
ดูว่าการเพิ่มประสิทธิภาพ WebAssembly และ WebGPU ช่วยปรับปรุงประสิทธิภาพแมชชีนเลิร์นนิงบนเว็บได้อย่างไร



การใช้ AI อนุมานข้อมูลบนเว็บ
เราทุกคนต่างได้ยินเรื่องราวที่ว่า AI กำลังพลิกโฉมโลกของเรา เว็บก็เช่นกัน
ปีนี้ Chrome ได้เพิ่มฟีเจอร์ Generative AI ซึ่งรวมถึงการสร้างธีมที่กำหนดเองและช่วยคุณเขียนข้อความฉบับร่างแรก แต่ AI มีประโยชน์มากกว่านั้น AI สามารถทำให้เว็บแอปพลิเคชันสมบูรณ์ยิ่งขึ้นได้
หน้าเว็บสามารถฝังคอมโพเนนต์อัจฉริยะสําหรับการมองเห็น เช่น การเลือกใบหน้าหรือการจดจําท่าทางสัมผัส สําหรับการจัดประเภทเสียง หรือสําหรับการตรวจจับภาษา ปีที่ผ่านมา เราได้เห็น Generative AI ได้รับความนิยมมากขึ้น รวมถึงเห็นการสาธิตโมเดลภาษาขนาดใหญ่บนเว็บที่น่าประทับใจมาก อย่าลืมดูAI ในอุปกรณ์ที่ใช้งานได้จริงสำหรับนักพัฒนาเว็บ
การอนุมานด้วยระบบ AI บนเว็บพร้อมใช้งานแล้วในอุปกรณ์จํานวนมากในปัจจุบัน และการประมวลผล AI สามารถเกิดขึ้นในหน้าเว็บได้เองโดยใช้ประโยชน์จากฮาร์ดแวร์ในอุปกรณ์ของผู้ใช้
การดำเนินการนี้มีประสิทธิภาพเนื่องจากเหตุผลหลายประการ ดังนี้
- ลดต้นทุน: การดำเนินการอนุมานในไคลเอ็นต์เบราว์เซอร์จะช่วยลดต้นทุนเซิร์ฟเวอร์ได้อย่างมาก และการดำเนินการนี้มีประโยชน์อย่างยิ่งสำหรับการค้นหา GenAI ซึ่งอาจมีราคาแพงกว่าการค้นหาทั่วไปหลายเท่า
- เวลาในการตอบสนอง: สําหรับแอปพลิเคชันที่ไวต่อเวลาในการตอบสนองเป็นพิเศษ เช่น แอปพลิเคชันเสียงหรือวิดีโอ การประมวลผลทั้งหมดในอุปกรณ์จะช่วยลดเวลาในการตอบสนอง
- ความเป็นส่วนตัว: การทำงานฝั่งไคลเอ็นต์ยังมีศักยภาพในการปลดล็อกแอปพลิเคชันระดับใหม่ที่ต้องใช้ความเป็นส่วนตัวมากขึ้น ซึ่งไม่สามารถส่งข้อมูลไปยังเซิร์ฟเวอร์ได้
ภาระงาน AI ทำงานบนเว็บในปัจจุบันอย่างไร
ปัจจุบันนักพัฒนาแอปพลิเคชันและนักวิจัยสร้างโมเดลโดยใช้เฟรมเวิร์ก โมเดลจะทำงานในเบราว์เซอร์โดยใช้รันไทม์ เช่น Tensorflow.js หรือ ONNX Runtime Web และรันไทม์จะใช้ Web API เพื่อดำเนินการ
รันไทม์ทั้งหมดเหล่านี้จะทำงานบน CPU ผ่าน JavaScript หรือ WebAssembly หรือบน GPU ผ่าน WebGL หรือ WebGPU ในท้ายที่สุด
