

Supporto dei valori in virgola mobile a 16 bit in WGSL
In WGSL, il tipo f16 è l'insieme di valori in virgola mobile a 16 bit del formato IEEE-754 binary16 (mezza precisione). Ciò significa che utilizza 16 bit per rappresentare un numero in virgola mobile, anziché 32 bit per la virgola mobile a precisione singola convenzionale (f32). Questa dimensione più piccola può portare a miglioramenti significativi delle prestazioni, soprattutto quando si elaborano grandi quantità di dati.
Per confronto, su un dispositivo Apple M1 Pro, l'implementazione di f16 dei modelli Llama2 7B utilizzati nella demo di chat WebLLM è notevolmente più veloce dell'implementazione di f32, con un miglioramento del 28% della velocità di precompilazione e del 41% della velocità di decodifica, come mostrato negli screenshot seguenti.
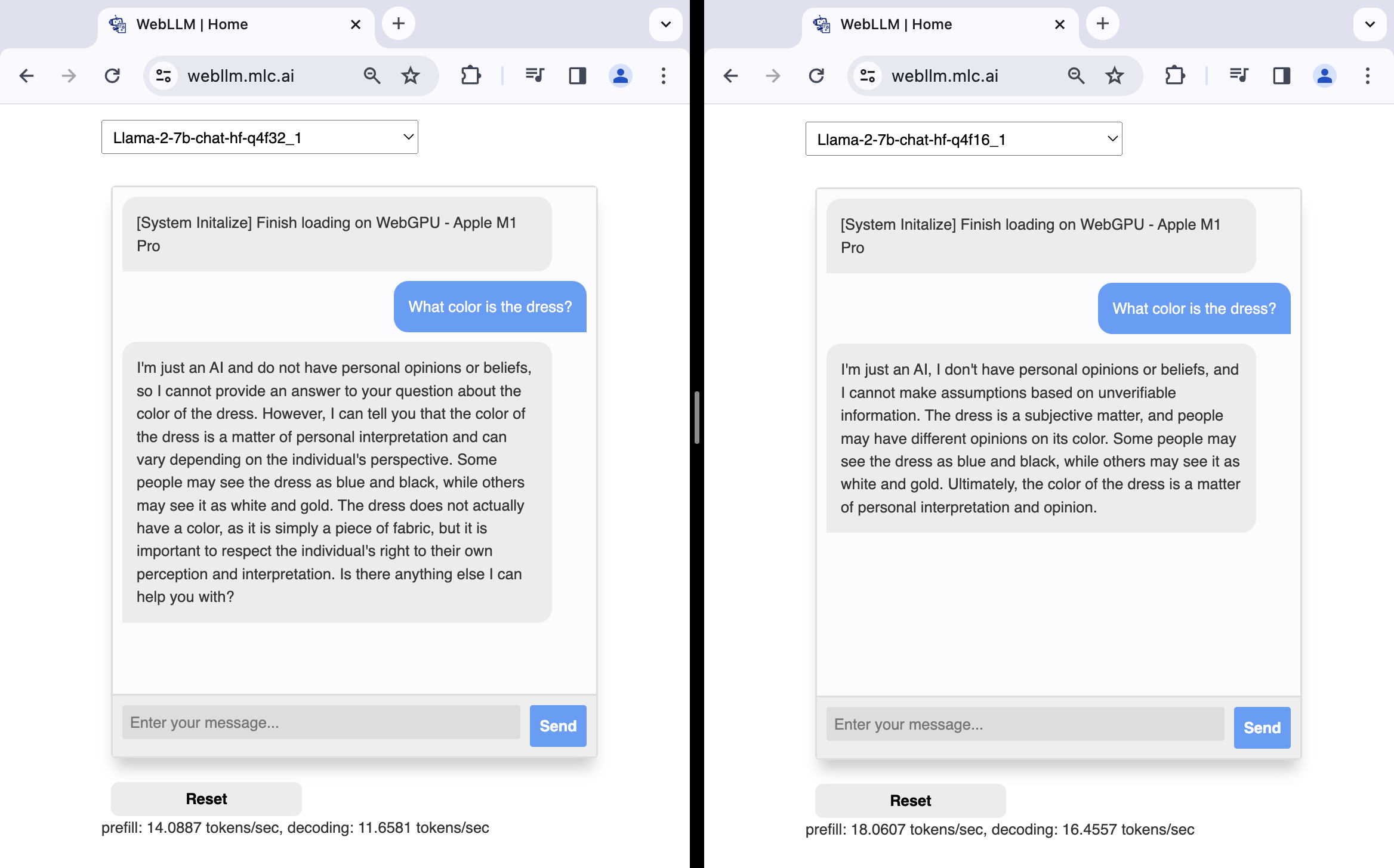
f32 (a sinistra) e f16 (a destra).Non tutte le GPU supportano valori in virgola mobile a 16 bit. Quando la funzionalità "shader-f16" è disponibile in un GPUAdapter, ora puoi richiedere un GPUDevice con questa funzionalità e creare un modulo shader WGSL che sfrutta il tipo di dati in virgola mobile a mezza precisione f16. Questo tipo è valido per l'utilizzo nel modulo shader WGSL solo se abiliti l'estensione WGSL con enable f16;.f16 In caso contrario, createShaderModule() genererà un errore di convalida. Vedi il seguente esempio minimo e il problema dawn:1510.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter.features.has("shader-f16")) {
throw new Error("16-bit floating-point value support is not available");
}
// Explicitly request 16-bit floating-point value support.
const device = await adapter.requestDevice({
requiredFeatures: ["shader-f16"],
});
const code = `
enable f16;
@compute @workgroup_size(1)
fn main() {
const c : vec3h = vec3<f16>(1.0h, 2.0h, 3.0h);
}
`;
const shaderModule = device.createShaderModule({ code });
// Create a compute pipeline with this shader module
// and run the shader on the GPU...
È possibile supportare sia i tipi f16 che f32 nel codice del modulo shader WGSL con un alias a seconda del supporto della funzionalità "shader-f16", come mostrato nello snippet seguente.
const adapter = await navigator.gpu.requestAdapter();
const hasShaderF16 = adapter.features.has("shader-f16");
