

大多數語言模型都有一個共同點:對於透過網際網路傳輸的資源而言,它們相當龐大。最小的 MediaPipe 物件偵測模型 (SSD MobileNetV2 float16) 為 5.6 MB,最大的則約為 25 MB。
這個開放原始碼大型語言模型 (LLM)
gemma-2b-it-gpu-int4.bin
大小為 1.35 GB,以 LLM 來說算是非常小。生成式 AI 模型可能非常龐大。因此,目前許多 AI 用途都發生在雲端。越來越多應用程式直接在裝置上執行經過高度最佳化的模型。雖然在瀏覽器中執行 LLM 的展示已存在,但以下是在瀏覽器中執行其他模型的實際工作環境級範例:
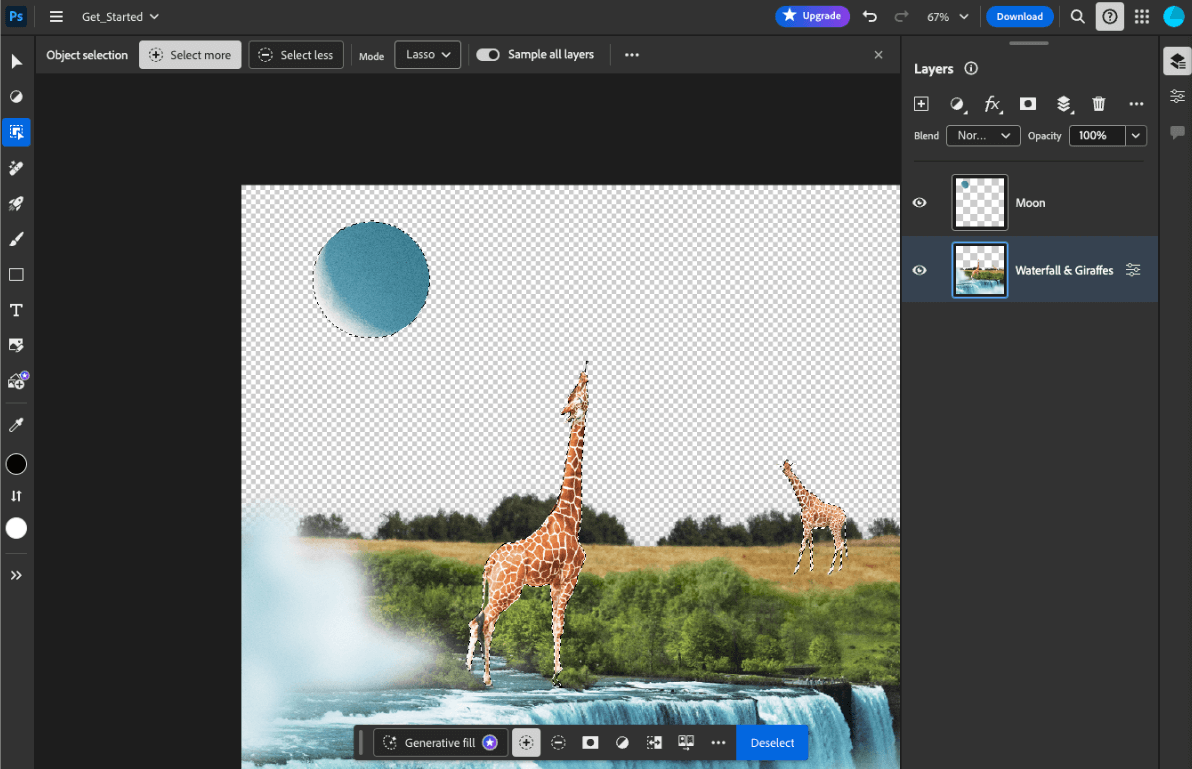
- Adobe Photoshop 會在裝置上執行
Conv2D模型變體,以提供智慧物件選取工具。 - Google Meet 會執行
MobileNetV3-small模型的改良版本,以進行人物區隔,提供背景模糊功能。 - Tokopedia 執行
MediaPipeFaceDetector-TFJS模型,即時偵測臉部,防止無效註冊。 - Google Colab 可讓使用者在 Colab 筆記本中使用硬碟中的模型。
為加快日後啟動應用程式的速度,您應在裝置上明確快取模型資料,而非依賴隱含的 HTTP 瀏覽器快取。
本指南使用 gemma-2b-it-gpu-int4.bin 模型建立聊天機器人,但這種方法可普遍適用於其他模型,以及裝置上的其他用途。將應用程式連結至模型最常見的方式,是與應用程式的其餘資源一起放送模型。因此請務必最佳化放送方式。
設定正確的快取標頭
如果您從伺服器提供 AI 模型,請務必設定正確的 Cache-Control 標頭。以下範例顯示預設設定,您可以根據應用程式需求進行調整。
Cache-Control: public, max-age=31536000, immutable
每個發布的 AI 模型版本都是靜態資源。對於從未變更的內容,應提供較長的 max-age,並在要求網址中清除快取。如需更新模型,請務必提供新網址。
使用者重新載入網頁時,即使伺服器知道內容穩定,用戶端仍會傳送重新驗證要求。immutable 指令會明確指出不需要重新驗證,因為內容不會變更。瀏覽器和中介快取或 Proxy 伺服器不廣泛支援 immutable 指令,但只要搭配普遍適用的 max-age 指令,就能確保最大相容性。public
回應指令表示回應可儲存在共用快取中。
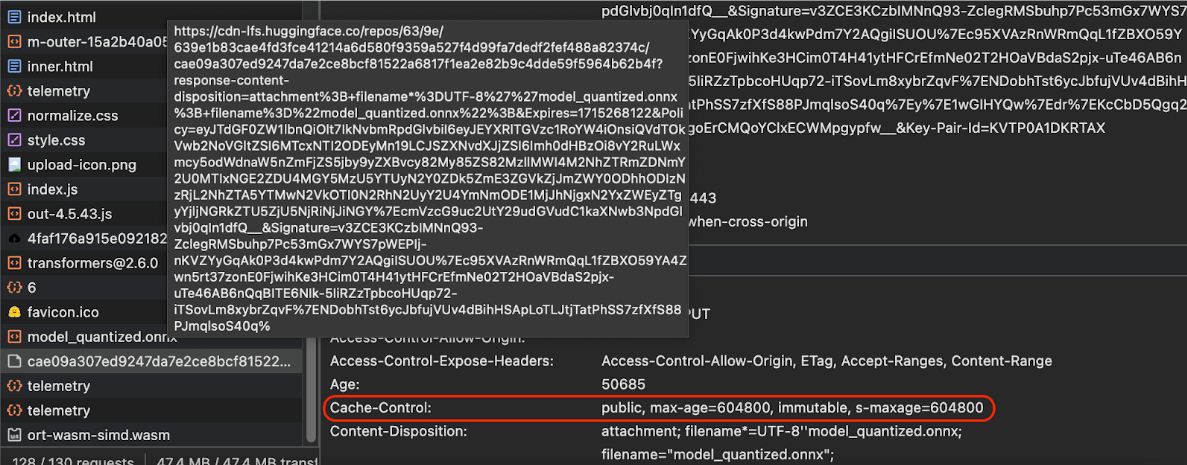
Cache-Control
標頭。(來源)
在用戶端快取 AI 模型
提供 AI 模型時,請務必在瀏覽器中明確快取模型。確保使用者重新載入應用程式後,模型資料隨時可用。
您可以使用多種技術達成這個目的。在下列程式碼範例中,假設每個模型檔案都儲存在名為 blob 的 Blob 物件中。
為瞭解效能,每個程式碼範例都會註解 performance.mark() 和 performance.measure() 方法。這些措施因裝置而異,無法普遍適用。

