

Data publikacji: 2 grudnia 2022 r., ostatnia aktualizacja: 23 stycznia 2026 r.
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)

Zespół Chrome przywrócił pełne renderowanie wstępne przyszłych stron, do których użytkownik prawdopodobnie przejdzie.
Krótka historia wstępnego renderowania
W przeszłości Chrome obsługiwał wskazówkę dotyczącą zasobów <link rel="prerender" href="/next-page">, ale nie była ona powszechnie obsługiwana poza Chrome i nie była zbyt ekspresywnym interfejsem API.
To starsze wstępne renderowanie z użyciem wskazówki linku rel=prerender zostało wycofane na rzecz pobierania z wyprzedzeniem bez stanu, które zamiast tego pobierało zasoby potrzebne przyszłej stronie, ale nie renderowało jej w pełni ani nie wykonywało JavaScriptu. Pobieranie z wyprzedzeniem bez stanu pomaga poprawić wydajność strony, zwiększając szybkość wczytywania zasobów, ale nie zapewnia natychmiastowego wczytywania strony, jak w przypadku pełnego renderowania wstępnego.
Zespół Chrome ponownie wprowadził pełne wstępne renderowanie w Chrome. Aby uniknąć komplikacji związanych z obecnym wykorzystaniem i umożliwić przyszłe rozszerzenie renderowania wstępnego, ten nowy mechanizm renderowania wstępnego nie będzie używać składni <link rel="prerender"...>, która pozostanie w przypadku pobierania z wyprzedzeniem bez stanu. W przyszłości planujemy wycofać tę składnię.
Jak wstępnie renderowana jest strona?
Stronę można wstępnie renderować na 4 sposoby, które mają na celu przyspieszenie nawigacji:
- Gdy wpisujesz adres URL w pasku adresu Chrome (zwanym też omniboksem), Chrome może automatycznie wstępnie renderować stronę, jeśli na podstawie Twojej historii przeglądania uzna, że prawdopodobnie ją odwiedzisz.
- Gdy używasz paska zakładek, Chrome może automatycznie wstępnie renderować stronę, gdy przytrzymasz wskaźnik nad jednym z przycisków zakładek.
- Gdy wpiszesz wyszukiwane hasło na pasku adresu Chrome, Chrome może automatycznie wstępnie renderować stronę wyników wyszukiwania, jeśli wyszukiwarka wyda taką instrukcję.
- Witryny mogą używać interfejsu Speculation Rules API, aby programowo informować Chrome, które strony mają być wstępnie renderowane. Zastępuje to działanie elementu
<link rel="prerender"...>i umożliwia witrynom proaktywne wstępne renderowanie strony na podstawie reguł spekulacyjnych na stronie. Mogą one być statycznie umieszczone na stronach lub dynamicznie wstawiane przez JavaScript zgodnie z uznaniem właściciela strony.
W każdym z tych przypadków wstępne renderowanie działa tak, jakby strona została otwarta na niewidocznej karcie w tle, a następnie została „aktywowana” przez zastąpienie karty na pierwszym planie wstępnie renderowaną stroną. Jeśli strona zostanie aktywowana, zanim w pełni zakończy się wstępne renderowanie, jej bieżący stan to „foregrounded” (na pierwszym planie) i będzie się ona nadal wczytywać. Oznacza to, że nadal możesz uzyskać przewagę.
Ponieważ wstępnie renderowana strona jest otwierana w stanie ukrytym, niektóre interfejsy API, które powodują natrętne zachowania (np. wyświetlanie promptów), nie są w tym stanie aktywowane, ale są opóźniane do momentu aktywacji strony. W nielicznych przypadkach, w których nie jest to jeszcze możliwe, wstępne renderowanie jest anulowane. Zespół Chrome pracuje nad udostępnieniem przyczyn anulowania wstępnego renderowania w formie interfejsu API, a także nad ulepszeniem narzędzi dla programistów, aby ułatwić identyfikowanie takich przypadków brzegowych.
Wpływ renderowania wstępnego
Wstępne renderowanie umożliwia niemal natychmiastowe wczytanie strony, co widać na tym filmie:
Przykładowa witryna działa już szybko, ale nawet w tym przypadku widać, jak renderowanie wstępne poprawia wygodę użytkowników. Może to mieć bezpośredni wpływ na podstawowe wskaźniki internetowe witryny, ponieważ LCP będzie bliskie zera, CLS zostanie zmniejszone (ponieważ wszelkie CLS wczytywania wystąpi przed pierwszym wyświetleniem), a INP ulegnie poprawie (ponieważ wczytywanie powinno zostać zakończone przed interakcją użytkownika).
Nawet jeśli strona aktywuje się przed pełnym wczytaniem, wcześniejsze rozpoczęcie wczytywania strony powinno poprawić komfort korzystania z niej. Gdy link zostanie aktywowany podczas wstępnego renderowania, wstępnie renderowana strona zostanie przeniesiona do ramki głównej i będzie się dalej wczytywać.
Wstępne renderowanie wykorzystuje jednak dodatkową pamięć i przepustowość sieci. Uważaj, aby nie wykonywać zbyt wielu wstępnych renderowań, co może obciążać zasoby użytkownika. Wstępne renderowanie tylko wtedy, gdy istnieje duże prawdopodobieństwo, że użytkownik przejdzie na stronę.
Więcej informacji o tym, jak mierzyć rzeczywisty wpływ na skuteczność w statystykach, znajdziesz w sekcji Mierzenie skuteczności.
