
Bu doküman, Daha hızlı Web Yapay Zeka için WebAssembly ve WebGPU geliştirmeleri, 1. bölüm başlıklı makalenin devamı niteliğindedir. Devam etmeden önce bu yayını okumanızı veya IO 24'teki konuşmayı izlemenizi öneririz.



WebGPU
WebGPU, web uygulamalarının verimli ve yüksek paralellikte hesaplama gerçekleştirmesi için istemcinin GPU donanımına erişmesine olanak tanır. Chrome'da WebGPU'yu kullanıma sunduğumuzdan bu yana web'de yapay zeka (AI) ve makine öğrenimi (ML) ile ilgili inanılmaz demolar gördük.
Örneğin, Web Stable Diffusion, metinden doğrudan tarayıcıda resim oluşturmak için yapay zekanın kullanılabileceğini gösterdi. Bu yılın başlarında Google'ın kendi Mediapipe ekibi, büyük dil modeli çıkarımına yönelik deneysel destek yayınladı.
Aşağıdaki animasyonda, Google'ın açık kaynak büyük dil modeli (LLM) olan Gemma'nın Chrome'da tamamen cihaz üzerinde gerçek zamanlı olarak çalışması gösterilmektedir.
Meta'nın Segment Anything Model'i için Hugging Face'ın demo'sunda, yüksek kaliteli nesne maskeleri tamamen istemcide oluşturulur.
Bunlar, yapay zeka ve makine öğrenimi için WebGPU'nun gücünü gösteren muhteşem projelerden yalnızca birkaçı. WebGPU, bu modellerin ve diğer modellerin CPU'da çalıştırıldığından çok daha hızlı çalışmasına olanak tanır.
Hugging Face'ın metin yerleştirme için WebGPU karşılaştırması, aynı modelin CPU uygulamasına kıyasla muazzam hız artışları gösteriyor. Apple M1 Max dizüstü bilgisayarda WebGPU, 30 kattan fazla daha hızlıydı. Diğer kullanıcılar, WebGPU'nun karşılaştırma testini 120 kattan fazla hızlandırdığını bildirdi.
AI ve ML için WebGPU özelliklerini iyileştirme
WebGPU, bilgisayar gölgelendiricileri desteği sayesinde milyarlarca parametreye sahip olabilecek yapay zeka ve makine öğrenimi modelleri için mükemmeldir. İşleme gölgelendiricileri GPU'da çalışır ve büyük miktarlarda veri üzerinde paralel dizi işlemlerinin yapılmasına yardımcı olur.
Geçtiğimiz yıl WebGPU'da yapılan çok sayıda iyileştirmenin yanı sıra web'de makine öğrenimi ve yapay zeka performansını iyileştirmek için daha fazla özellik eklemeye devam ettik. Kısa süre önce 16 bit kayan nokta ve paketlenmiş tam sayı nokta çarpımları olmak üzere iki yeni özellik kullanıma sunduk.
16 bit kayan nokta
Makine öğrenimi iş yüklerinin hassasiyet gerektirmediğini unutmayın. shader-f16, WebGPU gölgeleme dilinde f16 türünün kullanılmasını sağlayan bir özelliktir. Bu kayan nokta türü, normal 32 bit yerine 16 bit kullanır. f16 daha küçük bir aralığa sahiptir ve daha az hassastır ancak birçok makine öğrenimi modeli için bu yeterlidir.
Bu özellik, verimliliği birkaç şekilde artırır:
Azaltılmış bellek: f16 öğeleri içeren tenzorlar, bellek kullanımını yarı yarıya azaltan yarı yarıya daha az yer kaplar. GPU hesaplamaları genellikle bellek bant genişliğinde darboğaz oluşturur. Bu nedenle, belleğin yarısı genellikle gölgelendiricilerin iki kat daha hızlı çalıştığı anlamına gelebilir. Teknik olarak, bellek bant genişliğinden tasarruf etmek için f16'ya ihtiyacınız yoktur. Verileri düşük hassasiyetli bir biçimde depolayabilir ve ardından hesaplama için gölgelendiricide tam f32 olarak genişletebilirsiniz. Ancak GPU, verileri paketlemek ve paketini açmak için fazladan işlem gücü harcar.
Azaltılmış veri dönüşümü: f16, veri dönüşümünü en aza indirerek daha az bilgi işlem kullanır. Düşük hassasiyetli veriler depolanabilir ve daha sonra dönüşüm yapılmadan doğrudan kullanılabilir.
Daha fazla paralellik: Modern GPU'lar, GPU'nun yürütme birimlerine aynı anda daha fazla değer sığdırarak daha fazla sayıda paralel hesaplama gerçekleştirebilir. Örneğin, saniyede 5 trilyon f32 kayan nokta işlemini destekleyen bir GPU, saniyede 10 trilyon f16 kayan nokta işlemini destekleyebilir.
