


發布日期:2025 年 2 月 12 日
Google 搜尋是網路上最熱門的網站之一,也是速度最快的網站之一。Google 搜尋團隊持續投入心力,提升搜尋體驗的速度。在 Google 搜尋這類熱門網頁上,即使是毫秒級的改善,累積起來也能帶來顯著效益!這項對速度的重視包括知名的 Google 首頁、搜尋引擎結果網頁 (SERP),以及從這些搜尋結果點選至其他網站的點擊次數。
Google 搜尋一直使用 Speculation Rules API,提升從搜尋結果頁面導向結果連結的瀏覽速度,並運用 API 的幾項功能,其他網站擁有者或許也會感興趣。
預先擷取前兩筆結果
推測規則的其中一個用途,是預先擷取前兩項搜尋結果。舉例來說,搜尋「test」時,網頁會顯示下列推測規則:
{
"prefetch": [{
"source": "list",
"requires": [
"anonymous-client-ip-when-cross-origin"
],
"referrer_policy": "strict-origin",
"urls": [
"https://www.merriam-webster.com/dictionary/test",
"https://dictionary.cambridge.org/dictionary/english/test"
]
}]
}
底部的兩個網址是前兩項搜尋結果,系統會立即預先擷取這些網址。如果使用者點選這些連結,瀏覽器應該已經有 HTML 文件,因此可以搶先開始載入。