const device = await adapter.requestDevice({
requiredFeatures: hasShaderF16 ? ["shader-f16"] : [],
});
const header = hasShaderF16
? `enable f16;
alias min16float = f16;`
: `alias min16float = f32;`;
const code = `
${header}
@compute @workgroup_size(1)
fn main() {
const c = vec3<min16float>(1.0, 2.0, 3.0);
}
`;
Superare i limiti
Il numero massimo di byte necessari per contenere un campione (pixel o subpixel) dei dati di output della pipeline di rendering, in tutti gli allegati di colore, è 32 byte per impostazione predefinita. Ora è possibile richiedere fino a 64 utilizzando il limite maxColorAttachmentBytesPerSample. Vedi l'esempio seguente e issue dawn:2036.
const adapter = await navigator.gpu.requestAdapter();
if (adapter.limits.maxColorAttachmentBytesPerSample < 64) {
// When the desired limit isn't supported, take action to either fall back to
// a code path that does not require the higher limit or notify the user that
// their device does not meet minimum requirements.
}
// Request highest limit of max color attachments bytes per sample.
const device = await adapter.requestDevice({
requiredLimits: { maxColorAttachmentBytesPerSample: 64 },
});
I limiti di maxInterStageShaderVariables e maxInterStageShaderComponents utilizzati per la comunicazione tra le fasi sono stati aumentati su tutte le piattaforme. Per i dettagli, vedi issue dawn:1448.
Per ogni fase dello shader, il numero massimo di voci di layout del gruppo di binding in un layout della pipeline che sono buffer di archiviazione è 8 per impostazione predefinita. Ora è possibile richiedere fino a 10 utilizzando il limite maxStorageBuffersPerShaderStage. Vedi issue dawn:2159.
È stato aggiunto un nuovo limite per maxBindGroupsPlusVertexBuffers. È costituito dal numero massimo di slot di gruppi di binding e buffer dei vertici utilizzati contemporaneamente, contando gli slot vuoti sotto l'indice più alto. Il valore predefinito è 24. Vedi issue dawn:1849.
Modifiche allo stato di profondità-stencil
Per migliorare l'esperienza degli sviluppatori, gli attributi depthWriteEnabled e depthCompare dello stato di profondità-stencil non sono più sempre obbligatori: depthWriteEnabled è obbligatorio solo per i formati con profondità e depthCompare non è obbligatorio per i formati con profondità se non viene utilizzato. Vedi issue dawn:2132.