您可以選擇使用下列其中一個 API,在瀏覽器中快取 AI 模型: Cache API、 Origin Private File System API 和 IndexedDB API。一般建議是使用 Cache API,但本指南會討論所有選項的優缺點。
Cache API
Cache API 可為長期記憶體中快取的 Request 和 Response 物件配對提供永久儲存空間。雖然服務工作人員規格中已定義,但您可以從主執行緒或一般工作人員使用這個 API。如要在服務工作人員環境以外使用,請呼叫 Cache.put() 方法,並搭配合成 Response 物件和合成網址,而非 Request 物件。
本指南假設您使用記憶體內 blob。使用假的網址做為快取鍵,並根據 blob 合成 Response。如要直接下載模型,請使用透過發出 fetch() 要求取得的 Response。
舉例來說,以下說明如何使用 Cache API 儲存及還原模型檔案。
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
Origin Private File System API
來源私有檔案系統 (OPFS) 是相對較新的儲存端點標準。這類檔案系統屬於網頁來源的私有檔案系統,因此與一般檔案系統不同,使用者無法查看。這個檔案經過高度最佳化,可提升效能,並提供內容的寫入權限。
舉例來說,以下說明如何在 OPFS 中儲存及還原模型檔案。
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB 是將任意資料以持續性方式儲存在瀏覽器中的成熟標準。IndexedDB 的 API 複雜程度眾所皆知,但只要使用 idb-keyval 等包裝函式庫,就能將 IndexedDB 視為傳統的鍵值儲存區。
例如:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
將儲存空間標示為持續存在
在上述任一快取方法結尾呼叫 navigator.storage.persist(),要求使用永久儲存空間的權限。這個方法會傳回 Promise,如果已授予權限,Promise 會解析為 true,否則會解析為 false。瀏覽器可能會或可能不會接受要求,視瀏覽器專屬規則而定。
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
特殊情況:使用硬碟上的模型
您可以直接從使用者的硬碟參照 AI 模型,做為瀏覽器儲存空間的替代方案。這項技術可協助以研究為主的應用程式,展示在瀏覽器中執行特定模型的可行性,或讓藝術家在專業創意應用程式中使用自行訓練的模型。
File System Access API
使用 File System Access API,您可以開啟硬碟中的檔案,並取得可保存至 IndexedDB 的 FileSystemFileHandle。
