
Tìm hiểu cách các tính năng nâng cao WebAssembly và WebGPU cải thiện hiệu suất của công nghệ học máy trên web.



Suy luận AI trên web
Chúng ta đều đã nghe câu chuyện: AI đang thay đổi thế giới của chúng ta. Web cũng không phải là ngoại lệ.
Năm nay, Chrome đã bổ sung các tính năng AI tạo sinh, bao gồm cả tính năng tạo giao diện tuỳ chỉnh và giúp bạn viết bản thảo văn bản đầu tiên. Nhưng AI còn làm được nhiều việc hơn thế; AI có thể tự làm phong phú các ứng dụng web.
Các trang web có thể nhúng các thành phần thông minh để xử lý thị giác, chẳng hạn như chọn khuôn mặt hoặc nhận dạng cử chỉ, để phân loại âm thanh hoặc để phát hiện ngôn ngữ. Trong năm qua, chúng ta đã thấy AI tạo sinh phát triển mạnh mẽ, bao gồm cả một số bản minh hoạ thực sự ấn tượng về các mô hình ngôn ngữ lớn trên web. Hãy nhớ xem bài viết AI thực tế trên thiết bị dành cho nhà phát triển web.
Ngày nay, tính năng suy luận AI trên web đã có trên nhiều thiết bị và quá trình xử lý AI có thể diễn ra ngay trong trang web, tận dụng phần cứng trên thiết bị của người dùng.
Điều này rất hữu ích vì một số lý do:
- Giảm chi phí: Việc chạy quy trình suy luận trên ứng dụng trình duyệt giúp giảm đáng kể chi phí máy chủ. Điều này có thể đặc biệt hữu ích đối với các truy vấn GenAI, có thể tốn kém hơn nhiều so với các truy vấn thông thường.
- Độ trễ: Đối với các ứng dụng đặc biệt nhạy cảm với độ trễ, chẳng hạn như ứng dụng âm thanh hoặc video, việc tất cả quá trình xử lý diễn ra trên thiết bị sẽ giúp giảm độ trễ.
- Quyền riêng tư: Việc chạy ở phía máy khách cũng có thể mở ra một lớp ứng dụng mới yêu cầu tăng quyền riêng tư, trong đó dữ liệu không thể được gửi đến máy chủ.
Cách hoạt động của khối lượng công việc AI trên web hiện nay
Ngày nay, các nhà phát triển ứng dụng và nhà nghiên cứu xây dựng mô hình bằng các khung, mô hình thực thi trong trình duyệt bằng cách sử dụng môi trường thời gian chạy như Tensorflow.js hoặc ONNX Runtime Web, và môi trường thời gian chạy sử dụng API Web để thực thi.
Tất cả các môi trường thời gian chạy đó cuối cùng đều chạy trên CPU thông qua JavaScript hoặc WebAssembly hoặc trên GPU thông qua WebGL hoặc WebGPU.
