

De meeste taalmodellen hebben één ding gemeen: ze zijn vrij groot voor een resource die via internet wordt verzonden. Het kleinste MediaPipe-objectdetectiemodel ( SSD MobileNetV2 float16 ) weegt 5,6 MB en het grootste ongeveer 25 MB.
Het open-source grote taalmodel (LLM) gemma-2b-it-gpu-int4.bin is 1,35 GB groot – en dit wordt als zeer klein beschouwd voor een LLM. Generatieve AI-modellen kunnen enorm groot zijn. Daarom vindt AI-gebruik tegenwoordig vaak in de cloud plaats. Apps draaien steeds vaker sterk geoptimaliseerde modellen direct op het apparaat. Hoewel er demo's bestaan van LLM's die in de browser draaien , volgen hier enkele voorbeelden van andere modellen die in de browser draaien, op productieniveau:
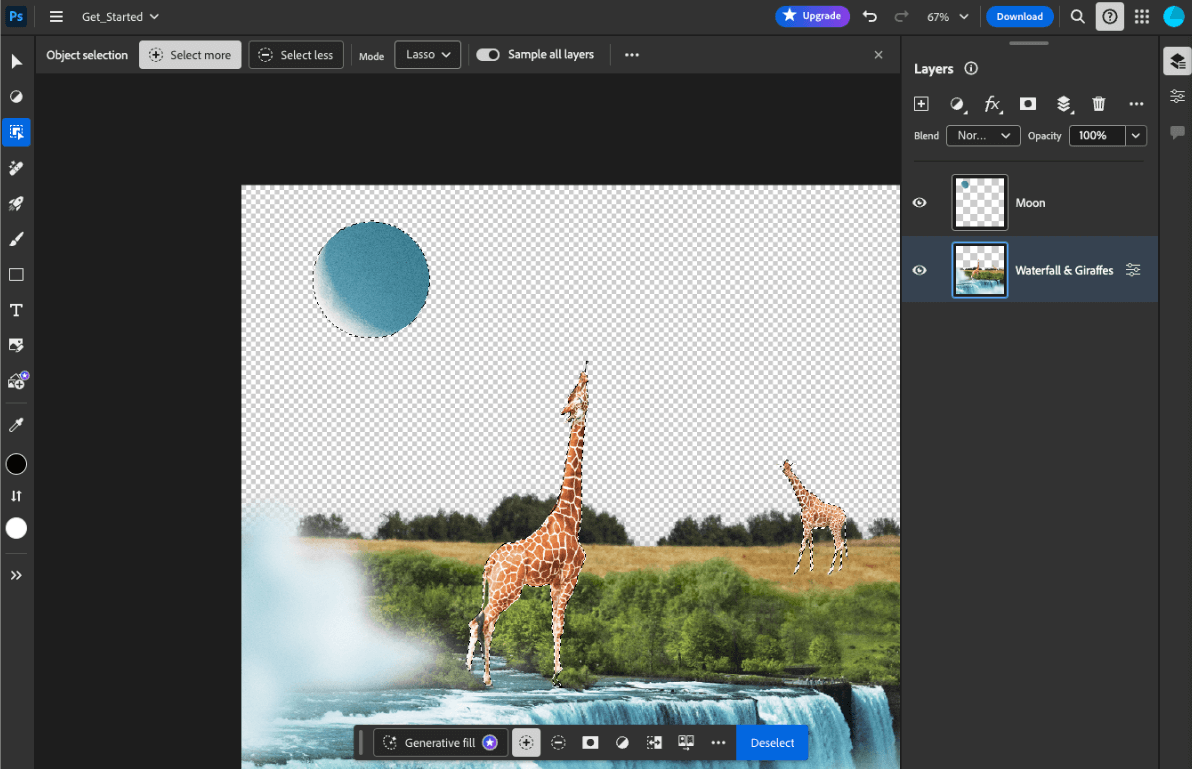
- Adobe Photoshop draait een variant van het
Conv2D-model op het apparaat voor zijn intelligente objectselectietool. - Google Meet gebruikt een geoptimaliseerde versie van het
MobileNetV3-smallmodel voor persoonssegmentatie voor de functie voor achtergrondvervaging. - Tokopedia gebruikt het
MediaPipeFaceDetector-TFJSmodel voor realtime gezichtsdetectie om ongeldige aanmeldingen voor haar service te voorkomen. - Met Google Colab kunnen gebruikers modellen van hun harde schijf gebruiken in Colab-notebooks.
Om toekomstige lanceringen van uw applicaties sneller te maken, moet u de modelgegevens expliciet op het apparaat cachen in plaats van te vertrouwen op de impliciete HTTP-browsercache.
