
Découvrez comment les améliorations apportées à WebAssembly et WebGPU améliorent les performances du machine learning sur le Web.



Inférence de l'IA sur le Web
Nous avons tous entendu dire que l'IA transforme notre monde. Le Web ne fait pas exception.
Cette année, Chrome a ajouté des fonctionnalités d'IA générative, y compris la création de thèmes personnalisés et l'aide à rédiger un premier jet de texte. Mais l'IA va bien plus loin : elle peut enrichir les applications Web elles-mêmes.
Les pages Web peuvent intégrer des composants intelligents pour la vision, comme la sélection de visages ou la reconnaissance de gestes, pour la classification audio ou pour la détection de la langue. Au cours de la dernière année, l'IA générative a connu un essor, avec des démonstrations vraiment impressionnantes de grands modèles de langage sur le Web. N'hésitez pas à consulter IA sur l'appareil pour les développeurs Web.
L'inférence IA sur le Web est aujourd'hui disponible sur une grande partie des appareils. Le traitement IA peut se produire sur la page Web elle-même, en exploitant le matériel de l'appareil de l'utilisateur.
Cette fonctionnalité est puissante pour plusieurs raisons:
- Réduction des coûts: l'exécution de l'inférence sur le client du navigateur réduit considérablement les coûts du serveur. Cela peut être particulièrement utile pour les requêtes GenAI, qui peuvent être des ordres de grandeur plus coûteuses que les requêtes standards.
- Latence: pour les applications particulièrement sensibles à la latence, comme les applications audio ou vidéo, effectuer tout le traitement sur l'appareil permet de réduire la latence.
- Confidentialité: l'exécution côté client peut également ouvrir une nouvelle classe d'applications nécessitant une confidentialité accrue, où les données ne peuvent pas être envoyées au serveur.
Comment les charges de travail d'IA sont-elles exécutées sur le Web aujourd'hui ?
Aujourd'hui, les développeurs d'applications et les chercheurs créent des modèles à l'aide de frameworks. Les modèles s'exécutent dans le navigateur à l'aide d'un environnement d'exécution tel que Tensorflow.js ou ONNX Runtime Web, et les environnements d'exécution utilisent des API Web pour l'exécution.
Tous ces environnements d'exécution finissent par s'exécuter sur le processeur via JavaScript ou WebAssembly, ou sur le GPU via WebGL ou WebGPU.
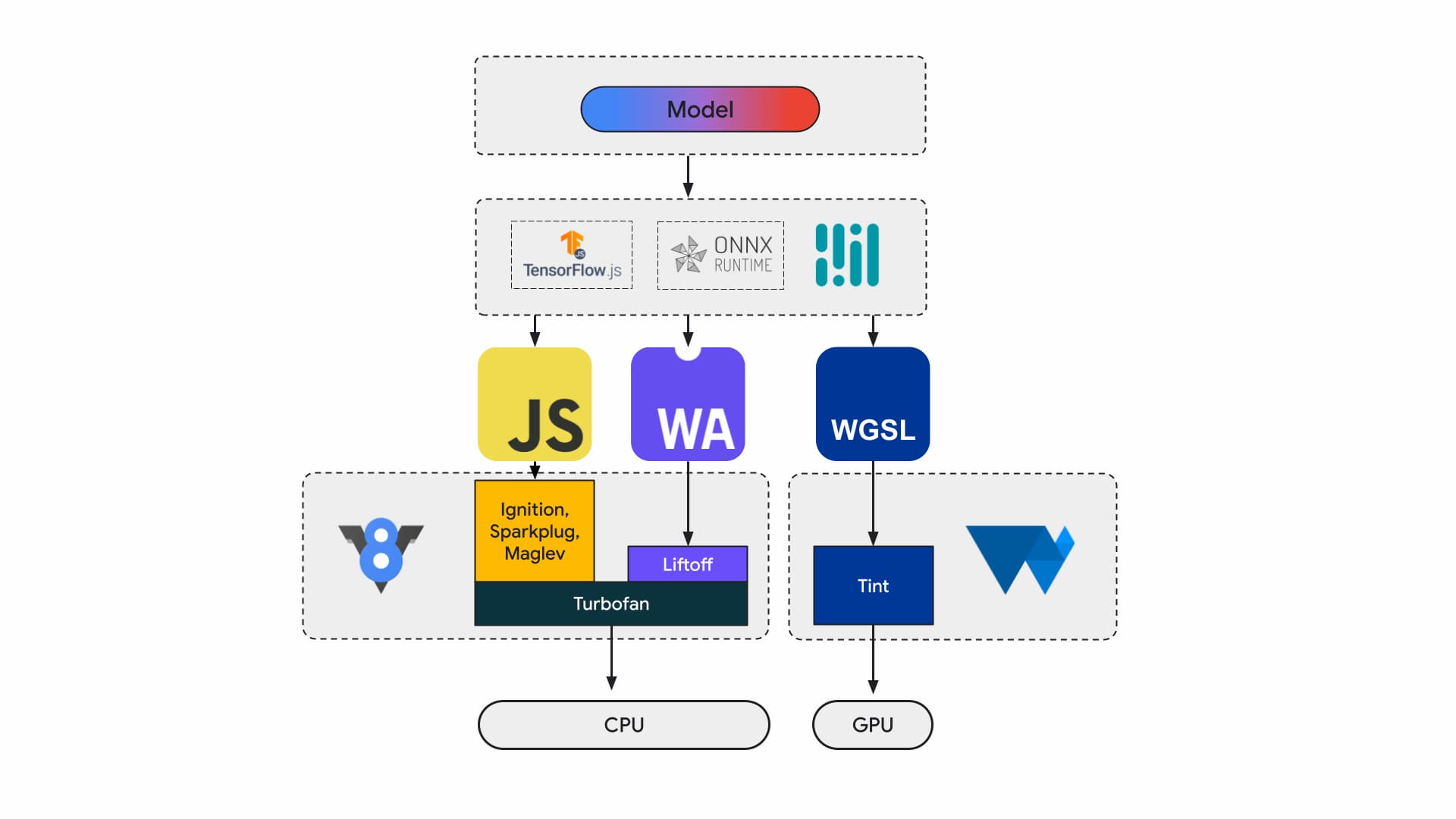
Charges de travail de machine learning