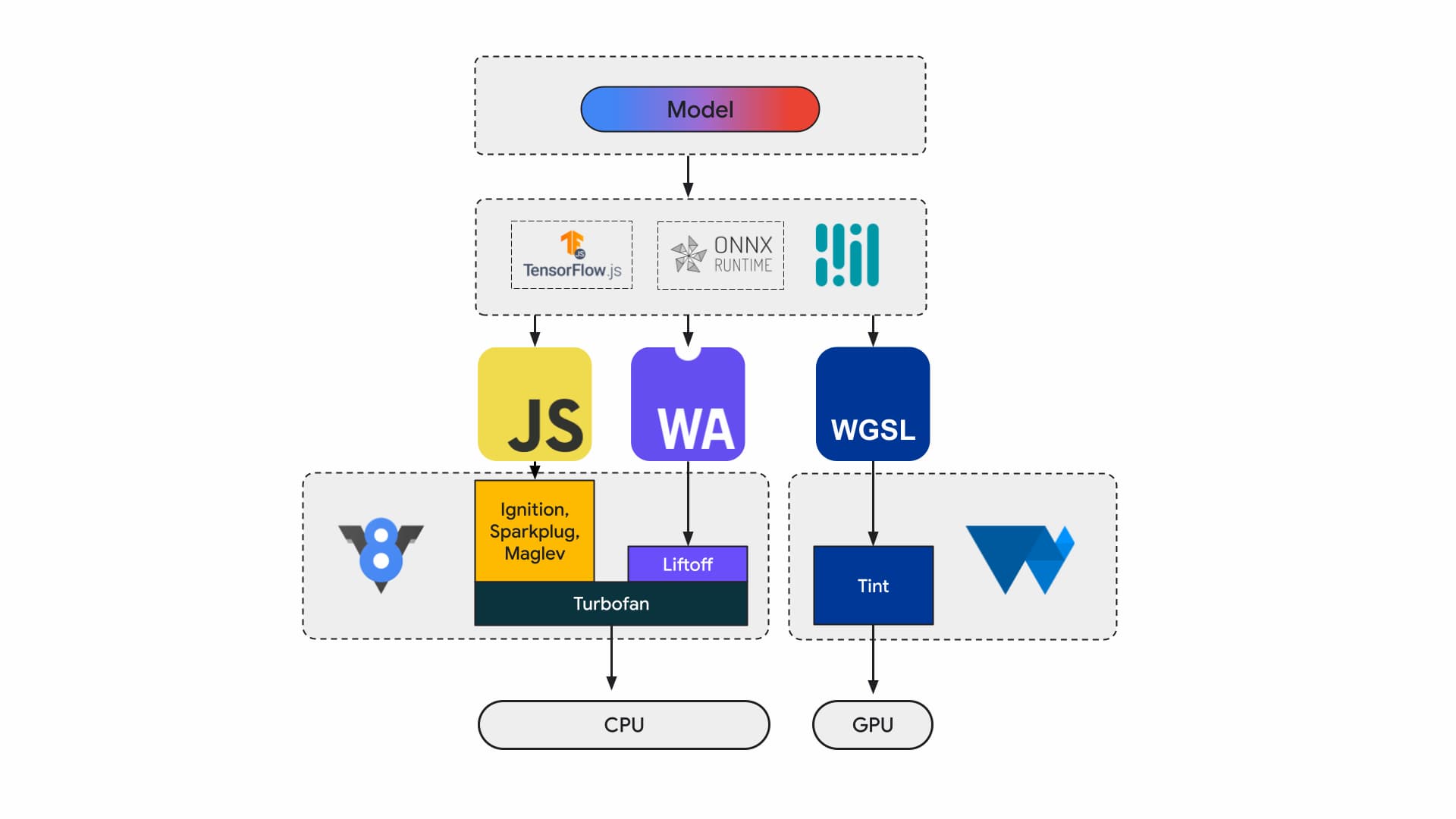
ภาระงานแมชชีนเลิร์นนิง
ภาระงานแมชชีนเลิร์นนิง (ML) จะส่งเทนเซอร์ผ่านกราฟของโหนดการประมวลผล Tensor คืออินพุตและเอาต์พุตของโหนดเหล่านี้ ซึ่งจะดำเนินการคำนวณกับข้อมูลเป็นจำนวนมาก
ซึ่งสำคัญเนื่องจากเหตุผลต่อไปนี้
- เทนเซอร์เป็นโครงสร้างข้อมูลที่ใหญ่มาก ซึ่งจะดำเนินการคํานวณกับโมเดลที่มีน้ำหนักหลายพันล้านรายการ
- การปรับขนาดและการอนุมานอาจทําให้เกิดการขนานกันของข้อมูล ซึ่งหมายความว่าจะดำเนินการเดียวกันกับองค์ประกอบทั้งหมดในเทนเซอร์
- ML ไม่จำเป็นต้องมีความแม่นยำ คุณอาจต้องใช้ตัวเลขทศนิยม 64 บิตเพื่อลงจอดบนดวงจันทร์ แต่อาจต้องใช้ตัวเลข 8 บิตหรือน้อยกว่าสำหรับการจดจำใบหน้า
แต่โชคดีที่นักออกแบบชิปได้เพิ่มฟีเจอร์ต่างๆ เพื่อทำให้โมเดลทำงานได้เร็วขึ้น เย็นขึ้น และทำให้โมเดลทำงานได้
ในระหว่างนี้ ทีม WebAssembly และ WebGPU ของเรากำลังพยายามนำเสนอความสามารถใหม่ๆ เหล่านี้ให้นักพัฒนาเว็บได้ใช้งาน หากคุณเป็นนักพัฒนาเว็บแอปพลิเคชัน ก็ไม่น่าจะใช้องค์ประกอบพื้นฐานระดับต่ำเหล่านี้บ่อยนัก เราคาดว่าเครื่องมือและเฟรมเวิร์กที่คุณใช้อยู่จะรองรับฟีเจอร์และส่วนขยายใหม่ คุณจึงได้รับประโยชน์จากการเปลี่ยนแปลงโครงสร้างพื้นฐานเพียงเล็กน้อย แต่หากต้องการปรับแต่งแอปพลิเคชันเพื่อเพิ่มประสิทธิภาพด้วยตนเอง ฟีเจอร์เหล่านี้ก็เกี่ยวข้องกับงานของคุณ
WebAssembly
WebAssembly (Wasm) คือรูปแบบไบต์โค้ดที่กะทัดรัดและมีประสิทธิภาพซึ่งรันไทม์จะเข้าใจและดำเนินการได้ ออกแบบมาเพื่อใช้ประโยชน์จากความสามารถของฮาร์ดแวร์ที่อยู่เบื้องหลัง เพื่อให้ทำงานได้ใกล้เคียงกับความเร็วของอุปกรณ์ ระบบจะตรวจสอบและเรียกใช้โค้ดในสภาพแวดล้อมแซนด์บ็อกซ์ที่ปลอดภัยต่อหน่วยความจำ
ข้อมูลโมดูล Wasm จะแสดงด้วยการเข้ารหัสไบนารีแบบหนาแน่น ซึ่งหมายความว่าจะถอดรหัสได้เร็วขึ้น โหลดได้เร็วขึ้น และลดการใช้หน่วยความจำเมื่อเทียบกับรูปแบบข้อความ โมดูลนี้เป็นแบบพกพาในแง่ที่ไม่จําเป็นต้องคาดเดาเกี่ยวกับสถาปัตยกรรมพื้นฐานที่ไม่ใช่สถาปัตยกรรมสมัยใหม่