採用這種模式時,使用者只需要授予模型檔案存取權一次。有了持續性權限,使用者可以選擇永久授予檔案存取權。重新載入應用程式並執行必要的使用者手勢 (例如按一下滑鼠) 後,即可從 IndexedDB 還原 FileSystemFileHandle,並存取硬碟上的檔案。
系統會查詢檔案存取權,並在必要時要求授權,讓日後的重新載入作業順暢無礙。以下範例說明如何從硬碟取得檔案控制代碼,然後儲存及還原該控制代碼。
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
這些方法並非互斥。您可能會在瀏覽器中明確快取模型,並使用使用者硬碟中的模型。
示範
您可以在 MediaPipe LLM 示範中,查看所有三種一般案例儲存方法和硬碟方法。
加分題:分塊下載大型檔案
如需從網際網路下載大型 AI 模型,請將下載作業平行處理為個別區塊,然後在用戶端重新組合。
fetch-in-chunks 套件提供可在程式碼中使用的輔助函式。您只需要將 url 傳遞給該函式即可。maxParallelRequests (預設值:6)、chunkSize (預設值:要下載的檔案大小除以 maxParallelRequests)、progressCallback 函式 (會回報 downloadedBytes 和總 fileSize),以及 AbortSignal 信號的 signal 皆為選用項目。
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
選擇適合自己的方法
本指南探討了在瀏覽器中有效快取 AI 模型的各種方法,這項工作對於提升應用程式的使用者體驗和效能至關重要。Chrome 儲存空間團隊建議使用 Cache API,確保能快速存取 AI 模型、縮短載入時間並提升回應速度,以達到最佳效能。
OPFS 和 IndexedDB 的實用性較低,OPFS 和 IndexedDB API 必須先序列化資料,才能儲存資料。IndexedDB 也需要在擷取資料時還原序列化,因此不適合儲存大型模型。
對於利基應用程式,檔案系統存取 API 可直接存取使用者裝置上的檔案,非常適合管理自有 AI 模型的使用者。
如要保護 AI 模型,請將模型保留在伺服器上。儲存在用戶端後,即可使用開發人員工具或 OFPS 開發人員工具擴充功能,從快取和 IndexedDB 擷取資料。這些儲存空間 API 本質上具有相同的安全性。您可能會想儲存模型的加密版本,但這樣就必須將解密金鑰提供給用戶端,而這可能會遭到攔截。這表示惡意行為人竊取模型的難度會稍微提高,但並非不可能。
建議您根據應用程式需求、目標對象行為,以及所用 AI 模型的特性,選擇合適的快取策略。確保應用程式在各種網路狀況和系統限制下,都能做出回應並穩定運作。
特別銘謝
本文由 Joshua Bell、Reilly Grant、Evan Stade、Nathan Memmott、Austin Sullivan、Etienne Noël、André Bandarra、Alexandra Klepper、François Beaufort、Paul Kinlan 和 Rachel Andrew 審查。