
Obecnie witryny lub aplikacje internetowe używają jednego z dwóch schematów nawigacji:
- Schemat nawigacji jest dostarczany domyślnie przez przeglądarki – oznacza to, że wpisujesz adres URL na pasku adresu przeglądarki, a żądanie nawigacji zwraca w odpowiedzi dokument. Następnie klikasz link, który powoduje usunięcie wczytanego bieżącego dokumentu z innego – ad infinitum.
- Wzorzec aplikacji jednostronicowej, który obejmuje początkowe żądanie nawigacji w celu wczytania powłoki aplikacji i za pomocą JavaScriptu wypełnia powłokę aplikacji znacznikami renderowanymi przez klienta treścią z interfejsu API backendu dla każdej „nawigacji”.
Korzyści obu z nich wskazują zwolennicy tych rozwiązań:
- Schemat nawigacji udostępniany domyślnie w przeglądarkach jest odporny, ponieważ trasy nie wymagają dostępu do JavaScriptu. Renderowanie znaczników za pomocą JavaScriptu przez klienta również może być procesem potencjalnie kosztownym, co oznacza, że na urządzeniach niższej klasy w sytuacji, w której treści będą opóźnione, ponieważ urządzenie będzie zablokowane w skryptach przetwarzania tych treści.
- Z drugiej strony aplikacje na jednej stronie (SPA) mogą zapewniać szybszą nawigację po początkowym wczytaniu. Zamiast czekać, aż przeglądarka wyładuje całkowicie nowy dokument (i powtarzać to przy każdej nawigacji), można zaoferować coś szybszego i bardziej podobnego do aplikacji. – nawet jeśli do działania wymaga JavaScriptu.
W tym poście porozmawiamy o trzeciej metodzie, która łączy 2 z powyższych sposobów: poleganie na mechanizmie skryptu service worker w celu wstępnego buforowania typowych elementów witryny, takich jak znaczniki nagłówka i stopki, oraz wykorzystywanie strumieni do jak najszybszego wysyłania odpowiedzi HTML do klienta, nadal przy jednoczesnym korzystaniu z domyślnego schematu nawigacji przeglądarki.
Po co przesyłać strumieniowo odpowiedzi HTML w skrypcie service worker?
Strumieniowe przesyłanie danych działa już w przypadku wysyłania żądań przez przeglądarkę. Jest to niezwykle istotne w kontekście żądań nawigacji, ponieważ dzięki niemu przeglądarka nie będzie blokowana i czeka na całą odpowiedź, zanim zacznie analizować znaczniki dokumentu i renderować stronę.

W przypadku mechanizmów Service Worker streaming działa trochę inaczej, bo wykorzystuje interfejs JavaScript Streams API. Najważniejszym zadaniem wykonywanym przez mechanizm Service Worker jest przechwytywanie żądań (w tym żądań nawigacji) i reagowanie na nie.
Żądania te mogą wchodzić w interakcje z pamięcią podręczną na wiele sposobów. Częstym wzorcem buforowania w przypadku znaczników jest preferowanie odpowiedzi z sieci na pierwszym miejscu, a zarazem korzystanie z pamięci podręcznej, jeśli jest dostępna starsza kopia, i opcjonalnie zapewnianie ogólnej odpowiedzi zastępczej, jeśli użytej odpowiedzi nie ma w pamięci podręcznej.
To sprawdzone rozwiązanie do stosowania znaczników, które działa dobrze, ale pomaga w zwiększaniu niezawodności w kontekście dostępu w trybie offline, ale nie przynosi żadnych nieodłącznych korzyści związanych z wydajnością w przypadku żądań nawigacji, które zależą od strategii w pierwszej kolejności lub tylko sieci. Dlatego właśnie warto używać strumieniowego przesyłania danych. Dowiesz się, jak używać opartego na interfejsie API Streams modułu workbox-streams w skrypcie service workbox, aby przyspieszyć żądania nawigacji w witrynie wielostronicowej.
Zestawienie typowej strony internetowej
Z struktury strukturalnej strony internetowe zazwyczaj zawierają wspólne elementy, które występują na każdej stronie. Typowy układ elementów strony wygląda często tak:
- Nagłówek.
- Treść.
- Stopka.