ข้อกำหนด WebAssembly เป็นแบบซ้ำๆ และได้รับการพัฒนาในกลุ่มชุมชน W3C แบบเปิด
รูปแบบไบนารีไม่ได้คาดเดาเกี่ยวกับสภาพแวดล้อมของโฮสต์ จึงออกแบบมาให้ทำงานได้ดีในการฝังที่ไม่ใช่เว็บด้วย
แอปพลิเคชันจะคอมไพล์ได้เพียงครั้งเดียวและทำงานได้ทุกที่ ไม่ว่าจะเป็นเดสก์ท็อป แล็ปท็อป โทรศัพท์ หรืออุปกรณ์อื่นๆ ที่มีเบราว์เซอร์ ดูข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ได้ที่เขียนครั้งเดียว เรียกใช้ได้ทุกที่ ในที่สุดก็กลายเป็นจริงด้วย WebAssembly
แอปพลิเคชันเวอร์ชันที่ใช้งานจริงส่วนใหญ่ที่เรียกใช้การอนุมาน AI ในเว็บจะใช้ WebAssembly ทั้งสําหรับการประมวลผลของ CPU และการติดต่อกับระบบประมวลผลเฉพาะวัตถุประสงค์ ในแอปพลิเคชันเนทีฟ คุณจะเข้าถึงทั้งการประมวลผลทั่วไปและแบบพิเศษได้ เนื่องจากแอปพลิเคชันเข้าถึงความสามารถของอุปกรณ์ได้
บนเว็บ เราประเมินชุดองค์ประกอบพื้นฐานที่จะแสดงอย่างรอบคอบเพื่อความสามารถในการใช้งานร่วมกันและความปลอดภัย วิธีนี้จะช่วยรักษาสมดุลระหว่างการเข้าถึงเว็บกับประสิทธิภาพสูงสุดที่ฮาร์ดแวร์มอบให้
WebAssembly คือการแยกแยะ CPU แบบพกพา ดังนั้นการอนุมาน Wasm ทั้งหมดจึงทำงานบน CPU แม้ว่านี่ไม่ใช่ตัวเลือกที่มีประสิทธิภาพสูงสุด แต่ CPU มีให้บริการอย่างแพร่หลายและทำงานกับเวิร์กโหลดส่วนใหญ่ในอุปกรณ์ส่วนใหญ่ได้
สำหรับปริมาณงานขนาดเล็ก เช่น ปริมาณงานข้อความหรือเสียง การใช้ GPU จะแพง ตัวอย่างล่าสุดที่ Wasm เป็นตัวเลือกที่เหมาะสมมีดังนี้
- Adobe ใช้ Tensorflow.js เพื่อปรับปรุง Photoshop สำหรับเว็บ
- Google Meet เพิ่มการเบลอพื้นหลัง ซึ่งเป็นเอฟเฟกต์วิดีโอแบบ Wasm รายการแรกบนเว็บ
- YouTube มีเอฟเฟกต์ Augmented Reality หลายรายการ
- Google Photos อนุญาตให้แต่งภาพออนไลน์
คุณดูข้อมูลเพิ่มเติมได้ในเดโมโอเพนซอร์ส เช่น whisper-tiny, llama.cpp และ Gemma2B ที่ทำงานในเบราว์เซอร์
ใช้แนวทางแบบองค์รวมกับแอปพลิเคชัน
คุณควรเลือกพรอมิเตอตามโมเดล ML, โครงสร้างพื้นฐานของแอปพลิเคชัน และประสบการณ์การใช้งานแอปพลิเคชันโดยรวมที่ต้องการมอบให้แก่ผู้ใช้