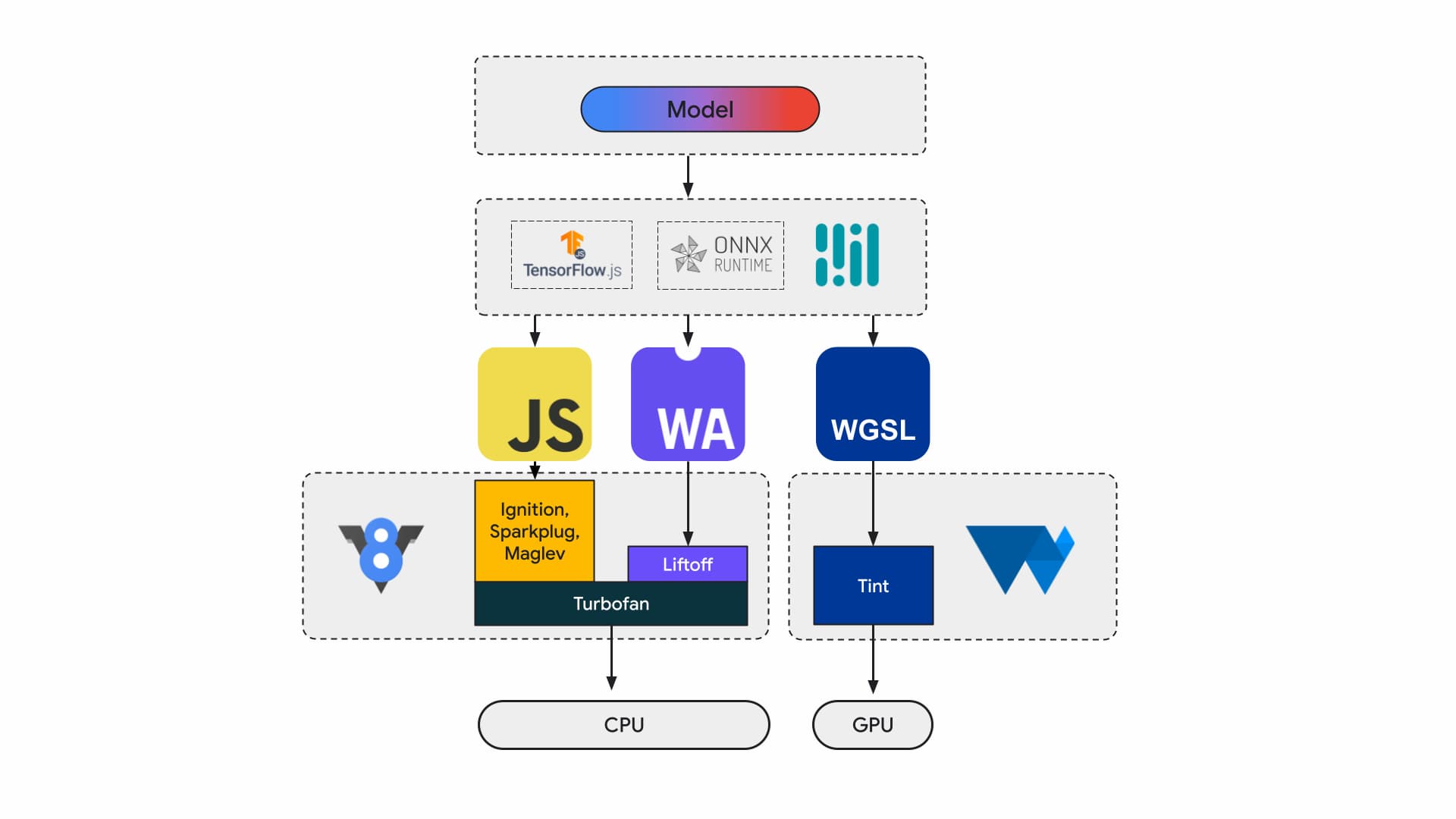
Khối lượng công việc học máy
Khối lượng công việc học máy (ML) đẩy tensor thông qua biểu đồ các nút điện toán. Tensor là dữ liệu đầu vào và đầu ra của các nút này, thực hiện một lượng lớn phép tính trên dữ liệu.
Điều này rất quan trọng vì:
- Tensor là các cấu trúc dữ liệu rất lớn, thực hiện phép tính trên các mô hình có thể có hàng tỷ trọng số
- Việc mở rộng quy mô và suy luận có thể dẫn đến song song dữ liệu. Điều này có nghĩa là các phép toán tương tự được thực hiện trên tất cả các phần tử trong tensor.
- Học máy không yêu cầu độ chính xác. Bạn có thể cần số có dấu phẩy động 64 bit để hạ cánh trên mặt trăng, nhưng có thể chỉ cần một biển số 8 bit trở xuống để nhận dạng khuôn mặt.
May mắn thay, các nhà thiết kế chip đã thêm các tính năng để giúp các mô hình chạy nhanh hơn, mát hơn và thậm chí có thể chạy được.