Wyświetlanie sugestii na pasku adresu Chrome
W pierwszym przypadku użycia możesz wyświetlić prognozy Chrome dotyczące adresów URL na stronie chrome://predictors:
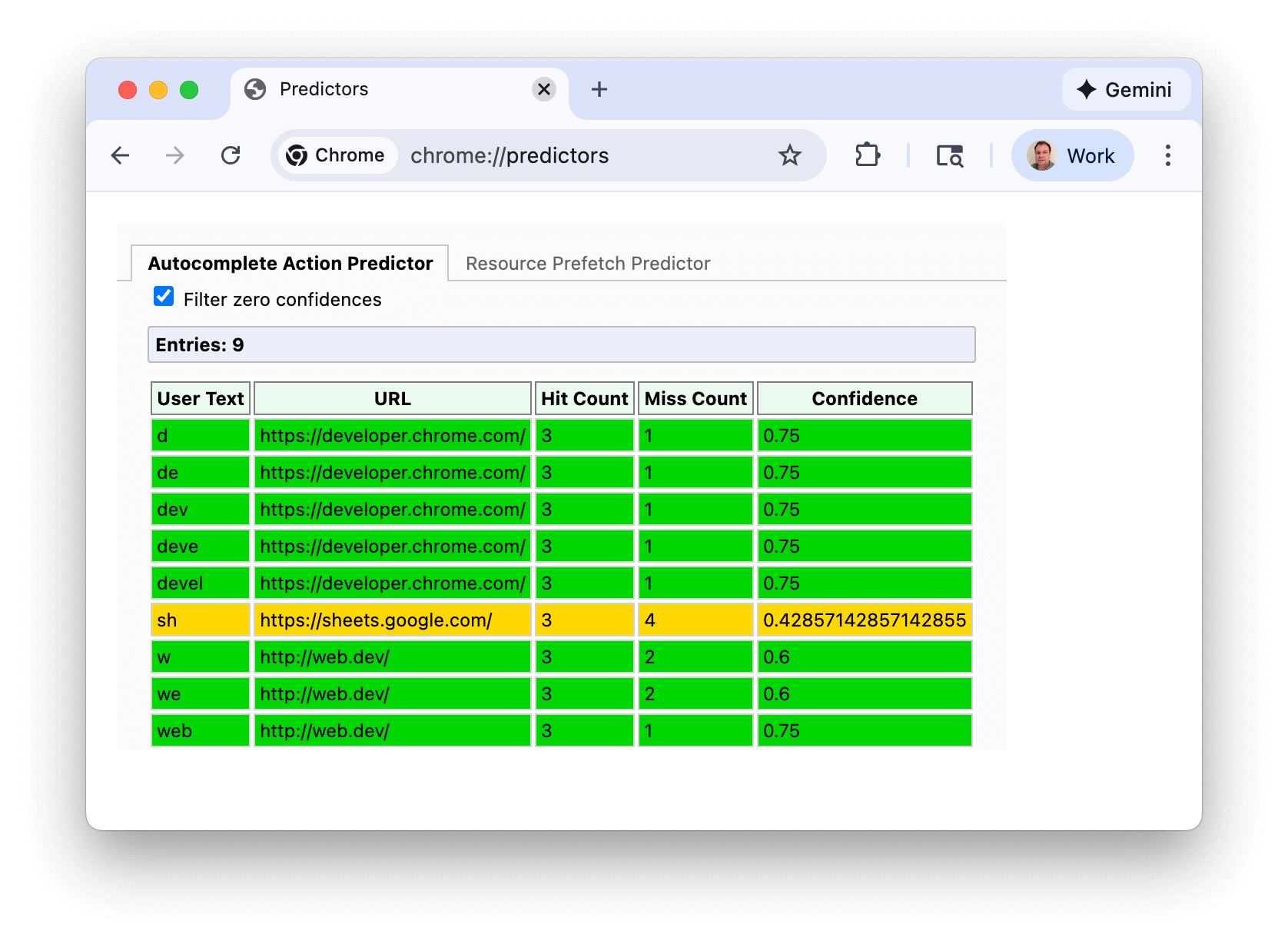
Zielone linie oznaczają wystarczającą pewność, aby wywołać wstępne renderowanie. W tym przykładzie wpisanie litery „s” daje rozsądną pewność (kolor bursztynowy), ale po wpisaniu „sh” Chrome ma wystarczającą pewność, że prawie zawsze przechodzisz do https://sheets.google.com.
Ten zrzut ekranu został zrobiony w stosunkowo nowej instalacji Chrome i zawiera prognozy z wykluczonymi wynikami o zerowej ufności. Jeśli jednak wyświetlisz własne predyktory, zobaczysz znacznie więcej wpisów i prawdopodobnie więcej znaków wymaganych do osiągnięcia wystarczająco wysokiego poziomu ufności.
Te predyktory są też odpowiedzialne za sugerowane opcje na pasku adresu, które mogłeś(-aś) zauważyć:
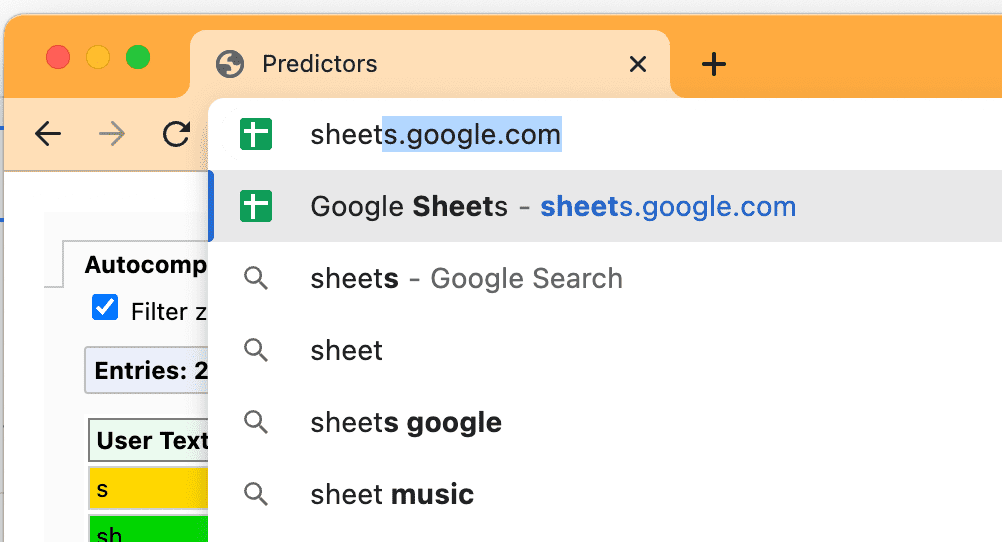
Chrome będzie stale aktualizować swoje predyktory na podstawie Twojego pisania i wyborów.
- Jeśli poziom ufności jest wyższy niż 30% (kolor bursztynowy), Chrome aktywnie nawiązuje wstępne połączenie z domeną, ale nie renderuje wstępnie strony.
- Jeśli poziom ufności jest wyższy niż 50% (wyświetlany na zielono), Chrome wstępnie renderuje adres URL.
Speculation Rules API
W przypadku opcji wstępnego renderowania interfejsu Speculation Rules API programiści witryn mogą wstawiać na stronach instrukcje JSON, aby informować przeglądarkę o tym, które adresy URL mają być wstępnie renderowane.
Lista adresów URL
Reguły spekulacyjne mogą być oparte na listach adresów URL:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Reguły dotyczące dokumentów
Reguły spekulacyjne mogą być też „regułami dokumentu” używającymi składni where. Ta specyfikacja zawiera linki znalezione w dokumencie na podstawie selektorów href (opartych na interfejsie URL Pattern API) lub selektorów CSS:
<script type="speculationrules">
{
"prerender": [{
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/wp-admin"}},
{ "not": {"href_matches": "/*\\?*(^|&)add-to-cart=*"}},
{ "not": {"selector_matches": ".do-not-prerender"}},
{ "not": {"selector_matches": "[rel~=nofollow]"}}
]
}
}]
}
</script>
chęć,
Ustawienie eagerness służy do określania, kiedy mają się uruchamiać spekulacje. Jest to szczególnie przydatne w przypadku reguł dotyczących dokumentów:
conservative: – spekulacja dotycząca naciśnięcia wskaźnika lub ekranu dotykowego.moderate: na komputerach stacjonarnych spekulacje są wykonywane, jeśli wskaźnik myszy jest przytrzymywany nad linkiem przez 200 milisekund (lub w przypadku zdarzeniapointerdown, jeśli nastąpi wcześniej, a na urządzeniach mobilnych, na których nie ma zdarzeniahover). W przypadku urządzeń mobilnych od sierpnia 2025 r. będziemy opierać się na złożonych heurystykach widocznego obszaru. Złożone heurystyki widocznego obszaru są uruchamiane 500 ms po tym, jak użytkownik przestał przewijać, w przypadku elementów zakotwiczenia znajdujących się w odległości pionowej mniejszej niż 30% od poprzedniego wskaźnika w dół, gdzie elementy zakotwiczenia są co najmniej 0,5 raza większe niż największy element zakotwiczenia w widocznym obszarze. Zgodnie z opisem w tym dokumencie.eager: ta wartość była wcześniej identyczna zimmediate, ale w Chrome 143 uległa zmianie. Na komputerze stacjonarnym spekulacje są wykonywane, jeśli wskaźnik jest przytrzymywany nad linkiem przez 10 milisekund. Od stycznia 2026 r. na urządzeniach mobilnych będziemy opierać się na prostej heurystyce widocznego obszaru. Proste heurystyki widocznego obszaru są wywoływane 50 ms po tym, jak element zakotwiczenia pojawi się w widocznym obszarze.immediate: ta wartość służy do spekulacji tak szybko, jak to możliwe, czyli od razu po zaobserwowaniu reguł spekulacyjnych.