Les charges de travail de machine learning (ML) transfèrent des tenseurs via un graphique de nœuds de calcul. Les tensors sont les entrées et les sorties de ces nœuds, qui effectuent de nombreux calculs sur les données.
C'est important, car:
- Les tenseurs sont de très grandes structures de données qui effectuent des calculs sur des modèles pouvant comporter des milliards de poids.
- L'ajustement et l'inférence peuvent entraîner un parallélisme de données. Cela signifie que les mêmes opérations sont effectuées sur tous les éléments des tenseurs.
- Le ML ne nécessite pas de précision. Vous aurez peut-être besoin d'un nombre à virgule flottante de 64 bits pour atterrir sur la Lune, mais vous n'aurez peut-être besoin que d'une mer de nombres de 8 bits ou moins pour la reconnaissance faciale.
Heureusement, les concepteurs de puces ont ajouté des fonctionnalités pour accélérer l'exécution des modèles, les refroidir et même les exécuter.
En attendant, les équipes WebAssembly et WebGPU s'efforcent de rendre ces nouvelles fonctionnalités accessibles aux développeurs Web. Si vous êtes développeur d'applications Web, vous n'utiliserez probablement pas fréquemment ces primitives de bas niveau. Nous nous attendons à ce que les chaînes d'outils ou les frameworks que vous utilisez soient compatibles avec les nouvelles fonctionnalités et extensions. Vous pourrez ainsi bénéficier de ces nouveautés avec un minimum de modifications apportées à votre infrastructure. Toutefois, si vous préférez optimiser manuellement les performances de vos applications, ces fonctionnalités sont adaptées à votre travail.
WebAssembly
WebAssembly (Wasm) est un format de code octet compact et efficace que les environnements d'exécution peuvent comprendre et exécuter. Il est conçu pour exploiter les fonctionnalités matérielles sous-jacentes afin de pouvoir s'exécuter à des vitesses quasi natives. Le code est validé et exécuté dans un environnement de bac à sable sécurisé.
Les informations du module Wasm sont représentées à l'aide d'un encodage binaire dense. Par rapport à un format basé sur du texte, cela signifie un décodage et un chargement plus rapides, ainsi qu'une utilisation réduite de la mémoire. Il est portable dans le sens où il ne fait pas d'hypothèses sur l'architecture sous-jacente qui ne sont pas déjà communes aux architectures modernes.
La spécification WebAssembly est itérative et est élaborée dans un groupe de la communauté du W3C ouvert.
