

Chrome Kullanıcı Deneyimi Raporu'nun (CrUX) ham verileri, Google Cloud'daki bir veritabanı olan BigQuery'de mevcuttur. BigQuery'yi kullanmak için bir GCP projesi ve SQL hakkında temel düzeyde bilgi sahibi olmanız gerekir.
Bu kılavuzda, web'deki kullanıcı deneyimlerinin durumuyla ilgili yararlı sonuçlar elde etmek için CrUX veri kümesine yönelik sorgular yazmak üzere BigQuery'yi nasıl kullanacağınızı öğrenin:
- Verilerin nasıl düzenlendiğini anlama
- Bir kaynağın performansını değerlendirmek için temel bir sorgu yazma
- Zaman içindeki performansı izlemek için gelişmiş bir sorgu yazma
Veri organizasyonu
Temel bir sorguya bakarak başlayın:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Sorguyu çalıştırmak için sorgu düzenleyiciye girin ve "Sorguyu çalıştır" düğmesine basın:
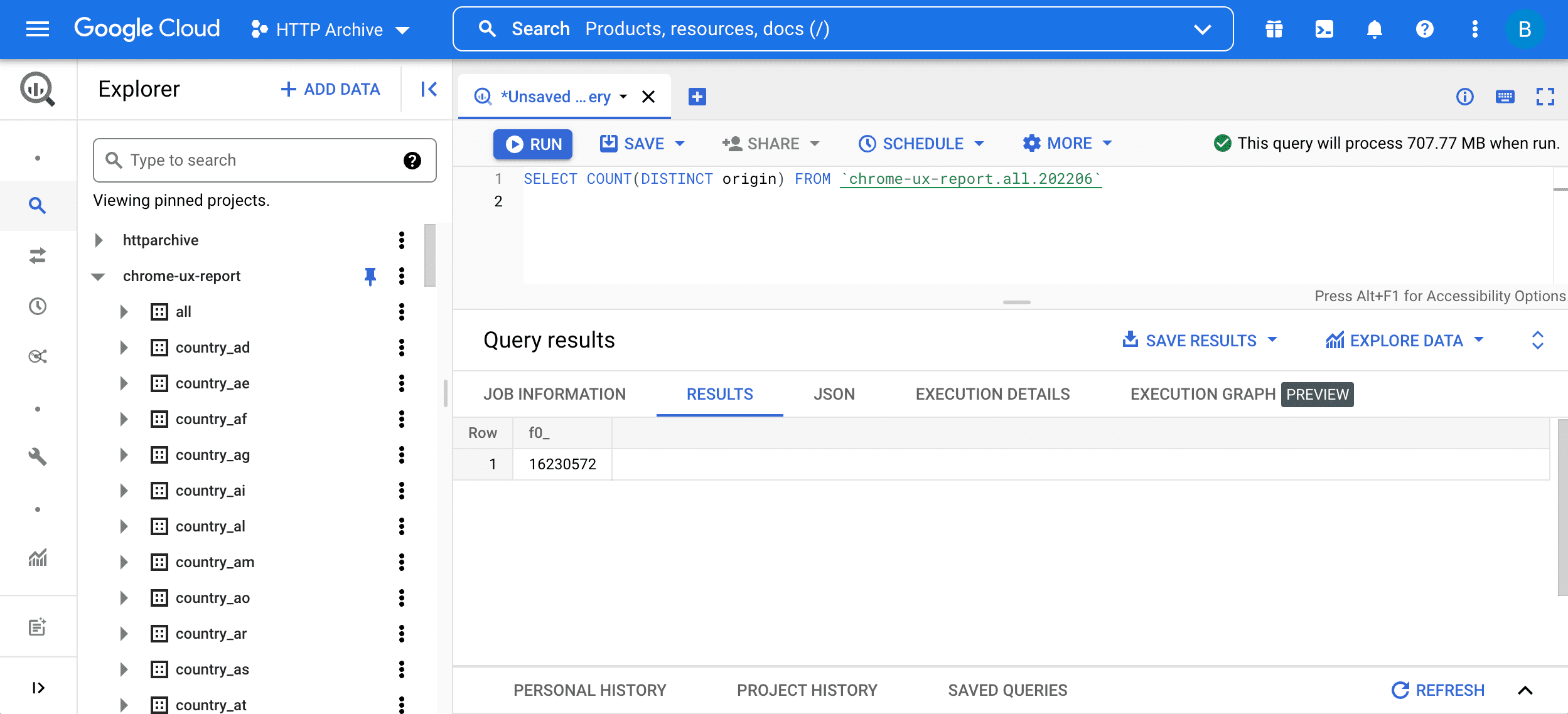
Bu sorgunun iki bölümü vardır:
SELECT COUNT(DISTINCT origin), tablodaki kaynak sayısını sorgulamak anlamına gelir. Kabaca söylemek gerekirse, aynı şemaya, ana makineye ve bağlantı noktasına sahip iki URL aynı kaynağın parçasıdır.FROM chrome-ux-report.all.202206, kaynak tablonun adresini belirtir. Bu adres üç bölümden oluşur:- Tüm CrUX verilerinin düzenlendiği Cloud projesinin adı
chrome-ux-report - Tüm ülkelerdeki verileri temsil eden
allveri kümesi 202206tablosu, verilerin yıl ve ayı YYYYMM biçiminde
- Tüm CrUX verilerinin düzenlendiği Cloud projesinin adı
Her ülke için veri kümeleri de vardır. Örneğin, chrome-ux-report.country_ca.202206 yalnızca Kanada'dan gelen kullanıcı deneyimi verilerini temsil eder.
Her veri kümesinde, 201710'dan bu yana her ay için tablolar bulunur. Önceki takvim ayına ait yeni tablolar düzenli olarak yayınlanır.
Veri tablolarının yapısı (şema olarak da bilinir) şunları içerir:
- Kaynak (ör.
origin = 'https://www.example.com'), ilgili web sitesindeki tüm sayfalar için birleştirilmiş kullanıcı deneyimi dağılımını temsil eder. - Sayfa yükleme sırasındaki bağlantı hızı (ör.
effective_connection_type.name = '4G') (Şubat 2025'ten itibaren kaldırıldı) - Cihaz türü (ör.
form_factor.name = 'desktop') - Kullanıcı deneyimi metrikleri
Her bir metriğe ait veriler bir nesne dizisi olarak düzenlenir. JSON gösterimindeki first_contentful_paint.histogram.bin şöyle görünür:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Her bin, milisaniye cinsinden bir başlangıç ve bitiş zamanı ve bu zaman aralığındaki kullanıcı deneyimlerinin yüzdesini temsil eden bir yoğunluk içerir. Diğer bir deyişle, bu varsayımsal kaynak, bağlantı hızı ve cihaz türü için FCP deneyimlerinin% 12, 34'ü 100 ms'den kısadır. Tüm kutu yoğunluklarının toplamı %100'dür.
BigQuery'deki tabloların yapısına göz atın.
Performans değerlendirme
Bu performans verilerini ayıklayan bir sorgu yazmak için tablo şemasıyla ilgili bilgilerimizi kullanabiliriz.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