您可以在開發人員工具的「應用程式」->「推測」分頁中查看規則和預先擷取嘗試,如先前所述:
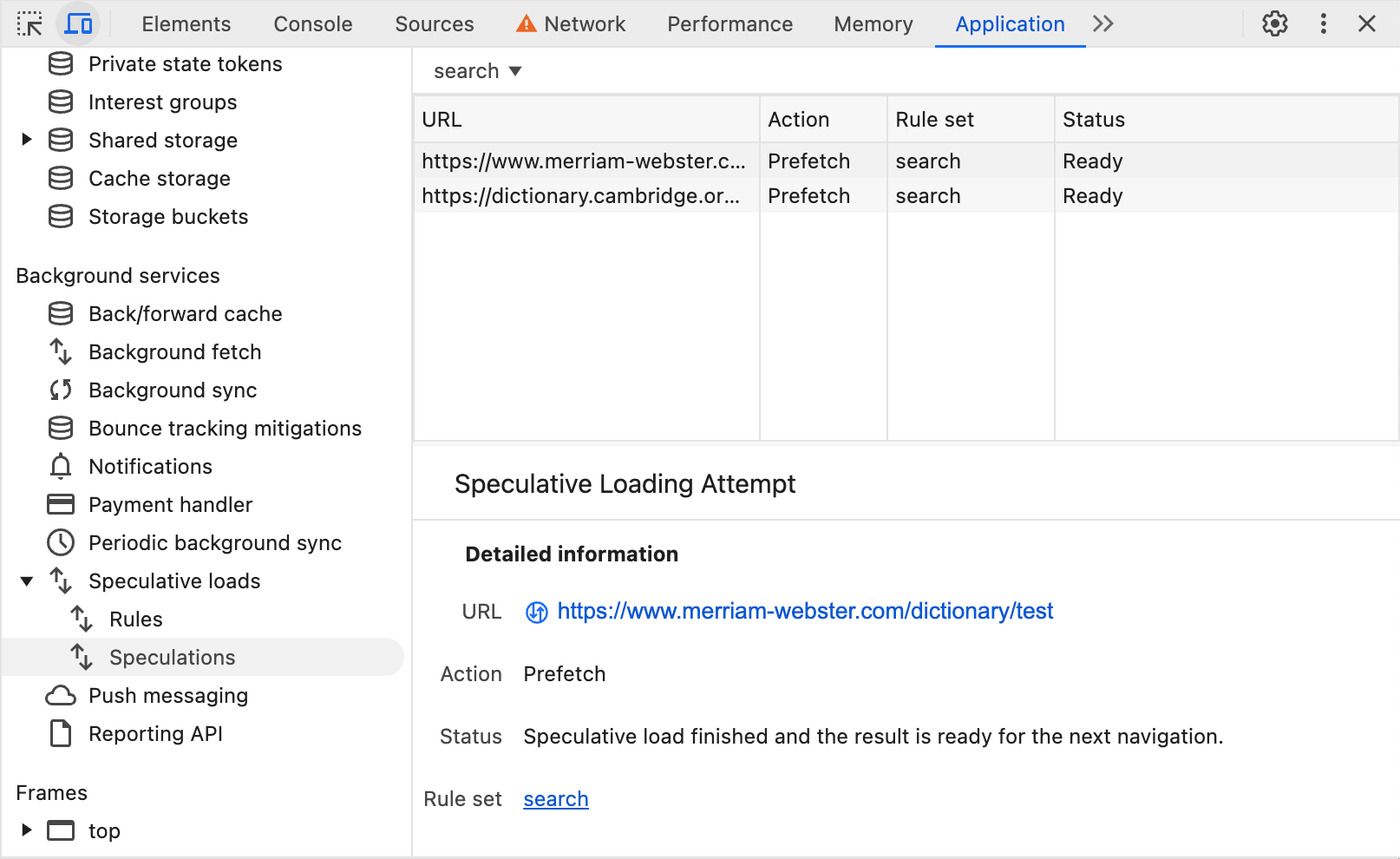
隱私權保護預先擷取
由於這些連結指向其他網站的內容,使用者尚未造訪這些網站,因此預先擷取時需要額外考量隱私權。
幸好 API 設計時已考量到這點,因此 Google 搜尋會運用兩項功能來保護使用者隱私權。
第一種是使用 requires 設定,確保預先擷取作業使用 Chrome 中的私人預先擷取 Proxy:
"requires": [
"anonymous-client-ip-when-cross-origin"
],
這項功能會使用 Proxy 確保連線匿名化 IP 位址,因此使用者點選連結並從搜尋結果頁面前往網站前,我們不會將使用者的 IP 位址洩漏給網站。
推測規則可以預先擷取跨來源資源,不必使用私人預先擷取 Proxy,但對於已使用 Google 服務的網站,Proxy 可防止 IP 位址傳送至 Google 以外的來源。其次,Google 搜尋會使用 referrer_policy 設定,確保搜尋網頁網址中編碼的詳細資料不會透過 referer HTTP 標頭傳送至網站:
"referrer_policy": "strict-origin",