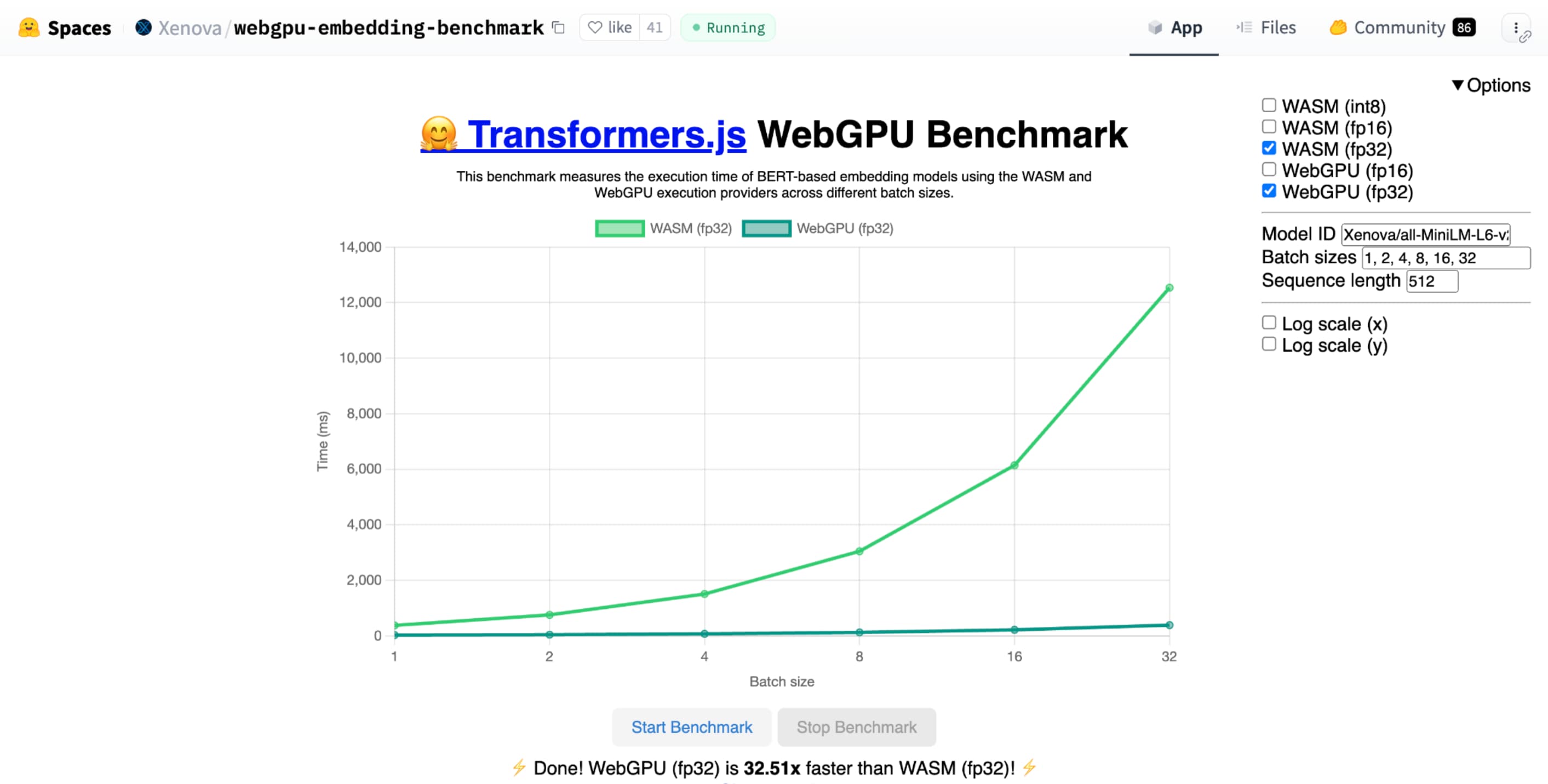
shader-f16 ile Hugging Face'ın metin yerleştirme için WebGPU karşılaştırması, Apple M1 Max dizüstü bilgisayarda f32'den 3 kat daha hızlı çalışır.
WebLLM, birden fazla büyük dil modelini çalıştırabilen bir projedir. Açık kaynak bir makine öğrenimi derleyici çerçevesi olan Apache TVM'i kullanır.
WebLLM'den, Llama 3 sekiz milyar parametre modelini kullanarak Paris'e bir gezi planlamasını istedim. Sonuçlar, modelin ön doldurma aşamasında f16'nın f32'den 2,1 kat daha hızlı olduğunu gösteriyor. Kod çözme aşamasında ise 1, 3 kattan daha hızlıdır.
Uygulamalar, öncelikle GPU adaptörünün f16'yı desteklediğini onaylamalı ve mevcutsa GPU cihazı isteğinde bulunurken f16'yı açıkça etkinleştirmelidir. f16 desteklenmiyorsa requiredFeatures dizisinde isteğinde bulunamazsınız.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Ardından, WebGPU gölgelendiricilerinizde en üstte f16'yı açıkça etkinleştirmeniz gerekir. Ardından, diğer tüm float veri türleri gibi gölgelendiricide kullanabilirsiniz.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Paketlenmiş tamsayı nokta çarpımları
Birçok model, yalnızca 8 bit hassasiyetle (f16'nın yarısı) iyi çalışır. Bu yöntem, segmentasyon ve nesne tanıma için LLM'ler ve görüntü modelleri arasında popülerdir. Bununla birlikte, modellerin çıkış kalitesi daha az hassasiyetle azalır. Bu nedenle, 8 bitlik kesme işlemi her uygulama için uygun değildir.