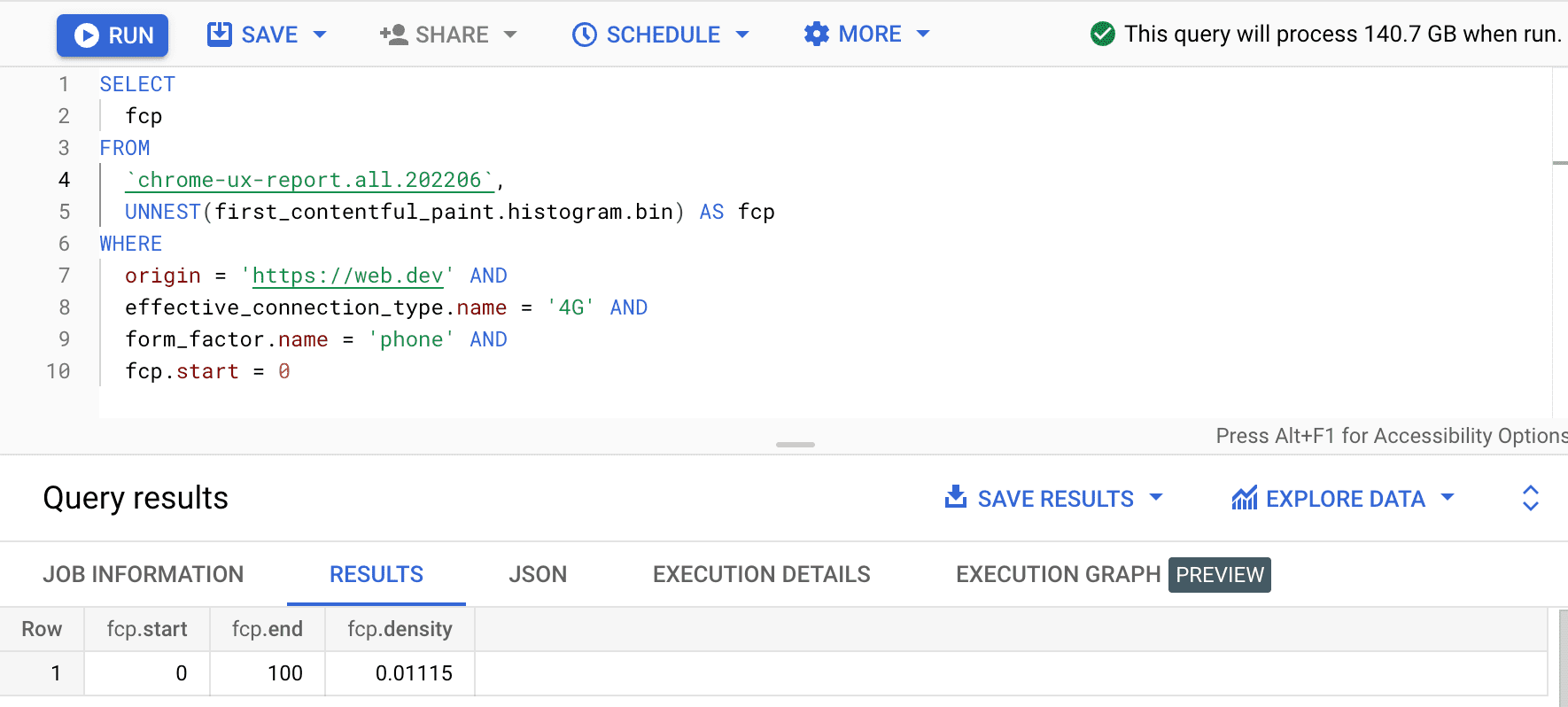
Sonuç 0.01115 olur.Bu da bu kaynaktaki kullanıcı deneyimlerinin% 1, 115'inin 4G'de ve telefonda 0 ila 100 ms arasında olduğu anlamına gelir. Sorgumuzu tüm bağlantılar ve cihaz türleri için genelleştirmek istersek bunları WHERE yan tümcesinden çıkarabilir ve ilgili tüm kutu yoğunluklarını toplamak için SUM toplayıcı işlevini kullanabiliriz:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
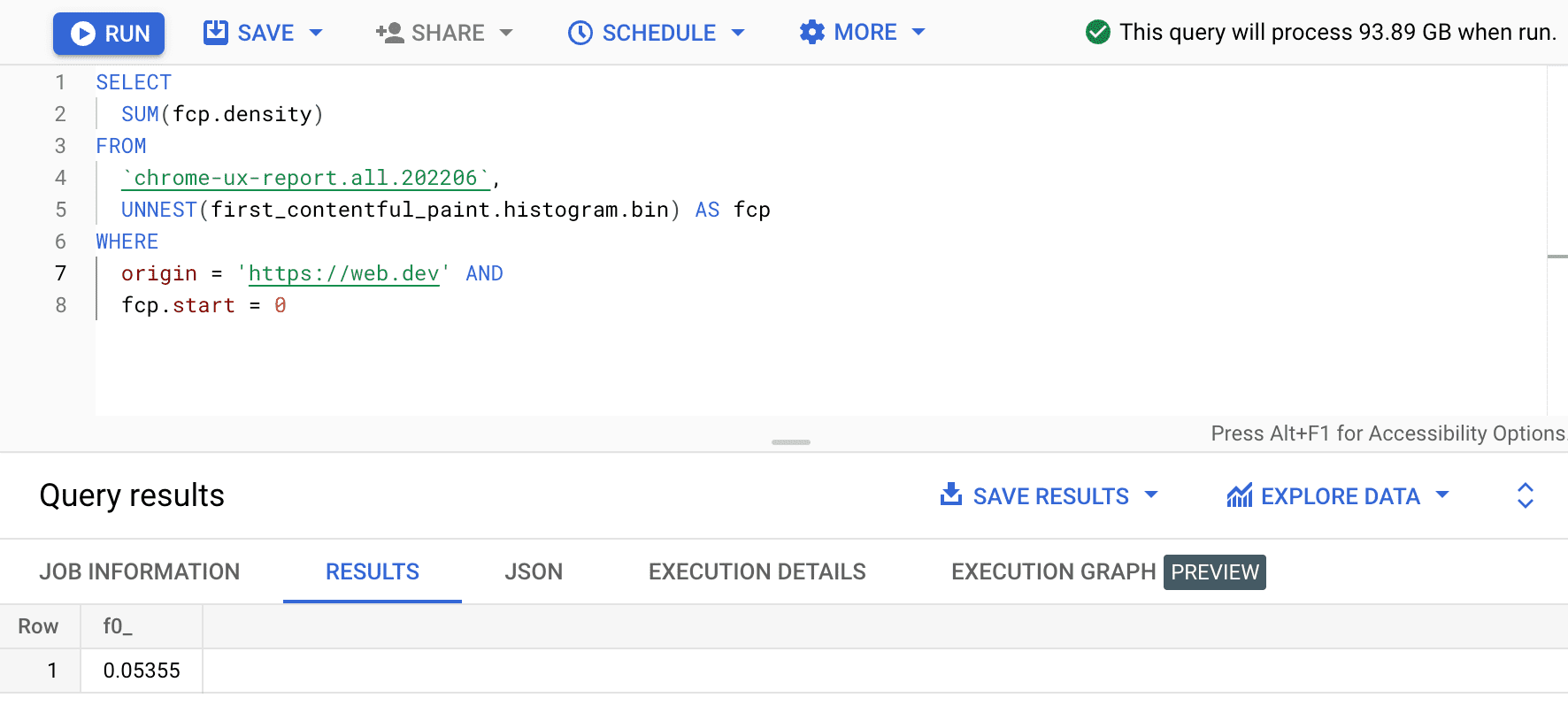
Sonuç 0.05355 veya tüm cihaz ve bağlantı türleri genelinde% 5, 355'tir. Sorguyu biraz değiştirebilir ve 0-1000 ms arasındaki "hızlı" FCP aralığındaki tüm kapların yoğunluklarını toplayabiliriz:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
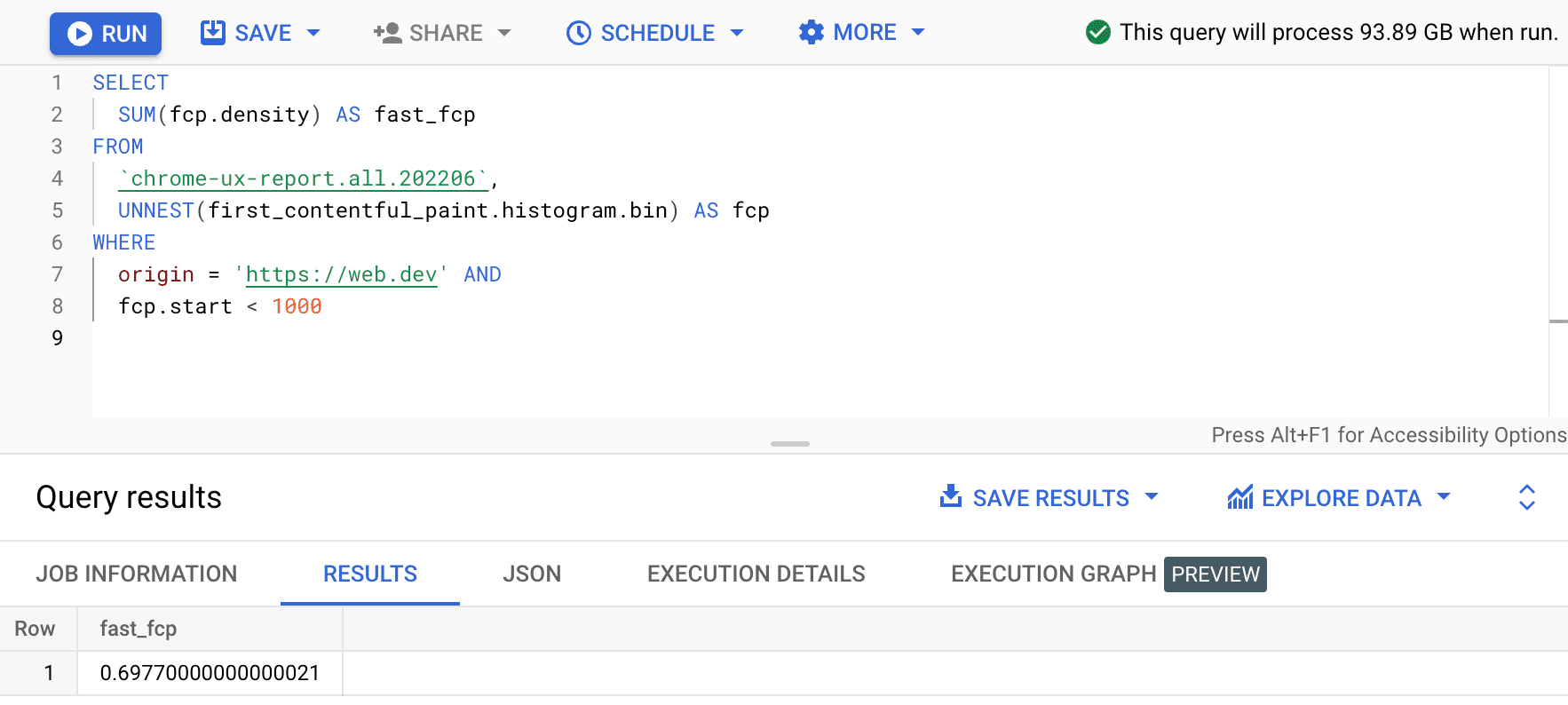
Bu işlemden sonra 0.6977 değerini elde ederiz. Diğer bir deyişle, web.dev'deki FCP kullanıcı deneyimlerinin% 69,77'si, FCP aralığı tanımına göre "hızlı" olarak kabul edilir.
