

לרוב מודלי השפה יש דבר אחד במשותף: הם גדולים למדי ביחס למשאב שמועבר באינטרנט. המודל הכי קטן לזיהוי אובייקטים ב-MediaPipe (SSD MobileNetV2 float16) שוקל 5.6MB, והגדול ביותר שוקל כ-25MB.
מודל השפה הגדול (LLM) בקוד פתוח gemma-2b-it-gpu-int4.bin תופס נפח של 1.35GB – וזה נחשב למודל קטן מאוד.
מודלים של AI גנרטיבי יכולים להיות עצומים. זו הסיבה לכך שהרבה שימושים ב-AI מתבצעים היום בענן. יותר ויותר אפליקציות מריצות מודלים שעברו אופטימיזציה גבוהה ישירות במכשיר. אמנם יש הדגמות של מודלים גדולים של שפה שפועלים בדפדפן, אבל הנה כמה דוגמאות של מודלים אחרים שפועלים בדפדפן ברמת ייצור:
- Adobe Photoshop מריץ במכשיר וריאציה של מודל
Conv2Dעבור כלי הבחירה החכם של אובייקטים. - Google Meet מריץ גרסה אופטימלית של מודל
MobileNetV3-smallלפילוח אנשים, כדי להשתמש בה בתכונת הטשטוש של הרקע. - Tokopedia מפעילה את מודל
MediaPipeFaceDetector-TFJSלאיתור פנים בזמן אמת כדי למנוע הרשמות לא תקפות לשירות שלה. - Google Colab מאפשר למשתמשים להשתמש במודלים מהדיסק הקשיח שלהם ב-notebook של Colab.
כדי להשיק את האפליקציות שלכם מהר יותר בעתיד, כדאי לשמור במטמון באופן מפורש את נתוני המודל במכשיר, במקום להסתמך על המטמון המרומז של דפדפן ה-HTTP.
במדריך הזה נעשה שימוש במודל gemma-2b-it-gpu-int4.bin כדי ליצור צ'אטבוט, אבל אפשר להשתמש בגישה הזו גם במודלים אחרים ובתרחישי שימוש אחרים במכשיר. הדרך הנפוצה ביותר לקשר אפליקציה למודל היא להפעיל את המודל לצד שאר משאבי האפליקציה. חשוב לבצע אופטימיזציה של הצגת המודעות.
הגדרת כותרות המטמון הנכונות
אם אתם מפעילים מודלים של AI מהשרת שלכם, חשוב להגדיר את הכותרת הנכונה של Cache-Control. בדוגמה הבאה מוצגת הגדרת ברירת מחדל טובה, שאפשר להשתמש בה כבסיס לצרכים של האפליקציה שלכם.
Cache-Control: public, max-age=31536000, immutable
כל גרסה שמופצת של מודל AI היא משאב סטטי. לתוכן שלא משתנה אף פעם צריך להגדיר max-age ארוך בשילוב עם cache busting בכתובת ה-URL של הבקשה. אם אתם צריכים לעדכן את המודל, אתם חייבים לתת לו כתובת URL חדשה.
כשהמשתמש טוען מחדש את הדף, הלקוח שולח בקשת אימות מחדש, למרות שהשרת יודע שהתוכן יציב. ההוראה
immutable
מציינת באופן מפורש שאין צורך באימות מחדש, כי התוכן לא ישתנה. ההנחיה immutable לא נתמכת באופן נרחב בדפדפנים ובשרתי proxy או במטמון ביניים, אבל שילוב שלה עם ההנחיה max-age שמוכרת בכל מקום מבטיח תאימות מקסימלית. ההנחיה לתגובה public מציינת שאפשר לאחסן את התגובה במטמון משותף.
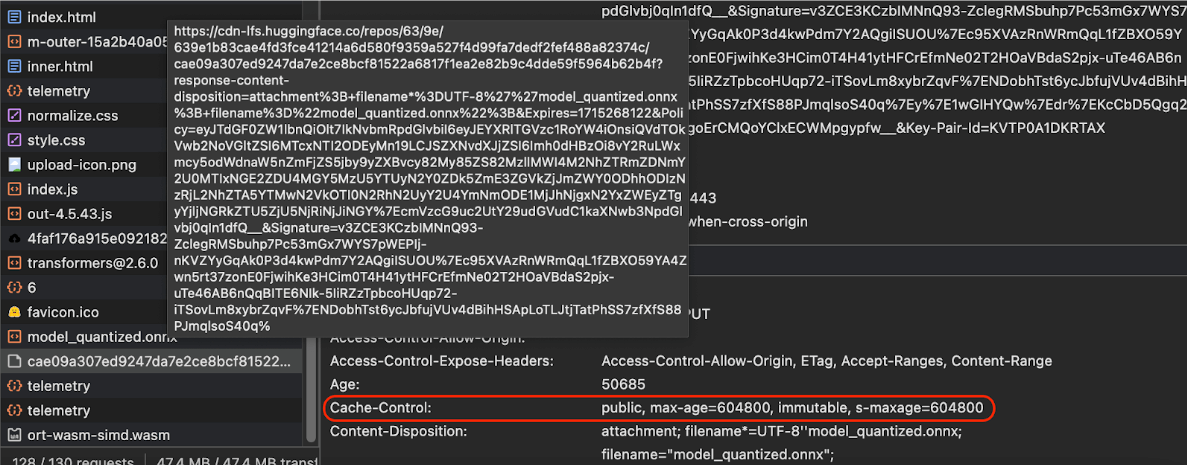
Cache-Control
שנשלחות על ידי Hugging Face כשמבקשים מודל AI.