Trong khi đó, các nhóm WebAssembly và WebGPU đang nỗ lực để giới thiệu những tính năng mới đó cho các nhà phát triển web. Nếu là nhà phát triển ứng dụng web, bạn không có nhiều khả năng thường xuyên sử dụng các loại dữ liệu gốc cấp thấp này. Chúng tôi dự kiến các chuỗi công cụ hoặc khung mà bạn đang sử dụng sẽ hỗ trợ các tính năng và tiện ích mới, nhờ đó, bạn có thể hưởng lợi mà không cần thay đổi nhiều cơ sở hạ tầng. Tuy nhiên, nếu bạn muốn điều chỉnh ứng dụng theo cách thủ công để cải thiện hiệu suất, thì các tính năng này sẽ phù hợp với công việc của bạn.
WebAssembly
WebAssembly (Wasm) là một định dạng mã byte nhỏ gọn, hiệu quả mà thời gian chạy có thể hiểu và thực thi. Công cụ này được thiết kế để tận dụng các chức năng phần cứng cơ bản, nhờ đó có thể thực thi ở tốc độ gần như tốc độ gốc. Mã được xác thực và thực thi trong môi trường hộp cát an toàn về bộ nhớ.
Thông tin mô-đun Wasm được biểu thị bằng mã hoá nhị phân dày đặc. So với định dạng dựa trên văn bản, điều đó có nghĩa là giải mã nhanh hơn, tải nhanh hơn, giảm mức sử dụng bộ nhớ. Kiến trúc này có thể di chuyển được theo nghĩa là không đưa ra giả định về cấu trúc cơ bản không phổ biến với các cấu trúc hiện đại.
Thông số kỹ thuật WebAssembly là lặp lại và được xử lý trong một nhóm cộng đồng W3C mở.
Định dạng tệp nhị phân không đưa ra giả định nào về môi trường lưu trữ, vì vậy, định dạng này cũng được thiết kế để hoạt động tốt trong các trường hợp nhúng không phải web.
Bạn có thể biên dịch ứng dụng một lần và chạy ở mọi nơi: máy tính để bàn, máy tính xách tay, điện thoại hoặc bất kỳ thiết bị nào khác có trình duyệt. Hãy xem bài viết Viết một lần, chạy ở mọi nơi cuối cùng đã được hiện thực hoá bằng WebAssembly để tìm hiểu thêm về vấn đề này.
Hầu hết các ứng dụng sản xuất chạy suy luận AI trên web đều sử dụng WebAssembly, cả để tính toán CPU và giao tiếp với tính toán cho mục đích đặc biệt. Trên các ứng dụng gốc, bạn có thể truy cập vào cả tính năng điện toán cho mục đích chung và mục đích đặc biệt, vì ứng dụng có thể truy cập vào các chức năng của thiết bị.
Trên web, để đảm bảo tính di động và bảo mật, chúng tôi đánh giá cẩn thận tập hợp các đối tượng gốc được hiển thị. Điều này giúp cân bằng khả năng hỗ trợ tiếp cận của web với hiệu suất tối đa do phần cứng cung cấp.
WebAssembly là một bản tóm tắt di động của CPU, vì vậy, tất cả các suy luận Wasm đều chạy trên CPU. Mặc dù đây không phải là lựa chọn hiệu quả nhất, nhưng CPU có sẵn và hoạt động trên hầu hết các khối lượng công việc, trên hầu hết các thiết bị.
Đối với các khối lượng công việc nhỏ hơn, chẳng hạn như khối lượng công việc văn bản hoặc âm thanh, GPU sẽ tốn kém. Có một số ví dụ gần đây cho thấy Wasm là lựa chọn phù hợp:
- Adobe sử dụng Tensorflow.js để nâng cao Photoshop cho web.
- Google Meet đã thêm tính năng làm mờ nền, một trong những hiệu ứng video đầu tiên dựa trên Wasm trên web.
- YouTube có một số hiệu ứng thực tế tăng cường.
- Google Photos cho phép chỉnh sửa trực tuyến.
Bạn có thể khám phá thêm trong các bản minh hoạ nguồn mở, chẳng hạn như: whisper-tiny, llama.cpp và Gemma2B chạy trong trình duyệt.
