



Publicado: 16 de mayo de 2024
Las opiniones positivas y negativas pueden influir en la decisión de compra de un comprador.
Según una investigación externa, el 82% de los compradores en línea buscan activamente opiniones negativas antes de realizar una compra. Estas opiniones negativas son útiles para los clientes y las empresas, ya que su disponibilidad puede ayudar a reducir las tasas de devoluciones y a los fabricantes a mejorar sus productos.
Estas son algunas formas en las que puedes mejorar la calidad de las opiniones:
- Verifica la toxicidad de cada opinión antes de enviarla. Podríamos alentar a los usuarios a quitar el lenguaje ofensivo y otros comentarios poco útiles para que su opinión ayude mejor a otros usuarios a tomar una mejor decisión de compra.
- Negativa: Este bolso es horrible y lo odio.
- Negativo con comentarios útiles Los cierres son muy rígidos y el material se siente de mala calidad. Devolví este bolso.
- Genera automáticamente una calificación según el idioma que se usa en la opinión.
- Determina si la opinión es negativa o positiva.
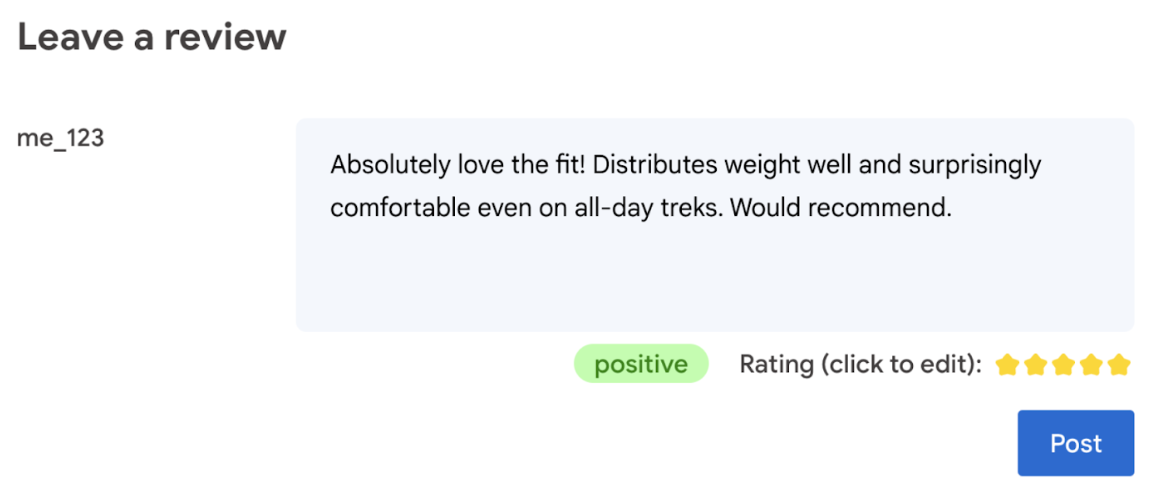
En última instancia, el usuario debe tener la última palabra sobre la calificación del producto.
El siguiente codelab ofrece soluciones del cliente, en el dispositivo y en el navegador. No se requieren conocimientos de desarrollo de IA, servidores ni claves de API.
Requisitos previos
Si bien la IA del servidor con soluciones (como la API de Gemini o la API de OpenAI) ofrece soluciones sólidas para muchas aplicaciones, en esta guía nos enfocamos en la IA web del cliente. La inferencia de IA del cliente se produce en el navegador para mejorar la experiencia de los usuarios web, ya que elimina los viajes de ida y vuelta del servidor.
En este codelab, usamos una combinación de técnicas para mostrarte lo que tienes en tu caja de herramientas para la IA del cliente.
Usamos los siguientes modelos y bibliotecas:
- TensforFlow.js para el análisis de toxicidad TensorFlow.js es una biblioteca de aprendizaje automático de código abierto para la inferencia y el entrenamiento en la Web.
- transformers.js para el análisis de opiniones Transformers.js es una biblioteca de IA web de Hugging Face.
- Gemma 2B para las calificaciones por estrellas. Gemma es una familia de modelos abiertos y ligeros creados a partir de la investigación y la tecnología que Google usó para crear los modelos de Gemini. Para ejecutar Gemma en el navegador, lo usamos con la API de LLM Inference experimental de MediaPipe.
Consideraciones de UX y seguridad
Hay algunas consideraciones para garantizar una experiencia del usuario y una seguridad óptimas:
- Permite que el usuario edite la calificación. En última instancia, el usuario debe tener la última palabra sobre la calificación del producto.
- Indícale claramente al usuario que las calificaciones y las opiniones son automáticas.
- Permite que los usuarios publiquen una opinión clasificada como tóxica, pero ejecuta una segunda verificación en el servidor. Esto evita una experiencia frustrante en la que una opinión no tóxica se clasifica erróneamente como tóxica (un falso positivo). Esto también abarca los casos en los que un usuario malicioso logra eludir la verificación del cliente.
- Una verificación de toxicidad del cliente es útil, pero se puede omitir. Asegúrate de ejecutar una verificación del servidor también.
Analiza la toxicidad con TensorFlow.js
Es rápido comenzar a analizar la toxicidad de una opinión del usuario con TensorFlow.js.