(מקור)
שמירת מודלים של AI במטמון בצד הלקוח
כשמציגים מודל AI, חשוב לשמור את המודל במטמון של הדפדפן באופן מפורש. כך נתוני המודל יהיו זמינים מיד אחרי שהמשתמש יטען מחדש את האפליקציה.
יש כמה טכניקות שבהן אפשר להשתמש כדי להשיג את המטרה הזו. בדוגמאות הקוד הבאות, נניח שכל קובץ מודל מאוחסן באובייקט Blob בשם blob בזיכרון.
כדי להבין את הביצועים, כל קוד לדוגמה מוסבר באמצעות השיטות performance.mark() ו-performance.measure(). האמצעים האלה תלויים במכשיר ולא ניתנים להכללה.

אתם יכולים לבחור להשתמש באחד מממשקי ה-API הבאים כדי לשמור במטמון מודלים של AI בדפדפן: Cache API, Origin Private File System API ו-IndexedDB API. ההמלצה הכללית היא להשתמש ב-Cache API, אבל במדריך הזה מפורטים היתרונות והחסרונות של כל האפשרויות.
Cache API
Cache API מספק אחסון קבוע של זוגות אובייקטים מסוג Request ו-Response שנשמרים במטמון בזיכרון לטווח ארוך. למרות שה-API הזה מוגדר במפרט של Service Workers, אפשר להשתמש בו מהשרשור הראשי או מ-worker רגיל. כדי להשתמש בו מחוץ להקשר של Service Worker, צריך להפעיל את ה-method Cache.put() עם אובייקט Response סינתטי, בשילוב עם כתובת URL סינתטית במקום אובייקט Request.
במדריך הזה אנחנו יוצאים מנקודת הנחה שאתם משתמשים ב-blob בזיכרון. משתמשים בכתובת URL מזויפת כמפתח המטמון וב-Response סינתטי שמבוסס על blob. אם רוצים להוריד את המודל ישירות, צריך להשתמש ב-Response שמתקבל משליחת בקשת fetch().
לדוגמה, כך מאחסנים ומשחזרים קובץ מודל באמצעות Cache API.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
Origin Private File System (OPFS) הוא תקן חדש יחסית לנקודת קצה של אחסון. הוא פרטי למקור של הדף, ולכן הוא לא גלוי למשתמש, בניגוד למערכת הקבצים הרגילה. הוא מספק גישה לקובץ מיוחד שעבר אופטימיזציה גבוהה לביצועים, ומציע גישת כתיבה לתוכן שלו.
לדוגמה, כך מאחסנים ומשחזרים קובץ מודל ב-OPFS.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB הוא תקן מבוסס לאחסון נתונים שרירותיים באופן קבוע בדפדפן. הוא ידוע לשמצה בגלל ה-API המורכב שלו, אבל באמצעות ספריית wrapper כמו idb-keyval אפשר להתייחס ל-IndexedDB כמו אל חנות קלאסית של זוגות מפתח/ערך.
לדוגמה:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
סימון האחסון כמתמשך
בסוף כל אחת מהשיטות האלה של שמירת נתונים במטמון, צריך להתקשר אל navigator.storage.persist() כדי לבקש הרשאה להשתמש באחסון קבוע. השיטה הזו מחזירה הבטחה שמובילה ל-true אם ניתנת הרשאה, ול-false אחרת. יכול להיות שהדפדפן יכבד את הבקשה ויכול להיות שלא, בהתאם לכללים הספציפיים לדפדפן.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
מקרה מיוחד: שימוש במודל בכונן קשיח
אפשר להפנות למודלים של AI ישירות מהדיסק הקשיח של המשתמש כחלופה לאחסון בדפדפן. הטכניקה הזו יכולה לעזור לאפליקציות שמתמקדות במחקר להציג את האפשרות להפעיל מודלים נתונים בדפדפן, או לאפשר לאומנים להשתמש במודלים שאומנו באופן עצמאי באפליקציות יצירתיות למקצוענים.
