



公開日: 2024 年 5 月 16 日
肯定的なレビューと否定的なレビューは、購入者の購入決定に影響を与える可能性があります。
外部の調査によると、オンライン ショッピングを利用するユーザーの 82% が、購入前に否定的なレビューを積極的に探しています。低評価のレビューは、返品率の低下やメーカーによる製品の改善に役立つため、顧客と企業の両方にとって有益です。
レビューの質を高める方法はいくつかあります。
- レビューが送信される前に、各レビューの有害性をチェックします。ユーザーが他のユーザーの購入判断に役立つレビューを投稿できるよう、不適切な表現や役に立たないコメントを削除するよう促すことができます。
- 否定的: このバッグは最悪で、嫌いです。
- 有用なフィードバックを含む否定的なレビュー ジッパーが非常に硬く、素材が安っぽく感じます。このバッグを返品しました。
- レビューで使用されている言語に基づいて評価を自動生成します。
- クチコミが否定的か肯定的かを判断します。
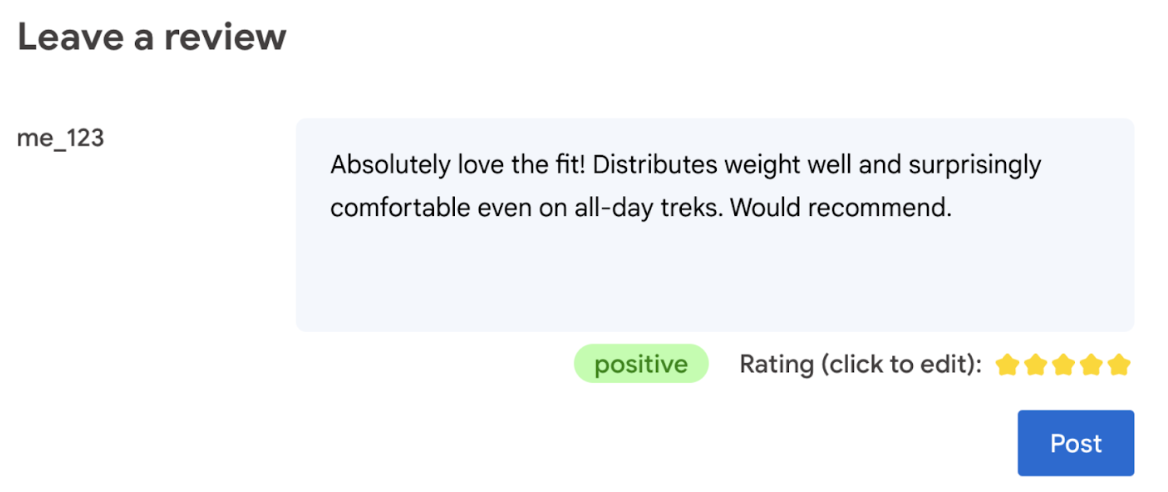
最終的に、ユーザーが商品評価を決定する必要があります。
次の Codelab では、クライアントサイドのソリューション(オンデバイスとブラウザ)を提供しています。AI 開発の知識、サーバー、API キーは必要ありません。
前提条件
Gemini API や OpenAI API などのソリューションを備えたサーバーサイド AI は、多くのアプリケーションに堅牢なソリューションを提供しますが、このガイドではクライアントサイドのウェブ AI に焦点を当てます。クライアントサイドの AI 推論はブラウザで行われるため、サーバーのラウンド トリップが不要になり、ウェブユーザーのエクスペリエンスが向上します。
この Codelab では、クライアントサイド AI のツールボックスにあるものを紹介するために、さまざまな手法を組み合わせて使用します。
次のライブラリとモデルを使用します。
- 毒性分析用の TensforFlow.js。TensorFlow.js は、ウェブでの推論とトレーニングの両方に対応したオープンソースの機械学習ライブラリです。
- 感情分析用の transformers.js。Transformers.js は、Hugging Face のウェブ AI ライブラリです。
- Gemma 2B(星評価用)。Gemma は、Google が Gemini モデルの作成に使用した研究とテクノロジーに基づいて構築された、軽量なオープンモデルのファミリーです。ブラウザで Gemma を実行するには、MediaPipe の試験運用版 LLM 推論 API とともに使用します。
UX と安全性に関する考慮事項
最適なユーザー エクスペリエンスと安全性を確保するために、以下の点を考慮する必要があります。
- ユーザーが評価を編集できるようにします。最終的に、ユーザーが商品評価を決定する必要があります。
- 評価とレビューが自動化されていることをユーザーに明確に伝えます。
- 有害と分類されたレビューをユーザーが投稿できるようにしますが、サーバーで 2 回目のチェックを実行します。これにより、有害でないレビューが誤って有害と分類される(偽陽性)という不満の多い事態を防ぐことができます。また、悪意のあるユーザーがクライアントサイドのチェックを回避した場合も対象となります。
- クライアント側の有害性チェックは有用ですが、バイパスされる可能性があります。サーバーサイドでもチェックを実行してください。
TensorFlow.js で有害性を分析する
TensorFlow.js を使用すると、ユーザー レビューの有害性をすばやく分析できます。
- TensorFlow.js ライブラリと毒性モデルをインストールしてインポートします。
- 最小予測信頼度を設定します。デフォルトは 0.85 です。この例では 0.9 に設定しています。
- モデルを非同期で読み込みます。
- レビューを非同期で分類します。このコードは、任意のカテゴリで 0.9 のしきい値を超える予測を特定します。
このモデルは、アイデンティティ攻撃、侮辱、わいせつなどの毒性を分類できます。
次に例を示します。
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Transformers.js で感情を判断する
Transformers.js ライブラリをインストールしてインポートします。
専用のパイプラインを使用して、感情分析タスクを設定します。パイプラインが初めて使用されると、モデルがダウンロードされてキャッシュに保存されます。それ以降、感情分析ははるかに高速になります。