Na przykładzie web.dev zestawienie typowych elementów wygląda tak:
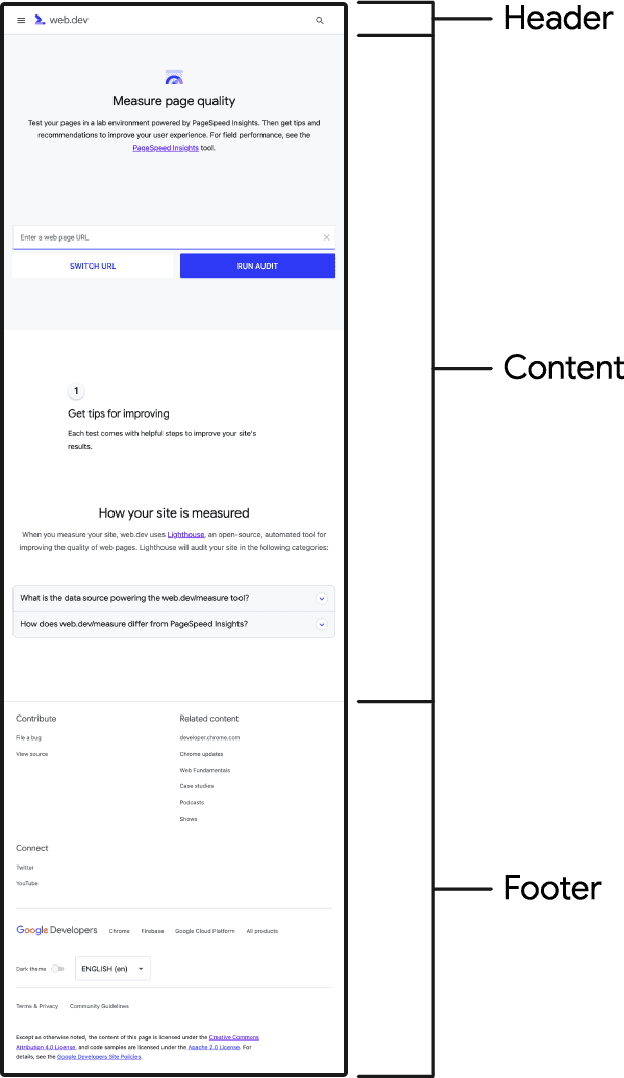
Celem identyfikacji części strony jest określenie, jakie elementy można wstępnie zapisać w pamięci podręcznej i pobrać bez przechodzenia do sieci. Chodzi mi o znaczniki nagłówka i stopki wspólne dla wszystkich stron, a w tym przypadku tę część strony, która zawsze jest przesyłana do sieci w pierwszej kolejności.
Jeśli wiemy, jak podzielić fragmenty strony i zidentyfikować wspólne elementy, możemy napisać mechanizm Service Worker, który zawsze będzie pobierać znaczniki nagłówka i stopki z pamięci podręcznej, a zarazem żądać tylko treści z sieci.
Następnie za pomocą interfejsu Streams API w workbox-streams możemy połączyć wszystkie te elementy i natychmiast odpowiadać na żądania nawigacji, przesyłając z sieci minimalną wymaganą ilość znaczników.
Tworzenie instancji roboczej usługi strumieniowania
Strumieniowanie częściowych treści za pomocą skryptu service worker składa się z wielu elementów, ale każdy z nich zostanie szczegółowo omówiony, zaczynając od struktury witryny.
Posegmentowanie witryny na części
Zanim zaczniesz pisać skrypt service worker usługi przesyłania strumieniowego, musisz wykonać 3 czynności:
- Utwórz plik zawierający wyłącznie znaczniki nagłówka Twojej witryny.
- Utwórz plik zawierający tylko znaczniki stopki w swojej witrynie.
- Pobierz główną zawartość każdej strony do osobnego pliku lub skonfiguruj backend, aby warunkowo wyświetlać tylko zawartość strony na podstawie nagłówka żądania HTTP.
Jak można się spodziewać, ostatni krok jest najtrudniejszy, zwłaszcza jeśli Twoja witryna jest statyczna. W takim przypadku musisz wygenerować 2 wersje każdej strony: jedna będzie zawierać pełne znaczniki strony, a druga tylko treść.
