

I dati non elaborati del report sull'esperienza utente di Chrome (CrUX) sono disponibili su BigQuery, un database su Google Cloud. L'utilizzo di BigQuery richiede un progetto Google Cloud e una conoscenza di base di SQL.
In questa guida, scopri come utilizzare BigQuery per scrivere query sul set di dati CrUX al fine di estrarre risultati utili sullo stato delle esperienze utente sul web:
- Informazioni su come sono organizzati i dati
- Scrivere una query di base per valutare il rendimento di un'origine
- Scrivi una query avanzata per monitorare il rendimento nel tempo
Organizzazione dei dati
Per iniziare, esamina una query di base:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Per eseguire la query, inseriscila nell'editor delle query e premi il pulsante "Esegui query":
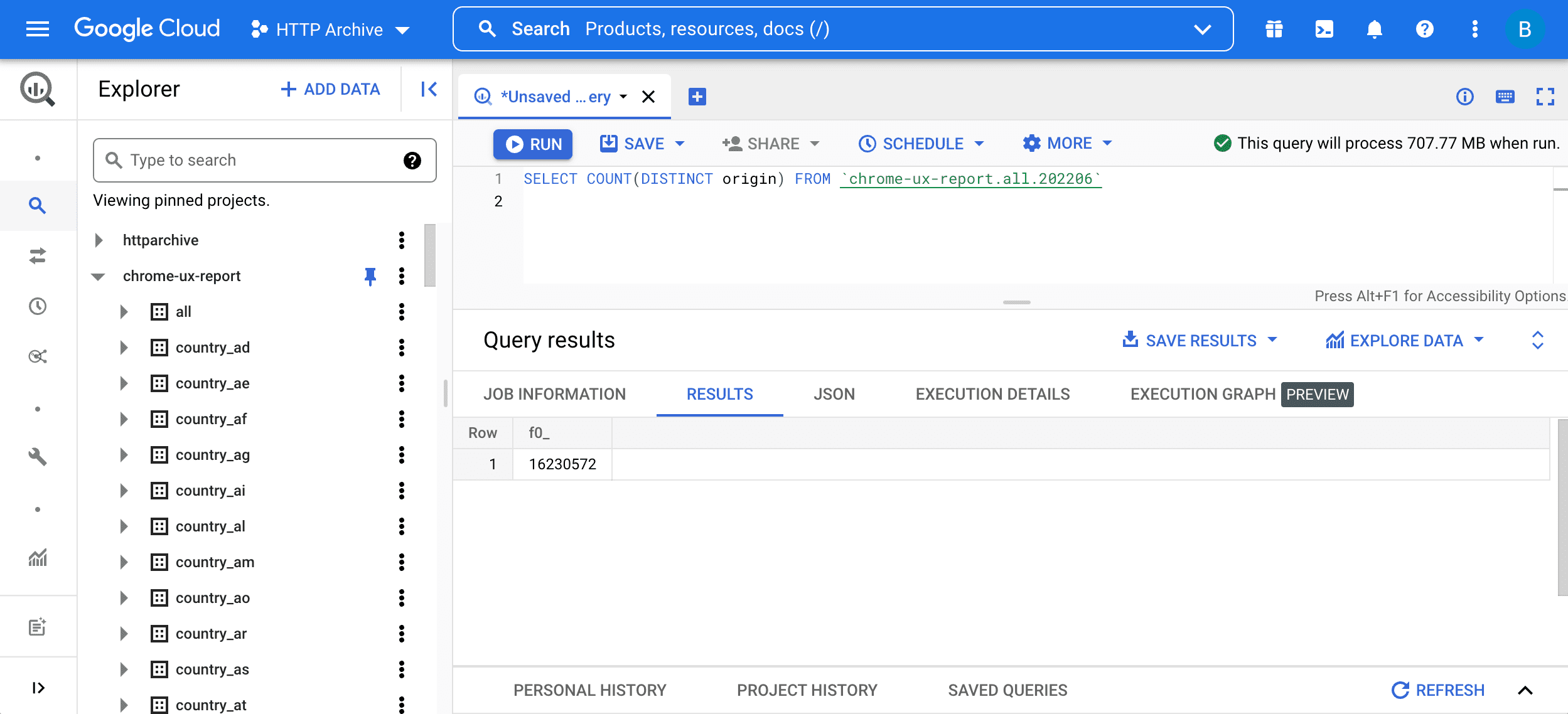
Questa query è composta da due parti:
SELECT COUNT(DISTINCT origin)indica la query per il numero di origini nella tabella. In termini generali, due URL fanno parte della stessa origine se hanno lo stesso schema, lo stesso host e la stessa porta.FROM chrome-ux-report.all.202206specifica l'indirizzo della tabella di origine, che è composta da tre parti:- Il nome del progetto Cloud
chrome-ux-reportin cui sono organizzati tutti i dati di CrUX - Il set di dati
all, che rappresenta i dati di tutti i paesi - La tabella
202206, l'anno e il mese dei dati nel formato AAAAMM
- Il nome del progetto Cloud
Esistono anche set di dati per ogni paese. Ad esempio, chrome-ux-report.country_ca.202206 rappresenta solo i dati sull'esperienza utente provenienti dal Canada.
In ogni set di dati sono presenti tabelle per ogni mese a partire da ottobre 2017. Le nuove tabelle per il mese di calendario precedente vengono pubblicate regolarmente.
La struttura delle tabelle di dati (nota anche come schema) contiene:
- L'origine, ad esempio
origin = 'https://www.example.com', che rappresenta la distribuzione aggregata dell'esperienza utente per tutte le pagine del sito web - La velocità di connessione al momento del caricamento della pagina, ad esempio
effective_connection_type.name = '4G'(rimosso da febbraio 2025) - Il tipo di dispositivo, ad esempio
form_factor.name = 'desktop' - Le metriche UX stesse
I dati relativi a ogni metrica sono organizzati come un array di oggetti. In notazione JSON, first_contentful_paint.histogram.bin avrà un aspetto simile al seguente:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Ogni intervallo contiene una data e un'ora di inizio e di fine in millisecondi e una densità che rappresenta la percentuale di esperienze utente all'interno di quell'intervallo di tempo. In altre parole, il 12, 34% delle esperienze FCP per questa origine ipotetica, velocità di connessione e tipo di dispositivo è inferiore a 100 ms. La somma di tutte le densità dei contenitori è pari al 100%.
Sfoglia la struttura delle tabelle in BigQuery.
Valutare il rendimento