Domyślna wartość eagerness dla reguł list to immediate. Opcje eager, moderate i conservative można wykorzystać do ograniczenia reguł list do adresów URL, z którymi użytkownik wchodzi w interakcję, do określonej listy. W wielu przypadkach bardziej odpowiednie mogą być jednak document reguły z odpowiednim warunkiem where.
Domyślna wartość eagerness dla reguł document to conservative. Ponieważ dokument może zawierać wiele adresów URL, używanie tagu immediate w przypadku reguł document powinno być ostrożne (patrz też sekcja Limity Chrome poniżej).
Które ustawienie eagerness wybrać, zależy od Twojej witryny. W przypadku lekkiej, statycznej witryny bardziej agresywne spekulowanie może być mało kosztowne i korzystne dla użytkowników. Witryny o bardziej złożonej architekturze i większych rozmiarach stron mogą ograniczyć marnotrawstwo, rzadziej spekulując, dopóki nie uzyskają od użytkowników bardziej pozytywnego sygnału intencji.
Opcja moderate to rozwiązanie pośrednie. Wiele witryn może skorzystać z tej reguły spekulacji, która wstępnie renderuje link, gdy wskaźnik jest nad nim przez 200 milisekund lub gdy wystąpi zdarzenie pointerdown. Jest to podstawowe, ale skuteczne wdrożenie reguł spekulacji:
<script type="speculationrules">
{
"prerender": [{
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Pobieranie z wyprzedzeniem
Reguły spekulacyjne mogą też służyć tylko do pobierania stron z wyprzedzeniem bez pełnego wstępnego renderowania. Może to być dobry pierwszy krok na drodze do wstępnego renderowania:
<script type="speculationrules">
{
"prefetch": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Renderuj do skryptu
Zespół Chrome pracuje też nad dodaniem prerender_until_script do interfejsu Speculation Rules API (zobacz błąd implementacji). Byłby to krok pośredni między pobieraniem z wyprzedzeniem a wstępnym renderowaniem i byłby używany w podobny sposób:
<script type="speculationrules">
{
"prerender_until_script": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Podobnie jak w przypadku NoState prefetch, ta dyrektywa wstępnie pobiera dokument HTML oraz podzasoby dostępne w tym dokumencie. Jednak w tym przypadku przeglądarka zacznie też wstępnie renderować stronę i zatrzyma się, gdy napotka pierwszy skrypt.
Oznacza to, że w przypadku stron bez JavaScriptu lub z JavaScriptem tylko w stopce strona może być prawie w całości wstępnie renderowana. Strony ze skryptami w <head> nie będą mogły być wstępnie renderowane, ale nadal będą korzystać z pobierania zasobów podrzędnych.
Pozwoli to uniknąć ryzyka niezamierzonych skutków ubocznych wynikających z wykonywania kodu JavaScript, ale zapewni znacznie większy wzrost wydajności niż tylko prefetch.
Limity Chrome
Chrome ma limity, które zapobiegają nadmiernemu używaniu interfejsu Speculation Rules API:
| zapał, | Pobieranie z wyprzedzeniem | Prerender |
|---|---|---|
immediate |
50 | 10 |
eager / moderate / conservative |
2 (FIFO) | 2 (FIFO) |
Ustawienia eager, moderate i conservative, które zależą od interakcji użytkownika, działają w kolejności FIFO: po osiągnięciu limitu nowa spekulacja spowoduje anulowanie najstarszej spekulacji i zastąpienie jej nowszą, aby oszczędzać pamięć. Anulowane spekulacje można ponownie wywołać, np. przez ponowne najechanie kursorem na dany link. Spowoduje to ponowne spekulowanie tego adresu URL i usunięcie najstarszej spekulacji. W takim przypadku poprzednie spekulatywne pobieranie spowoduje zapisanie w pamięci podręcznej HTTP wszystkich zasobów, które można zapisać w pamięci podręcznej dla tego adresu URL, więc kolejne spekulatywne pobieranie powinno być mniej kosztowne. Dlatego limit został ustawiony na skromny próg 2. Reguły listy statycznej nie są wywoływane przez działanie użytkownika, więc mają wyższy limit, ponieważ przeglądarka nie może wiedzieć, które z nich są potrzebne i kiedy.
Chrome rozważa też zwiększenie limitu do 5 na urządzeniach mobilnych w przypadku eager i moderate, przynajmniej w przypadku wstępnego pobierania, ponieważ jest to mniej precyzyjna heurystyka. Deweloperzy korzystający z eager mogą rozważyć użycie dodatkowo reguł conservative, gdy w obszarze widoku jest dostępnych wiele linków. Dzięki temu spekulatywne wczytywanie będzie działać nawet wtedy, gdy link nie zostanie wybrany jako jeden z pierwszych dwóch.
Limit immediate jest też dynamiczny, więc usunięcie elementu skryptu adresu URL list zwiększy pojemność, ponieważ anuluje usunięte spekulacje.
Chrome będzie też zapobiegać używaniu spekulacji w określonych warunkach, w tym:
- Save-Data.
- Oszczędzanie energii, gdy jest włączone i bateria jest bliska rozładowania.
- Ograniczenia pamięci.
- Gdy ustawienie „Wstępnie wczytuj strony” jest wyłączone (co jest też wyraźnie wyłączane przez rozszerzenia Chrome, takie jak uBlock Origin).
- Strony otwarte na kartach w tle.
Chrome nie renderuje też w przypadku wstępnie renderowanych stron elementów iframe z innych domen do momentu aktywacji.
Wszystkie te warunki mają na celu ograniczenie wpływu nadmiernej spekulacji, gdy jest ona szkodliwa dla użytkowników.
Jak uwzględnić na stronie reguły spekulacyjne
Reguły spekulacyjne można statycznie umieścić w kodzie HTML strony lub dynamicznie wstawić na stronie za pomocą JavaScriptu:
- Statycznie uwzględnione reguły spekulacji: na przykład witryna z wiadomościami lub blog może wstępnie renderować najnowszy artykuł, jeśli często jest on kolejnym miejscem docelowym dla dużej części użytkowników. Można też używać reguł dokumentu z wartościami
moderatelubconservative, aby spekulować na podstawie interakcji użytkowników z linkami. - Dynamicznie wstawiane reguły spekulacji: mogą być oparte na logice aplikacji, spersonalizowane pod kątem użytkownika lub oparte na innych heurystykach.