Tworzenie instancji roboczej usługi strumieniowego przesyłania danych
Jeśli moduł workbox-streams nie został zainstalowany, oprócz wszystkich obecnie zainstalowanych modułów Workbox musisz zainstalować te moduły. W tym przykładzie dotyczy to tych pakietów:
npm i workbox-navigation-preload workbox-strategies workbox-routing workbox-precaching workbox-streams --save
Następnym krokiem jest utworzenie nowego skryptu service worker i wstępne zapisywanie w pamięci podręcznej części nagłówka i stopki.
Częściowe wstępne buforowanie
Najpierw utworzysz skrypt service worker w katalogu głównym projektu o nazwie sw.js (lub innej preferowanej nazwie pliku). Na początek:
// sw.js
import * as navigationPreload from 'workbox-navigation-preload';
import {NetworkFirst} from 'workbox-strategies';
import {registerRoute} from 'workbox-routing';
import {matchPrecache, precacheAndRoute} from 'workbox-precaching';
import {strategy as composeStrategies} from 'workbox-streams';
// Enable navigation preload for supporting browsers
navigationPreload.enable();
// Precache partials and some static assets
// using the InjectManifest method.
precacheAndRoute([
// The header partial:
{
url: '/partial-header.php',
revision: __PARTIAL_HEADER_HASH__
},
// The footer partial:
{
url: '/partial-footer.php',
revision: __PARTIAL_FOOTER_HASH__
},
// The offline fallback:
{
url: '/offline.php',
revision: __OFFLINE_FALLBACK_HASH__
},
...self.__WB_MANIFEST
]);
// To be continued...
Ten kod ma kilka funkcji:
- Włącza wstępne wczytywanie nawigacji w przeglądarkach, które ją obsługują.
- Umieszcza w pamięci podręcznej znaczniki nagłówka i stopki. Oznacza to, że znaczniki nagłówka i stopki każdej strony są pobierane od razu, ponieważ nie są blokowane przez sieć.
- Powoduje wstępne wczytywanie zasobów statycznych w zmiennej
__WB_MANIFEST, która korzysta z metodyinjectManifest.
Strumieniowanie odpowiedzi
Najważniejszym elementem tego procesu jest zachęcenie skryptu service worker do strumieniowania połączonych odpowiedzi. Jednak dzięki Workbox i jego workbox-streams nie trzeba robić tego wszystkiego samodzielnie:
// sw.js
import * as navigationPreload from 'workbox-navigation-preload';
import {NetworkFirst} from 'workbox-strategies';
import {registerRoute} from 'workbox-routing';
import {matchPrecache, precacheAndRoute} from 'workbox-precaching';
import {strategy as composeStrategies} from 'workbox-streams';
// ...
// Prior navigation preload and precaching code omitted...
// ...
// The strategy for retrieving content partials from the network:
const contentStrategy = new NetworkFirst({
cacheName: 'content',
plugins: [
{
// NOTE: This callback will never be run if navigation
// preload is not supported, because the navigation
// request is dispatched while the service worker is
// booting up. This callback will only run if navigation
// preload is _not_ supported.
requestWillFetch: ({request}) => {
const headers = new Headers();
// If the browser doesn't support navigation preload, we need to
// send a custom `X-Content-Mode` header for the back end to use
// instead of the `Service-Worker-Navigation-Preload` header.
headers.append('X-Content-Mode', 'partial');
// Send the request with the new headers.
// Note: if you're using a static site generator to generate
// both full pages and content partials rather than a back end
// (as this example assumes), you'll need to point to a new URL.
return new Request(request.url, {
method: 'GET',
headers
});
},
// What to do if the request fails.
handlerDidError: async ({request}) => {
return await matchPrecache('/offline.php');
}
}
]
});
// Concatenates precached partials with the content partial
// obtained from the network (or its fallback response).
const navigationHandler = composeStrategies([
// Get the precached header markup.
() => matchPrecache('/partial-header.php'),
// Get the content partial from the network.
({event}) => contentStrategy.handle(event),
// Get the precached footer markup.
() => matchPrecache('/partial-footer.php')
]);
// Register the streaming route for all navigation requests.
registerRoute(({request}) => request.mode === 'navigate', navigationHandler);
// Your service worker can end here, or you can add more
// logic to suit your needs, such as runtime caching, etc.