เช่น ในการตรวจหาจุดสังเกตบนใบหน้าของ MediaPipe การอนุมานของ CPU และการอนุมานของ GPU นั้นเปรียบเทียบกันได้ (ทำงานบนอุปกรณ์ Apple M1) แต่ก็มีบางรุ่นที่ความแปรปรวนอาจสูงกว่ามาก
สำหรับเวิร์กโหลด ML เราจะพิจารณามุมมองแอปพลิเคชันแบบองค์รวมไปพร้อมกับฟังความคิดเห็นจากผู้เขียนเฟรมเวิร์กและพาร์ทเนอร์แอปพลิเคชัน เพื่อพัฒนาและส่งการปรับปรุงที่ผู้ใช้ต้องการมากที่สุด โดยแบ่งออกเป็น 3 หมวดหมู่หลักๆ ดังนี้
- แสดงส่วนขยาย CPU ที่สําคัญต่อประสิทธิภาพ
- เปิดใช้การเรียกใช้โมเดลขนาดใหญ่ขึ้น
- เปิดใช้การทำงานร่วมกันอย่างราบรื่นกับ Web API อื่นๆ
การประมวลผลที่เร็วขึ้น
ปัจจุบันข้อกำหนด WebAssembly มีเฉพาะชุดคำสั่งบางอย่างที่เราแสดงต่อเว็บเท่านั้น แต่ฮาร์ดแวร์ยังคงเพิ่มคำสั่งใหม่ๆ อย่างต่อเนื่อง ซึ่งทำให้ช่องว่างระหว่างประสิทธิภาพของเนทีฟกับ WebAssembly เพิ่มขึ้น
โปรดทราบว่าโมเดล ML ไม่จำเป็นต้องมีความแม่นยำในระดับสูงเสมอไป SIMD แบบผ่อนปรนเป็นข้อเสนอที่ลดข้อกำหนดที่ไม่แน่นอนที่เข้มงวดบางอย่าง ซึ่งทำให้การคอมไพล์โค้ดสำหรับการดำเนินการกับเวกเตอร์บางรายการซึ่งเป็นจุดที่มีการใช้งานสูงมีประสิทธิภาพมากขึ้น นอกจากนี้ SIMD แบบผ่อนปรนยังเปิดตัวคำสั่ง Dot Product และ FMA ใหม่ซึ่งจะเร่งความเร็วของเวิร์กโหลดที่มีอยู่ 1.5-3 เท่า ฟีเจอร์นี้พร้อมให้ใช้งานใน Chrome 114
รูปแบบทศนิยมแบบครึ่งความแม่นยำใช้ 16 บิตสำหรับ IEEE FP16 แทน 32 บิตที่ใช้สำหรับค่าความแม่นยำเดี่ยว การใช้ค่าความละเอียดครึ่งหนึ่งมีข้อดีหลายประการเมื่อเทียบกับค่าความละเอียดเดี่ยว เช่น ความต้องการหน่วยความจําลดลง ซึ่งช่วยให้สามารถฝึกและใช้งานเครือข่ายประสาทได้มากขึ้น รวมถึงลดแบนด์วิดท์หน่วยความจํา การลดความแม่นยำจะเพิ่มความเร็วในการโอนข้อมูลและการดำเนินการทางคณิตศาสตร์
รุ่นขนาดใหญ่
ตัวชี้ไปยังหน่วยความจําแบบเส้นตรงของ Wasm จะแสดงเป็นจํานวนเต็ม 32 บิต ซึ่งส่งผล 2 อย่าง ได้แก่ ขนาดฮีปถูกจำกัดไว้ที่ 4 GB (เมื่อคอมพิวเตอร์มี RAM จริงมากกว่านั้น) และโค้ดแอปพลิเคชันที่กําหนดเป้าหมายเป็น Wasm ต้องเข้ากันได้กับขนาดพอยเตอร์ 32 บิต (ซึ่ง