Hoewel deze handleiding het gemma-2b-it-gpu-int4.bin model gebruikt om een chatbot te maken, kan de aanpak worden gegeneraliseerd naar andere modellen en use cases op het apparaat. De meest gebruikelijke manier om een app aan een model te koppelen, is door het model samen met de rest van de app-resources te gebruiken. Het is cruciaal om de levering te optimaliseren.
Configureer de juiste cacheheaders
Als u AI-modellen vanaf uw server serveert, is het belangrijk om de juiste Cache-Control header te configureren. Het volgende voorbeeld toont een solide standaardinstelling, die u kunt gebruiken voor de behoeften van uw app.
Cache-Control: public, max-age=31536000, immutable
Elke uitgebrachte versie van een AI-model is een statische bron. Content die nooit verandert, moet een lange max-age krijgen in combinatie met cachebusting in de aanvraag-URL. Als u het model toch moet bijwerken, moet u het een nieuwe URL geven .
Wanneer de gebruiker de pagina opnieuw laadt, stuurt de client een verzoek tot hervalidatie, ook al weet de server dat de inhoud stabiel is. De richtlijn immutable geeft expliciet aan dat hervalidatie niet nodig is, omdat de inhoud niet verandert. De richtlijn immutable ' wordt niet breed ondersteund door browsers en intermediaire cache- of proxyservers, maar door deze te combineren met de universeel bekende richtlijn max-age kunt u maximale compatibiliteit garanderen. De richtlijn public response' geeft aan dat het antwoord in een gedeelde cache kan worden opgeslagen.

Cache-Control headers weer die door Hugging Face worden verzonden bij het aanvragen van een AI-model. ( Bron ) Cache AI-modellen client-side
Wanneer u een AI-model gebruikt, is het belangrijk om het model expliciet in de browser te cachen. Dit zorgt ervoor dat de modelgegevens direct beschikbaar zijn nadat een gebruiker de app opnieuw laadt.
Er zijn verschillende technieken die u kunt gebruiken om dit te bereiken. Voor de volgende codevoorbeelden gaan we ervan uit dat elk modelbestand is opgeslagen in een Blob object met de naam blob in het geheugen.
Om de prestaties te begrijpen, wordt elk codevoorbeeld geannoteerd met de methoden performance.mark() en performance.measure() . Deze metingen zijn apparaatafhankelijk en niet generaliseerbaar.

U kunt ervoor kiezen om een van de volgende API's te gebruiken om AI-modellen in de browser te cachen: Cache API , Origin Private File System API en IndexedDB API . De algemene aanbeveling is om de Cache API te gebruiken , maar in deze handleiding worden de voor- en nadelen van alle opties besproken.
Cache-API
De Cache API biedt permanente opslag voor Request en Response -objectparen die in het long-live geheugen worden opgeslagen. Hoewel deze API is gedefinieerd in de Service Workers-specificatie , kunt u deze API gebruiken vanuit de hoofdthread of een reguliere worker. Om deze buiten een service worker-context te gebruiken, roept u de Cache.put() -methode aan met een synthetisch Response object, gekoppeld aan een synthetische URL in plaats van een Request -object.
Deze handleiding gaat uit van een in-memory blob . Gebruik een nep-URL als cachesleutel en een synthetische Response gebaseerd op de blob . Als u het model rechtstreeks zou downloaden, zou u de Response gebruiken die u zou krijgen door een fetch() -aanvraag in te dienen.
Hier leest u bijvoorbeeld hoe u een modelbestand kunt opslaan en herstellen met de Cache API.
const storeFileInSWCache = async (blob) => {
try {
performance.mark('start-sw-cache-cache');
const modelCache = await caches.open('models');
await modelCache.put('model.bin', new Response(blob));
performance.mark('end-sw-cache-cache');
const mark = performance.measure(
'sw-cache-cache',
'start-sw-cache-cache',
'end-sw-cache-cache'
);
console.log('Model file cached in sw-cache.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromSWCache = async () => {
try {
performance.mark('start-sw-cache-restore');
const modelCache = await caches.open('models');
const response = await modelCache.match('model.bin');
if (!response) {
throw new Error(`File model.bin not found in sw-cache.`);
}
const file = await response.blob();
performance.mark('end-sw-cache-restore');
const mark = performance.measure(
'sw-cache-restore',
'start-sw-cache-restore',
'end-sw-cache-restore'
);
console.log(mark.name, mark.duration.toFixed(2));
console.log('Cached model file found in sw-cache.');
return file;
} catch (err) {
throw err;
}
};
API voor privébestandssysteem van oorsprong
Het Origin Private File System (OPFS) is een relatief jonge standaard voor een opslag-endpoint. Het is privé voor de oorsprong van de pagina en dus onzichtbaar voor de gebruiker, in tegenstelling tot het reguliere bestandssysteem. Het biedt toegang tot een speciaal bestand dat sterk geoptimaliseerd is voor prestaties en schrijftoegang biedt tot de inhoud ervan.