Áp dụng phương pháp toàn diện cho ứng dụng
Bạn nên chọn các loại dữ liệu gốc dựa trên mô hình học máy cụ thể, cơ sở hạ tầng ứng dụng và trải nghiệm ứng dụng tổng thể mà bạn muốn mang đến cho người dùng
Ví dụ: trong tính năng phát hiện điểm đặc trưng trên khuôn mặt của MediaPipe, suy luận CPU và suy luận GPU có thể so sánh được (chạy trên thiết bị Apple M1), nhưng có những mô hình mà độ biến thiên có thể cao hơn đáng kể.
Đối với khối lượng công việc về học máy, chúng tôi xem xét chế độ xem ứng dụng toàn diện, đồng thời lắng nghe các tác giả khung và đối tác ứng dụng để phát triển và phân phối các tính năng nâng cao được yêu cầu nhiều nhất. Các loại dữ liệu này được chia thành ba loại chính:
- Hiển thị các tiện ích CPU quan trọng đối với hiệu suất
- Cho phép chạy các mô hình lớn hơn
- Cho phép tương tác liền mạch với các API Web khác
Điện toán nhanh hơn
Hiện tại, thông số kỹ thuật WebAssembly chỉ bao gồm một bộ hướng dẫn nhất định mà chúng tôi hiển thị cho web. Tuy nhiên, phần cứng tiếp tục thêm các hướng dẫn mới hơn làm tăng khoảng cách giữa hiệu suất gốc và WebAssembly.
Hãy nhớ rằng các mô hình học máy không phải lúc nào cũng yêu cầu độ chính xác cao. SIMD thư giãn là một đề xuất giúp giảm một số yêu cầu nghiêm ngặt, không xác định, dẫn đến việc tạo mã nhanh hơn cho một số thao tác vectơ là điểm nóng về hiệu suất. Ngoài ra, Relaxed SIMD còn giới thiệu các lệnh FMA và tích vô hướng mới giúp tăng tốc khối lượng công việc hiện tại từ 1,5 đến 3 lần. Tính năng này đã được phát hành trong Chrome 114.
Định dạng dấu phẩy động có độ bán chính xác sử dụng 16 bit cho IEEE FP16 thay vì 32 bit dùng cho các giá trị có độ chính xác đơn. So với các giá trị có độ chính xác đơn, việc sử dụng các giá trị có độ bán chính xác có một số ưu điểm như giảm yêu cầu về bộ nhớ, cho phép huấn luyện và triển khai các mạng nơron lớn hơn, giảm băng thông bộ nhớ. Việc giảm độ chính xác sẽ giúp tăng tốc độ truyền dữ liệu và các phép toán.
Mô hình lớn hơn
Con trỏ vào bộ nhớ tuyến tính Wasm được biểu thị dưới dạng số nguyên 32 bit. Điều này dẫn đến hai hệ quả: kích thước vùng nhớ khối xếp bị giới hạn ở mức 4 GB (khi máy tính có nhiều RAM vật lý hơn thế) và mã ứng dụng nhắm đến Wasm phải tương thích với kích thước con trỏ 32 bit (kích thước nào).
Đặc biệt là với các mô hình lớn như hiện nay, việc tải các mô hình này vào WebAssembly có thể bị hạn chế. Đề xuất Memory64 loại bỏ các hạn chế này bằng bộ nhớ tuyến tính lớn hơn 4GB và phù hợp với không gian địa chỉ của các nền tảng gốc.
Chúng tôi đã triển khai đầy đủ tính năng này trong Chrome và dự kiến sẽ ra mắt vào cuối năm nay. Hiện tại, bạn có thể chạy thử nghiệm bằng cờ chrome://flags/#enable-experimental-webassembly-features và gửi ý kiến phản hồi cho chúng tôi.
Khả năng tương tác tốt hơn trên web
WebAssembly có thể là điểm truy cập cho tính năng điện toán cho mục đích đặc biệt trên web.
Bạn có thể sử dụng WebAssembly để đưa các ứng dụng GPU lên web. Điều đó có nghĩa là cùng một ứng dụng C++ có thể chạy trên thiết bị cũng có thể chạy trên web, với một số sửa đổi nhỏ.
