

Sebagian besar model bahasa memiliki satu kesamaan: ukurannya
cukup besar untuk resource yang
ditransfer melalui Internet. Model deteksi objek MediaPipe terkecil (SSD MobileNetV2 float16) berukuran 5,6 MB dan yang terbesar berukuran sekitar 25 MB.
Model bahasa besar (LLM) open source
gemma-2b-it-gpu-int4.bin
berukuran 1,35 GB—dan ini dianggap sangat kecil untuk LLM.
Model AI generatif bisa sangat besar. Itulah sebabnya banyak penggunaan AI saat ini terjadi di cloud. Makin banyak aplikasi yang menjalankan model yang sangat dioptimalkan secara langsung di perangkat. Meskipun demo LLM yang berjalan di browser sudah ada, berikut beberapa contoh tingkat produksi dari model lain yang berjalan di browser:
- Adobe Photoshop menjalankan varian model
Conv2Ddi perangkat untuk alat pemilihan objek cerdasnya. - Google Meet menjalankan versi model
MobileNetV3-smallyang dioptimalkan untuk segmentasi orang dalam fitur latar belakang blur-nya. - Tokopedia menjalankan model
MediaPipeFaceDetector-TFJSuntuk deteksi wajah real-time guna mencegah pendaftaran yang tidak valid ke layanannya. - Google Colab memungkinkan pengguna menggunakan model dari hard disk mereka di notebook Colab.
Untuk mempercepat peluncuran aplikasi Anda di masa mendatang, Anda harus secara eksplisit melakukan caching data model di perangkat, bukan mengandalkan cache browser HTTP implisit.
Meskipun panduan ini menggunakan model gemma-2b-it-gpu-int4.bin untuk membuat chatbot, pendekatan ini dapat digeneralisasi agar sesuai dengan model lain dan kasus penggunaan lain di perangkat. Cara paling umum untuk menghubungkan aplikasi ke model adalah dengan menayangkan
model bersama resource aplikasi lainnya. Anda harus mengoptimalkan
penayangan.
Mengonfigurasi header cache yang tepat
Jika Anda menayangkan model AI dari server, Anda harus mengonfigurasi header
Cache-Control
yang benar. Contoh berikut menunjukkan setelan default yang solid, yang dapat Anda bangun
untuk kebutuhan aplikasi Anda.
Cache-Control: public, max-age=31536000, immutable
Setiap versi model AI yang dirilis adalah resource statis. Konten yang tidak pernah berubah harus diberi
max-age
panjang yang dikombinasikan dengan penghentian cache
di URL permintaan. Jika Anda perlu memperbarui model, Anda harus
memberikan URL baru.
Saat pengguna memuat ulang halaman, klien akan mengirim permintaan validasi ulang, meskipun server mengetahui bahwa konten stabil. Direktif
immutable
secara eksplisit menunjukkan bahwa validasi ulang tidak diperlukan, karena
konten tidak akan berubah. Direktif immutable
tidak didukung secara luas
oleh browser dan server proxy atau cache perantara, tetapi dengan
menggabungkannya dengan
direktif max-age yang dipahami secara universal, Anda dapat memastikan kompatibilitas
maksimum. Direktif respons public
menunjukkan bahwa respons dapat disimpan dalam cache bersama.