Hier leest u bijvoorbeeld hoe u een modelbestand in de OPFS kunt opslaan en herstellen.
const storeFileInOPFS = async (blob) => {
try {
performance.mark('start-opfs-cache');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin', { create: true });
const writable = await handle.createWritable();
await blob.stream().pipeTo(writable);
performance.mark('end-opfs-cache');
const mark = performance.measure(
'opfs-cache',
'start-opfs-cache',
'end-opfs-cache'
);
console.log('Model file cached in OPFS.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromOPFS = async () => {
try {
performance.mark('start-opfs-restore');
const root = await navigator.storage.getDirectory();
const handle = await root.getFileHandle('model.bin');
const file = await handle.getFile();
performance.mark('end-opfs-restore');
const mark = performance.measure(
'opfs-restore',
'start-opfs-restore',
'end-opfs-restore'
);
console.log('Cached model file found in OPFS.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
IndexedDB API
IndexedDB is een gevestigde standaard voor het permanent opslaan van willekeurige gegevens in de browser. Het staat bekend om zijn ietwat complexe API, maar door een wrapperbibliotheek zoals idb-keyval te gebruiken, kunt u IndexedDB behandelen als een klassieke sleutel-waardeopslag.
Bijvoorbeeld:
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
const storeFileInIDB = async (blob) => {
try {
performance.mark('start-idb-cache');
await set('model.bin', blob);
performance.mark('end-idb-cache');
const mark = performance.measure(
'idb-cache',
'start-idb-cache',
'end-idb-cache'
);
console.log('Model file cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromIDB = async () => {
try {
performance.mark('start-idb-restore');
const file = await get('model.bin');
if (!file) {
throw new Error('File model.bin not found in IDB.');
}
performance.mark('end-idb-restore');
const mark = performance.measure(
'idb-restore',
'start-idb-restore',
'end-idb-restore'
);
console.log('Cached model file found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Opslag markeren als bewaard
Roep navigator.storage.persist() aan aan het einde van een van deze cachemethoden om toestemming te vragen voor het gebruik van permanente opslag. Deze methode retourneert een promise die true oplevert als de toestemming is verleend, en anders false . De browser kan het verzoek wel of niet honoreren , afhankelijk van browserspecifieke regels.
if ('storage' in navigator && 'persist' in navigator.storage) {
try {
const persistent = await navigator.storage.persist();
if (persistent) {
console.log("Storage will not be cleared except by explicit user action.");
return;
}
console.log("Storage may be cleared under storage pressure.");
} catch (err) {
console.error(err.name, err.message);
}
}
Speciaal geval: Gebruik een model op een harde schijf
Je kunt AI-modellen rechtstreeks vanaf de harde schijf van een gebruiker raadplegen als alternatief voor browseropslag. Deze techniek kan onderzoeksgerichte apps helpen de haalbaarheid van het uitvoeren van bepaalde modellen in de browser te demonstreren, of kunstenaars in staat stellen om zelfgetrainde modellen te gebruiken in apps voor professionele creativiteit.
API voor toegang tot bestandssysteem
Met de File System Access API kunt u bestanden vanaf de harde schijf openen en een FileSystemFileHandle verkrijgen die u kunt behouden in IndexedDB.
Met dit patroon hoeft de gebruiker slechts één keer toegang tot het modelbestand te verlenen. Dankzij permanente machtigingen kan de gebruiker ervoor kiezen om permanent toegang tot het bestand te verlenen. Na het opnieuw laden van de app en een vereiste gebruikersbeweging, zoals een muisklik, kan de FileSystemFileHandle worden hersteld vanuit IndexedDB met toegang tot het bestand op de harde schijf.
De toegangsrechten voor bestanden worden opgevraagd en indien nodig aangevraagd, waardoor dit probleemloos verloopt bij toekomstig herladen. Het volgende voorbeeld laat zien hoe u een handle voor een bestand van de harde schijf kunt halen en deze handle vervolgens kunt opslaan en herstellen.
import { fileOpen } from 'https://cdn.jsdelivr.net/npm/browser-fs-access@latest/dist/index.modern.js';
import { get, set } from 'https://cdn.jsdelivr.net/npm/idb-keyval@latest/+esm';
button.addEventListener('click', async () => {
try {
const file = await fileOpen({
extensions: ['.bin'],
mimeTypes: ['application/octet-stream'],
description: 'AI model files',
});
if (file.handle) {
// It's an asynchronous method, but no need to await it.