Emscripten, chuỗi công cụ trình biên dịch Wasm, đã có các liên kết cho WebGPU. Đây là điểm truy cập để suy luận AI trên web, vì vậy, điều quan trọng là Wasm có thể tương tác liền mạch với phần còn lại của nền tảng web. Chúng tôi đang nỗ lực để đưa ra một số đề xuất trong lĩnh vực này.
Tích hợp lời hứa JavaScript (JSPI)
Các ứng dụng C và C++ thông thường (cũng như nhiều ngôn ngữ khác) thường được viết dựa trên API đồng bộ. Điều này có nghĩa là ứng dụng sẽ ngừng thực thi cho đến khi thao tác hoàn tất. Các ứng dụng chặn như vậy thường dễ viết hơn so với các ứng dụng nhận biết được chế độ không đồng bộ.
Khi các thao tác tốn kém chặn luồng chính, chúng có thể chặn I/O và người dùng sẽ thấy hiện tượng giật. Mô hình lập trình đồng bộ của ứng dụng gốc không khớp với mô hình không đồng bộ của web. Điều này đặc biệt gây phiền toái cho các ứng dụng cũ, vì sẽ tốn kém chi phí để chuyển đổi. Emscripten cung cấp một cách để thực hiện việc này bằng Asyncify, nhưng đây không phải lúc nào cũng là lựa chọn tốt nhất – kích thước mã lớn hơn và không hiệu quả bằng.
Ví dụ sau đây là tính toán fibonacci, sử dụng lời hứa JavaScript để cộng.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
Trong ví dụ này, hãy chú ý đến những điều sau:
- Macro
EM_ASYNC_JStạo ra tất cả mã keo cần thiết để chúng ta có thể sử dụng JSPI truy cập vào kết quả của promise, giống như đối với một hàm thông thường. - Tuỳ chọn dòng lệnh đặc biệt,
-s ASYNCIFY=2. Thao tác này sẽ gọi tuỳ chọn tạo mã sử dụng JSPI để giao tiếp với các lệnh nhập JavaScript trả về lời hứa.
Để biết thêm về JSPI, cách sử dụng và lợi ích của JSPI, hãy đọc bài viết Giới thiệu API tích hợp WebAssembly JavaScript Promise trên v8.dev. Tìm hiểu về bản dùng thử theo nguyên gốc hiện tại.
Điều khiển bộ nhớ
Nhà phát triển có rất ít quyền kiểm soát đối với bộ nhớ Wasm; mô-đun này sở hữu bộ nhớ riêng. Mọi API cần truy cập vào bộ nhớ này đều phải sao chép vào hoặc sao chép ra, và mức sử dụng này thực sự có thể tăng lên. Ví dụ: một ứng dụng đồ hoạ có thể cần sao chép vào và sao chép ra cho mỗi khung hình.
Đề xuất Kiểm soát bộ nhớ nhằm cung cấp khả năng kiểm soát chi tiết hơn đối với bộ nhớ tuyến tính Wasm và giảm số lượng bản sao trên quy trình ứng dụng. Đề xuất này đang ở Giai đoạn 1, chúng tôi đang tạo bản minh hoạ trong V8, công cụ JavaScript của Chrome, để thông báo về quá trình phát triển của tiêu chuẩn này.
Quyết định phần phụ trợ phù hợp với bạn
Mặc dù CPU có mặt ở khắp mọi nơi, nhưng không phải lúc nào CPU cũng là lựa chọn tốt nhất. Tính năng điện toán cho mục đích đặc biệt trên GPU hoặc bộ tăng tốc có thể mang lại hiệu suất cao hơn nhiều lần, đặc biệt là đối với các mẫu lớn hơn và trên các thiết bị cao cấp. Điều này đúng cho cả ứng dụng gốc và ứng dụng web.
Bạn chọn phần phụ trợ nào tuỳ thuộc vào ứng dụng, khung hoặc chuỗi công cụ, cũng như các yếu tố khác ảnh hưởng đến hiệu suất. Tuy nhiên, chúng tôi vẫn tiếp tục đầu tư vào các đề xuất giúp Wasm cốt lõi hoạt động hiệu quả với phần còn lại của nền tảng web, cụ thể là với WebGPU.