Possiamo utilizzare le nostre conoscenze dello schema della tabella per scrivere una query che estragga questi dati sul rendimento.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
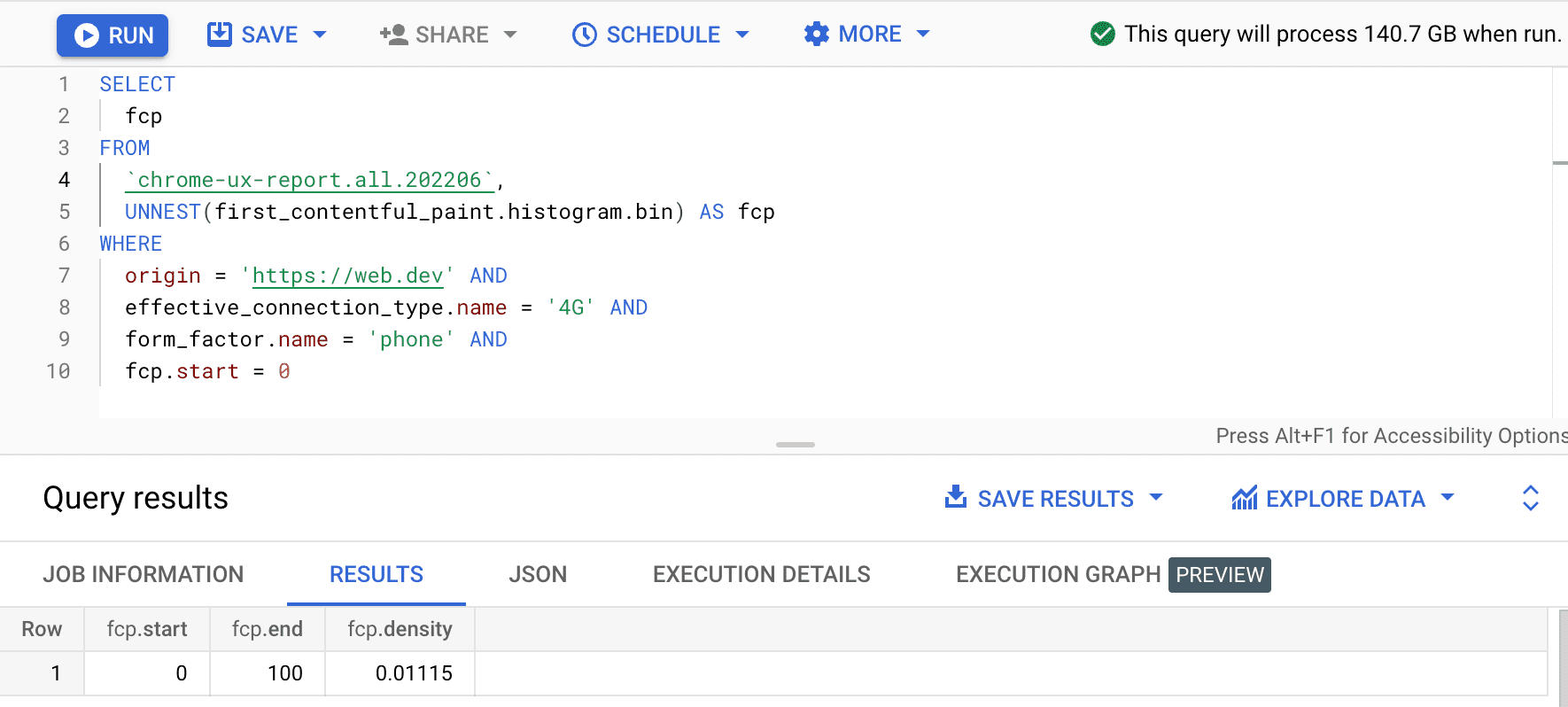
Il risultato è 0.01115, il che significa che l'1,115% delle esperienze utente in questa origine è compreso tra 0 e 100 ms su 4G e su uno smartphone. Se vogliamo generalizzare la query a qualsiasi connessione e a qualsiasi tipo di dispositivo, possiamo ometterli dalla clausola WHERE e utilizzare la funzione di aggregazione SUM per sommare tutte le rispettive densità dei bin:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
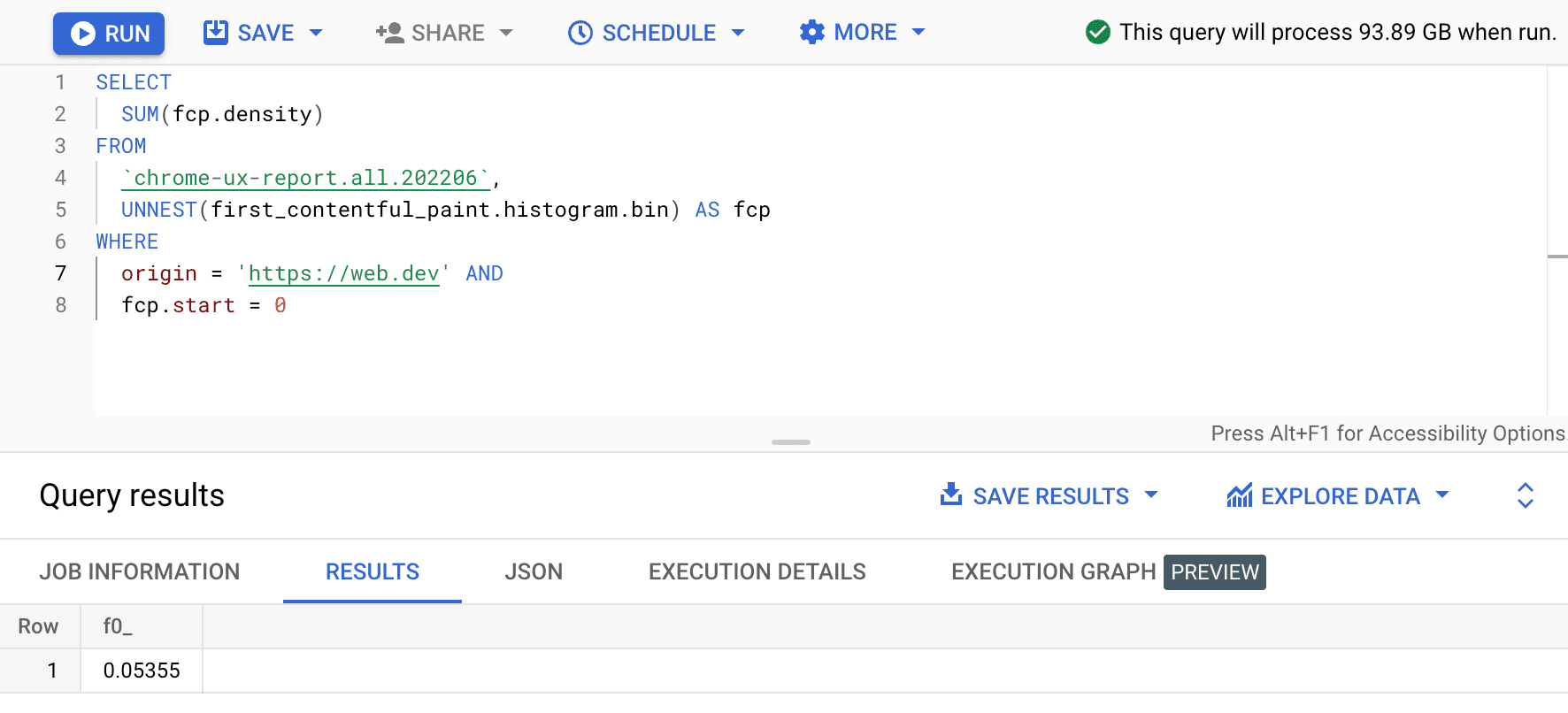
Il risultato è 0.05355, ovvero il 5,355% su tutti i dispositivi e i tipi di connessione. Possiamo modificare leggermente la query e sommare le densità per tutti i bucket che rientrano nell'intervallo FCP "veloce" compreso tra 0 e 1000 ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
