

دادههای خام گزارش Chrome UX ( CrUX ) در BigQuery ، یک پایگاه داده در Google Cloud در دسترس است. استفاده از BigQuery به یک پروژه GCP و دانش اولیه SQL نیاز دارد.
در این راهنما، نحوه استفاده از BigQuery را برای نوشتن پرسوجوها در برابر مجموعه دادههای CrUX برای استخراج نتایج واضح در مورد وضعیت تجربیات کاربر در وب بیاموزید:
- درک نحوه سازماندهی داده ها
- برای ارزیابی عملکرد یک منبع، یک پرسش اساسی بنویسید
- یک پرسش پیشرفته بنویسید تا عملکرد را در طول زمان پیگیری کنید
سازماندهی داده ها
با نگاه کردن به یک پرس و جو اولیه شروع کنید:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
برای اجرای پرس و جو، آن را در ویرایشگر پرس و جو وارد کنید و دکمه "Run query" را فشار دهید:
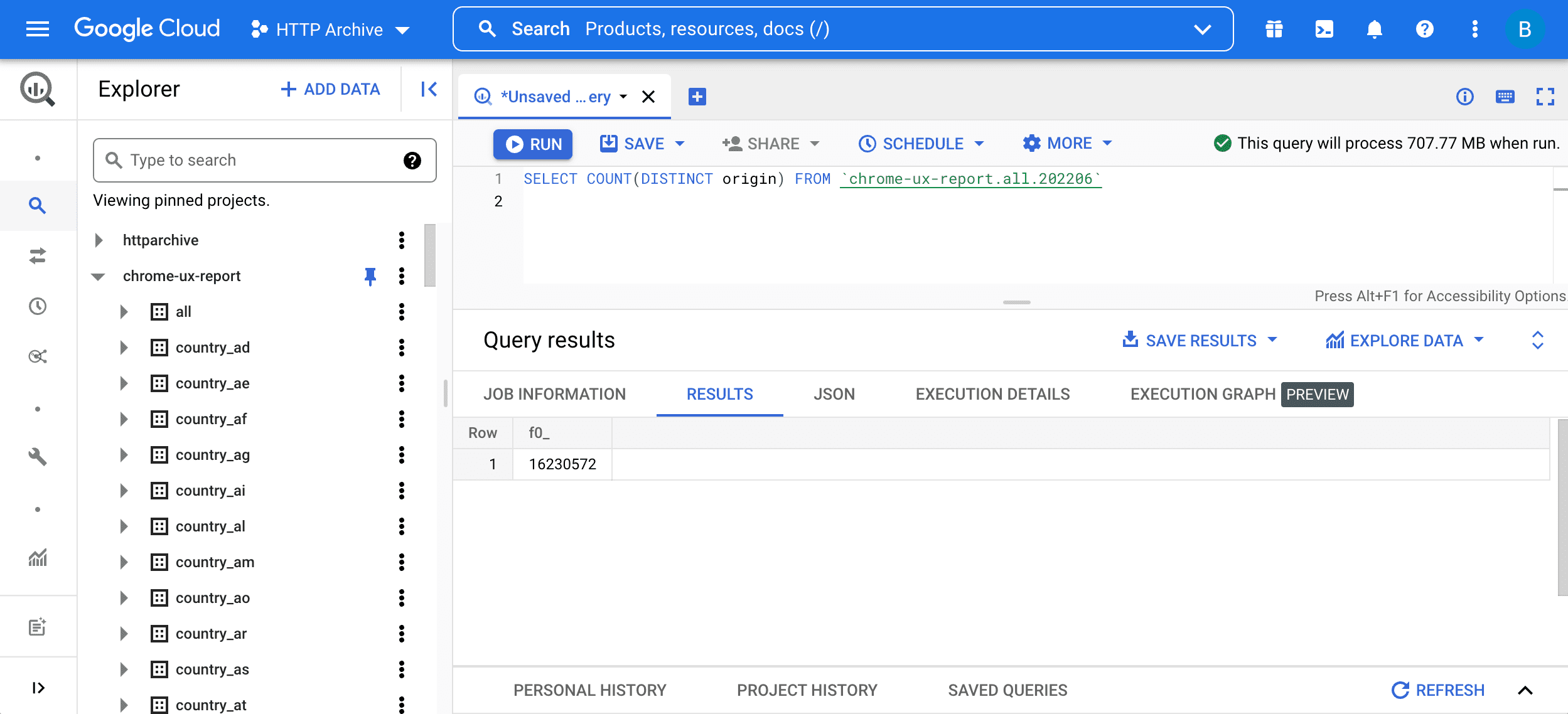
این پرس و جو دو بخش دارد:
SELECT COUNT(DISTINCT origin)به معنای پرس و جو برای تعداد مبداها در جدول است. به طور کلی، اگر طرح، میزبان و پورت یکسانی داشته باشند، دو URL بخشی از یک مبدا هستند.FROM chrome-ux-report.all.202206آدرس جدول منبع را مشخص می کند که دارای سه قسمت است:- نام پروژه Cloud
chrome-ux-reportکه در آن تمام دادههای CrUX سازماندهی میشوند - مجموعه داده
all، نشان دهنده داده ها در همه کشورها است - جدول
202206، سال و ماه داده ها در قالب YYYYMM
- نام پروژه Cloud
همچنین مجموعه داده هایی برای هر کشور وجود دارد. به عنوان مثال، chrome-ux-report.country_ca.202206 فقط دادههای تجربه کاربر را نشان میدهد که از کانادا منشا میگیرد.
در هر مجموعه داده جداولی برای هر ماه از سال 201710 وجود دارد. جداول جدید برای ماه تقویم قبلی به طور منظم منتشر می شوند.
ساختار جداول داده (همچنین به عنوان طرحواره شناخته می شود) شامل:
- مبدا، برای مثال
origin = 'https://www.example.com'، که توزیع مجموع تجربه کاربر را برای همه صفحات در آن وب سایت نشان می دهد. - سرعت اتصال در زمان بارگیری صفحه، برای مثال