Osobom, które wolą dynamiczne wstawianie na podstawie działań takich jak najechanie kursorem lub kliknięcie linku (wiele bibliotek w przeszłości korzystało z <link rel=prefetch>), zalecamy zapoznanie się z regułami dokumentu, ponieważ umożliwiają one przeglądarce obsługę wielu przypadków użycia.
Reguły spekulacji można dodawać w <head> lub <body> w głównej ramce. Reguły spekulacyjne w ramkach podrzędnych nie są wykonywane, a reguły spekulacyjne na wstępnie renderowanych stronach są wykonywane dopiero po aktywowaniu tej strony.
Nagłówek HTTP Speculation-Rules
Reguły spekulacyjne można też dostarczać za pomocą Speculation-Rules nagłówka HTTP, zamiast umieszczać je bezpośrednio w HTML dokumentu. Ułatwia to wdrażanie przez sieci CDN bez konieczności zmiany zawartości dokumentów.
Nagłówek HTTP Speculation-Rules jest zwracany z dokumentem i wskazuje lokalizację pliku JSON zawierającego reguły spekulacji:
Speculation-Rules: "/speculationrules.json"
Ten zasób musi używać prawidłowego typu MIME i w przypadku zasobu pochodzącego z innej domeny musi przejść sprawdzanie CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Jeśli chcesz używać względnych adresów URL, możesz uwzględnić klucz "relative_to": "document" w regułach spekulacji. W przeciwnym razie adresy URL będą względne względem adresu URL pliku JSON z regułami spekulacji. Może to być szczególnie przydatne, jeśli musisz wybrać niektóre lub wszystkie linki z tej samej domeny.
Pole tagu reguł spekulacyjnych
W składni JSON reguł spekulacyjnych można też dodać „tagi” na poziomie ogólnym dla wszystkich reguł spekulacyjnych w zestawie reguł:
{
"tag": "my-rules",
"prefetch": [
"urls": ["next.html"]
],
"prerender": [
"urls": ["next2.html"]
],
}
lub na poziomie poszczególnych reguł:
{
"prefetch": [
"urls": ["next.html"],
"tag": "my-prefetch-rules"
],
"prerender": [
"urls": ["next2.html"],
"tag": "my-prerender-rules"
],
}
Ten tag jest następnie odzwierciedlany w nagłówku HTTP Sec-Speculation-Tags, którego można używać do filtrowania reguł spekulacji na serwerze. Nagłówek HTTP Sec-Speculation-Tags może zawierać wiele tagów, jeśli spekulacja jest objęta kilkoma regułami, jak pokazano w tym przykładzie:
Sec-Speculation-Tags: null
Sec-Speculation-Tags: null, "cdn-prefetch"
Sec-Speculation-Tags: "my-prefetch-rules"
Sec-Speculation-Tags: "my-prefetch-rules", "my-rules", "cdn-prefetch"
Niektóre sieci CDN automatycznie wstawiają reguły spekulacji, ale blokują spekulacje w przypadku stron, które nie są buforowane na serwerach brzegowych, aby uniknąć zwiększenia wykorzystania serwera źródłowego. Tagi umożliwiają im identyfikowanie spekulacji zainicjowanych przez domyślny zestaw reguł, ale nadal zezwalają na przekazywanie do źródła wszelkich reguł dodanych przez witrynę.
Tagi zestawu reguł są też wyświetlane w Narzędziach deweloperskich w Chrome.
Pole Reguły spekulacyjnetarget_hint
Reguły spekulacji mogą też zawierać pole target_hint, które zawiera prawidłową nazwę kontekstu przeglądania lub słowo kluczowe wskazujące, gdzie strona oczekuje aktywacji wstępnie wyrenderowanej treści:
<script type=speculationrules>
{
"prerender": [{
"target_hint": "_blank",
"urls": ["next.html"]
}]
}
</script>
Ta wskazówka umożliwia obsługę spekulacji dotyczących wstępnego renderowania w przypadku linków target="_blank":
<a target="_blank" href="next.html">Open this link in a new tab</a>
Obecnie w Chrome obsługiwane są tylko wartości "target_hint": "_blank" i "target_hint": "_self" (domyślna, jeśli nie podano innej) i tylko w przypadku wstępnego renderowania – pobieranie wstępne nie jest obsługiwane.
target_hint jest potrzebny tylko w przypadku urls reguł spekulacji, ponieważ w przypadku reguł dokumentów target jest znany z samego linku.
Reguły spekulacyjne i SPA
Reguły spekulacyjne są obsługiwane tylko w przypadku nawigacji po pełnych stronach zarządzanych przez przeglądarkę, a nie w przypadku aplikacji jednostronicowych (SPA) ani stron szkieletu aplikacji. W przypadku tych architektur nie pobiera się dokumentów, ale wykonuje się wywołania API lub częściowe pobieranie danych lub stron, które są następnie przetwarzane i wyświetlane na bieżącej stronie. Dane potrzebne do tzw. „miękkich nawigacji” mogą być wstępnie pobierane przez aplikację poza regułami spekulacji, ale nie mogą być wstępnie renderowane.
Reguły spekulacyjne mogą służyć do wstępnego renderowania samej aplikacji ze strony poprzedniej. Może to pomóc zrekompensować niektóre dodatkowe koszty początkowego wczytywania, które występują w przypadku niektórych aplikacji SPA. Zmian trasy w aplikacji nie można jednak wstępnie renderować.
Debugowanie reguł spekulacyjnych
Zapoznaj się z postem poświęconym debugowaniu reguł spekulacyjnych, aby poznać nowe funkcje narzędzi deweloperskich w Chrome, które pomagają w wyświetlaniu i debugowaniu tego nowego interfejsu API.
Wiele reguł spekulacyjnych
Do tej samej strony można też dodać wiele reguł spekulacyjnych, które zostaną dołączone do istniejących reguł. Dlatego wszystkie poniższe sposoby powodują wstępne renderowanie zarówno one.html, jak i two.html:
Lista adresów URL:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html", "two.html"]
}
]
}
</script>
Wiele skryptów speculationrules:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html"]
}
]
}
</script>
<script type="speculationrules">
{
"prerender": [
{
"urls": ["two.html"]
}
]
}
</script>
Wiele list w jednym zbiorze speculationrules
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html"]
},
{
"urls": ["two.html"]
}
]
}
</script>
No-Vary-Search – pomoc
Podczas wstępnego pobierania lub renderowania wstępnego strony niektóre parametry URL (technicznie zwane parametrami wyszukiwania) mogą być nieistotne dla strony faktycznie dostarczanej przez serwer i używane tylko przez JavaScript po stronie klienta.
Na przykład parametry UTM są używane przez Google Analytics do pomiaru skuteczności kampanii, ale zwykle nie powodują, że serwer dostarcza różne strony. Oznacza to, że page1.html?utm_content=123 i page1.html?utm_content=456 będą dostarczać tę samą stronę z serwera, więc tę samą stronę można ponownie wykorzystać z pamięci podręcznej.
Podobnie aplikacje mogą używać innych parametrów adresu URL, które są obsługiwane tylko po stronie klienta.