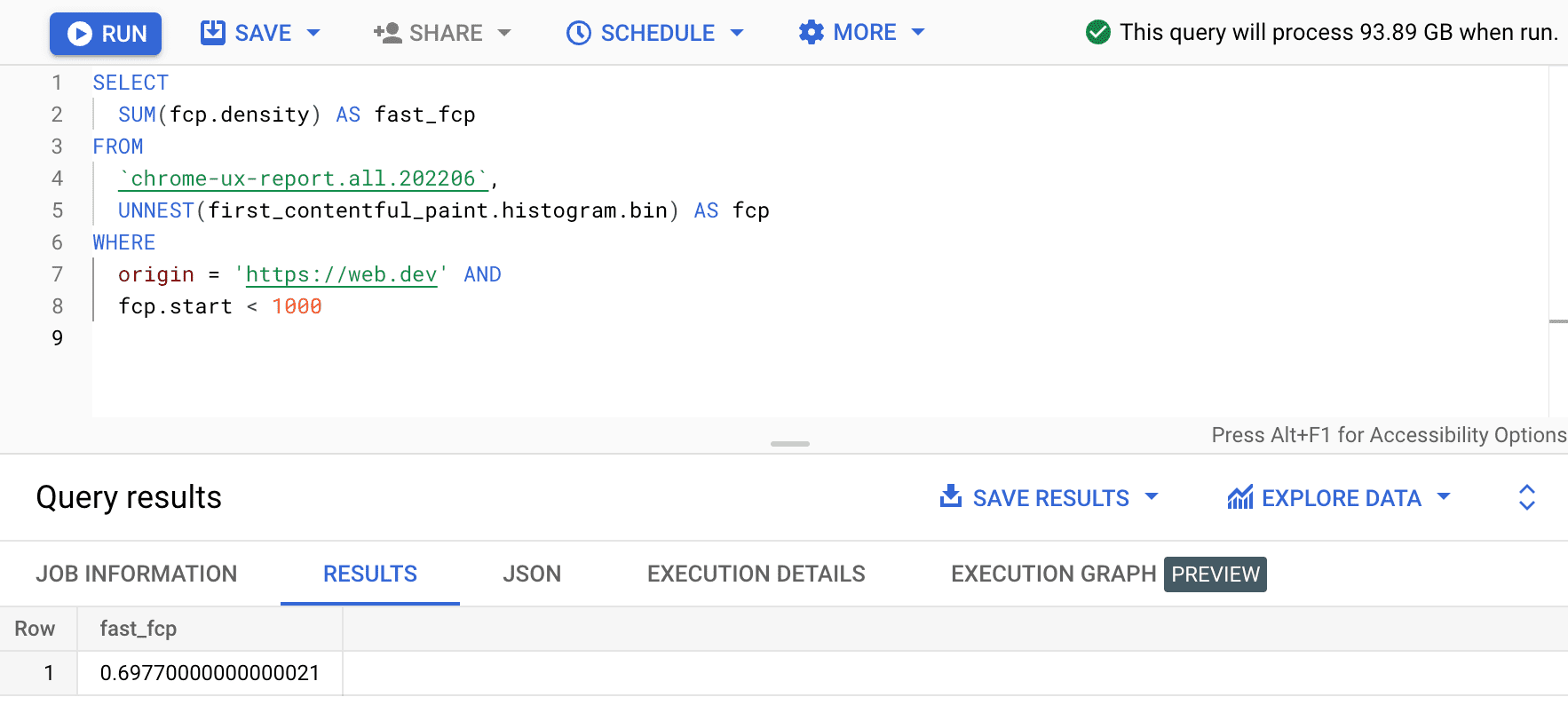
Questo ci dà 0.6977. In altre parole, il 69,77% delle esperienze utente FCP su web.dev è considerato "rapido" in base alla definizione dell'intervallo FCP.
Monitora le prestazioni
Ora che abbiamo estratto i dati sul rendimento di un'origine, possiamo confrontarli con i dati storici disponibili nelle tabelle precedenti. Per farlo, potremmo riscrivere l'indirizzo della tabella in un mese precedente oppure utilizzare la sintassi dei caratteri jolly per eseguire query su tutti i mesi:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
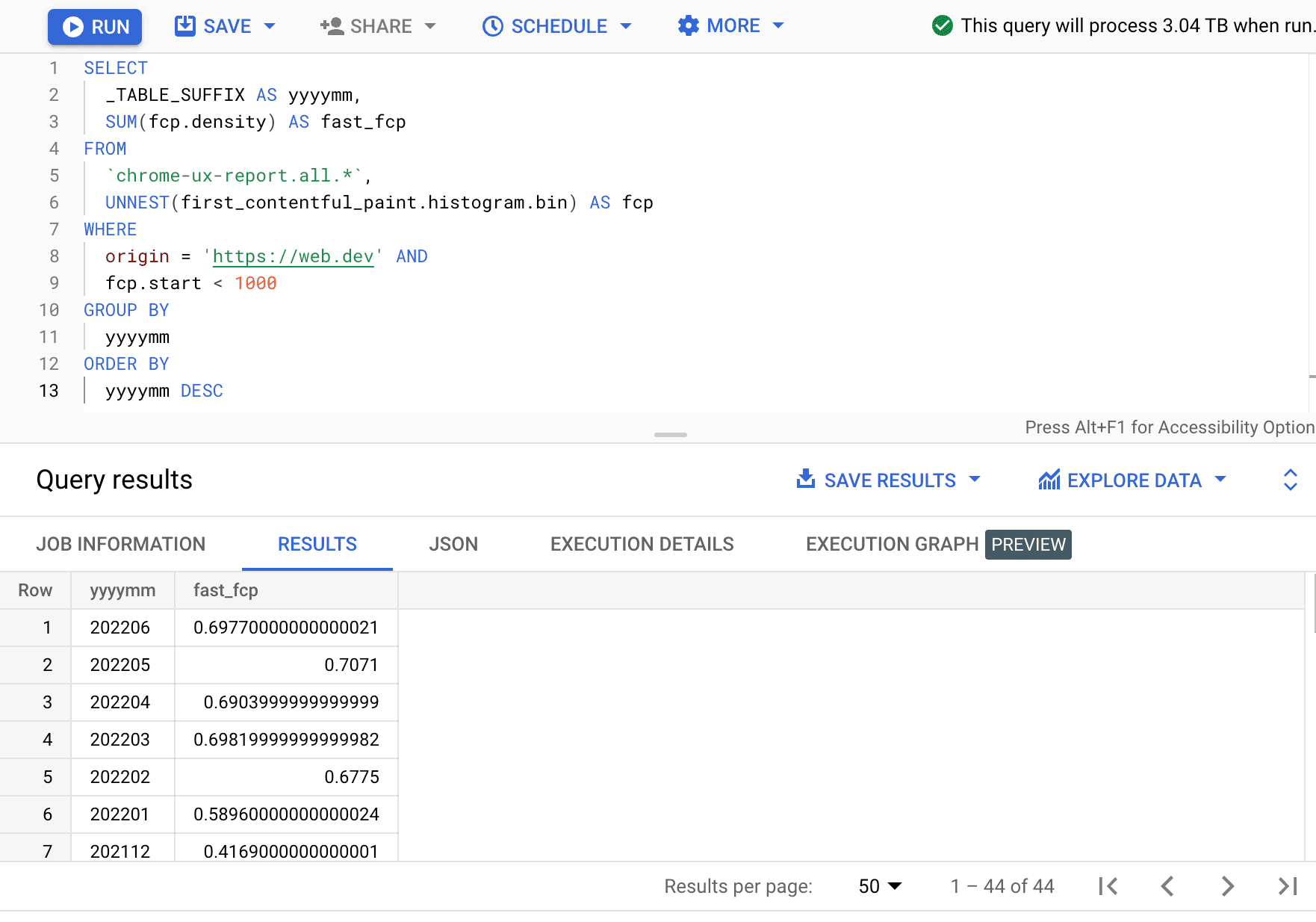
Qui vediamo che la percentuale di esperienze FCP rapide varia di alcuni punti percentuali ogni mese.
| aaaamm | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| … | … |
Con queste tecniche, puoi esaminare il rendimento di un'origine, calcolare la percentuale di esperienze rapide e monitorarla nel tempo. Come passaggio successivo, prova a eseguire query per due o più origini e confronta il loro rendimento.
Domande frequenti
Di seguito sono riportate alcune delle domande frequenti sul set di dati BigQuery CrUX:
Quando conviene utilizzare BigQuery rispetto ad altri strumenti?
BigQuery è necessario solo quando non riesci a ottenere le stesse informazioni da altri strumenti come la dashboard CrUX e PageSpeed Insights. Ad esempio, BigQuery ti consente di suddividere i dati in modo significativo e persino di unirli ad altri set di dati pubblici come HTTP Archive per eseguire attività di data mining avanzate.
Esistono limitazioni all'utilizzo di BigQuery?
Sì, la limitazione più importante è che per impostazione predefinita gli utenti possono eseguire query solo su 1 TB di dati al mese. Oltre questa quantità, si applica la tariffa standard di 5 $/TB.
Dove posso trovare ulteriori informazioni su BigQuery?
Per ulteriori informazioni, consulta la documentazione di BigQuery.