File System Access API
באמצעות File System Access API, אפשר לפתוח קבצים מהדיסק הקשיח ולקבל FileSystemFileHandle שאפשר לשמור ב-IndexedDB.
במקרה כזה, המשתמש צריך להעניק גישה לקובץ המודל רק פעם אחת. בזכות הרשאות קבועות, המשתמש יכול לבחור להעניק גישה לקובץ באופן קבוע. אחרי טעינה מחדש של האפליקציה ומחווה נדרשת של המשתמש, כמו לחיצה על העכבר, אפשר לשחזר את FileSystemFileHandle מ-IndexedDB עם גישה לקובץ בדיסק הקשיח.
הרשאות הגישה לקובץ נבדקות ומבוקשות אם צריך, כך שהטעינה מחדש בעתיד תהיה חלקה. בדוגמה הבאה מוצג איך לקבל ידית לקובץ מהדיסק הקשיח, ואז לאחסן ולשחזר את הידית.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
השיטות האלה לא בלעדיות. יכול להיות שתבצעו גם שמירה במטמון של מודל בדפדפן וגם שימוש במודל מדיסק קשיח של משתמש.
הדגמה (דמו)
אפשר לראות את כל שלוש השיטות הרגילות לאחסון של מקרים ואת השיטה של הדיסק הקשיח שמוטמעות בהדגמה של MediaPipe LLM.
בונוס: הורדה של קובץ גדול במקטעים
אם אתם צריכים להוריד מודל AI גדול מהאינטרנט, כדאי להוריד אותו במקביל בחלקים נפרדים, ואז לחבר אותם שוב במחשב הלקוח.
החבילה fetch-in-chunks מספקת פונקציית עזר שאפשר להשתמש בה בקוד. צריך רק להעביר אליו את url. הפרמטרים maxParallelRequests (ברירת מחדל: 6), chunkSize (ברירת מחדל: גודל הקובץ להורדה חלקי maxParallelRequests), הפונקציה progressCallback (שמדווחת על downloadedBytes ועל הסך הכולל fileSize) והפרמטר signal לאות AbortSignal הם אופציונליים.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
בחירת השיטה שמתאימה לכם
במדריך הזה סקרנו שיטות שונות לאחסון במטמון של מודלים של AI בדפדפן. אחסון במטמון הוא חיוני לשיפור חוויית המשתמש והביצועים של האפליקציה. צוות האחסון של Chrome ממליץ להשתמש ב-Cache API כדי להשיג ביצועים אופטימליים, להבטיח גישה מהירה למודלים של AI, לקצר את זמני הטעינה ולשפר את מהירות התגובה.
האפשרויות OPFS ו-IndexedDB פחות שימושיות. לפני שאפשר לאחסן את הנתונים, צריך להשתמש ב-API של OPFS וב-API של IndexedDB כדי לבצע סריאליזציה של הנתונים. בנוסף, צריך לבצע דה-סריאליזציה של הנתונים ב-IndexedDB כשמאחזרים אותם, ולכן זה המקום הכי פחות מתאים לאחסון מודלים גדולים.
במקרה של אפליקציות נישה, File System Access API מאפשר גישה ישירה לקבצים במכשיר של המשתמש, ומתאים במיוחד למשתמשים שמנהלים מודלים של AI משלהם.
אם אתם צריכים לאבטח את מודל ה-AI, אל תעבירו אותו לשרת. אחרי שהנתונים מאוחסנים בצד הלקוח, קל לחלץ אותם מהמטמון ומ-IndexedDB באמצעות כלי הפיתוח או התוסף OFPS DevTools. ממשקי ה-API האלה לאחסון זהים מבחינת אבטחה. יכול להיות שתתפתו לאחסן גרסה מוצפנת של המודל, אבל אז תצטרכו להעביר את מפתח הפענוח ללקוח, ומישהו עלול ליירט אותו. כלומר, יהיה קצת יותר קשה לגורם זדוני לגנוב את המודל שלכם, אבל זה לא בלתי אפשרי.
מומלץ לבחור אסטרטגיית אחסון במטמון שתתאים לדרישות של האפליקציה, להתנהגות של קהל היעד ולמאפיינים של מודלי ה-AI שבהם נעשה שימוש. כך תוכלו לוודא שהאפליקציות שלכם מגיבות במהירות ופועלות בצורה חלקה בתנאי רשת שונים ובמגבלות מערכת שונות.
תודות
המאמר הזה נבדק על ידי Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan ו-Rachel Andrew.