Kod składa się z 3 głównych części, które spełniają te wymagania:
- Strategia
NetworkFirstsłuży do obsługi żądań części treści. W ramach tej strategii określono niestandardową nazwę pamięci podręcznejcontent, która będzie zawierać części treści, oraz niestandardową wtyczkę, która określa, czy należy ustawić nagłówek żądaniaX-Content-Modedla przeglądarek, które nie obsługują wstępnego wczytywania nawigacji (i dlatego nie wysyłają nagłówkaService-Worker-Navigation-Preload). Wtyczka określa też, czy wysłać ostatnią wersję części treści w pamięci podręcznej, czy też wysłać zastępczą stronę offline, jeśli nie przechowujemy wersji bieżącego żądania w pamięci podręcznej. - Metoda
strategyw zasadzieworkbox-streams(używana tutaj jakocomposeStrategies) służy do łączenia części nagłówka i stopki wstępnie z pamięci podręcznej z częściową zawartością żądanej z sieci. - Cały schemat jest obsługiwany przez
registerRoutedla żądań nawigacji.
W przypadku tych zasad skonfigurowane jest przesyłanie odpowiedzi na bieżąco. Może się jednak okazać, że musisz wykonać pewne czynności w backendzie, aby treści z sieci stanowiły tylko część strony, którą da się scalić z częściami w pamięci podręcznej.
Jeśli witryna ma backend
Gdy jest włączone wstępne wczytywanie nawigacji, przeglądarka wysyła nagłówek Service-Worker-Navigation-Preload z wartością true. W powyższym przykładowym kodzie wysłaliśmy jednak niestandardowy nagłówek X-Content-Mode, gdy wstępne wczytywanie nawigacji po zdarzeniach nie jest obsługiwane w przeglądarce. Możesz zmienić odpowiedź odpowiednio do obecności takich nagłówków. W kodzie PHP może to wyglądać mniej więcej tak w przypadku danej strony:
<?php
// Check if we need to render a content partial
$navPreloadSupported = isset($_SERVER['HTTP_SERVICE_WORKER_NAVIGATION_PRELOAD']) && $_SERVER['HTTP_SERVICE_WORKER_NAVIGATION_PRELOAD'] === 'true';
$partialContentMode = isset($_SERVER['HTTP_X_CONTENT_MODE']) && $_SERVER['HTTP_X_CONTENT_MODE'] === 'partial';
$isPartial = $navPreloadSupported || $partialContentMode;
// Figure out whether to render the header
if ($isPartial === false) {
// Get the header include
require_once($_SERVER['DOCUMENT_ROOT'] . '/includes/site-header.php');
// Render the header
siteHeader();
}
// Get the content include
require_once('./content.php');
// Render the content
content($isPartial);
// Figure out whether to render the footer
if ($isPartial === false) {
// Get the footer include
require_once($_SERVER['DOCUMENT_ROOT'] . '/includes/site-footer.php');
// Render the footer
siteFooter();
}
?>
W powyższym przykładzie fragmenty treści są wywoływane jako funkcje, które przyjmują wartość $isPartial, aby zmienić sposób renderowania fragmentów. Na przykład funkcja renderowania content może zawierać w warunkach tylko określone znaczniki, które po pobraniu jako częściowe – co omówimy wkrótce.
Uwagi
Zanim wdrożysz skrypt service worker w celu strumieniowania i połączenia części, musisz wziąć pod uwagę kilka rzeczy. Chociaż użycie skryptu service worker w ten sposób nie zmienia domyślnego działania nawigacji w przeglądarce, prawdopodobnie trzeba będzie rozwiązać kilka kwestii.
aktualizowanie elementów strony podczas nawigacji,
Najtrudniejsze w tym podejściu jest to, że niektóre rzeczy trzeba będzie zaktualizować po stronie klienta. Na przykład znaczniki nagłówka w pamięci podręcznej oznaczają, że strona będzie zawierać te same treści w elemencie <title>, a nawet konieczna będzie aktualizacja stanów włączenia/wyłączenia elementów nawigacyjnych przy każdej nawigacji. Te i inne elementy może wymagać aktualizacji po stronie klienta dla każdego żądania nawigacji.