Aggiornamenti delle informazioni sull'adattatore
Gli attributi delle informazioni sull'adattatore type e backend non standard sono ora disponibili quando viene chiamato requestAdapterInfo() se l'utente ha attivato il flag "Funzionalità per sviluppatori WebGPU" all'indirizzo chrome://flags/#enable-webgpu-developer-features. type può essere "GPU discreta", "GPU integrata", "CPU" o "sconosciuto". backend è "WebGPU", "D3D11", "D3D12", "metal", "vulkan", "openGL", "openGLES" o "null". Vedi issue dawn:2112 e issue dawn:2107.
Il parametro di elenco facoltativo unmaskHints in requestAdapterInfo() è stato rimosso. Vedi issue dawn:1427.
Quantizzazione delle query con timestamp
Le query sui timestamp consentono alle applicazioni di misurare il tempo di esecuzione dei comandi della GPU con una precisione al nanosecondo. Tuttavia, la specifica WebGPU rende facoltative le query sui timestamp a causa di problemi di attacco temporale. Il team di Chrome ritiene che la quantizzazione delle query di timestamp offra un buon compromesso tra precisione e sicurezza, riducendo la risoluzione a 100 microsecondi. Vedi issue dawn:1800.
In Chrome, gli utenti possono disattivare la quantizzazione dei timestamp attivando il flag "Funzionalità per sviluppatori WebGPU" all'indirizzo chrome://flags/#enable-webgpu-developer-features. Tieni presente che questo flag da solo non attiva la funzionalità "timestamp-query". La sua implementazione è ancora sperimentale e pertanto richiede il flag "Unsafe WebGPU Support" (Supporto WebGPU non sicuro) all'indirizzo chrome://flags/#enable-unsafe-webgpu.
In Dawn è stato aggiunto un nuovo pulsante di attivazione/disattivazione del dispositivo denominato "timestamp_quantization", che è abilitato per impostazione predefinita. Il seguente snippet mostra come consentire la funzionalità sperimentale "timestamp-query" senza quantizzazione del timestamp quando si richiede un dispositivo.
wgpu::DawnTogglesDescriptor deviceTogglesDesc = {};
const char* allowUnsafeApisToggle = "allow_unsafe_apis";
deviceTogglesDesc.enabledToggles = &allowUnsafeApisToggle;
deviceTogglesDesc.enabledToggleCount = 1;
const char* timestampQuantizationToggle = "timestamp_quantization";
deviceTogglesDesc.disabledToggles = ×tampQuantizationToggle;
deviceTogglesDesc.disabledToggleCount = 1;
wgpu::DeviceDescriptor desc = {.nextInChain = &deviceTogglesDesc};
// Request a device with no timestamp quantization.
myAdapter.RequestDevice(&desc, myCallback, myUserData);
Funzionalità per le pulizie di primavera
La funzionalità sperimentale "timestamp-query-inside-passes" è stata rinominata "chromium-experimental-timestamp-query-inside-passes" per indicare chiaramente agli sviluppatori che questa funzionalità è sperimentale e al momento disponibile solo nei browser basati su Chromium. Vedi issue dawn:1193.
La funzionalità sperimentale "pipeline-statistics-query", implementata solo parzialmente, è stata rimossa perché non è più in fase di sviluppo. Vedi issue chromium:1177506.
Questi sono solo alcuni dei punti salienti. Consulta l'elenco completo dei commit.
Novità di WebGPU
Un elenco di tutti gli argomenti trattati nella serie Novità di WebGPU.