8 bit değerlerini doğal olarak destekleyen GPU sayısı nispeten azdır. Bu noktada, sıkıştırılmış tam sayı nokta çarpımları devreye girer. DP4a'yı Chrome 123'te kullanıma sunduk.
Modern GPU'larda, iki 32 bitlik tam sayıyı alıp her birini art arda paketlenmiş 4 adet 8 bitlik tam sayı olarak yorumlayan ve bileşenleri arasındaki nokta çarpımını hesaplayan özel talimatlar bulunur.
Matris çarpma çekirdekleri çok sayıda nokta çarpımından oluştuğu için bu özellikle yapay zeka ve makine öğrenimi için faydalıdır.
Örneğin, 4 x 8 boyutunda bir matrisi 8 x 1 boyutunda bir vektörle çarpalım. Bu hesaplama, çıkış vektöründeki A, B, C ve D değerlerinin her birini hesaplamak için 4 iç çarpım yapılmasını içerir.
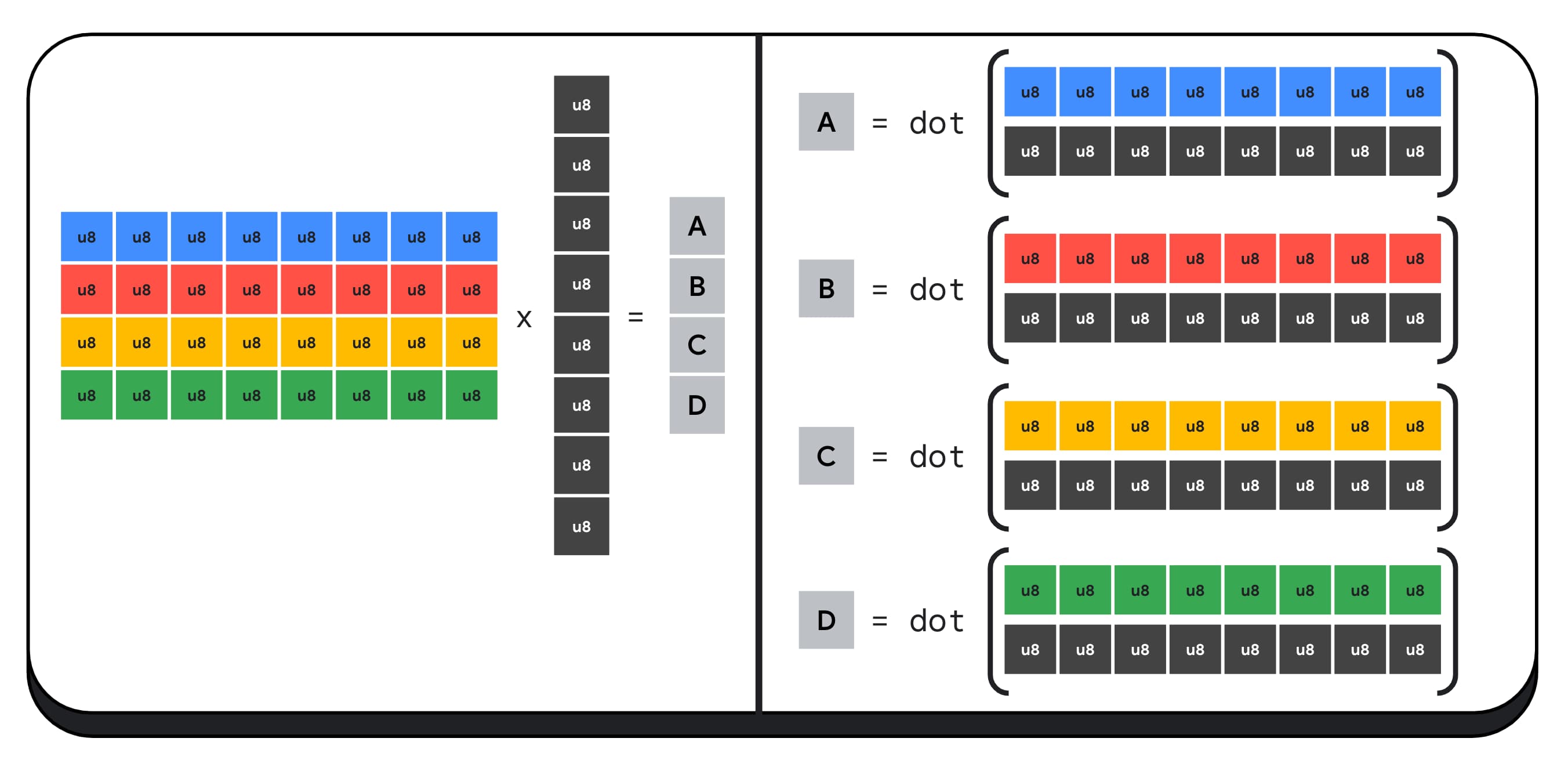
Bu çıkışların her birinin hesaplanması için aynı işlem uygulanır. Bunlardan birini hesaplamayla ilgili adımlara göz atacağız. Herhangi bir hesaplamadan önce, 8 bitlik tam sayı verilerini önce f16 gibi aritmetik işlem yapabileceğimiz bir türe dönüştürmemiz gerekir. Ardından, öğe bazında çarpma işlemi gerçekleştirip tüm ürünleri toplarız. Matris-vektor çarpımının tamamı için verileri paketinden çıkarmak üzere 40 tam sayıdan kayan noktaya dönüştürme, 32 kayan nokta çarpımı ve 28 kayan nokta toplama işlemi gerçekleştiririz.
