

Giriş
Medya Kaynağı Uzantılar (MSE), HTML5 <audio> ve <video> öğeleri için genişletilmiş arabelleğe alma ve oynatma kontrolü sağlar. Başlangıçta HTTP üzerinden Dinamik Adaptif Akış (DASH) tabanlı video oynatıcıları kolaylaştırmak için geliştirilmiş olsa da bu oynatıcıların ses için, özellikle de ara vermeden oynatma için nasıl kullanılabileceğini aşağıda göreceğiz.
Şarkıların bir parçadan diğerine sorunsuz şekilde geçtiği bir müzik albümü dinlemişsinizdir. Hatta şu anda böyle bir albüm dinliyor olabilirsiniz. Sanatçılar, bu kesintisiz oynatma deneyimlerini hem sanatsal bir seçim olarak hem de sesin tek bir kesintisiz akış olarak kaydedildiği plaklar ve CD'ler ile ilişkili bir öğe olarak oluşturur. Ne yazık ki MP3 ve AAC gibi modern ses codec'lerinin çalışma şekli nedeniyle bu sorunsuz işitsel deneyim günümüzde genellikle kayboluyor.
Nedenini ayrıntılı olarak aşağıda açıklayacağız ancak şimdilik bir gösterimle başlayalım. Aşağıda, mükemmel Sintel filminin beş ayrı MP3 dosyasına bölünüp MSE kullanılarak yeniden birleştirilen ilk otuz saniyesi gösterilmektedir. Kırmızı çizgiler, her MP3'ün oluşturulması (kodlanması) sırasında eklenen boşlukları gösterir. Bu noktalarda ses kesintileri duyarsınız.
İğrenç! Bu deneyim pek iyi değil. Daha iyisini yapabiliriz. Yukarıdaki demoda kullanılan MP3 dosyalarının aynısını kullanarak biraz daha çalışmamız gerekiyor. Bu can sıkıcı boşlukları kaldırmak için MSE'yi kullanabiliriz. Bir sonraki demoda yeşil çizgiler, dosyaların birleştirildiği ve boşlukların kaldırıldığı yerleri gösterir. Bu, Chrome 38 ve sonraki sürümlerde sorunsuz bir şekilde oynatılır.
Boşluksuz içerik oluşturmanın çeşitli yolları vardır. Bu demoda, normal bir kullanıcının bilgisayarında bulunabilecek dosya türlerine odaklanacağız. Her dosyanın, önceki veya sonraki ses segmentlerine bakılmaksızın ayrı ayrı kodlandığı.
Temel Kurulum
Öncelikle, MediaSource örneğinin temel kurulumunu ele alalım. Adından da anlaşılacağı gibi medya kaynağı uzantıları, mevcut medya öğelerinin uzantılarıdır. Aşağıda, standart bir URL ayarlar gibi bir ses öğesinin source özelliğine MediaSource örneğimizi temsil eden bir Object URL atıyoruz.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function() {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function(data) { onAudioLoaded(data, 0); } );
});
audio.src = URL.createObjectURL(mediaSource);
MediaSource nesnesi bağlandıktan sonra bazı ilklendirme işlemleri gerçekleştirir ve sonunda bir sourceopen etkinliği tetikler. Bu noktada bir SourceBuffer oluşturabiliriz. Yukarıdaki örnekte, MP3 segmentlerimizi ayrıştırıp kodlarını çözebilen bir audio/mpeg öğesi oluşturuyoruz. Birkaç diğer tür de mevcuttur.
Anormal Dalga Formları
Birazdan koda geri döneceğiz ancak şimdi, az önce eklediğimiz dosyaya, özellikle de sonuna daha yakından bakalım. Aşağıda, sintel_0.mp3 kanalındaki her iki kanalda da ortalaması alınan son 3.000 örneğin grafiği gösterilmektedir. Kırmızı çizgideki her piksel, [-1.0, 1.0] aralığındaki bir kayan nokta örneğidir.