โดยเฉพาะอย่างยิ่งกับโมเดลขนาดใหญ่อย่างที่เรามีอยู่ในปัจจุบัน การโหลดโมเดลเหล่านี้ลงใน WebAssembly อาจมีข้อจํากัด ข้อเสนอ Memory64 จะนําข้อจํากัดเหล่านี้ออกโดยให้หน่วยความจําเชิงเส้นมีขนาดใหญ่กว่า 4 GB และจับคู่กับพื้นที่ที่อยู่ของแพลตฟอร์มเนทีฟ
เรามีการติดตั้งใช้งานที่ใช้งานได้อย่างเต็มรูปแบบใน Chrome และคาดว่าจะพร้อมให้บริการภายในปีนี้ ในระหว่างนี้ คุณสามารถทำการทดสอบโดยใช้ Flag chrome://flags/#enable-experimental-webassembly-features และส่งความคิดเห็นถึงเราได้
การทำงานร่วมกันของเว็บที่ดีขึ้น
WebAssembly อาจเป็นจุดแรกเข้าสําหรับการประมวลผลเฉพาะทางบนเว็บ
WebAssembly สามารถใช้เพื่อนําแอปพลิเคชัน GPU มาใช้ในเว็บได้ ซึ่งหมายความว่าแอปพลิเคชัน C++ เดียวกันที่ทำงานในอุปกรณ์จะทำงานบนเว็บได้ด้วยด้วยการแก้ไขเล็กน้อย
Emscripten ซึ่งเป็นเครื่องมือทางภาษาสำหรับคอมไพเลอร์ Wasm มีไบน์ดิ้งสำหรับ WebGPU อยู่แล้ว Wasm เป็นจุดแรกเข้าสำหรับการอนุมาน AI บนเว็บ จึงเป็นเรื่องสำคัญอย่างยิ่งที่ Wasm จะทำงานร่วมกันกับแพลตฟอร์มเว็บอื่นๆ ได้อย่างราบรื่น เรากำลังดำเนินการกับข้อเสนอ 2-3 ข้อในเรื่องนี้
การผสานรวมสัญญา JavaScript (JSPI)
แอปพลิเคชัน C และ C++ ทั่วไป (รวมถึงภาษาอื่นๆ อีกมากมาย) มักจะเขียนขึ้นเพื่อใช้กับ API แบบซิงค์ ซึ่งหมายความว่าแอปพลิเคชันจะหยุดการดําเนินการจนกว่าการดำเนินการจะเสร็จสมบูรณ์ โดยปกติแล้ว แอปพลิเคชันการบล็อกดังกล่าวจะเขียนได้ง่ายกว่าแอปพลิเคชันที่รองรับการทำงานแบบแอซิงค์
เมื่อการดำเนินการที่มีค่าใช้จ่ายสูงบล็อกเทรดหลัก การดำเนินการดังกล่าวอาจบล็อก I/O และผู้ใช้จะเห็นความกระตุก รูปแบบการเขียนโปรแกรมแบบซิงค์ของแอปพลิเคชันเนทีฟไม่ตรงกับรูปแบบแบบแอซิงโครนัสของเว็บ ซึ่งจะสร้างปัญหาอย่างยิ่งสําหรับแอปพลิเคชันเดิมที่การพอร์ตจะทําได้ยากและค่าใช้จ่ายสูง Emscripten มีวิธีดำเนินการนี้ด้วย Asyncify แต่วิธีนี้อาจไม่ใช่ตัวเลือกที่ดีที่สุดเสมอไป เนื่องจากโค้ดมีขนาดใหญ่ขึ้นและไม่มีประสิทธิภาพเท่า
