



Gepubliceerd: 16 mei 2024
Positieve en negatieve beoordelingen kunnen de aankoopbeslissing van een koper beïnvloeden.
Volgens extern onderzoek zoekt 82% van de online shoppers actief naar negatieve recensies voordat ze een aankoop doen. Deze negatieve recensies zijn nuttig voor klanten en bedrijven, omdat de beschikbaarheid van negatieve recensies het retourpercentage kan helpen verlagen en makers kan helpen hun producten te verbeteren.
Hier volgen enkele manieren waarop u de beoordelingskwaliteit kunt verbeteren:
- Controleer elke beoordeling op toxiciteit voordat deze wordt ingediend. We kunnen gebruikers aanmoedigen om aanstootgevend taalgebruik en andere nutteloze opmerkingen te verwijderen, zodat hun beoordeling andere gebruikers het beste helpt een betere aankoopbeslissing te nemen.
- Negatief : deze tas is waardeloos en ik haat hem.
- Negatief met nuttige feedback. De ritsen zijn erg stijf en het materiaal voelt goedkoop aan. Ik heb deze tas geretourneerd.
- Genereer automatisch een beoordeling op basis van het taalgebruik in de recensie.
- Bepaal of de recensie negatief of positief is.
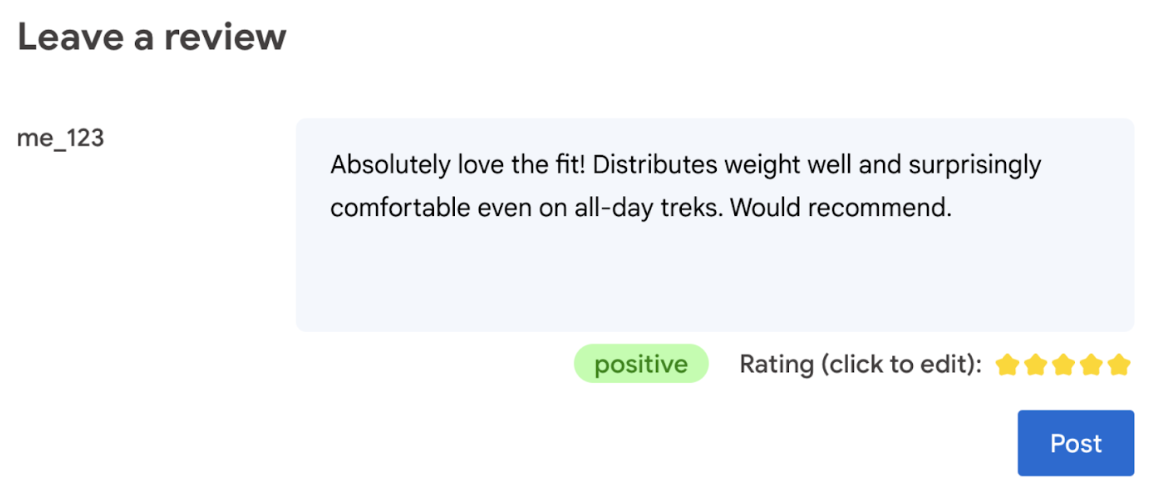
Uiteindelijk moet de gebruiker het laatste woord hebben over de productbeoordeling.
Het volgende codelab biedt oplossingen aan de clientzijde, op het apparaat en in de browser. Geen AI-ontwikkelingskennis, servers of API-sleutels vereist.
Vereisten
Hoewel AI op de server met oplossingen (zoals de Gemini API of OpenAI API ) robuuste oplossingen biedt voor veel toepassingen, concentreren we ons in deze handleiding op web-AI aan de clientzijde. AI-inferentie aan de clientzijde vindt plaats in de browser, om de ervaring voor internetgebruikers te verbeteren door serverrondreizen te verwijderen.
In dit codelab gebruiken we een mix van technieken om u te laten zien wat er in uw toolbox zit voor AI aan de clientzijde.
Wij gebruiken de volgende bibliotheken en modellen:
- TensforFlow.js voor toxiciteitsanalyse. TensorFlow.js is een open source machine learning-bibliotheek voor zowel gevolgtrekking als training op internet.
- transformers.js voor sentimentanalyse. Transformers.js is een web-AI-bibliotheek van Hugging Face.
- Gemma 2B voor sterbeoordelingen. Gemma is een familie van lichtgewicht, open modellen die zijn opgebouwd op basis van het onderzoek en de technologie die Google heeft gebruikt om de Gemini-modellen te maken. Om Gemma in de browser uit te voeren, gebruiken we het met de experimentele LLM Inference API van MediaPipe.
UX en veiligheidsoverwegingen
Er zijn een aantal overwegingen om een optimale gebruikerservaring en veiligheid te garanderen:
- Sta de gebruiker toe de beoordeling te bewerken. Uiteindelijk moet de gebruiker het laatste woord hebben over de productbeoordeling.
- Maak de gebruiker duidelijk dat de beoordelingen en recensies geautomatiseerd zijn.
- Sta gebruikers toe een recensie te plaatsen die als giftig is geclassificeerd, maar voer een tweede controle uit op de server. Dit voorkomt een frustrerende ervaring waarbij een niet-giftige beoordeling ten onrechte als giftig wordt geclassificeerd (een vals-positief). Dit geldt ook voor gevallen waarin een kwaadwillende gebruiker erin slaagt de controle aan de clientzijde te omzeilen.
- Een toxiciteitscontrole aan de clientzijde is nuttig, maar kan worden omzeild. Zorg ervoor dat u ook een controle op de server uitvoert.