Daha fazla işlem içeren daha büyük matrisler için paketlenmiş tam sayı nokta çarpımları, çalışma miktarını azaltmaya yardımcı olabilir.
Sonuç vektöründeki her çıkış için, yerleşik WebGPU Gölgelendirme Dili dot4U8Packed'ni kullanarak iki paketlenmiş nokta çarpımı işlemi gerçekleştirip sonuçları toplarız. Toplamda, matris-vektor çarpımının tamamı için herhangi bir veri dönüşümü gerçekleştirmeyiz. 8 paketlenmiş nokta çarpımı ve 4 tam sayı toplama işlemi gerçekleştiririz.
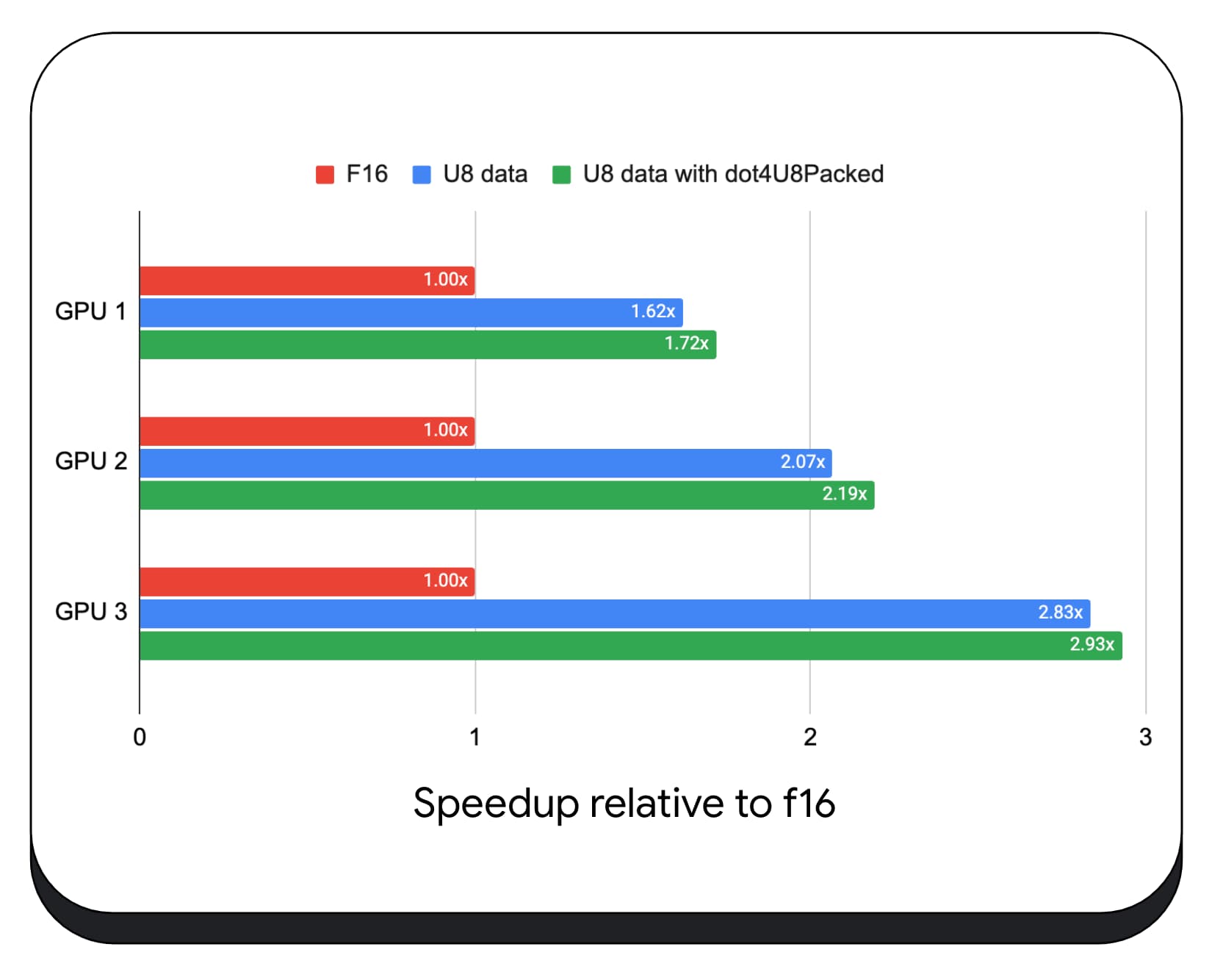
Paketlenmiş tam sayı nokta çarpımlarını, çeşitli tüketici GPU'larında 8 bit veri ile test ettik. 16 bit kayan noktaya kıyasla 8 bitin 1,6 ila 2,8 kat daha hızlı olduğunu görebiliriz. Ayrıca paketlenmiş tam sayı nokta çarpımlarını kullandığımızda performans daha da artar. 1,7 ila 2,9 kat daha hızlıdır.
wgslLanguageFeatures mülkünde tarayıcı desteği olup olmadığını kontrol edin. GPU, paketlenmiş nokta ürünlerini doğal olarak desteklemiyorsa tarayıcı kendi uygulamasını polyfill yapar.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Aşağıdaki kod snippet'i karşılaştırması (fark), WebGPU gölgelendiricisinde paketlenmiş tam sayı ürünlerini kullanmak için gereken değişiklikleri vurgulamaktadır.