Propozycja No-Vary-Search umożliwia serwerowi określenie parametrów, które nie powodują różnicy w dostarczanym zasobie, a tym samym pozwalają przeglądarce na ponowne użycie wcześniej zapisanych w pamięci podręcznej wersji dokumentu, które różnią się tylko tymi parametrami. Jest to obsługiwane w Chrome (i przeglądarkach opartych na Chromium) w przypadku spekulacji dotyczących nawigacji zarówno w przypadku wstępnego pobierania, jak i wstępnego renderowania.
Reguły spekulacyjne obsługują używanie expects_no_vary_search do wskazywania, gdzie ma być zwracany nagłówek HTTP No-Vary-Search. Może to pomóc w uniknięciu niepotrzebnych pobrań przed wyświetleniem odpowiedzi.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
W tym przykładzie /products początkowy kod HTML strony jest taki sam w przypadku obu identyfikatorów produktów 123 i 124. Zawartość strony różni się jednak w zależności od renderowania po stronie klienta, które wykorzystuje JavaScript do pobierania danych o produktach za pomocą parametru wyszukiwania id. Dlatego wstępnie pobieramy ten adres URL i powinien on zwracać nagłówek HTTP No-Vary-Search wskazujący, że strona może być używana w przypadku dowolnego parametru wyszukiwania id.
Jeśli jednak użytkownik kliknie którykolwiek z linków przed zakończeniem wstępnego pobierania, przeglądarka może nie otrzymać strony /products. W tym przypadku przeglądarka nie wie, czy będzie zawierać nagłówek HTTP No-Vary-Search. Przeglądarka musi wtedy zdecydować, czy ponownie pobrać link, czy poczekać na zakończenie wstępnego pobierania, aby sprawdzić, czy zawiera on nagłówek HTTP No-Vary-Search. Ustawienie expects_no_vary_search informuje przeglądarkę, że odpowiedź strony powinna zawierać nagłówek HTTP No-Vary-Search, i nakazuje jej poczekać na zakończenie wstępnego pobierania.
Możesz też dodać do expects_no_vary_search kilka parametrów, rozdzielając je spacją (ponieważ No-Vary-Search jest nagłówkiem strukturalnym HTTP):
"expects_no_vary_search": "params=(\"param1\" \"param2\" \"param3\")"
Ograniczenia reguł spekulacyjnych i przyszłe ulepszenia
Reguły spekulacyjne są ograniczone do stron otwieranych w tej samej karcie, ale pracujemy nad zmniejszeniem tego ograniczenia.
Domyślnie wstępne renderowanie jest ograniczone do stron z tej samej domeny. Można włączyć renderowanie wstępne stron z tej samej witryny i innej domeny (np. https://a.example.com może wstępnie wyrenderować stronę w https://b.example.com). Aby użyć spekulowanej strony (w tym przykładzie https://b.example.com), musisz wyrazić na to zgodę, dodając nagłówek HTTP Supports-Loading-Mode: credentialed-prerender. W przeciwnym razie Chrome anuluje spekulację.
W przyszłych wersjach może być też dozwolone wstępne renderowanie stron z innych witryn i domen, o ile nie ma plików cookie dla wstępnie renderowanej strony, a strona ta wyrazi zgodę za pomocą podobnego nagłówka HTTP Supports-Loading-Mode: uncredentialed-prerender.
Reguły spekulacyjne obsługują już pobieranie z wyprzedzeniem z innych domen. W przypadku pobierania z wyprzedzeniem z innych domen w tej samej witrynie nie ma ograniczeń. Wstępne pobieranie z innej witryny i innego pochodzenia jest obsługiwane tylko wtedy, gdy nie ma plików cookie dla domeny innego pochodzenia. Jeśli użytkownik odwiedził już wcześniej tę witrynę i istnieją pliki cookie, spekulacja nie zostanie użyta i w Narzędziach deweloperskich pojawi się błąd.
Biorąc pod uwagę obecne ograniczenia, jednym ze wzorców, który może poprawić wrażenia użytkowników zarówno w przypadku linków wewnętrznych, jak i zewnętrznych (w miarę możliwości), jest wstępne renderowanie adresów URL z tej samej domeny i próba wstępnego pobierania adresów URL z innej domeny:
<script type="speculationrules">
{
"prerender": [
{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}
],
"prefetch": [
{
"where": { "not": { "href_matches": "/*" } },
"eagerness": "moderate"
}
]
}
</script>
Ograniczenie domyślnego zapobiegania spekulacjom dotyczącym linków do innych domen jest niezbędne ze względów bezpieczeństwa. Jest to ulepszenie funkcji <link rel="prefetch"> w przypadku miejsc docelowych z innej domeny, które również nie będą wysyłać plików cookie, ale nadal będą próbować wstępnego pobierania. Może to spowodować zmarnowanie wstępnego pobierania, które trzeba będzie wysłać ponownie, lub, co gorsza, załadowanie nieprawidłowej strony.
Obsługa interfejsu Detect Speculation Rules API
Obsługę interfejsu Speculation Rules API możesz wykryć za pomocą standardowych testów HTML:
if (HTMLScriptElement.supports && HTMLScriptElement.supports('speculationrules')) {
console.log('Your browser supports the Speculation Rules API.');
}
Dynamiczne dodawanie reguł spekulacyjnych za pomocą JavaScriptu
Oto przykład dodawania reguły spekulacji prerender za pomocą kodu JavaScript:
if (HTMLScriptElement.supports &&
HTMLScriptElement.supports('speculationrules')) {
const specScript = document.createElement('script');
specScript.type = 'speculationrules';
specRules = {
prerender: [
{
urls: ['/next.html'],
},
],
};
specScript.textContent = JSON.stringify(specRules);
console.log('added speculation rules to: next.html');
document.body.append(specScript);
}
Wersję demonstracyjną wstępnego renderowania za pomocą interfejsu Speculation Rules API z użyciem wstawiania JavaScriptu możesz zobaczyć na tej stronie demonstracyjnej wstępnego renderowania.
Wstawienie elementu <script type = "speculationrules"> bezpośrednio do DOM za pomocą innerHTML nie spowoduje zarejestrowania reguł spekulacyjnych ze względów bezpieczeństwa. Należy je dodać w sposób pokazany wcześniej. Treści wstawione dynamicznie za pomocą innerHTML, które zawierają nowe linki, będą jednak uwzględniane przez istniejące reguły na stronie.
Podobnie bezpośrednie edytowanie panelu Elementy w Narzędziach deweloperskich Chrome w celu dodania elementu <script type = "speculationrules"> nie powoduje zarejestrowania reguł spekulacyjnych. Zamiast tego skrypt dynamicznego dodawania tego elementu do DOM musi zostać uruchomiony z konsoli, aby wstawić reguły.