effective_connection_type.name = '4G'( از فوریه 2025 حذف شد ) - نوع دستگاه، برای مثال
form_factor.name = 'desktop' - خود معیارهای UX
داده های هر متریک به صورت آرایه ای از اشیاء سازماندهی می شوند. در نماد JSON، first_contentful_paint.histogram.bin شبیه به این است:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
هر سطل حاوی یک زمان شروع و پایان بر حسب میلی ثانیه و چگالی است که نشان دهنده درصد تجربیات کاربر در آن محدوده زمانی است. به عبارت دیگر، 12.34 درصد از تجربیات FCP برای این مبدا فرضی، سرعت اتصال و نوع دستگاه کمتر از 100 میلیثانیه است. مجموع تمام تراکم های بن 100٪ است.
ساختار جداول را در BigQuery مرور کنید.
عملکرد را ارزیابی کنید
ما میتوانیم از دانش خود در مورد طرح جدول برای نوشتن پرسشی استفاده کنیم که این دادههای عملکرد را استخراج میکند.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
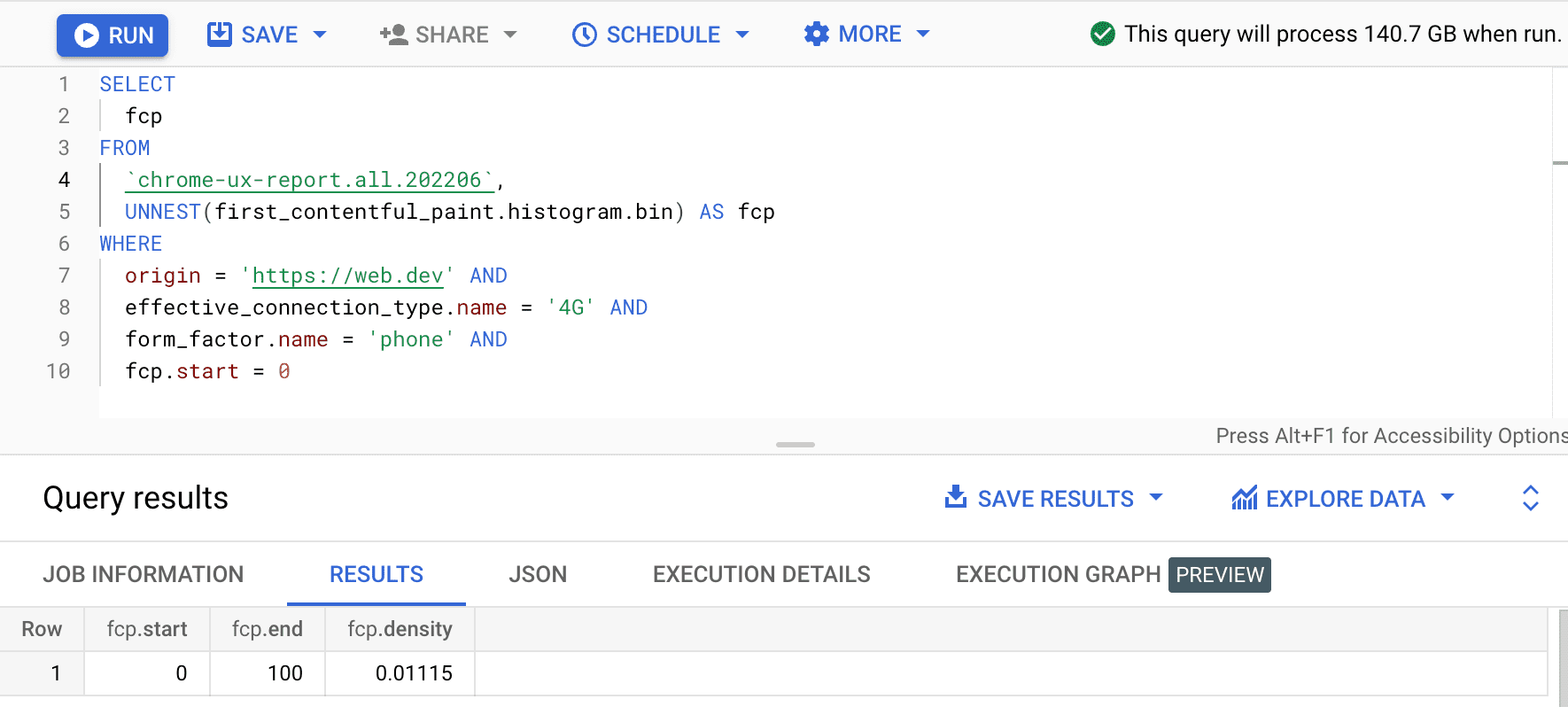
نتیجه 0.01115 است، به این معنی که 1.115٪ از تجربیات کاربر در این مبدا بین 0 تا 100 میلیثانیه در 4G و روی تلفن همراه است. اگر بخواهیم پرس و جوی خود را به هر اتصال و هر نوع دستگاهی تعمیم دهیم، میتوانیم آنها را از عبارت WHERE حذف کنیم و از تابع جمعآوری SUM برای جمعکردن تمام تراکمهای bin مربوطه آنها استفاده کنیم:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
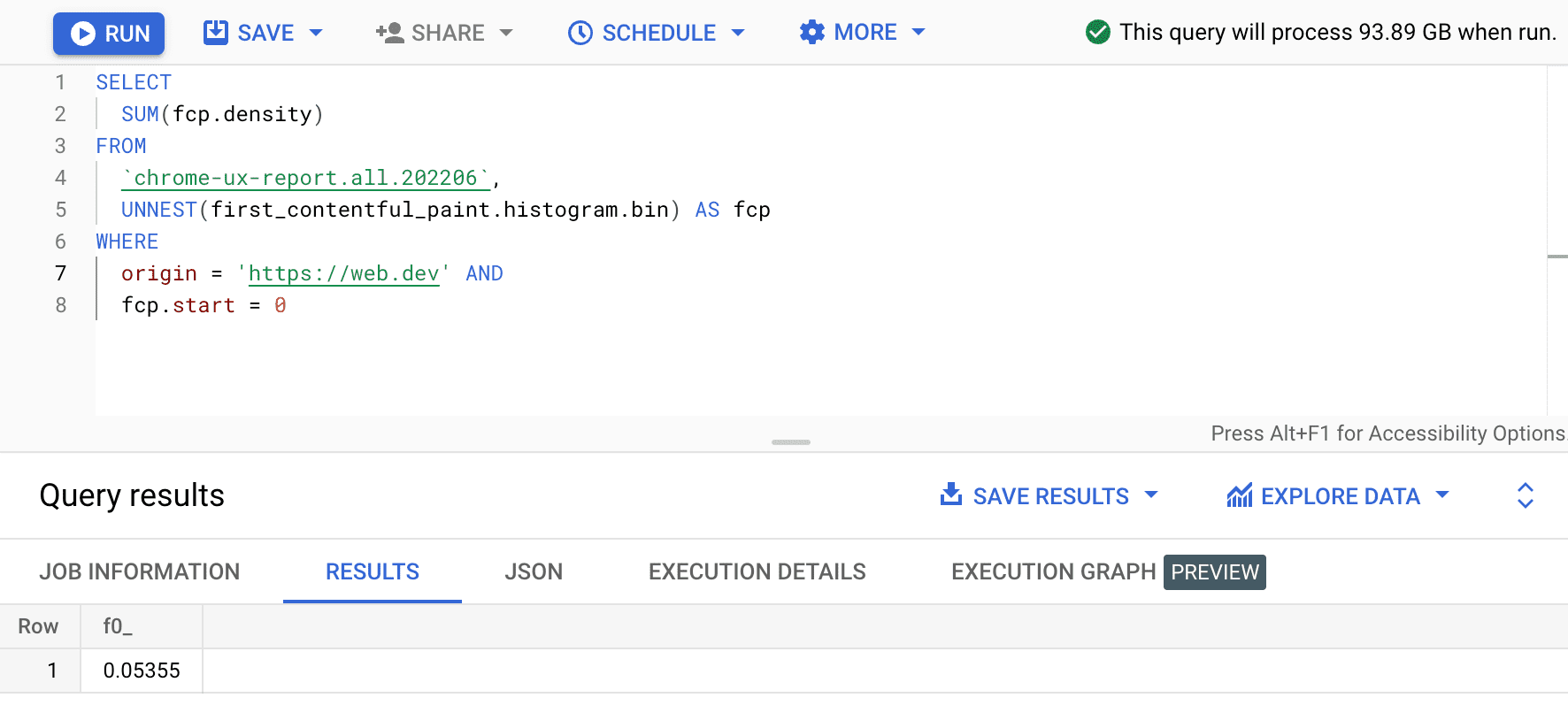
نتیجه 0.05355 یا 5.355٪ در همه دستگاه ها و انواع اتصال است. ما میتوانیم پرس و جو را کمی تغییر دهیم و تراکمها را برای همه binهایی که در محدوده FCP "سریع" 0-1000 میلیثانیه هستند، اضافه کنیم:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
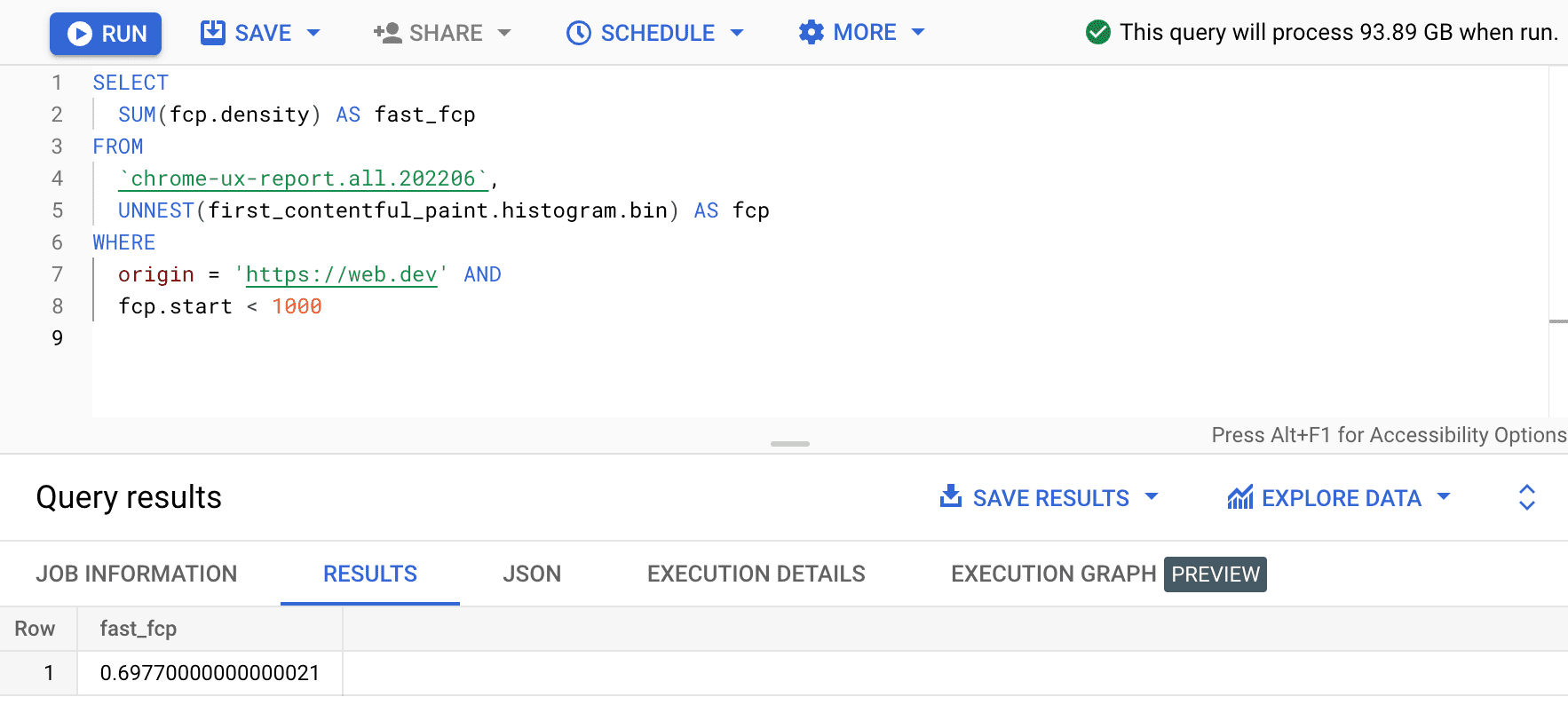
این به ما 0.6977 می دهد. به عبارت دیگر، 69.77٪ از تجربیات کاربر FCP در web.dev طبق تعریف محدوده FCP "سریع" در نظر گرفته می شود.