Le format binaire ne fait aucune hypothèse sur l'environnement hôte. Il est donc conçu pour fonctionner également dans les représentations vectorielles continues non Web.
Votre application peut être compilée une seule fois et exécutée partout: sur un ordinateur de bureau, un ordinateur portable, un téléphone ou tout autre appareil équipé d'un navigateur. Pour en savoir plus, consultez Écrire une fois, exécuter partout, enfin réalisé avec WebAssembly.
La plupart des applications de production qui exécutent l'inférence IA sur le Web utilisent WebAssembly, à la fois pour le calcul du processeur et pour l'interface avec le calcul à usage spécial. Dans les applications natives, vous pouvez accéder à la fois au calcul à usage général et à celui à usage spécial, car l'application peut accéder aux fonctionnalités de l'appareil.
Sur le Web, pour des raisons de portabilité et de sécurité, nous évaluons attentivement l'ensemble de primitives exposé. Cela permet d'équilibrer l'accessibilité du Web avec les performances maximales fournies par le matériel.
WebAssembly est une abstraction portable des processeurs. Par conséquent, toutes les inférences Wasm sont exécutées sur le processeur. Bien qu'il ne s'agisse pas du choix le plus performant, les processeurs sont largement disponibles et fonctionnent sur la plupart des charges de travail, sur la plupart des appareils.
Pour les charges de travail plus petites, telles que les charges de travail textuelles ou audio, le GPU serait coûteux. Voici quelques exemples récents où Wasm est le bon choix:
- Adobe utilise TensorFlow.js pour améliorer Photoshop pour le Web.
- Google Meet a ajouté le floutage d'arrière-plan, l'un des premiers effets vidéo basés sur Wasm sur le Web.
- YouTube propose plusieurs effets de réalité augmentée.
- Google Photos permet de retoucher des photos en ligne.
Vous pouvez en découvrir encore plus dans les démonstrations Open Source, comme whisper-tiny, llama.cpp et Gemma2B exécuté dans le navigateur.
Adopter une approche globale pour vos applications
Vous devez choisir des primitives en fonction du modèle de ML, de l'infrastructure de l'application et de l'expérience globale prévue pour les utilisateurs.
Par exemple, dans la détection des points de repère du visage de MediaPipe, l'inférence du processeur et l'inférence du GPU sont comparables (exécutées sur un appareil Apple M1), mais il existe des modèles pour lesquels la variance peut être beaucoup plus élevée.
En ce qui concerne les charges de travail ML, nous adoptons une vue globale de l'application, tout en écoutant les auteurs de frameworks et les partenaires d'applications pour développer et déployer les améliorations les plus demandées. Ils se divisent globalement en trois catégories:
- Exposer les extensions de processeur essentielles aux performances
- Exécuter des modèles plus volumineux
- Permettre une interopérabilité fluide avec d'autres API Web
Calcul plus rapide
Pour le moment, la spécification WebAssembly n'inclut qu'un certain ensemble d'instructions que nous exposons sur le Web. Toutefois, le matériel continue d'ajouter de nouvelles instructions qui creusent l'écart entre les performances natives et celles de WebAssembly.
N'oubliez pas que les modèles de ML n'exigent pas toujours des niveaux de précision élevés. Relaxed SIMD est une proposition qui réduit certaines des exigences strictes de non-déterminisme, ce qui accélère la génération de code pour certaines opérations vectorielles qui sont des points chauds pour les performances. De plus, Relaxed SIMD introduit de nouvelles instructions de produit scalaire et FMA qui accélèrent les charges de travail existantes de 1,5 à 3 fois. Cette fonctionnalité a été publiée dans Chrome 114.
Le format à virgule flottante demi-précision utilise 16 bits pour IEEE FP16 au lieu des 32 bits utilisés pour les valeurs à simple précision. Par rapport aux valeurs à précision simple, l'utilisation de valeurs à demi-précision présente plusieurs avantages : réduction des exigences en mémoire, ce qui permet d'entraîner et de déployer des réseaux de neurones plus volumineux, et réduction de la bande passante mémoire. Une précision réduite accélère le transfert de données et les opérations mathématiques.
Modèles plus volumineux
Les pointeurs vers la mémoire linéaire Wasm sont représentés sous forme d'entiers de 32 bits. Cela a deux conséquences: la taille des tas est limitée à 4 Go (alors que les ordinateurs disposent de beaucoup plus de RAM physique), et le code d'application qui cible Wasm doit être compatible avec une taille de pointeur 32 bits (qui).