Before: Kısmi nokta çarpımlarını "sum" değişkeninde toplayan bir WebGPU gölgelendiricisidir. Döngünün sonunda "sum", bir vektör ile giriş matrisinin bir satırı arasındaki tam nokta çarpımını tutar.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Sonra: Paketlenmiş tam sayı nokta çarpımlarını kullanmak için yazılmış bir WebGPU gölgelendirici. Temel fark, bu gölgelendiricinin vektör ve matristen 4 kayan nokta değeri yüklemek yerine tek bir 32 bitlik tam sayı yüklemesidir. Bu 32 bitlik tam sayı, dört 8 bitlik tam sayı değerinin verilerini içerir. Ardından, iki değerin nokta çarpımını hesaplamak için dot4U8Packed işlevini çağırırız.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Hem 16 bit kayan nokta hem de paketlenmiş tam sayı nokta ürünleri, Chrome'da yapay zekayı ve makine öğrenimini hızlandıran yerleşik özelliklerdir. 16 bit kayan nokta, donanım desteklediğinde kullanılabilir ve Chrome tüm cihazlarda paketlenmiş tam sayı nokta çarpımlarını uygular.
Daha iyi performans elde etmek için bu özellikleri Chrome kararlı sürümünde hemen kullanabilirsiniz.
Önerilen özellikler
Gelecekte iki özellik daha üzerinde çalışıyoruz: alt gruplar ve ortak matris çarpımı.
Alt gruplar özelliği, iletişim kurmak veya 16'dan fazla sayının toplamı gibi toplu matematik işlemleri yapmak için SIMD düzeyinde paralellik sağlar. Bu sayede, mesaj dizileri arasında verimli veri paylaşımı yapılabilir. Alt gruplar, modern GPU API'lerinde farklı adlar ve biraz farklı biçimlerde desteklenir.
Ortak kümeyi, WebGPU standartlaştırma grubuna götürdüğümüz bir teklife dönüştürdük. Ayrıca, deneysel bir işaretin arkasında Chrome'da alt grupların prototipini oluşturduk ve ilk sonuçlarımızı tartışmaya sunduk. Asıl sorun, taşınabilir davranışı nasıl sağlayacağınızdır.
Ortak matris çarpımı, GPU'lara daha yeni eklendi. Büyük bir matris çarpımı, birden fazla küçük matris çarpımına ayrılabilir. Ortak matris çarpımı, bu küçük sabit boyutlu bloklarda çarpımları tek bir mantıksal adımda gerçekleştirir. Bu adımda, bir grup iş parçacığı sonucu hesaplamak için verimli bir şekilde birlikte çalışır.
Temel GPU API'lerindeki desteği araştırdık ve WebGPU standartlaştırma grubuna bir teklif sunmayı planlıyoruz. Alt gruplarda olduğu gibi, tartışmanın büyük kısmının taşınabilirlikle ilgili olmasını bekliyoruz.
Alt grup işlemlerinin performansını değerlendirmek için gerçek bir uygulamada alt gruplar için deneysel desteği MediaPipe'e entegre ettik ve Chrome'un alt grup işlemleri prototipiyle test ettik.
Büyük dil modelinin ön doldurma aşamasında GPU çekirdeklerinde alt gruplar kullandık. Bu nedenle, yalnızca ön doldurma aşamasındaki hızlandırmayı bildiriyorum. Intel GPU'da alt grupların, temel değere kıyasla iki buçuk kat daha hızlı performans gösterdiğini görüyoruz. Ancak bu iyileştirmeler farklı GPU'larda tutarlı değildir.