Chrome 143
- Scambio dei componenti di texture
- Rimuovere l'utilizzo della texture di archiviazione di sola lettura bgra8unorm
- Aggiornamenti di Dawn
Chrome 142
- Funzionalità di supporto del formato delle texture estese
- Indice primitivo in WGSL
- Aggiornamenti di Dawn
Chrome 141
- Tint IR completed
- Analisi dell'intervallo di numeri interi nel compilatore WGSL
- Aggiornamento di SPIR-V 1.4 per il backend Vulkan
- Aggiornamenti di Dawn
Chrome 140
- Le richieste di dispositivi utilizzano l'adattatore
- Abbreviazione per l'utilizzo della texture in cui viene utilizzata la visualizzazione della texture
- WGSL textureSampleLevel supporta le texture 1D
- Ritiro dell'utilizzo della texture di archiviazione di sola lettura bgra8unorm
- Rimuovi l'attributo isFallbackAdapter di GPUAdapter
- Aggiornamenti di Dawn
Chrome 139
- Supporto delle texture 3D per i formati compressi BC e ASTC
- Nuova funzionalità "Funzionalità e limiti principali"
- Origin trial per la modalità di compatibilità WebGPU
- Aggiornamenti di Dawn
Chrome 138
- Abbreviazione per l'utilizzo del buffer come risorsa di binding
- Modifiche ai requisiti di dimensione per i buffer mappati durante la creazione
- Report sull'architettura per le GPU recenti
- Deprecare l'attributo isFallbackAdapter di GPUAdapter
- Aggiornamenti di Dawn
Chrome 137
- Utilizzare la visualizzazione della texture per il binding externalTexture
- I buffer vengono copiati senza specificare offset e dimensioni
- WGSL workgroupUniformLoad utilizzando il puntatore ad atomic
- Attributo powerPreference di GPUAdapterInfo
- Rimuovi l'attributo compatibilityMode di GPURequestAdapterOptions
- Aggiornamenti di Dawn
Chrome 136
- Attributo isFallbackAdapter di GPUAdapterInfo
- Miglioramenti del tempo di compilazione degli shader su D3D12
- Salvare e copiare le immagini della tela
- Limitazioni della modalità di compatibilità dell'impatto
- Aggiornamenti di Dawn
Chrome 135
- Consenti la creazione del layout della pipeline con il layout del gruppo di binding nullo
- Consenti alle finestre di visualizzazione di estendersi oltre i limiti delle destinazioni di rendering
- Accesso più semplice alla modalità di compatibilità sperimentale su Android
- Rimuovi il limite maxInterStageShaderComponents
- Aggiornamenti di Dawn
Chrome 134
- Migliorare i carichi di lavoro di machine learning con i sottogruppi
- Rimuovere il supporto dei tipi di texture filtrabili float come miscelabili
- Aggiornamenti di Dawn
Chrome 133
- Formati dei vertici unorm8x4-bgra e a un componente aggiuntivi
- Consenti di richiedere limiti sconosciuti con valore indefinito
- Modifiche alle regole di allineamento WGSL
- Miglioramenti delle prestazioni di WGSL con l'eliminazione
- Utilizzare displaySize di VideoFrame per le texture esterne
- Gestire le immagini con orientamenti non predefiniti utilizzando copyExternalImageToTexture
- Miglioramento dell'esperienza degli sviluppatori
- Attivare la modalità di compatibilità con featureLevel
- Pulizia delle funzionalità dei sottogruppi sperimentali
- Ritiro del limite maxInterStageShaderComponents
- Aggiornamenti di Dawn
Chrome 132
- Utilizzo della visualizzazione delle texture
- Fusione di texture in virgola mobile a 32 bit
- Attributo adapterInfo di GPUDevice
- Configurazione del contesto del canvas con formato non valido che genera un errore JavaScript
- Limitazioni del campionamento dei filtri sulle texture
- Sperimentazione estesa dei sottogruppi
- Miglioramento dell'esperienza degli sviluppatori
- Supporto sperimentale per i formati di texture normalizzati a 16 bit
- Aggiornamenti di Dawn
Chrome 131
- Distanze di ritaglio in WGSL
- GPUCanvasContext getConfiguration()
- Le primitive punto e linea non devono avere distorsione della profondità
- Funzioni integrate di scansione inclusiva per i sottogruppi
- Supporto sperimentale per l'estrazione indiretta multipla
- Opzione di compilazione del modulo shader Strict Math
- Rimozione di requestAdapterInfo() di GPUAdapter