En particulier avec les grands modèles que nous avons aujourd'hui, le chargement de ces modèles dans WebAssembly peut être restrictif. La proposition Memory64 supprime ces restrictions en permettant à la mémoire linéaire d'être supérieure à 4 Go et de correspondre à l'espace d'adressage des plates-formes natives.
Nous avons une implémentation complète et fonctionnelle dans Chrome, qui devrait être déployée dans le courant de l'année. Pour le moment, vous pouvez effectuer des tests avec l'indicateur chrome://flags/#enable-experimental-webassembly-features et nous envoyer vos commentaires.
Meilleure interopérabilité Web
WebAssembly pourrait être le point d'entrée du calcul à usage spécial sur le Web.
WebAssembly peut être utilisé pour apporter des applications GPU sur le Web. Cela signifie que la même application C++ qui peut s'exécuter sur l'appareil peut également s'exécuter sur le Web, avec de légères modifications.
Emscripten, la chaîne d'outils de compilation Wasm, dispose déjà de liaisons pour WebGPU. Il s'agit du point d'entrée de l'inférence IA sur le Web. Il est donc essentiel que Wasm puisse interagir de manière transparente avec le reste de la plate-forme Web. Nous travaillons sur plusieurs propositions dans ce domaine.
Intégration de promesses JavaScript (JSPI)
Les applications C et C++ (ainsi que de nombreux autres langages) sont généralement écrites avec une API synchrone. Cela signifie que l'application arrête l'exécution jusqu'à la fin de l'opération. Ces applications bloquantes sont généralement plus intuitives à écrire que les applications compatibles avec l'async.
Lorsque des opérations coûteuses bloquent le thread principal, elles peuvent bloquer les E/S, et les à-coups sont visibles par les utilisateurs. Il existe un décalage entre le modèle de programmation synchrone des applications natives et le modèle asynchrone du Web. Cela est particulièrement problématique pour les anciennes applications, dont le portage serait coûteux. Emscripten permet de le faire avec Asyncify, mais ce n'est pas toujours la meilleure option, car la taille du code est plus importante et moins efficace.
L'exemple suivant calcule la série de Fibonacci à l'aide de promesses JavaScript pour l'addition.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
Dans cet exemple, tenez compte des points suivants:
- La macro
EM_ASYNC_JSgénère tout le code de liaison nécessaire pour que nous puissions utiliser JSPI pour accéder au résultat de la promesse, comme pour une fonction normale. - L'option de ligne de commande spéciale,
-s ASYNCIFY=2. Cette option permet de générer du code qui utilise JSPI pour interagir avec les importations JavaScript qui renvoient des promesses.
Pour en savoir plus sur la JSPI, comment l'utiliser et ses avantages, consultez Présentation de l'API WebAssembly JavaScript Promise Integration sur v8.dev. Découvrez le test en cours sur l'origine.
Contrôle de la mémoire
Les développeurs ont très peu de contrôle sur la mémoire Wasm. Le module possède sa propre mémoire. Toutes les API qui doivent accéder à cette mémoire doivent effectuer des opérations de copie, et cette utilisation peut vraiment s'accumuler. Par exemple, une application graphique peut avoir besoin de copier et de coller pour chaque frame.
La proposition de contrôle de la mémoire vise à fournir un contrôle plus précis de la mémoire linéaire Wasm et à réduire le nombre de copies dans le pipeline de l'application. Cette proposition en est à sa phase 1. Nous la prototypons dans V8, le moteur JavaScript de Chrome, afin d'en informer l'évolution de la norme.
Choisir le backend qui vous convient
Bien que le processeur soit omniprésent, il n'est pas toujours la meilleure option. Le calcul à usage spécial sur le GPU ou les accélérateurs peut offrir des performances d'ordres de grandeur supérieurs, en particulier pour les modèles plus volumineux et sur les appareils haut de gamme. Cela s'applique aux applications natives et aux applications Web.
Le backend que vous choisissez dépend de l'application, du framework ou de la chaîne d'outils, ainsi que d'autres facteurs qui influencent les performances. Cela dit, nous continuons d'investir dans des propositions qui permettent au Wasm principal de fonctionner correctement avec le reste de la plate-forme Web, et plus particulièrement avec WebGPU.