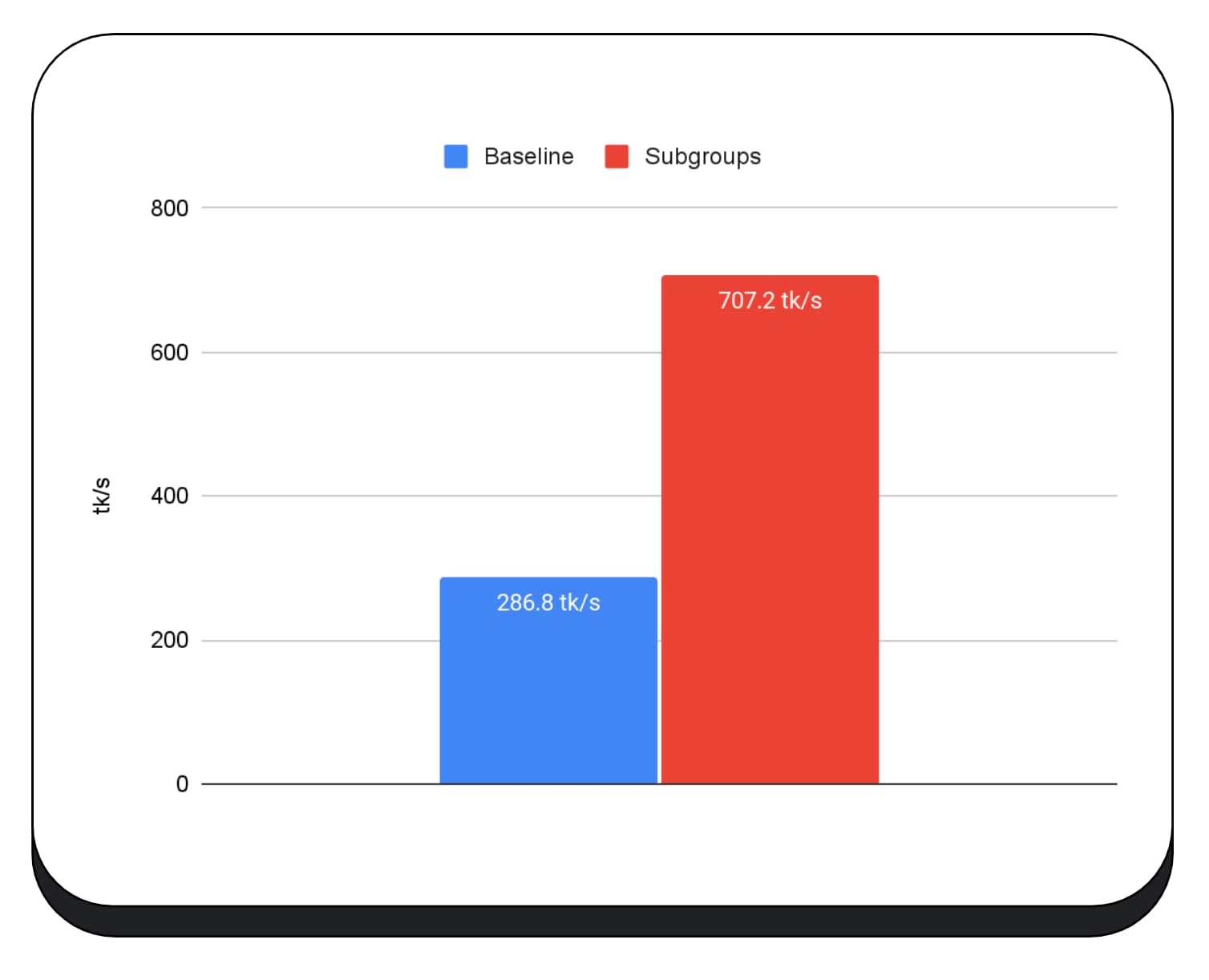
Aşağıdaki grafikte, birden fazla tüketici GPU'sunda matris çarpma mikro karşılaştırmasını optimize etmek için alt grupların uygulanmasının sonuçları gösterilmektedir. Matris çarpımı, büyük dil modellerindeki en ağır işlemlerden biridir. Veriler, alt grupların çoğu GPU'da hızı iki, beş ve hatta on üç kat artırdığını gösteriyor. Ancak ilk GPU'da alt grupların çok daha iyi olmadığını fark edin.
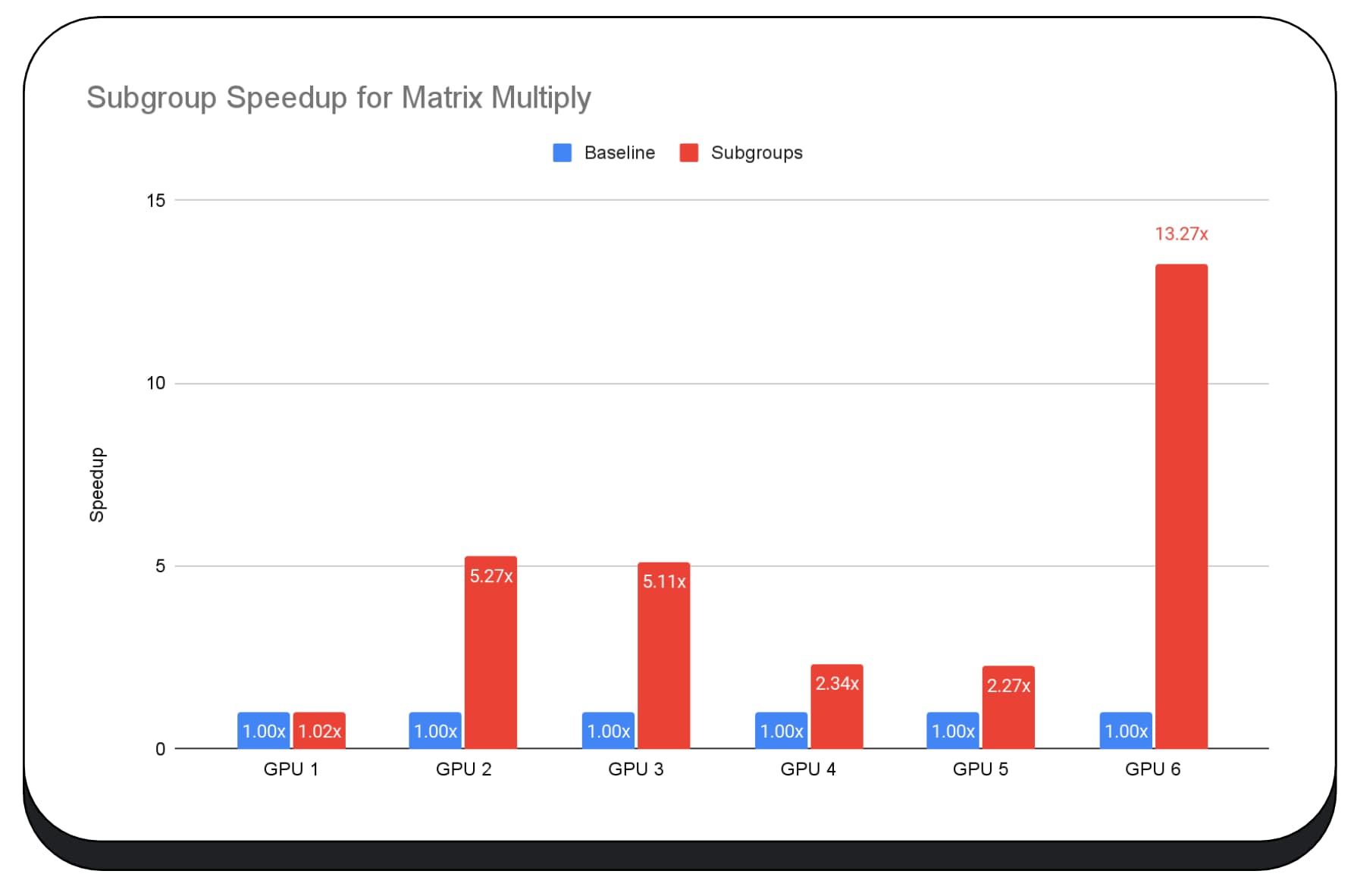
GPU optimizasyonu zordur
GPU'nuzu optimize etmenin en iyi yolu, istemcinin sunduğu GPU'ya bağlıdır. Yeni ve gelişmiş GPU özelliklerini kullanmak her zaman beklediğiniz şekilde sonuç vermeyebilir. Bunun nedeni, birçok karmaşık faktörün devreye girmesidir. Bir GPU'daki en iyi optimizasyon stratejisi, başka bir GPU'daki en iyi strateji olmayabilir.
GPU'nun bilgi işlem iş parçacıklarını tam olarak kullanırken bellek bant genişliğini en aza indirmek istiyorsunuz.