storeFileHandleInIDB(file.handle);
}
return file;
} catch (err) {
if (err.name !== 'AbortError') {
console.error(err.name, err.message);
}
}
});
const storeFileHandleInIDB = async (handle) => {
try {
performance.mark('start-file-handle-cache');
await set('model.bin.handle', handle);
performance.mark('end-file-handle-cache');
const mark = performance.measure(
'file-handle-cache',
'start-file-handle-cache',
'end-file-handle-cache'
);
console.log('Model file handle cached in IDB.', mark.name, mark.duration.toFixed(2));
} catch (err) {
console.error(err.name, err.message);
}
};
const restoreFileFromFileHandle = async () => {
try {
performance.mark('start-file-handle-restore');
const handle = await get('model.bin.handle');
if (!handle) {
throw new Error('File handle model.bin.handle not found in IDB.');
}
if ((await handle.queryPermission()) !== 'granted') {
const decision = await handle.requestPermission();
if (decision === 'denied' || decision === 'prompt') {
throw new Error('Access to file model.bin.handle not granted.');
}
}
const file = await handle.getFile();
performance.mark('end-file-handle-restore');
const mark = performance.measure(
'file-handle-restore',
'start-file-handle-restore',
'end-file-handle-restore'
);
console.log('Cached model file handle found in IDB.', mark.name, mark.duration.toFixed(2));
return file;
} catch (err) {
throw err;
}
};
Deze methoden sluiten elkaar niet uit. Er kan een situatie zijn waarin u een model expliciet in de browser cachet en een model van de harde schijf van een gebruiker gebruikt.
Demonstratie
In de demo van MediaPipe LLM kunt u alle drie de reguliere opslagmethoden en de harde schijfmethode zien, geïmplementeerd.
Bonus: Download een groot bestand in delen
Als u een groot AI-model van internet moet downloaden, kunt u de download paralleliseren in afzonderlijke delen en deze vervolgens op de client weer aan elkaar plakken.
Het pakket fetch-in-chunks biedt een hulpfunctie die je in je code kunt gebruiken. Je hoeft er alleen de url aan door te geven. De maxParallelRequests (standaard: 6), de chunkSize (standaard: de te downloaden bestandsgrootte gedeeld door maxParallelRequests ), de progressCallback functie (die rapporteert over de downloadedBytes en de totale fileSize ) en het signal voor een AbortSignal -signaal zijn allemaal optioneel.
import fetchInChunks from 'fetch-in-chunks';
async function downloadFileWithProgress() {
try {
const blob = await fetchInChunks('https://example.com/largefile.zip', {
progressCallback: (downloaded, total) => {
console.log(`Downloaded ${((downloaded / total) * 100).toFixed(2)}%`);
},
});
return blob;
} catch (error) {
console.error('Error fetching file:', error);
}
}
downloadFileWithProgress();
Kies de juiste methode voor u
In deze handleiding zijn verschillende methoden besproken voor het effectief cachen van AI-modellen in de browser. Deze taak is cruciaal voor het verbeteren van de gebruikerservaring en de prestaties van uw app. Het Chrome-opslagteam raadt de Cache API aan voor optimale prestaties, om snelle toegang tot AI-modellen te garanderen, laadtijden te verkorten en de responsiviteit te verbeteren.
OPFS en IndexedDB zijn minder bruikbare opties. De OPFS en IndexedDB API's moeten de data serialiseren voordat deze kan worden opgeslagen. IndexedDB moet de data ook deserialiseren wanneer deze wordt opgehaald, waardoor het de slechtste plek is om grote modellen op te slaan.
Voor nichetoepassingen biedt de File System Access API directe toegang tot bestanden op het apparaat van een gebruiker, ideaal voor gebruikers die hun eigen AI-modellen beheren.
Als u uw AI-model moet beveiligen, bewaar het dan op de server. Eenmaal opgeslagen op de client, is het eenvoudig om de gegevens uit zowel de cache als de geïndexeerde database te halen met DevTools of de OFPS DevTools-extensie . Deze opslag-API's zijn inherent gelijkwaardig qua beveiliging. U zou in de verleiding kunnen komen om een gecodeerde versie van het model op te slaan, maar dan moet u de decoderingssleutel naar de client sturen, die kan worden onderschept. Dit betekent dat het voor een kwaadwillende iets moeilijker is om uw model te stelen, maar niet onmogelijk.
We raden u aan een cachingstrategie te kiezen die aansluit bij de vereisten van uw app, het gedrag van de doelgroep en de kenmerken van de gebruikte AI-modellen. Dit zorgt ervoor dat uw applicaties responsief en robuust zijn onder verschillende netwerkomstandigheden en systeembeperkingen.
Dankbetuigingen
Dit werd beoordeeld door Joshua Bell, Reilly Grant, Evan Stade, Nathan Memmott, Austin Sullivan, Etienne Noël, André Bandarra, Alexandra Klepper, François Beaufort, Paul Kinlan en Rachel Andrew.