Dodawanie reguł spekulacyjnych za pomocą menedżera tagów
Aby dodać reguły spekulacyjne za pomocą menedżera tagów, np. Menedżera tagów Google (GTM), musisz wstawić je za pomocą JavaScriptu, a nie bezpośrednio przez GTM, z tych samych powodów, które zostały wymienione wcześniej:<script type = "speculationrules">
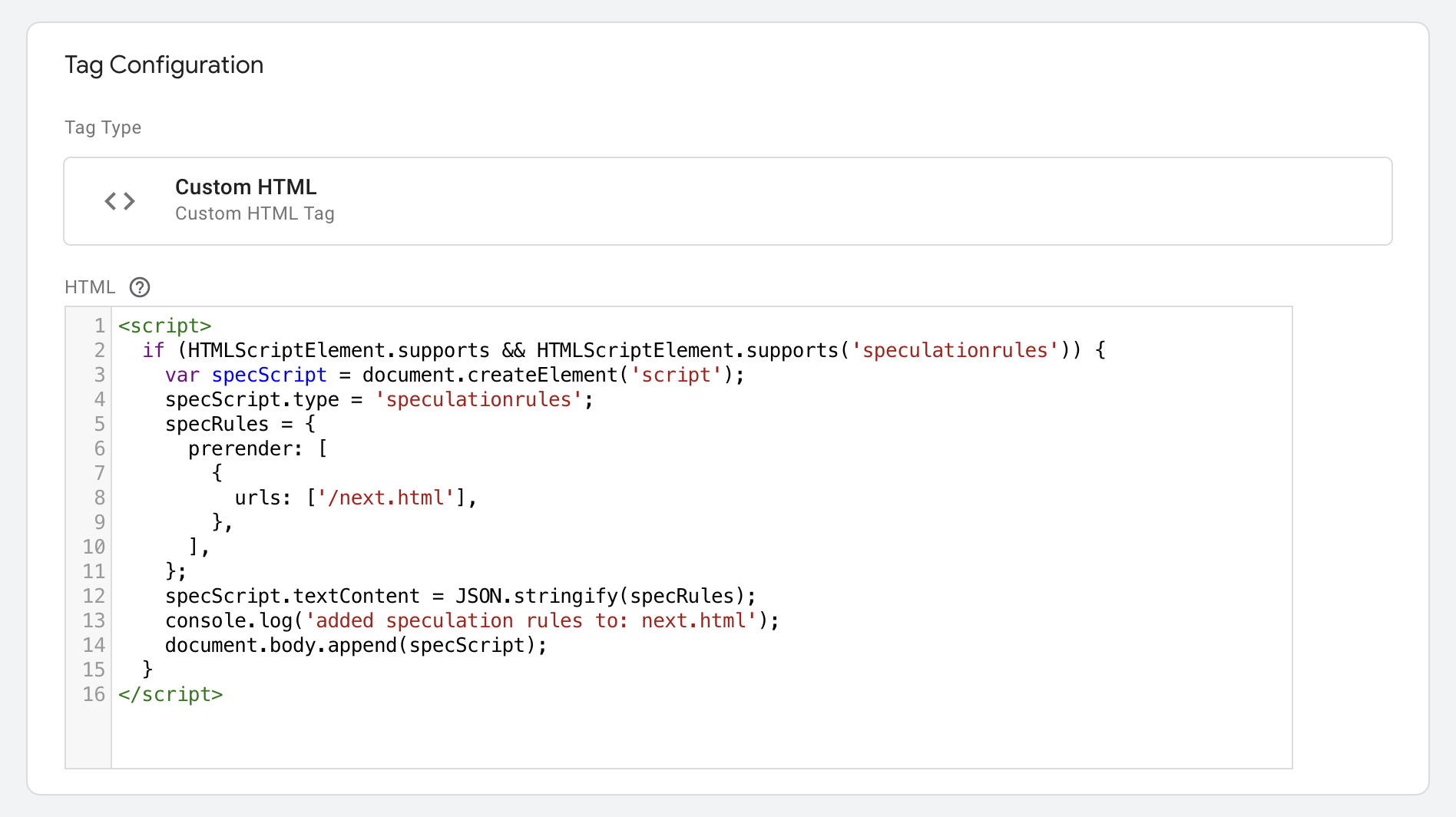
Uwaga: w tym przykładzie użyto znaku var, ponieważ Menedżer tagów Google nie obsługuje znaku const.
Anulowanie reguł spekulacyjnych
Usunięcie reguł spekulacyjnych spowoduje anulowanie renderowania wstępnego. Zanim jednak to nastąpi, prawdopodobnie zostaną już wykorzystane zasoby na zainicjowanie wstępnego renderowania, dlatego nie zalecamy wstępnego renderowania, jeśli istnieje prawdopodobieństwo, że trzeba będzie je anulować. Z drugiej strony zasoby w pamięci podręcznej mogą być nadal używane, więc anulowania nie są całkowicie bezużyteczne i mogą nadal przynosić korzyści w przyszłości.
Spekulacje można też anulować za pomocą nagłówka HTTP Clear-Site-Data z dyrektywami prefetchCache i prerenderCache.
Może to być przydatne, gdy stan zmienia się na serwerze. Na przykład podczas wywoływania interfejsu API „add-to-basket” (dodaj do koszyka) lub interfejsu API logowania lub wylogowywania.
W idealnej sytuacji te aktualizacje stanu byłyby propagowane do wstępnie renderowanych stron za pomocą interfejsów API, takich jak Broadcast Channel API, ale tam, gdzie nie jest to możliwe lub dopóki taka logika nie zostanie wdrożona, łatwiej może być anulować spekulację.
Zasady dotyczące spekulacji i zasady bezpieczeństwa treści
Reguły spekulacyjne używają elementu <script>, więc nawet jeśli zawierają tylko kod JSON, muszą być uwzględnione w zasadach script-src Content-Security-Policy, jeśli witryna ich używa – za pomocą skrótu lub liczby jednorazowej.
Do script-src można dodać nowy inline-speculation-rules, co umożliwi obsługę elementów <script type="speculationrules"> wstrzykiwanych ze skryptów z haszem lub nonce. Nie obsługuje to reguł zawartych w początkowym kodzie HTML, więc w przypadku witryn, które używają ścisłej zasady CSP, reguły muszą być wstrzykiwane przez JavaScript.
Wykrywanie i wyłączanie renderowania wstępnego
Wstępne renderowanie zwykle zapewnia użytkownikom pozytywne wrażenia, ponieważ umożliwia szybkie, a często natychmiastowe renderowanie strony. Jest to korzystne zarówno dla użytkownika, jak i właściciela witryny, ponieważ wstępnie renderowane strony zapewniają większą wygodę, którą w inny sposób trudno byłoby osiągnąć.
Może się jednak zdarzyć, że nie chcesz wstępnego renderowania stron, np. gdy zmieniają one stan na podstawie początkowego żądania lub kodu JavaScript wykonanego na stronie.
Włączanie i wyłączanie wstępnego renderowania w Chrome
Wstępne renderowanie jest włączone tylko w przypadku użytkowników Chrome, którzy mają włączone ustawienie „Wstępne wczytywanie stron” w sekcji chrome://settings/performance/. Dodatkowo wstępne renderowanie jest wyłączone na urządzeniach z małą ilością pamięci lub gdy system operacyjny jest w trybie oszczędzania danych lub energii. Zapoznaj się z sekcją Limity Chrome.