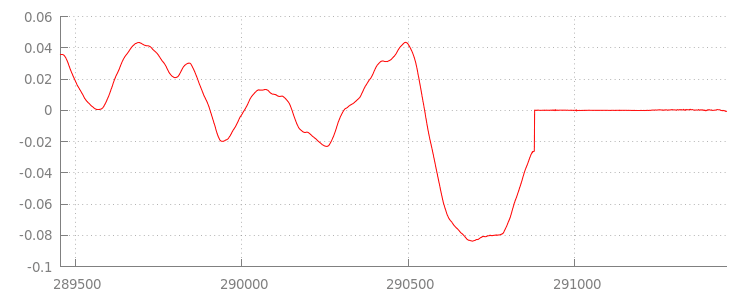
Why are there so many zero (silent) samples? Bu sorunlar, kodlama sırasında ortaya çıkan sıkıştırma kusurlarından kaynaklanır. Neredeyse her kodlayıcı bir tür dolgu ekler. Bu durumda LAME, dosyanın sonuna tam olarak 576 dolgu örneği ekledi.
Her dosyanın sonuna eklenen dolguya ek olarak başına da dolgu eklendi. sintel_1.mp3 kanalına göz atarsak ön tarafta 576 tane daha dolgu örneği olduğunu görürüz. Dolgu miktarı, kodlayıcıya ve içeriğe göre değişir ancak her dosyada bulunan metadata değerine göre tam değerleri biliriz.

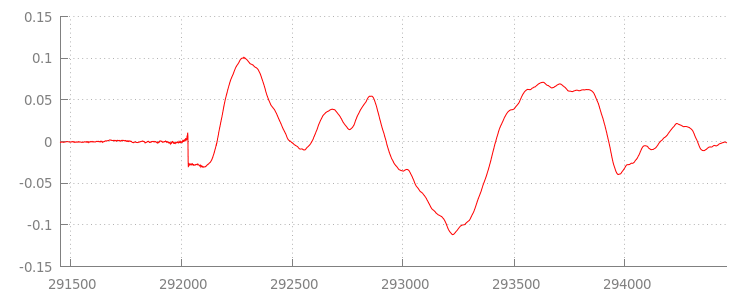
Önceki demodaki segmentler arasındaki aksaklıklara, her dosyanın başında ve sonunda yer alan sessiz bölümler neden oluyor. Boşluksuz oynatma için bu sessiz bölümleri kaldırmamız gerekir. Neyse ki bu işlem MediaSource ile kolayca yapılabilir. Aşağıda, bu sessizliği kaldırmak için onAudioLoaded() yöntemimizi ekleme aralığı ve zaman damgası ofseti kullanacak şekilde değiştireceğiz.
Örnek Kod
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function() {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3',
function(data) { onAudioLoaded(data, index); });
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Sorunsuz bir dalga biçimi
Ekle pencerelerimizi uyguladıktan sonra dalga formuna tekrar göz atarak yeni kodumuzun neleri başardığını görelim. Aşağıda, sintel_0.mp3'ün sonundaki sessiz bölümün (kırmızı) ve sintel_1.mp3'ün başındaki sessiz bölümün (mavi) kaldırıldığını ve segmentler arasında sorunsuz bir geçiş elde edildiğini görebilirsiniz.

Sonuç
Böylece beş segmentin tümünü sorunsuz bir şekilde tek bir videoda birleştirdik ve demomuzun sonuna geldik. Sohbetimizi sonlandırmadan önce, onAudioLoaded() yöntemimizin kapsayıcıları veya codec'leri dikkate almadığını fark etmiş olabilirsiniz. Bu, bu tekniklerin tümünün kapsayıcı veya codec türüne bakılmaksızın çalışacağı anlamına gelir. Aşağıda, orijinal demoyu MP3 yerine DASH uyumlu parçalara ayrılmış MP4 olarak yeniden oynatabilirsiniz.
Daha fazla bilgi edinmek isterseniz kesintisiz içerik oluşturma ve meta veri ayrıştırma hakkında daha ayrıntılı bilgi edinmek için aşağıdaki ek bölümlere göz atın. Bu demoyu destekleyen koda daha yakından bakmak için gapless.js sayfasını da inceleyebilirsiniz.
Bu e-postayı okuduğunuz için teşekkür ederiz.
