significa que a tentativa de um usuário malicioso de roubar seu modelo é um pouco mais difícil, mas não impossível.
Recomendamos que você escolha uma estratégia de cache que se alinhe aos requisitos do seu app, ao comportamento do público-alvo e às características dos modelos de IA usados. Isso garante que seus aplicativos sejam responsivos e robustos em várias condições de rede e restrições do sistema.
Agradecimentos
Revisado por Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan e Rachel Andrew.