عملکرد را پیگیری کنید
اکنون که دادههای عملکرد مربوط به یک مبدا را استخراج کردهایم، میتوانیم آن را با دادههای تاریخی موجود در جداول قدیمیتر مقایسه کنیم. برای انجام این کار، میتوانیم آدرس جدول را به یک ماه قبل بازنویسی کنیم، یا میتوانیم از دستور عام برای پرسجویی در تمام ماهها استفاده کنیم:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
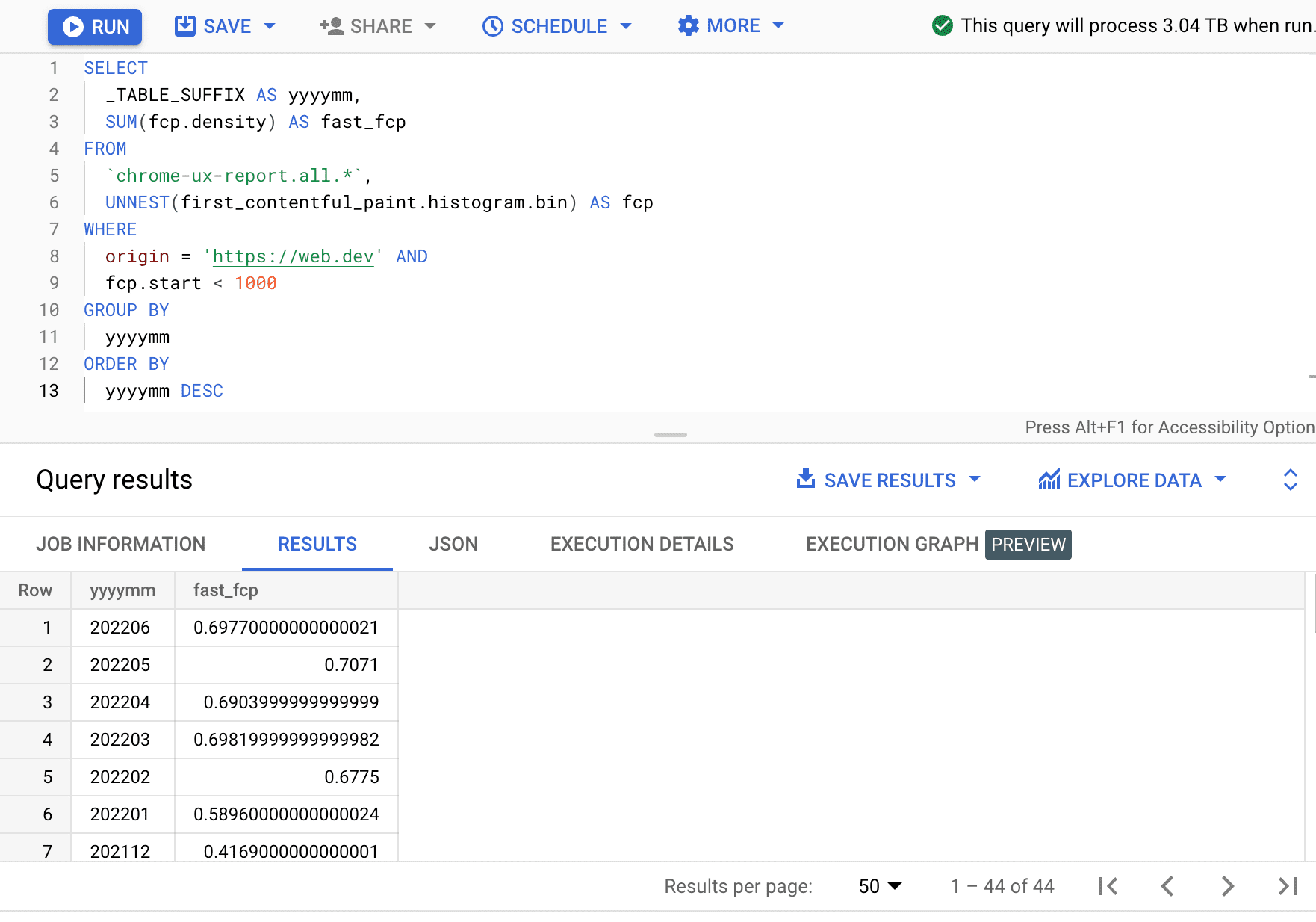
در اینجا، می بینیم که درصد تجارب سریع FCP هر ماه چند درصد متفاوت است.
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77٪ |
| 202205 | 70.71% |
| 202204 | 69.04٪ |
| 202203 | 69.82٪ |
| 202202 | 67.75٪ |
| 202201 | 58.96٪ |
| 202112 | 41.69٪ |
| ... | ... |
با این تکنیکها، میتوانید عملکرد را برای یک منبع جستجو کنید، درصد تجربیات سریع را محاسبه کنید و آن را در طول زمان پیگیری کنید. به عنوان گام بعدی، سعی کنید دو یا چند منبع را پرس و جو کنید و عملکرد آنها را با هم مقایسه کنید.
سوالات متداول
اینها برخی از سوالات متداول در مورد مجموعه داده CrUX BigQuery هستند:
چه زمانی از BigQuery بر خلاف ابزارهای دیگر استفاده کنم؟
BigQuery تنها زمانی مورد نیاز است که نتوانید همان اطلاعات را از ابزارهای دیگری مانند داشبورد CrUX و PageSpeed Insights دریافت کنید. برای مثال، BigQuery به شما امکان میدهد دادهها را به روشهای معنیداری برش دهید و حتی آنها را با سایر مجموعههای داده عمومی مانند بایگانی HTTP بپیوندید تا دادهکاوی پیشرفته انجام دهید.
آیا محدودیتی برای استفاده از BigQuery وجود دارد؟
بله، مهمترین محدودیت این است که کاربران بهطور پیشفرض میتوانند فقط 1 ترابایت داده در ماه را پرس و جو کنند. فراتر از آن، نرخ استاندارد 5 دلار / ترابایت اعمال می شود.
از کجا می توانم درباره BigQuery بیشتر بیاموزم؟
برای اطلاعات بیشتر، مستندات BigQuery را بررسی کنید.