Performansı izleme
Bir kaynakla ilgili performans verilerini ayıkladık. Artık bu verileri eski tablolardaki geçmiş verilerle karşılaştırabiliriz. Bunu yapmak için tablo adresini daha önceki bir aya göre yeniden yazabilir veya tüm ayları sorgulamak için joker karakter söz dizimini kullanabiliriz:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
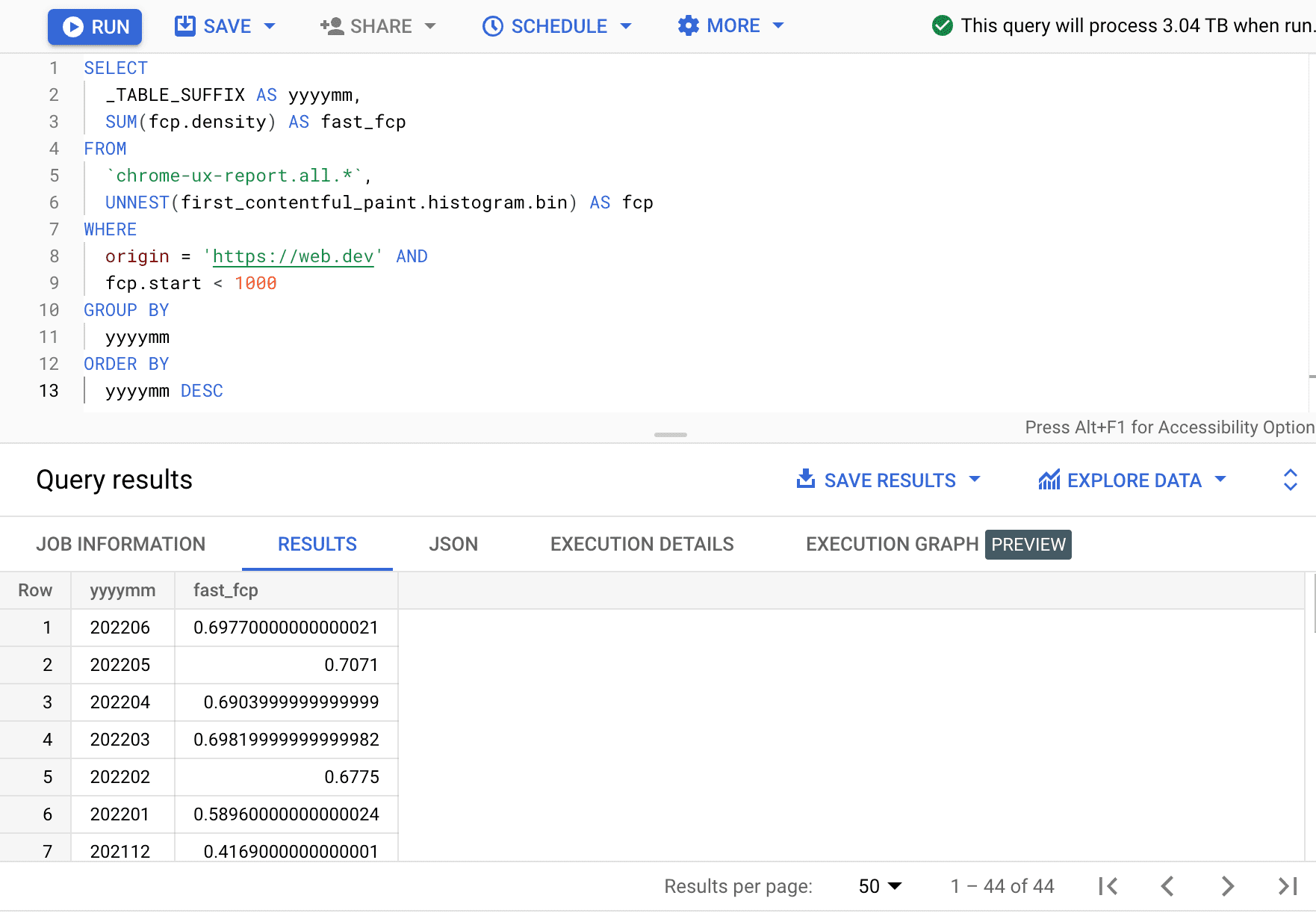
Burada, hızlı FCP deneyimlerinin yüzdesinin her ay birkaç yüzde puanı değiştiğini görüyoruz.
| yyyyaa | fast_fcp |
|---|---|
| 202206 | %69,77 |
| 202205 | %70,71 |
| 202204 | %69,04 |
| 202203 | %69,82 |
| 202202 | %67,75 |
| 202201 | %58,96 |
| 202112 | %41,69 |
| ... | ... |
Bu tekniklerle bir kaynağın performansını arayabilir, hızlı deneyimlerin yüzdesini hesaplayabilir ve zaman içinde izleyebilirsiniz. Bir sonraki adımda, iki veya daha fazla kaynak için sorgu oluşturmayı ve performanslarını karşılaştırmayı deneyin.
SSS
CrUX BigQuery veri kümesiyle ilgili sık sorulan sorulardan bazıları şunlardır:
Diğer araçlar yerine BigQuery'yi ne zaman kullanırım?
BigQuery yalnızca CrUX kontrol paneli ve PageSpeed Insights gibi diğer araçlardan aynı bilgileri alamadığınız durumlarda gereklidir. Örneğin, BigQuery, verileri anlamlı şekillerde dilimlemenize ve hatta bazı gelişmiş veri madenciliği işlemleri yapmak için HTTP Archive gibi diğer herkese açık veri kümeleriyle birleştirmenize olanak tanır.
BigQuery'nin kullanımıyla ilgili herhangi bir sınırlama var mı?
Evet, en önemli sınırlama, kullanıcıların varsayılan olarak aylık yalnızca 1 TB veri sorgulayabilmesidir. Bu kotanın üzerindeki kullanımlar için 1 TB başına 5 ABD doları olan standart ücret geçerlidir.
BigQuery hakkında daha fazla bilgiyi nereden edinebilirim?
Daha fazla bilgi için BigQuery belgelerine göz atın.