現在大多數瀏覽器預設為 strict-origin-when-cross-origin,但這項設定會使用更嚴格的設定,即使是同源預先擷取,也會使用 strict-origin 參照網址政策。
如果使用者有網站的 Cookie,系統就會自動進行第三層防護。在這種情況下,使用者可能會根據這些 Cookie 收到不同的結果,而 Chrome 不會使用預先擷取的 HTML:
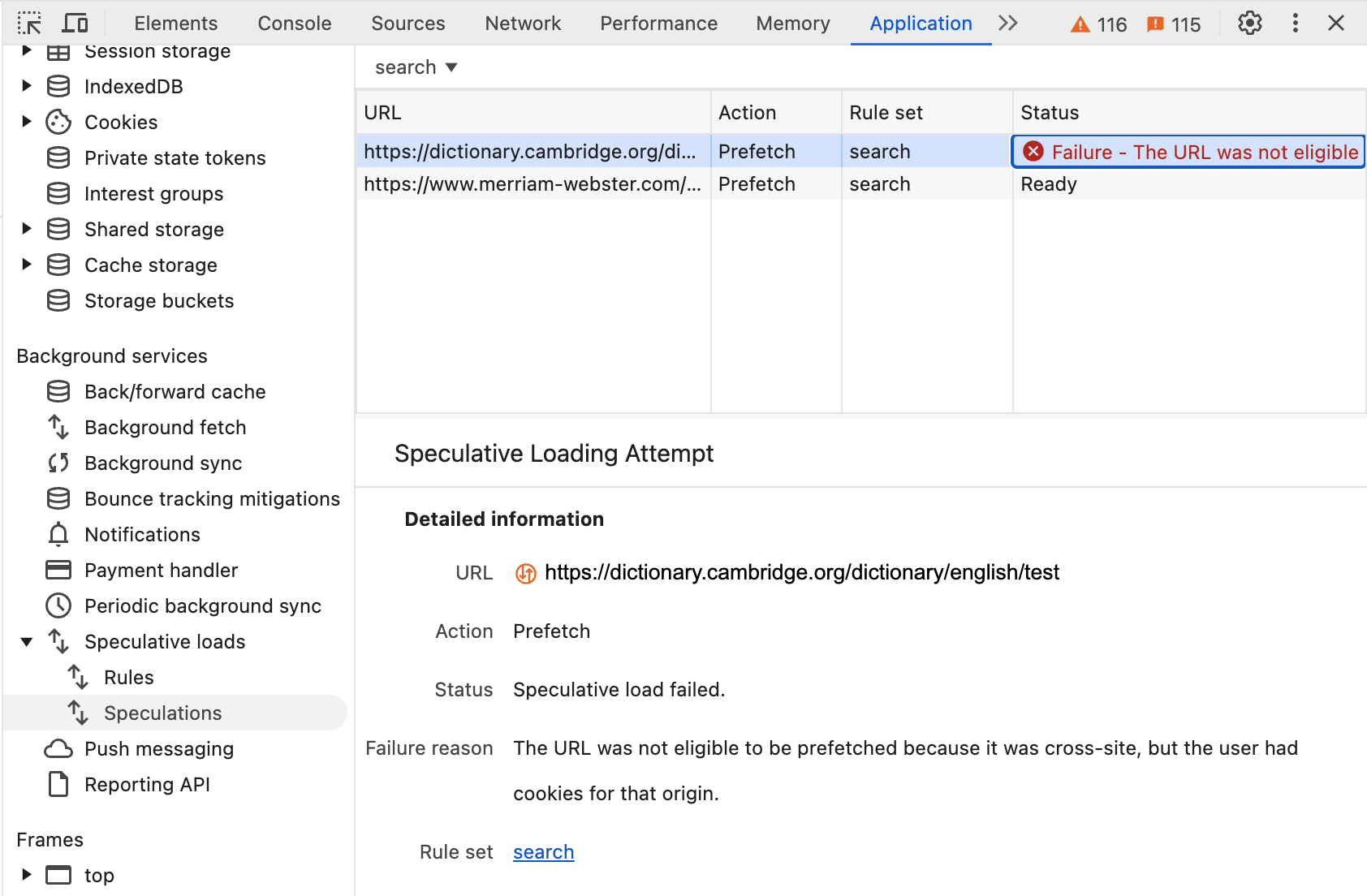
也就是說,如果使用者有 Cookie,點選該網站時就無法享有預先擷取功能帶來的效能提升,但系統會優先保護隱私權並確保網頁載入準確。此外,如果使用者已造訪某個網站並擁有該網站的 Cookie,則他們可能已快取該網站的部分資產,即使沒有預先擷取,網頁載入速度也可能較快。
預先擷取前兩項結果對使用者的影響
與大多數變更一樣,Google 搜尋在 A/B 測試實驗中推出預先擷取功能,並評估影響。最大內容繪製 (LCP) 指標大幅改善。在 Android 版 Chrome 中,Google 搜尋點擊的 LCP 減少了 67 毫秒。後續推出的 Chrome 電腦版也獲得類似的改善,LCP 減少了 58.6 毫秒。這些改善項目適用於導向的網站,而非 Google 搜尋網站本身,但可讓 Google 搜尋使用者受益。
這些 LCP 改善幅度看似微不足道,但對於 Google 搜尋這類經過高度最佳化的網站來說,即使是毫秒級的改善,我們也會為使用者歡慶,因此數十毫秒的改善幅度相當驚人!您的網站可能會獲得顯著效益,建議您試試看!