ตัวอย่างต่อไปนี้เป็นการคำนวณ Fibonacci โดยใช้สัญญา JavaScript สำหรับการบวก
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
ในตัวอย่างนี้ ให้สังเกตสิ่งต่อไปนี้
- มาโคร
EM_ASYNC_JSจะสร้างโค้ดกาวที่จำเป็นทั้งหมดเพื่อให้เราใช้ JSPI เพื่อเข้าถึงผลลัพธ์ของ Promise ได้ เช่นเดียวกับฟังก์ชันปกติ - ตัวเลือกบรรทัดคำสั่งพิเศษ
-s ASYNCIFY=2ซึ่งจะเรียกใช้ตัวเลือกในการสร้างโค้ดที่ใช้ JSPI เพื่อเชื่อมต่อกับ JavaScript import ที่แสดงผลพรอมิส
ดูข้อมูลเพิ่มเติมเกี่ยวกับ JSPI, วิธีใช้ และประโยชน์ของ JSPI ได้ที่การเปิดตัว WebAssembly JavaScript Promise Integration API ใน v8.dev ดูข้อมูลเกี่ยวกับการทดลองใช้แหล่งที่มาในปัจจุบัน
การควบคุมหน่วยความจำ
นักพัฒนาแอปมีการควบคุมหน่วยความจำ Wasm เพียงเล็กน้อยเท่านั้น เนื่องจากโมดูลมีหน่วยความจำของตัวเอง API ใดก็ตามที่ต้องการเข้าถึงหน่วยความจํานี้ต้องคัดลอกเข้าหรือคัดลอกออก และการใช้งานนี้อาจเพิ่มมากขึ้นเรื่อยๆ เช่น แอปพลิเคชันกราฟิกอาจต้องคัดลอกเข้าและคัดลอกออกสำหรับแต่ละเฟรม
ข้อเสนอการควบคุมหน่วยความจำมีจุดประสงค์เพื่อมอบการควบคุมหน่วยความจำเชิงเส้นของ Wasm ที่ละเอียดยิ่งขึ้นและลดจำนวนสำเนาในไปป์ไลน์ของแอปพลิเคชัน ข้อเสนอนี้อยู่ในระยะที่ 1 เรากำลังสร้างต้นแบบใน V8 ซึ่งเป็นเครื่องมือ JavaScript ของ Chrome เพื่อใช้เป็นข้อมูลในการพัฒนามาตรฐาน
เลือกแบ็กเอนด์ที่เหมาะกับคุณ
แม้ว่า CPU จะใช้ได้กับทุกที่ แต่ก็ไม่ได้เป็นตัวเลือกที่ดีที่สุดเสมอไป การประมวลผลสำหรับวัตถุประสงค์พิเศษใน GPU หรือตัวเร่งให้ประสิทธิภาพที่สูงขึ้นหลายเท่า โดยเฉพาะสำหรับรุ่นที่ใหญ่ขึ้นและอุปกรณ์ระดับไฮเอนด์ ซึ่งมีผลกับทั้งแอปพลิเคชันเนทีฟและแอปพลิเคชันเว็บ
แบ็กเอนด์ที่คุณเลือกจะขึ้นอยู่กับแอปพลิเคชัน เฟรมเวิร์ก หรือชุดเครื่องมือ รวมถึงปัจจัยอื่นๆ ที่ส่งผลต่อประสิทธิภาพ อย่างไรก็ตาม เราจะยังคงลงทุนในข้อเสนอต่างๆ ที่ช่วยให้ Wasm หลักทำงานร่วมกับแพลตฟอร์มเว็บอื่นๆ ได้ดี และโดยเฉพาะกับ WebGPU