Ek A: Boşluksuz İçerik Oluşturma
Ara vermeden içerik üretmek zor olabilir. Aşağıda, bu demoda kullanılan Sintel medyasının oluşturulması adım adım açıklanmıştır. Başlamak için Sintel'in kayıpsız FLAC ses parçasının bir kopyasına ihtiyacınız vardır. Gelecekte referans olarak kullanabileceğiniz SHA1 değeri aşağıda verilmiştir. FFmpeg, MP4Box, LAME ve afconvert içeren bir OSX kurulumuna ihtiyacınız vardır.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Öncelikle, 1-Snow_Fight.flac kanalının ilk 31,5 saniyesini ayıracağız. Ayrıca, oynatma işlemi sona erdiğinde tıklamaları önlemek için 28.saniyeden itibaren 2,5 saniyelik bir karartma eklemek istiyoruz. Aşağıdaki FFmpeg komut satırını kullanarak tüm bunları yapabilir ve sonuçları sintel.flac içine koyabiliriz.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Ardından, dosyayı her biri 6,5 saniyelik 5 wave dosyasına böleriz.Wave, neredeyse her kodlayıcı tarafından desteklendiğinden en kolay kullanılan biçimdir. Bu işlemi FFmpeg ile de yapabiliriz. Bu durumda sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav ve sintel_4.wav değerlerini elde ederiz.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Ardından MP3 dosyalarını oluşturalım. LAME, aralıksız içerik oluşturmak için çeşitli seçenekler sunar. İçeriğin kontrolü sizdeyse segmentler arasında dolgu yapılmasını önlemek için tüm dosyaların toplu kodlamasıyla birlikte --nogap kullanmayı düşünebilirsiniz. Ancak bu demo için bu dolguyu istiyoruz. Bu nedenle, dalga dosyalarının standart yüksek kaliteli VBR kodlamasını kullanacağız.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
MP3 dosyaları oluşturmak için gereken tek şey budur. Şimdi, parçalara ayrılmış MP4 dosyalarının oluşturulmasını ele alalım. iTunes için masterlanmış medya oluşturma konusunda Apple'ın talimatlarını uygularız. Aşağıda, dalga dosyalarını talimatlara göre ara CAF dosyalarına dönüştürüp önerilen parametreleri kullanarak MP4 kapsayıcısında AAC olarak kodlayacağız.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
MediaSource ile kullanılabilmesi için uygun şekilde parçalara ayırmamız gereken birkaç M4A dosyamız var. Amacımız doğrultusunda bir saniyelik bir parça boyutu kullanacağız. MP4Box, her bir parçalanmış MP4'ü sintel_#_dashinit.mp4 olarak yazar ve atılabilen bir MPEG-DASH manifesti (sintel_#_dash.mpd) ekler.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
İşte bu kadar. Artık kesintisiz oynatma için gerekli doğru meta verilere sahip parçalı MP4 ve MP3 dosyalarımız var. Bu meta verilerin nasıl göründüğü hakkında daha fazla bilgi için Ek B'ye bakın.
Ek B: Aralıksız Meta Verileri Ayrıştırma
Boşluksuz içerik oluşturma gibi, boşluksuz meta verileri ayrıştırmak da depolama için standart bir yöntem olmadığından zor olabilir. Aşağıda, en yaygın iki kodlayıcı olan LAME ve iTunes'ın sessiz ara vermeyen meta verilerini nasıl depoladığından bahsedeceğiz. Yukarıda kullanılan ParseGaplessData() için bazı yardımcı yöntemler ve bir ana hat oluşturarak başlayalım.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<../= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Ayrıştırması ve açıklanması en kolay olduğu için ilk olarak Apple'ın iTunes meta veri biçimini ele alacağız. iTunes (ve afconvert), MP3 ve M4A dosyalarına ASCII olarak şu şekilde kısa bir bölüm yazar:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Bu, MP3 kapsayıcısındaki bir ID3 etiketine ve MP4 kapsayıcısındaki bir meta veri atomuna yazılır. Amacımız doğrultusunda ilk 0000000 jetonunu yoksayabiliriz. Sonraki üç jeton, ön dolgu, son dolgu ve dolgu olmayan toplam örnek sayısıdır. Bunların her birini sesin örnekleme hızına bölerek her birinin süresini elde ederiz.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Diğer taraftan, çoğu açık kaynak MP3 kodlayıcı, sessiz bir MPEG çerçevesinin içine yerleştirilmiş özel bir Xing başlığında sessiz meta verileri depolar (sessizdir, böylece Xing başlığını anlamayan kod çözücüler yalnızca sessiz oynatır). Maalesef bu etiket her zaman mevcut değildir ve bir dizi isteğe bağlı alana sahiptir. Bu demo için medya üzerinde kontrol sahibiyiz ancak pratikte, kesintisiz meta verilerin ne zaman kullanılabileceğini öğrenmek için bazı ek kontroller yapılması gerekir.