- Aggiornamenti di Dawn
Chrome 130
- Combinazione di due fonti
- Miglioramenti al tempo di compilazione degli shader su Metal
- Ritiro di GPUAdapter requestAdapterInfo()
- Aggiornamenti di Dawn
Chrome 129
- Supporto HDR con modalità di mappatura della tonalità della tela
- Supporto per i sottogruppi espansi
- Aggiornamenti di Dawn
Chrome 128
- Sperimentazione con i sottogruppi
- Ritiro dell'impostazione della distorsione della profondità per linee e punti
- Nascondi l'avviso di DevTools relativo a un errore non acquisito se preventDefault
- WGSL interpolate sampling first and either
- Aggiornamenti di Dawn
Chrome 127
- Supporto sperimentale per OpenGL ES su Android
- Attributo info di GPUAdapter
- Miglioramenti dell'interoperabilità di WebAssembly
- Errori del codificatore di comandi migliorati
- Aggiornamenti di Dawn
Chrome 126
- Aumentare il limite di maxTextureArrayLayers
- Ottimizzazione del caricamento del buffer per il backend Vulkan
- Miglioramenti al tempo di compilazione degli shader
- I buffer dei comandi inviati devono essere univoci
- Aggiornamenti di Dawn
Chrome 125
- Sottogruppi (funzionalità in fase di sviluppo)
- Rendering in una sezione della texture 3D
- Aggiornamenti di Dawn
Chrome 124
- Texture di archiviazione di sola lettura e lettura/scrittura
- Supporto di service worker e shared worker
- Nuovi attributi delle informazioni sull'adattatore
- Correzioni di bug
- Aggiornamenti di Dawn
Chrome 123
- Supporto delle funzioni integrate DP4a in WGSL
- Parametri del puntatore senza limitazioni in WGSL
- Zucchero sintattico per la dereferenziazione dei compositi in WGSL
- Stato di sola lettura separato per gli aspetti stencil e profondità
- Aggiornamenti di Dawn
Chrome 122
- Ampliare la copertura con la modalità di compatibilità (funzionalità in fase di sviluppo)
- Aumentare il limite maxVertexAttributes
- Aggiornamenti di Dawn
Chrome 121
- Supporto di WebGPU su Android
- Utilizzare DXC anziché FXC per la compilazione degli shader su Windows
- Query con timestamp nei passaggi di calcolo e rendering
- Punti di ingresso predefiniti per i moduli shader
- Supporto di display-p3 come spazio colore GPUExternalTexture
- Informazioni sugli heap di memoria
- Aggiornamenti di Dawn
Chrome 120
- Supporto per valori in virgola mobile a 16 bit in WGSL
- Superare i limiti
- Modifiche allo stato di profondità-stencil
- Aggiornamenti delle informazioni sull'adattatore
- Quantizzazione delle query con timestamp
- Funzionalità per le pulizie di primavera
Chrome 119
- Texture a virgola mobile a 32 bit filtrabili
- Formato dei vertici unorm10-10-10-2
- Formato della texture rgb10a2uint
- Aggiornamenti di Dawn
Chrome 118
- Supporto di HTMLImageElement e ImageData in
copyExternalImageToTexture() - Supporto sperimentale per la texture di archiviazione in lettura/scrittura e sola lettura
- Aggiornamenti di Dawn
Chrome 117
- Annulla buffer dei vertici
- Annulla impostazione gruppo di binding
- Silenzia gli errori durante la creazione della pipeline asincrona quando il dispositivo viene smarrito
- Aggiornamenti alla creazione di moduli shader SPIR-V
- Miglioramento dell'esperienza degli sviluppatori
- Pipeline di memorizzazione nella cache con layout generato automaticamente
- Aggiornamenti di Dawn
Chrome 116
- Integrazione di WebCodecs
- Dispositivo smarrito restituito da GPUAdapter
requestDevice() - Mantenere la riproduzione video fluida se viene chiamato
importExternalTexture() - Conformità alle specifiche
- Miglioramento dell'esperienza degli sviluppatori
- Aggiornamenti di Dawn
Chrome 115
- Estensioni del linguaggio WGSL supportate
- Supporto sperimentale per Direct3D 11
- Utilizzare la GPU discreta per impostazione predefinita con l'alimentazione CA
- Miglioramento dell'esperienza degli sviluppatori
- Aggiornamenti di Dawn
Chrome 114
- Ottimizzare JavaScript
- getCurrentTexture() su canvas non configurato genera InvalidStateError
- Aggiornamenti di WGSL
- Aggiornamenti di Dawn