レビューを非同期で分類します。カスタムしきい値を使用して、アプリケーションで使用可能と見なす信頼レベルを設定します。
次に例を示します。
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Gemma と MediaPipe を使用して星の評価を提案する
LLM Inference API を使用すると、大規模言語モデル(LLM)をブラウザで完全に実行できます。
この新機能は、クライアントサイド モデルの 100 倍以上のメモリとコンピューティングを必要とする LLM の需要を考慮すると、特に画期的です。新しいオペレーション、量子化、キャッシュ保存、重み共有など、ウェブスタック全体にわたる最適化により、これが可能になります。出典: 「MediaPipe と TensorFlow Lite を使用したオンデバイスの大規模言語モデル」。
- MediaPipe LLM 推論 API をインストールしてインポートします。
- モデルをダウンロードする。ここでは、Kaggle からダウンロードした Gemma 2B を使用します。Gemma 2B は、Google のオープン ウェイト モデルの中で最も小さいモデルです。
FilesetResolverを使用して、コードを正しいモデルファイルに指定します。これは、生成 AI モデルのアセットに特定のディレクトリ構造がある可能性があるため、重要です。- MediaPipe の LLM インターフェースを使用してモデルを読み込んで構成します。モデルを使用する準備をします。モデルの場所、回答の推奨される長さ、温度による推奨される創造性のレベルを指定します。
- モデルにプロンプトを指定します(例をご覧ください)。
- モデルのレスポンスを待ちます。
- 評価を解析する: モデルのレスポンスから星評価を抽出します。
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
質問の例
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
要点
AI/ML の専門知識は不要です。プロンプトの設計には反復が必要ですが、残りのコードは標準的なウェブ開発です。
クライアント サイドのモデルはかなり正確です。このドキュメントのスニペットを実行すると、有害性分析と感情分析の両方で正確な結果が得られることがわかります。Gemma の評価は、テストされたいくつかの参照レビューで Gemini モデルの評価とほぼ一致しました。その精度を検証するには、さらにテストが必要です。
ただし、Gemma 2B のプロンプトを設計するには作業が必要です。Gemma 2B は小規模な LLM であるため、満足のいく結果を得るには詳細なプロンプトが必要です。特に、Gemini API で必要なプロンプトよりも詳細なプロンプトが必要です。
推論は非常に高速です。このドキュメントのスニペットを実行すると、多くのデバイスで推論が高速化され、サーバーのラウンド トリップよりも高速になる可能性があります。ただし、推論速度は大きく異なる可能性があります。ターゲット デバイスでの徹底的なベンチマークが必要です。WebGPU、WebAssembly、ライブラリの更新により、ブラウザ推論は今後も高速化されると予想されます。たとえば、Transformers.js は v3 で Web GPU のサポートを追加しており、これによりオンデバイス推論を大幅に高速化できます。
ダウンロード サイズが非常に大きくなることがあります。ブラウザでの推論は高速ですが、AI モデルの読み込みは難しい場合があります。ブラウザ内 AI を実行するには、通常、ライブラリとモデルの両方が必要であり、ウェブアプリのダウンロード サイズが増加します。
Tensorflow の毒性モデル(従来の自然言語処理モデル)は数キロバイトにすぎませんが、Transformers.js のデフォルトの感情分析モデルなどの生成 AI モデルは 60 MB に達します。Gemma などの大規模言語モデルは、1.3 GB にもなることがあります。これは、中央値の 2.2 MB のウェブページ サイズをはるかに超えており、最適なパフォーマンスを得るために推奨されるサイズを大幅に超えています。クライアントサイドの生成 AI は、特定のシナリオで実現可能です。
ウェブ上の生成 AI の分野は急速に進化しています。今後、より小さくウェブに最適化されたモデルが登場する予定です。
次のステップ
Chrome では、ブラウザで生成 AI を実行する別の方法の試験運用を行っています。早期プレビュー プログラムに登録して、お試しください。