Aby obejść ten problem, możesz umieścić wbudowany element <script> w części treści pochodzącej z sieci, aby zaktualizować kilka ważnych elementów:
<!-- The JSON below contains information about the current page. -->
<script id="page-data" type="application/json">'{"title":"Sand Wasp — World of Wasps","description":"Read all about the sand wasp in this tidy little post."}'</script>
<script>
const pageData = JSON.parse(document.getElementById('page-data').textContent);
// Update the page title
document.title = pageData.title;
</script>
<article>
<!-- Page content omitted... -->
</article>
To tylko jeden z przykładów tego, co musisz zrobić, jeśli zdecydujesz się na tę konfigurację skryptu service worker. W przypadku bardziej złożonych aplikacji, które zawierają informacje o użytkowniku, konieczne może być na przykład przechowywanie odpowiednich danych w sklepie internetowym (takim jak localStorage) i aktualizowanie strony w tym sklepie.
Jak radzić sobie z powolnymi sieciami
Jedną z wad związanych ze strumieniowym przesyłaniem odpowiedzi ze znacznikami z pamięci podręcznej może być wolne połączenie sieciowe. Problem polega na tym, że znaczniki nagłówka z pamięci podręcznej pojawiają się natychmiast, jednak fragment treści z sieci może pojawić się dopiero po pewnym czasie od wstępnego wyrenderowania znaczników nagłówka.
Może to powodować dezorientację, a przy bardzo powolnym działaniu sieci może się nawet wydawać, że strona nie działa i nie wyświetla się dalej. W takich przypadkach możesz umieścić ikonę lub komunikat wczytywania w znacznikach części treści, które będzie można ukryć po wczytaniu treści.
Możesz to zrobić na przykład za pomocą CSS. Załóżmy, że część nagłówka kończy się otwierającym elementem <article>, który jest pusty, dopóki nie wypełni się częściowej treści. Możesz utworzyć regułę CSS podobną do tej:
article:empty::before {
text-align: center;
content: 'Loading...';
}
Działa, ale niezależnie od szybkości sieci komunikat o wczytywaniu jest wyświetlany po stronie klienta. Jeśli chcesz uniknąć dziwnego pojawienia się komunikatu, możesz zastosować metodę, w której zagnieżdżamy selektor we fragmencie kodu powyżej w klasie slow:
.slow article:empty::before {
text-align: center;
content: 'Loading...';
}
Następnie możesz użyć JavaScriptu w części nagłówka, aby odczytać efektywny typ połączenia (przynajmniej w przeglądarkach Chromium), aby dodać klasę slow do elementu <html> przy wybranych typach połączeń:
<script>
const effectiveType = navigator?.connection?.effectiveType;
if (effectiveType !== '4g') {
document.documentElement.classList.add('slow');
}
</script>
Dzięki temu będziesz mieć pewność, że efektywne typy połączeń wolniejsze niż typ 4g otrzymają komunikat o wczytywaniu. Następnie w części zawartości możesz umieścić wbudowany element <script>, aby usunąć klasę slow z kodu HTML w celu pozbycia się komunikatu o wczytywaniu:
<script>
document.documentElement.classList.remove('slow');
</script>
Określanie odpowiedzi zastępczej
Załóżmy, że w przypadku częściowych treści stosujesz strategię skoncentrowaną na sieci. Jeśli użytkownik jest offline i wejdzie na stronę, którą już odwiedził, będzie ona objęta ochroną. Jeśli jednak wejdą na stronę, której jeszcze nie odwiedzili, nie zobaczą niczego. Aby tego uniknąć, musisz wyświetlić odpowiedź zastępczą.
Kod wymagany do uzyskania odpowiedzi zastępczej przedstawiliśmy we wcześniejszych przykładach kodu. Ten proces składa się z 2 etapów:
- Wstępnie buforuj odpowiedź zastępczą offline.
- Skonfiguruj wywołanie zwrotne
handlerDidErrorwe wtyczce dla strategii skoncentrowanej na sieci, aby sprawdzić pamięć podręczną ostatnio wyświetlanej wersji strony. Jeśli strona nigdy nie była otwierana, musisz użyć metodymatchPrecachez modułuworkbox-precaching, aby pobrać odpowiedź zastępczą z pamięci podręcznej.
Pamięć podręczna i CDN
Jeśli takiego wzorca strumieniowego przesyłania danych używasz w skrypcie service worker, sprawdź, czy w Twojej sytuacji pasuje do tego:
- używasz CDN lub innego rodzaju pośredniej/publicznej pamięci podręcznej.