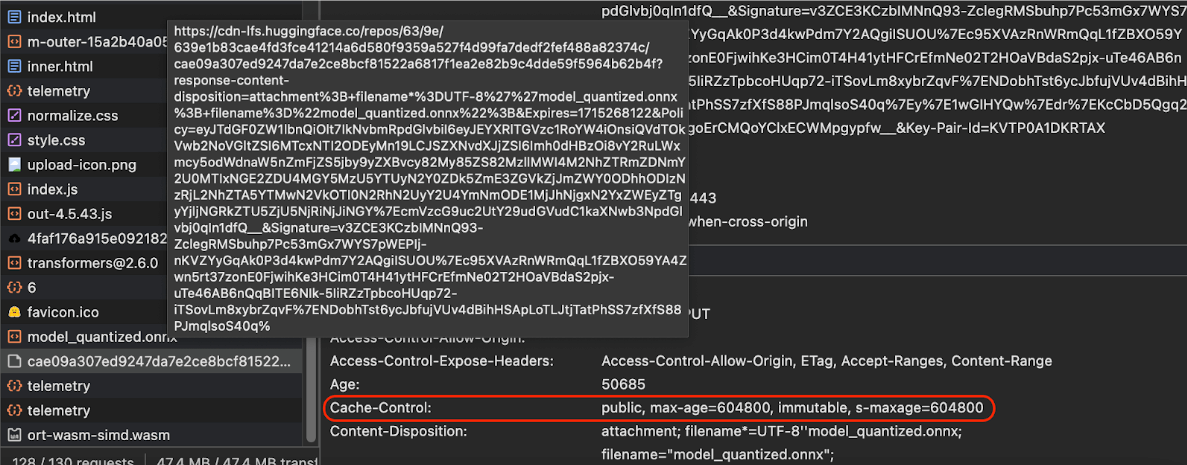
Cache-Control
produksi yang dikirim oleh Hugging Face saat meminta model AI.
(Sumber)
Meng-cache model AI di sisi klien
Saat menayangkan model AI, penting untuk menyimpan model secara eksplisit di cache browser. Hal ini memastikan data model tersedia setelah pengguna memuat ulang aplikasi.
Ada sejumlah teknik yang dapat Anda gunakan untuk mencapai hal ini. Untuk contoh kode berikut, asumsikan setiap file model disimpan dalam objek Blob bernama blob dalam memori.
Untuk memahami performa, setiap contoh kode dianotasi dengan metode
performance.mark()
dan performance.measure(). Pengukuran ini bergantung pada perangkat dan tidak dapat digeneralisasi.

Anda dapat memilih untuk menggunakan salah satu API berikut untuk meng-cache model AI di browser: Cache API, the Origin Private File System API, dan IndexedDB API. Rekomendasi umum adalah menggunakan Cache API, tetapi panduan ini membahas kelebihan dan kekurangan semua opsi.
Cache API
Cache API menyediakan
penyimpanan persisten untuk pasangan objek
Request dan Response yang di-cache dalam memori yang aktif dalam jangka panjang. Meskipun
didefinisikan dalam spesifikasi Service Worker,
Anda dapat menggunakan API ini dari thread utama atau pekerja biasa. Untuk menggunakannya di luar
konteks pekerja layanan, panggil metode
Cache.put()
dengan objek Response sintetis, yang dipasangkan dengan URL sintetis, bukan objek
Request.
Panduan ini mengasumsikan blob dalam memori. Gunakan URL palsu sebagai kunci cache dan Response sintetis berdasarkan blob. Jika ingin mendownload model secara langsung, Anda akan menggunakan Response yang akan Anda dapatkan dari membuat permintaan fetch().
Misalnya, berikut cara menyimpan dan memulihkan file model dengan Cache API.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
Origin Private File System (OPFS) adalah standar yang relatif baru untuk endpoint penyimpanan. File ini bersifat pribadi untuk asal halaman, dan dengan demikian tidak terlihat oleh pengguna, tidak seperti sistem file biasa. Objek ini menyediakan akses ke file khusus yang sangat dioptimalkan untuk performa dan menawarkan akses tulis ke kontennya.
Misalnya, berikut cara menyimpan dan memulihkan file model di OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB adalah standar yang sudah mapan untuk menyimpan data arbitrer secara persisten di browser. IndexedDB terkenal dengan API-nya yang agak rumit, tetapi dengan menggunakan library wrapper seperti idb-keyval Anda dapat memperlakukan IndexedDB seperti penyimpanan key-value klasik.
Contoh:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Menandai penyimpanan sebagai tetap ada
Panggil navigator.storage.persist()
di akhir salah satu metode penyimpanan dalam cache ini untuk meminta izin menggunakan
penyimpanan persisten. Metode ini menampilkan promise yang di-resolve ke true jika izin diberikan, dan false jika tidak. Browser
dapat atau tidak dapat memenuhi permintaan,
bergantung pada aturan khusus browser.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Kasus khusus: Menggunakan model di hard disk
Anda dapat merujuk model AI langsung dari hard disk pengguna sebagai alternatif untuk penyimpanan browser. Teknik ini dapat membantu aplikasi yang berfokus pada riset menunjukkan kelayakan menjalankan model tertentu di browser, atau memungkinkan artis menggunakan model yang dilatih sendiri di aplikasi kreativitas ahli.