Analyseer de toxiciteit met TensorFlow.js
Met TensorFlow.js kunt u snel beginnen met het analyseren van de toxiciteit van een gebruikersrecensie.
- Installeer en importeer de TensorFlow.js-bibliotheek en het toxiciteitsmodel.
- Stel een minimale voorspellingsbetrouwbaarheid in. De standaardwaarde is 0,85 en in ons voorbeeld hebben we deze ingesteld op 0,9.
- Laad het model asynchroon.
- Classificeer de recensie asynchroon. Onze code identificeert voor elke categorie voorspellingen die de drempel van 0,9 overschrijden.
Dit model kan toxiciteit categoriseren in identiteitsaanvallen, beledigingen, obsceniteit en meer.
Bijvoorbeeld:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Bepaal het sentiment met Transformers.js
Installeer en importeer de Transformers.js-bibliotheek.
Stel de sentimentanalysetaak in met een speciale pijplijn . Wanneer een pijplijn voor de eerste keer wordt gebruikt, wordt het model gedownload en in de cache opgeslagen. Vanaf dat moment zou de sentimentanalyse veel sneller moeten zijn.
Classificeer de recensie asynchroon. Gebruik een aangepaste drempelwaarde om het betrouwbaarheidsniveau in te stellen dat u bruikbaar acht voor uw toepassing.
Bijvoorbeeld:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Stel een sterbeoordeling voor bij Gemma en MediaPipe
Met de LLM Inference API kunt u grote taalmodellen (LLM's) volledig in de browser uitvoeren.
Deze nieuwe mogelijkheid is bijzonder transformatief gezien de geheugen- en rekenvereisten van LLM's, die meer dan honderd keer groter zijn dan die van client-side modellen. Optimalisaties op de hele webstack maken dit mogelijk, inclusief nieuwe bewerkingen, kwantisering, caching en gewichtsverdeling. Bron: "Grote taalmodellen op het apparaat met MediaPipe en TensorFlow Lite" .
- Installeer en importeer de MediaPipe LLM-inferentie-API.
- Een model downloaden . Hier gebruiken we Gemma 2B , gedownload van Kaggle . Gemma 2B is de kleinste van Google's open-weight-modellen.
- Verwijs de code naar de juiste modelbestanden, met de
FilesetResolver. Dit is belangrijk omdat generatieve AI-modellen een specifieke directorystructuur voor hun assets kunnen hebben. - Laad en configureer het model met de LLM-interface van MediaPipe. Bereid het model voor op gebruik: specificeer de modellocatie, de gewenste lengte van de antwoorden en het gewenste niveau van creativiteit met betrekking tot de temperatuur.
- Geef het model een prompt ( zie een voorbeeld ).
- Wacht op de reactie van het model.
- Analyseren voor de beoordeling: Haal de sterbeoordeling uit de reactie van het model.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Voorbeeld prompt
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Afhaalrestaurants
Er is geen AI/ML-expertise vereist . Het ontwerpen van een prompt vereist iteraties, maar de rest van de code is standaard webontwikkeling.
Client-side modellen zijn redelijk accuraat . Als u de fragmenten uit dit document doorneemt, zult u zien dat zowel de toxiciteits- als de sentimentanalyse nauwkeurige resultaten opleveren. De Gemma-beoordelingen kwamen voor het grootste deel overeen met de Gemini-modelbeoordelingen voor een paar geteste referentierecensies. Om die nauwkeurigheid te valideren, zijn meer tests nodig.
Dat gezegd hebbende, het ontwerpen van de prompt voor Gemma 2B kost werk. Omdat Gemma 2B een kleine LLM is, heeft het een gedetailleerde prompt nodig om bevredigende resultaten te produceren, met name gedetailleerder dan wat vereist is met de Gemini API.
Inferentie kan razendsnel zijn . Als u de fragmenten uit dit document uitvoert, moet u er rekening mee houden dat de gevolgtrekking op een aantal apparaten snel kan gaan, mogelijk sneller dan serverrondreizen. Dat gezegd hebbende, kan de inferentiesnelheid sterk variëren. Grondige benchmarking op doelapparaten is nodig. We verwachten dat browserinferentie steeds sneller zal worden met WebGPU-, WebAssembly- en bibliotheekupdates. Transformers.js voegt bijvoorbeeld Web GPU-ondersteuning toe in v3 , wat de inferentie op het apparaat vele malen kan versnellen .
Downloadgroottes kunnen erg groot zijn. Inferentie in de browser gaat snel, maar het laden van AI-modellen kan een uitdaging zijn. Om AI in de browser uit te voeren, hebt u doorgaans zowel een bibliotheek als een model nodig, die bijdragen aan de downloadgrootte van uw web-app.
Terwijl het Tensorflow-toxiciteitsmodel (een klassiek model voor natuurlijke taalverwerking) slechts een paar kilobyte groot is, bereiken generatieve AI-modellen zoals het standaard sentimentanalysemodel van Transformers.js 60 MB. Grote taalmodellen zoals Gemma kunnen wel 1,3 GB groot zijn. Dit overschrijdt de gemiddelde webpaginagrootte van 2,2 MB , die al veel groter is dan aanbevolen voor de beste prestaties. Generatieve AI aan de clientzijde is haalbaar in specifieke scenario's.
Het veld van generatieve AI op internet evolueert snel! Er wordt verwacht dat er in de toekomst kleinere, voor het web geoptimaliseerde modellen zullen ontstaan .
Volgende stappen
Chrome experimenteert met een andere manier om generatieve AI in de browser uit te voeren. U kunt zich aanmelden voor het vroege preview-programma om het te testen.