- Określono nagłówek
Cache-Controlz inną dyrektywąmax-agelubs-maxagew połączeniu z dyrektywąpublic.
Jeśli spełniasz oba te warunki, pośrednia pamięć podręczna może przechowywać odpowiedzi dla żądań nawigacji. Pamiętaj jednak, że w przypadku korzystania z tego wzorca możesz udostępniać 2 różne odpowiedzi dla każdego adresu URL:
- Pełna odpowiedź zawierająca znaczniki nagłówka, treści i stopki.
- Odpowiedź częściowa zawierająca tylko treść.
Może to powodować pewne niepożądane działania, co prowadzi do podwojenia znaczników nagłówka i stopki, ponieważ mechanizm Service Worker może pobierać pełną odpowiedź z pamięci podręcznej CDN i łączyć to ze wstępnie zapisanymi znacznikami nagłówka i stopki.
Aby obejść ten problem, musisz korzystać z nagłówka Vary, który wpływa na zachowanie buforowania przez klucz odpowiedzi możliwych do zapisania w pamięci podręcznej do co najmniej 1 nagłówka, który znajdował się w żądaniu. Odpowiedzi na żądania nawigacji różnią się w zależności od nagłówków żądań Service-Worker-Navigation-Preload i niestandardowych X-Content-Mode, dlatego w odpowiedzi musimy określić ten nagłówek Vary:
Vary: Service-Worker-Navigation-Preload,X-Content-Mode
Ten nagłówek pozwala przeglądarce rozróżnić pełne i częściowe odpowiedzi na żądania nawigacji, unikając problemów ze podwójnymi znacznikami nagłówka i stopki oraz pośrednimi pamięciami podręcznymi.
Wynik
Większość porad dotyczących wydajności w czasie wczytywania sprowadza się do tego, że „pokaż mu, co masz”. Nie ograniczaj się i nie czekaj, aż wszystko będzie gotowe, zanim pokażesz cokolwiek użytkownikowi.
Jake Archibald w filmie Fun Hacks for Faster Content .
Przeglądarki świetnie sobie radzą z odpowiedziami na żądania związane z nawigacją, nawet w przypadku ogromnych treści odpowiedzi HTML. Domyślnie przeglądarki stopniowo przesyłają strumieniowo i przetwarzają znaczniki we fragmentach, co pozwala uniknąć długich zadań, co jest korzystne dla wydajności uruchamiania.
Jest to korzystna opcja, gdy używamy wzorca mechanizmu roboczego usługi strumieniowego przesyłania danych. Za każdym razem, gdy już od początku odpowiadasz na żądanie z pamięci podręcznej skryptu service worker, początek odpowiedzi pojawia się niemal natychmiast. Połączenie wstępnie zapisanych znaczników nagłówka i stopki w pamięci podręcznej z odpowiedziami z sieci pozwala uzyskać istotne korzyści w zakresie wydajności:
- Czas do pierwszego bajtu (TTFB) jest często znacznie skrócony, ponieważ pierwszy bajt odpowiedzi na żądanie nawigacji jest natychmiastowy.
- Pierwsze wyrenderowanie treści (FCP) będzie bardzo szybkie, ponieważ znaczniki nagłówka w pamięci podręcznej zawierają odniesienie do arkusza stylów w pamięci podręcznej, co oznacza, że strona wczytuje się bardzo, bardzo szybko.
- W niektórych przypadkach największe wyrenderowanie treści (LCP) może też być szybsze, zwłaszcza jeśli największy element na ekranie jest dostarczany przez część nagłówka ze wstępnie buforowanym. Mimo to jak najszybsze udostępnienie czegoś z pamięci podręcznej mechanizmu Service Worker w połączeniu z mniejszymi ładunkami znaczników może poprawić LCP.
Strumieniowanie wielostronicowych architektur może być nieco skomplikowane, ale złożoność nie jest w teorii bardziej uciążliwa niż SPA. Główną zaletą jest to, że nie zastępujesz domyślnego schematu nawigacji przeglądarki, tylko go ulepszasz.
Co więcej, Workbox sprawia, że taka architektura jest nie tylko możliwa, ale też łatwiejsza niż w przypadku samodzielnego wdrożenia. Wypróbuj je w swojej witrynie i zobacz, o ile szybsza może być witryna wielostronicowa dla użytkowników w terenie.