Öncelikle toplam örnek sayısını ayrıştıracağız. Basitlik açısından bunu Xing başlığından okuyacağız ancak normal MPEG ses başlığından da oluşturulabilir. Xing üstbilgileri Xing veya Info etiketiyle işaretlenebilir. Bu etiketten tam 4 bayt sonra, dosyadaki toplam kare sayısını temsil eden 32 bit bulunur. Bu değeri kare başına örnek sayısıyla çarptığımızda dosyadaki toplam örnek sayısını elde ederiz.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Toplam örnek sayısına sahip olduğumuza göre, dolgu örneklerinin sayısını okumaya geçebiliriz. Bu, kodlayıcınıza bağlı olarak Xing üst bilgisine yerleştirilmiş bir LAME veya Lavf etiketi altında yazılabilir. Bu başlığın tam 17 bayt sonrasında, sırasıyla 12 bitlik ön ve arka dolguyu temsil eden 3 bayt bulunur.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Böylece, kesintisiz içeriklerin büyük bir kısmını ayrıştırmak için eksiksiz bir işlevimiz oldu. Bununla birlikte, uç durumlar kesinlikle çok sayıda olduğundan benzer kodu üretimde kullanmadan önce dikkatli olmanızı öneririz.
Ek C: Çöp Toplama Hakkında
SourceBuffer örneklerine ait bellek, içerik türüne, platforma özgü sınırlara ve mevcut oynatma konumuna göre etkin bir şekilde çöp toplanır. Chrome'da bellek, önceden oynatılmış arabellekten geri alınır. Ancak bellek kullanımı platforma özgü sınırları aşarsa oynatılmayan arabelleklerden bellek kaldırılır.
Oynatma, geri kazanılan bellek nedeniyle zaman çizelgesinde bir boşluğa ulaştığında, boşluk yeterince küçükse kesinti yaşanabilir veya boşluk çok büyükse oynatma tamamen duraklatılabilir. Bu iki durum da iyi bir kullanıcı deneyimi sunmaz. Bu nedenle, aynı anda çok fazla veri eklemekten kaçınmak ve artık gerekli olmayan aralıkları medya zaman çizelgesinden manuel olarak kaldırmak önemlidir.
Aralıklar, her SourceBuffer üzerinde remove() yöntemi kullanılarak kaldırılabilir. Bu işlem, [start, end] aralığını saniyeler içinde kaldırır. appendBuffer()'e benzer şekilde, her remove() tamamlandıktan sonra bir updateend etkinliği tetikler. Diğer kaldırma veya ekleme işlemleri, etkinlik tetiklenene kadar gönderilmemelidir.
Masaüstü Chrome'da aynı anda yaklaşık 12 megabayt ses içeriği ve 150 megabayt video içeriği saklayabilirsiniz. Tarayıcılar veya platformlar arasında bu değerlere güvenmemelisiniz. Örneğin, bu değerler kesinlikle mobil cihazları temsil etmez.
Çöp toplama işlemi yalnızca SourceBuffers değişkenine eklenen verileri etkiler. JavaScript değişkenlerinde ne kadar veri tutabileceğinizle ilgili herhangi bir sınır yoktur. Gerekirse aynı verileri aynı konuma yeniden ekleyebilirsiniz.