Bellek erişim kalıpları da çok önemli olabilir. GPU'lar, işlem iş parçacıkları belleğe donanım için en uygun şekilde eriştiğinde çok daha iyi performans gösterir. Önemli: Farklı GPU donanımlarında farklı performans özelliklerine sahip olabilirsiniz. GPU'ya bağlı olarak farklı optimizasyonlar yapmanız gerekebilir.
Aşağıdaki grafikte, aynı matris çarpma algoritmasını kullandık ancak çeşitli optimizasyon stratejilerinin etkisini ve farklı GPU'lar arasındaki karmaşıklığı ve varyasyonu daha iyi göstermek için başka bir boyut ekledik. Burada "Swizzle" olarak adlandıracağımız yeni bir teknik kullanıma sunduk. Swizzle, bellek erişim kalıplarını donanım için daha uygun olacak şekilde optimize eder.
Bellek karıştırmanın önemli bir etkisi olduğunu görebilirsiniz. Bu etki bazen alt gruplardan bile daha fazla olabilir. GPU 6'da swizzle 12 kat, alt gruplar ise 13 kat hız artışı sağlar. Bu iki özelliğin birlikte kullanılması, inanılmaz bir 26 kat hızlanma sağlıyor. Diğer GPU'larda bazen swizzle ve alt grupların birlikte kullanılması, tek başına kullanılanlardan daha iyi performans gösterir. Diğer GPU'larda ise yalnızca swizzle kullanılması en iyi performansı sağlar.