自 2022 年 10 月起,Android 裝置上的 Google 搜尋預設會啟用「使用推測規則預先擷取」功能,並於 2024 年 9 月前在電腦版推出。
前兩項結果以外的結果
自 Speculation Rules API 推出以來,已透過 eagerness 屬性進行強化,因此只有在使用者將游標懸停在連結上或開始點選連結時,才會進行預測。
Google 搜尋決定不只預先擷取前兩項搜尋結果,也預先擷取其餘搜尋結果,但只有在使用者將游標懸停在連結上時,才會使用 moderate eagerness 設定。這樣可避免浪費資源,因為系統會優先處理較有可能獲得點擊的連結。
同樣地,在 Chrome 中搜尋時,您可以在開發人員工具中看到這項規則,且與先前的規則相同,但這次設定了 "eagerness": "moderate" 選項:
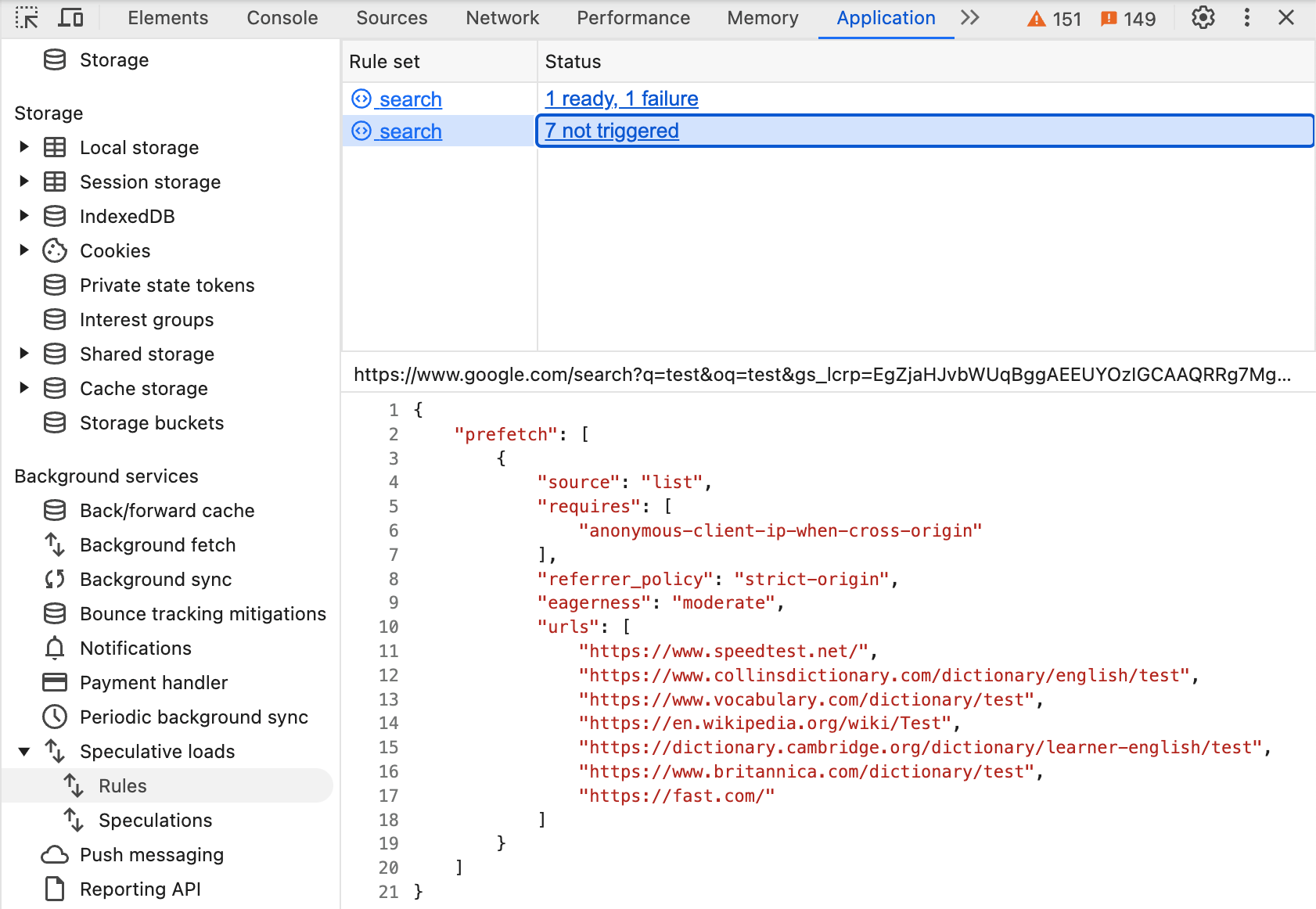
將游標懸停在這些連結上,即可觸發預先擷取。請注意,Google 搜尋會明確列出網址,而不是使用 Speculation Rules API 的文件規則功能,因為他們不想預先擷取廣告等其他網址。
預先擷取前兩項結果以外的內容對使用者的影響
根據 A/B 測試結果,電腦版 Chrome 瀏覽器將 Google 搜尋的首次顯示內容所需時間 (FCP) 縮短了 7.6 毫秒,最大內容繪製 (LCP) 則縮短了 9.5 毫秒。與前兩個結果的 58.6 毫秒改善幅度相比,這些增益較小,但由於系統不會積極預先擷取這些結果,因此領先時間較短,這並不令人意外。不過,基於先前所述原因,這些仍是不錯的收益。
2024 年 12 月起,系統預設會在電腦上預先擷取其餘搜尋結果。
在行動裝置上,由於通常無法使用懸停功能,因此我們並未看到任何實際改善,雖然也沒有回歸,但這些額外的預先擷取功能並未在行動裝置上啟用。
Google 搜尋的進一步推測用途
Google 仍在實驗這項令人期待的全新 API,希望盡可能加快網頁瀏覽速度。我們還在開發其他幾項功能。