- Instala y carga la biblioteca de TensorFlow.js y el modelo de toxicidad.
- Establece un nivel mínimo de confianza en la predicción. El valor predeterminado es 0.85, y, en nuestro ejemplo, lo establecimos en 0.9.
- Carga el modelo de forma asíncrona.
- Clasifica la opinión de forma asíncrona. Nuestro código identifica las predicciones que superan un umbral de 0.9 para cualquier categoría.
Este modelo puede categorizar la toxicidad en ataques a la identidad, insultos, obscenidades y mucho más.
Por ejemplo:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Determina el sentimiento con Transformers.js
Instala e importa la biblioteca de Transformers.js.
Configura la tarea de análisis de opiniones con una canalización dedicada. Cuando se usa una canalización por primera vez, el modelo se descarga y se almacena en caché. A partir de ese momento, el análisis de opiniones debería ser mucho más rápido.
Clasifica la opinión de forma asíncrona. Usa un umbral personalizado para establecer el nivel de confianza que consideras útil para tu aplicación.
Por ejemplo:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Sugerir una calificación por estrellas con Gemma y MediaPipe
Con la API de LLM Inference, puedes ejecutar modelos de lenguaje grandes (LLM) completamente en el navegador.
Esta nueva capacidad es particularmente transformadora si se tienen en cuenta las demandas de memoria y procesamiento de los LLM, que son más de cien veces mayores que las de los modelos del cliente. Las optimizaciones en toda la pila web hacen que esto sea posible, incluidas las nuevas operaciones, la cuantización, el almacenamiento en caché y el uso compartido de pesos. Fuente: "Large Language Models On-Device with MediaPipe and TensorFlow Lite".
- Instala e importa la API de inferencia de LLM de MediaPipe.
- Descarga un modelo. Aquí, usamos Gemma 2B, descargado de Kaggle. Gemma 2B es el más pequeño de los modelos de código abierto de Google.
- Apunta el código a los archivos del modelo correctos con
FilesetResolver. Esto es importante porque los modelos de IA generativa pueden tener una estructura de directorios específica para sus recursos. - Carga y configura el modelo con la interfaz de LLM de MediaPipe. Prepara el modelo para su uso: especifica su ubicación, la longitud preferida de las respuestas y el nivel de creatividad preferido con la temperatura.
- Dale una instrucción al modelo (consulta un ejemplo).
- Espera la respuesta del modelo.
- Analiza la calificación: Extrae la calificación con estrellas de la respuesta del modelo.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Ejemplo de instrucción
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Conclusiones
No se requiere experiencia en IA o AA. El diseño de una instrucción requiere iteraciones, pero el resto del código es desarrollo web estándar.
Los modelos del lado del cliente son bastante precisos. Si ejecutas los fragmentos de este documento, observarás que tanto el análisis de toxicidad como el de opiniones arrojan resultados precisos. En su mayor parte, las calificaciones de Gemma coincidieron con las del modelo de Gemini para algunas opiniones de referencia probadas. Para validar esa precisión, se requieren más pruebas.
Dicho esto, diseñar la instrucción para Gemma 2B requiere trabajo. Dado que Gemma 2B es un LLM pequeño, necesita una instrucción detallada para producir resultados satisfactorios, notablemente más detallada que la que se requiere con la API de Gemini.
La inferencia puede ser muy rápida. Si ejecutas los fragmentos de este documento, deberías observar que la inferencia puede ser rápida, posiblemente más rápida que los viajes de ida y vuelta del servidor, en varios dispositivos. Dicho esto, la velocidad de inferencia puede variar mucho. Se necesita una evaluación comparativa exhaustiva en los dispositivos objetivo. Esperamos que la inferencia del navegador siga siendo más rápida con WebGPU, WebAssembly y las actualizaciones de la biblioteca. Por ejemplo, Transformers.js agregó compatibilidad con WebGPU en la versión 3, lo que puede acelerar la inferencia en el dispositivo muchas veces.
Los tamaños de descarga pueden ser muy grandes. La inferencia en el navegador es rápida, pero cargar modelos de IA puede ser un desafío. Para ejecutar la IA en el navegador, por lo general, necesitas una biblioteca y un modelo, lo que aumenta el tamaño de descarga de tu app web.
Si bien el modelo de toxicidad de TensorFlow (un modelo clásico de procesamiento de lenguaje natural) solo ocupa unos pocos kilobytes, los modelos de IA generativa, como el modelo de análisis de opiniones predeterminado de Transformers.js, alcanzan los 60 MB. Los modelos de lenguaje grandes, como Gemma, pueden tener un tamaño de hasta 1.3 GB. Esto supera con creces el tamaño medio de 2.2 MB de las páginas web, que ya es mucho más grande de lo recomendado para obtener el mejor rendimiento. La IA generativa del cliente es viable en situaciones específicas.
El campo de la IA generativa en la Web está evolucionando rápidamente. Se espera que surjan modelos más pequeños y optimizados para la Web en el futuro.
Próximos pasos
Chrome está experimentando con otra forma de ejecutar la IA generativa en el navegador. Puedes registrarte en el Programa de versión preliminar anticipada para probarla.