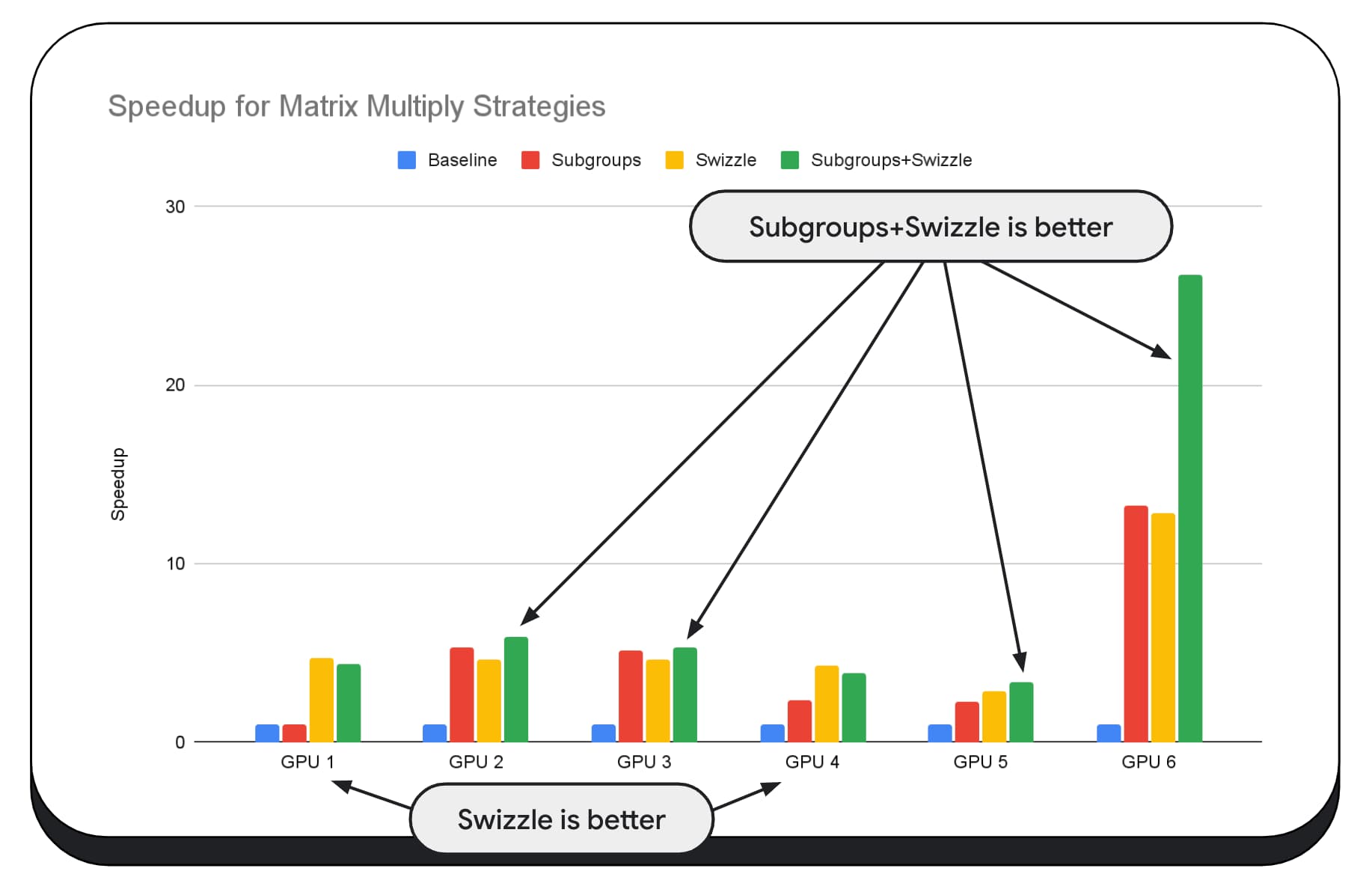
GPU algoritmalarını her donanım parçasında iyi çalışacak şekilde ayarlamak ve optimize etmek çok fazla uzmanlık gerektirebilir. Ancak Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web gibi daha üst düzey kitaplık çerçevelerinde çok sayıda yetenekli çalışma var.
Kitaplıklar ve çerçeveler, çeşitli GPU mimarilerini yönetmenin karmaşıklığını ele almak ve istemcide iyi çalışacak platforma özel kod oluşturmak için iyi bir konumdadır.
Çıkarımlar
Chrome Ekibi, makine öğrenimi iş yükleri için web platformunu iyileştirmek amacıyla WebAssembly ve WebGPU standartlarının gelişmesine yardımcı olmaya devam ediyor. Daha hızlı hesaplama temel öğelerine, web standartları arasında daha iyi birlikte çalışabilirliğe yatırım yapıyoruz ve hem büyük hem de küçük modellerin cihazlarda verimli bir şekilde çalışabildiğinden emin oluyoruz.
Amacımız, web'in en iyi özelliklerini (erişim, kullanılabilirlik ve taşınabilirlik) korurken platformun özelliklerini en üst düzeye çıkarmaktır. Bunu tek başımıza yapamayız. W3C'deki diğer tarayıcı tedarikçileriyle ve birçok geliştirme iş ortağıyla birlikte çalışıyoruz.
WebAssembly ve WebGPU ile çalışırken aşağıdakileri göz önünde bulundurmanızı öneririz:
- Yapay zeka çıkarım özelliği artık web'de ve tüm cihazlarda kullanılabilir. Bu, istemci cihazlarda çalıştırma avantajı sağlar (ör. daha düşük sunucu maliyeti, düşük gecikme süresi ve daha fazla gizlilik).
- Tartışılan birçok özellik temel olarak çerçeve yazarlarıyla ilgili olsa da uygulamalarınızdan da fazladan maliyet yansıtılmaksızın yararlanabilirsiniz.
- Web standartları sürekli değiştiğinden geri bildirimlerinizi her zaman bekliyoruz. WebAssembly ve WebGPU için kendi sürümünüzü paylaşın.
Teşekkür ederiz
WebGPU f16 ve paketlenmiş tam sayı nokta çarpımı özelliklerinin geliştirilmesinde önemli rol oynayan Intel web grafikleri ekibine teşekkür ederiz. Diğer tarayıcı tedarikçileri de dahil olmak üzere W3C'deki WebAssembly ve WebGPU çalışma gruplarının diğer üyelerine teşekkür ederiz.
Hem Google'daki hem de açık kaynak topluluğundaki yapay zeka ve makine öğrenimi ekiplerine, inanılmaz iş ortakları oldukları için teşekkür ederiz. Elbette tüm bunların mümkün olmasını sağlayan tüm ekip arkadaşlarımıza da teşekkür ederiz.