Wykrywanie i wyłączanie wstępnego renderowania po stronie serwera
Wstępnie renderowane strony będą wysyłane z nagłówkiem HTTP Sec-Purpose:
Sec-Purpose: prefetch;prerender
W przypadku stron pobranych z wyprzedzeniem za pomocą interfejsu Speculation Rules API ten nagłówek będzie miał wartość prefetch:
Sec-Purpose: prefetch
Serwery mogą odpowiadać na podstawie tego nagłówka, aby rejestrować żądania spekulacyjne, zwracać różne treści lub zapobiegać wstępnemu renderowaniu. Jeśli zostanie zwrócony kod odpowiedzi końcowej inny niż kod powodzenia (czyli po przekierowaniach nie będzie to kod z zakresu 200–299), strona nie zostanie wstępnie wyrenderowana, a wszystkie wstępnie pobrane strony zostaną odrzucone. Pamiętaj też, że odpowiedzi 204 i 205 nie są dodatkowo prawidłowe w przypadku wstępnego renderowania, ale są prawidłowe w przypadku wstępnego pobierania.
Jeśli nie chcesz, aby dana strona była wstępnie renderowana, najlepszym sposobem na to jest zwrócenie kodu odpowiedzi innego niż 2XX (np. 503). Aby jednak zapewnić jak najlepsze wrażenia, zalecamy zezwolenie na renderowanie wstępne, ale opóźnienie za pomocą JavaScriptu wszelkich działań, które powinny być wykonywane tylko wtedy, gdy strona jest rzeczywiście wyświetlana.
Wykrywanie wstępnego renderowania w JavaScript
Interfejs document.prerendering API będzie zwracać wartość true podczas wstępnego renderowania strony. Strony mogą używać tego interfejsu API, aby zapobiegać wykonywaniu niektórych działań podczas wstępnego renderowania lub opóźniać je do momentu aktywowania strony.
Gdy wstępnie renderowany dokument zostanie aktywowany, wartość PerformanceNavigationTimingactivationStart zostanie ustawiona na czas niezerowy, który będzie oznaczać czas między rozpoczęciem wstępnego renderowania a faktyczną aktywacją dokumentu.
Możesz mieć funkcję sprawdzającą wstępne renderowanie i wstępnie renderowane strony, np. taką:
function pagePrerendered() {
return (
document.prerendering ||
self.performance?.getEntriesByType?.('navigation')[0]?.activationStart > 0
);
}
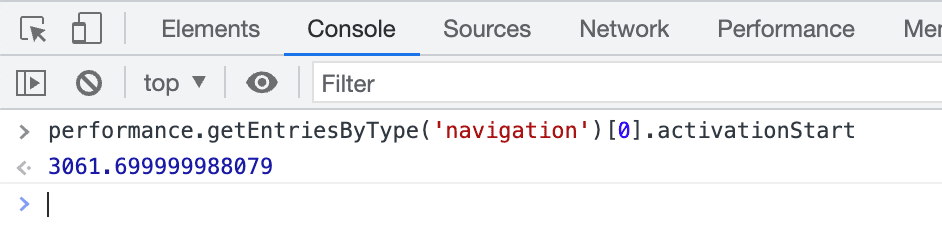
Najprostszym sposobem sprawdzenia, czy strona została wstępnie wyrenderowana (w całości lub częściowo), jest otwarcie Narzędzi deweloperskich po aktywowaniu strony i wpisanie w konsoli performance.getEntriesByType('navigation')[0].activationStart. Jeśli zostanie zwrócona wartość różna od zera, oznacza to, że strona została wstępnie wyrenderowana:
Gdy użytkownik wyświetli stronę, zostanie wysłane zdarzenie prerenderingchange na document. Możesz go użyć do włączania działań, które wcześniej były domyślnie uruchamiane po wczytaniu strony, ale które chcesz opóźnić do momentu, gdy użytkownik faktycznie wyświetli stronę.
Za pomocą tych interfejsów API JavaScript interfejsu użytkownika może wykrywać wstępnie renderowane strony i odpowiednio reagować na nie.
Wpływ na statystyki
Analityka służy do pomiaru korzystania z witryny, np. za pomocą Google Analytics do pomiaru odsłon i zdarzeń. Możesz też mierzyć wskaźniki wydajności stron za pomocą monitorowania rzeczywistych użytkowników (RUM).
Strony powinny być wstępnie renderowane tylko wtedy, gdy istnieje duże prawdopodobieństwo, że użytkownik je wczyta. Dlatego opcje wstępnego renderowania na pasku adresu Chrome są dostępne tylko wtedy, gdy prawdopodobieństwo jest wysokie (ponad 80% czasu).
Jednak w przypadku korzystania z interfejsu Speculation Rules API wstępnie renderowane strony mogą mieć wpływ na statystyki, a właściciele witryn mogą musieć dodać dodatkowy kod, aby włączyć statystyki dotyczące wstępnie renderowanych stron tylko po ich aktywacji, ponieważ nie wszyscy dostawcy usług analitycznych mogą to robić domyślnie.
Można to osiągnąć za pomocą Promise, który czeka na zdarzenie prerenderingchange, jeśli dokument jest wstępnie renderowany, lub rozwiązuje problem natychmiast, jeśli jest już renderowany:
// Set up a promise for when the page is activated,
// which is needed for prerendered pages.
const whenActivated = new Promise((resolve) => {
if (document.prerendering) {
document.addEventListener('prerenderingchange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenActivated;
// Initialise your analytics
}
initAnalytics();
Innym podejściem jest opóźnienie działań analitycznych do momentu, gdy strona stanie się widoczna po raz pierwszy. Obejmuje to zarówno renderowanie wstępne, jak i otwieranie kart w tle (np. po kliknięciu prawym przyciskiem myszy i wybraniu opcji „Otwórz w nowej karcie”):
// Set up a promise for when the page is first made visible
const whenFirstVisible = new Promise((resolve) => {
if (document.hidden) {
document.addEventListener('visibilitychange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenFirstVisible;
// Initialise your analytics
}
initAnalytics();
Może to mieć sens w przypadku analityki i podobnych zastosowań, ale w innych przypadkach możesz chcieć, aby wczytywało się więcej treści, i dlatego możesz użyć tagów document.prerendering i prerenderingchange, aby kierować reklamy na strony renderowane wstępnie.
Wstrzymywanie wczytywania innych treści podczas renderowania wstępnego
Do wstrzymywania innych treści w fazie wstępnego renderowania można używać tych samych interfejsów API, które zostały omówione wcześniej. Mogą to być konkretne części kodu JavaScript lub całe elementy skryptu, których nie chcesz uruchamiać na etapie wstępnego renderowania.
Na przykład w przypadku tego skryptu:
<script src="https://example.com/app/script.js" async></script>
Możesz to zmienić na dynamicznie wstawiany element skryptu, który jest wstawiany tylko na podstawie poprzedniej funkcji whenActivated:
async function addScript(scriptUrl) {
await whenActivated;
const script = document.createElement('script');
script.src = 'scriptUrl';
document.body.appendChild(script);
}
addScript('https://example.com/app/script.js');
Może to być przydatne do wstrzymywania odrębnych skryptów, które obejmują analitykę, lub renderowania treści na podstawie stanu lub innych zmiennych, które mogą się zmieniać w trakcie wizyty. Może to dotyczyć np. rekomendacji, stanu logowania lub ikon koszyka, aby mieć pewność, że wyświetlane są najbardziej aktualne informacje.
Chociaż jest to bardziej prawdopodobne w przypadku wstępnego renderowania, te warunki dotyczą też stron wczytywanych na kartach w tle, o których wspomnieliśmy wcześniej (dlatego zamiast funkcji whenActivated można użyć funkcji whenFirstVisible).