File System Access API
Dengan File System Access API, Anda dapat membuka file dari hard disk dan mendapatkan FileSystemFileHandle yang dapat Anda pertahankan ke IndexedDB.
Dengan pola ini, pengguna hanya perlu memberikan akses ke file model
sekali saja. Berkat izin yang dipertahankan,
pengguna dapat memilih untuk memberikan akses permanen ke file. Setelah memuat ulang
aplikasi dan gestur pengguna yang diperlukan, seperti klik mouse, FileSystemFileHandle
dapat dipulihkan dari IndexedDB dengan akses ke file
di hard disk.
Izin akses file dikueri dan diminta jika perlu, sehingga pemuatan ulang pada masa mendatang menjadi lancar. Contoh berikut menunjukkan cara mendapatkan handle untuk file dari hard disk, lalu menyimpan dan memulihkan handle.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Metode ini tidak saling eksklusif. Mungkin ada kasus saat Anda secara eksplisit menyimpan model ke dalam cache di browser dan menggunakan model dari hard disk pengguna.
Demo
Anda dapat melihat ketiga metode penyimpanan reguler dan metode hard disk yang diterapkan di demo LLM MediaPipe.
Bonus: Mendownload file besar dalam potongan-potongan
Jika Anda perlu mendownload model AI berukuran besar dari Internet, lakukan download secara paralel ke dalam beberapa bagian terpisah, lalu gabungkan kembali di klien.
Paket fetch-in-chunks menyediakan
fungsi helper yang dapat Anda gunakan dalam kode. Anda hanya perlu meneruskan
url. maxParallelRequests (default: 6), chunkSize
(default: ukuran file yang akan didownload dibagi dengan maxParallelRequests), fungsi progressCallback (yang melaporkan downloadedBytes dan total fileSize), dan signal untuk
sinyal AbortSignal bersifat opsional.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Pilih metode yang tepat untuk Anda
Panduan ini telah membahas berbagai metode untuk secara efektif melakukan caching model AI di browser, tugas yang sangat penting untuk meningkatkan pengalaman pengguna dan performa aplikasi Anda. Tim penyimpanan Chrome merekomendasikan Cache API untuk performa optimal, guna memastikan akses cepat ke model AI, mengurangi waktu pemuatan, dan meningkatkan responsivitas.
OPFS dan IndexedDB adalah opsi yang kurang dapat digunakan. OPFS dan IndexedDB API perlu melakukan serialisasi data sebelum dapat disimpan. IndexedDB juga perlu mendeserialisasi data saat diambil, sehingga menjadi tempat terburuk untuk menyimpan model besar.
Untuk aplikasi khusus, File System Access API menawarkan akses langsung ke file di perangkat pengguna, ideal untuk pengguna yang mengelola model AI mereka sendiri.
Jika Anda perlu mengamankan model AI, simpan model tersebut di server. Setelah disimpan di klien, data dapat diekstrak dengan mudah dari Cache dan IndexedDB dengan DevTools atau ekstensi DevTools OFPS. API penyimpanan ini pada dasarnya memiliki tingkat keamanan yang sama. Anda mungkin tergoda untuk menyimpan model versi terenkripsi, tetapi Anda harus mendapatkan kunci dekripsi ke klien, yang dapat dicegat. Artinya, upaya pelaku jahat untuk mencuri model Anda akan sedikit lebih sulit, tetapi tidak mustahil.
Sebaiknya pilih strategi caching yang sesuai dengan persyaratan aplikasi, perilaku target audiens, dan karakteristik model AI yang digunakan. Hal ini memastikan aplikasi Anda responsif dan tangguh dalam berbagai kondisi jaringan dan batasan sistem.
Ucapan terima kasih
Fitur ini ditinjau oleh Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan, dan Rachel Andrew.