舉例來說,當使用者在 Chrome 網址列中輸入搜尋查詢,以及在 Android 上的搜尋框等其他位置輸入查詢時,Chrome 會為已啟用預先載入功能的使用者推出預先算繪的搜尋結果頁面。其他搜尋引擎也可以實作這項功能 (不只是 Google 搜尋),但我們目前不清楚其他搜尋引擎是否已實作。
Google 搜尋不會進一步實作結果連結的預先算繪,因為這項功能不適用於跨網站導覽 (甚至必須選擇啟用同網站、跨來源的預先算繪)。
瀏覽器支援注意事項
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)

目前 Chromium 架構的瀏覽器已導入 Speculation Rules API,但 Chrome 正在透過 W3C 標準程序發布 API 規格,並希望其他瀏覽器也能導入這項 API。
目前只有 Chrome 實作私密預先擷取 Proxy,其他以 Chromium 為基礎的瀏覽器則未實作。不過,如果其他瀏覽器實作自己的私密預先擷取 Proxy,Google 搜尋也可能會在這些瀏覽器中實作這些改善措施。
由於不使用私密預先擷取 Proxy 進行預先擷取會造成隱私權問題,因此 Google 搜尋不會在不支援這項技術的瀏覽器上預先擷取,也不會針對其他瀏覽器使用其他技術實作備援。不過,由於這是漸進式強化功能,因此這只表示這些瀏覽器的使用者無法享有這項微幅的速度提升。
立即在網站上試用!
所有網站都能使用 Speculation Rules API,不限於 Google 搜尋。除了本文討論的預先擷取功能外,預先算繪還能帶來更多優點,只要在適當的時機和地點使用即可。Google 搜尋等大型網站已證明,這項 API 可明顯提升使用者體驗,因此我們建議所有網站擁有者瞭解如何使用這項 API,並從中獲益。
此外,其他網站也能使用本文詳述的隱私權保護機制,但使用者必須在設定中啟用「擴充預先載入」支援,才能允許非 Google 網站透過 Google 的私密預先擷取 Proxy 轉送流量。這是因為這會在使用者和網站之間引入 Google 做為額外一方,但 Google 網站並不需要這麼做,因為 Google 已經是參與方之一。