W wielu przypadkach stan należy też sprawdzać w przypadku ogólnych visibilitychange zmian – na przykład po powrocie na stronę, która była w tle, liczniki koszyka powinny zostać zaktualizowane o najnowszą liczbę produktów w koszyku. Nie jest to więc problem związany konkretnie z wstępnym renderowaniem, ale wstępne renderowanie sprawia, że istniejący problem staje się bardziej widoczny.
Jednym ze sposobów, w jaki Chrome ogranicza potrzebę ręcznego opakowywania skryptów lub funkcji, jest wstrzymywanie niektórych interfejsów API, o czym wspomnieliśmy wcześniej. Ponadto nie są renderowane elementy iframe innych firm, więc ręcznego wstrzymywania wymaga tylko treść znajdująca się na ich wierzchu.
pomiar wyników,
Aby mierzyć dane o skuteczności, platformy analityczne powinny rozważyć, czy lepiej jest mierzyć je na podstawie czasu aktywacji, a nie czasu wczytywania strony, który jest podawany przez interfejsy API przeglądarki.
W przypadku podstawowych wskaźników internetowych, mierzonych przez Chrome za pomocą Raportu na temat użytkowania Chrome, mają one na celu pomiar wygody użytkownika. Są one mierzone na podstawie czasu aktywacji. W takim przypadku wskaźnik LCP może wynosić 0 sekund, co pokazuje, że jest to świetny sposób na poprawę Core Web Vitals.
Od wersji 3.1.0 web-vitals jest aktualizowana, aby obsługiwać wstępnie renderowane nawigacje w taki sam sposób, w jaki Chrome mierzy podstawowe sygnały internetowe. Ta wersja oznacza też wstępnie renderowane nawigacje w przypadku tych danych w atrybucie Metric.navigationType, jeśli strona została wstępnie wyrenderowana w całości lub częściowo.
Pomiar wstępnego renderowania
Informację o tym, czy strona jest wstępnie renderowana, można uzyskać za pomocą niezerowego wpisu activationStart w PerformanceNavigationTiming. Możesz to następnie zarejestrować za pomocą wymiaru niestandardowego lub podobnego podczas rejestrowania wyświetleń strony, np. za pomocą funkcji pagePrerendered opisanej wcześniej:
// Set Custom Dimension for Prerender status
gtag('set', { 'dimension1': pagePrerendered() });
// Initialise GA - including sending page view by default
gtag('config', 'G-12345678-1');
Dzięki temu w statystykach zobaczysz, ile nawigacji zostało wstępnie wyrenderowanych w porównaniu z innymi typami nawigacji. Będziesz też mieć możliwość powiązania dowolnych danych o skuteczności lub danych biznesowych z tymi różnymi typami nawigacji. Szybsze wczytywanie stron oznacza większe zadowolenie użytkowników, co często ma realny wpływ na wyniki biznesowe, jak pokazują nasze studia przypadków.
Gdy zmierzysz wpływ renderowania wstępnego stron na wyniki biznesowe w przypadku natychmiastowej nawigacji, możesz zdecydować, czy warto zainwestować więcej wysiłku w korzystanie z tej technologii, aby umożliwić renderowanie wstępne większej liczby nawigacji, czy też zbadać, dlaczego strony nie są wstępnie renderowane.
Pomiar współczynnika trafień
Oprócz pomiaru wpływu stron odwiedzanych po renderowaniu wstępnym ważne jest też mierzenie stron, które zostały wstępnie wyrenderowane, ale nie zostały później odwiedzone. Może to oznaczać, że wstępnie renderujesz zbyt wiele treści i wykorzystujesz cenne zasoby użytkownika, nie przynosząc mu przy tym większych korzyści.
Można to zmierzyć, wywołując zdarzenie analityczne po wstawieniu reguł spekulacyjnych – po sprawdzeniu, czy przeglądarka obsługuje renderowanie wstępne za pomocą HTMLScriptElement.supports('speculationrules') – aby wskazać, że zażądano renderowania wstępnego. (Pamiętaj, że samo żądanie renderowania wstępnego nie oznacza, że zostało ono rozpoczęte lub zakończone. Jak wspomnieliśmy wcześniej, renderowanie wstępne to wskazówka dla przeglądarki, która może nie renderować wstępnie stron na podstawie ustawień użytkownika, bieżącego wykorzystania pamięci lub innych heurystyk).
Następnie możesz porównać liczbę tych zdarzeń z rzeczywistą liczbą wyświetleń wstępnie wyrenderowanych stron. Możesz też w razie potrzeby uruchomić inne zdarzenie po aktywacji, aby ułatwić porównanie.
„Odsetek udanych działań” można oszacować, sprawdzając różnicę między tymi 2 wartościami. W przypadku stron, na których używasz interfejsu Speculation Rules API do wstępnego renderowania stron, możesz odpowiednio dostosować reguły, aby utrzymać wysoki współczynnik trafień i zachować równowagę między wykorzystywaniem zasobów użytkowników w celu ułatwienia im korzystania z usługi a niepotrzebnym zużywaniem tych zasobów.
Pamiętaj, że wstępne renderowanie może odbywać się z powodu wstępnego renderowania paska adresu, a nie tylko reguł spekulacyjnych. Jeśli chcesz je odróżnić, możesz sprawdzić pole document.referrer (które w przypadku nawigacji po pasku adresu, w tym wstępnie renderowanej nawigacji po pasku adresu, będzie puste).
Sprawdź też strony, które nie są wstępnie renderowane, ponieważ może to oznaczać, że nie kwalifikują się one do wstępnego renderowania, nawet z paska adresu. Może to oznaczać, że nie korzystasz z tego ulepszenia zwiększającego skuteczność. Zespół Chrome planuje dodać dodatkowe narzędzia do testowania kwalifikacji do wstępnego renderowania, być może podobne do narzędzia do testowania pamięci podręcznej wstecz/do przodu, a także potencjalnie dodać interfejs API, który będzie informować o przyczynach niepowodzenia wstępnego renderowania.
Wpływ na rozszerzenia
Więcej informacji o dodatkowych kwestiach, które autorzy rozszerzeń do Chrome mogą wziąć pod uwagę w przypadku wstępnie renderowanych stron, znajdziesz w artykule Rozszerzenia Chrome: rozszerzanie interfejsu API w celu obsługi natychmiastowej nawigacji.
Prześlij opinię
Wstępne renderowanie jest aktywnie rozwijane przez zespół Chrome i planujemy rozszerzyć zakres funkcji dostępnych w wersji Chrome 108. Zachęcamy do przesyłania opinii na temat repozytorium GitHub lub za pomocą naszego narzędzia do śledzenia problemów. Z niecierpliwością czekamy na przypadki użycia tego nowego interfejsu API i chętnie będziemy się nimi dzielić.
Powiązane artykuły
- Ćwiczenia z programowania dotyczące reguł spekulacyjnych
- Debugowanie reguł spekulacyjnych
- Przedstawiamy NoState Prefetch
- Specyfikacja interfejsu Speculation Rules API
- Repozytorium GitHub Navigational speculation
- Rozszerzenia do Chrome: rozszerzenie interfejsu API o obsługę natychmiastowej nawigacji
Podziękowania
Miniatura autorstwa Marca-Oliviera Jodoina na Unsplash