

De ruwe data van het Chrome UX Report ( CrUX ) zijn beschikbaar op BigQuery , een database op Google Cloud. Om BigQuery te gebruiken, hebt u een GCP-project en basiskennis van SQL nodig.
In deze handleiding leert u hoe u BigQuery kunt gebruiken om query's te schrijven op de CrUX-dataset om verhelderende resultaten te verkrijgen over de status van gebruikerservaringen op het web:
- Begrijp hoe de gegevens zijn georganiseerd
- Schrijf een eenvoudige query om de prestaties van een oorsprong te evalueren
- Schrijf een geavanceerde query om de prestaties in de loop van de tijd te volgen
Gegevensorganisatie
Begin met het bekijken van een eenvoudige query:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Om de query uit te voeren, voert u deze in de query-editor in en klikt u op de knop "Query uitvoeren":
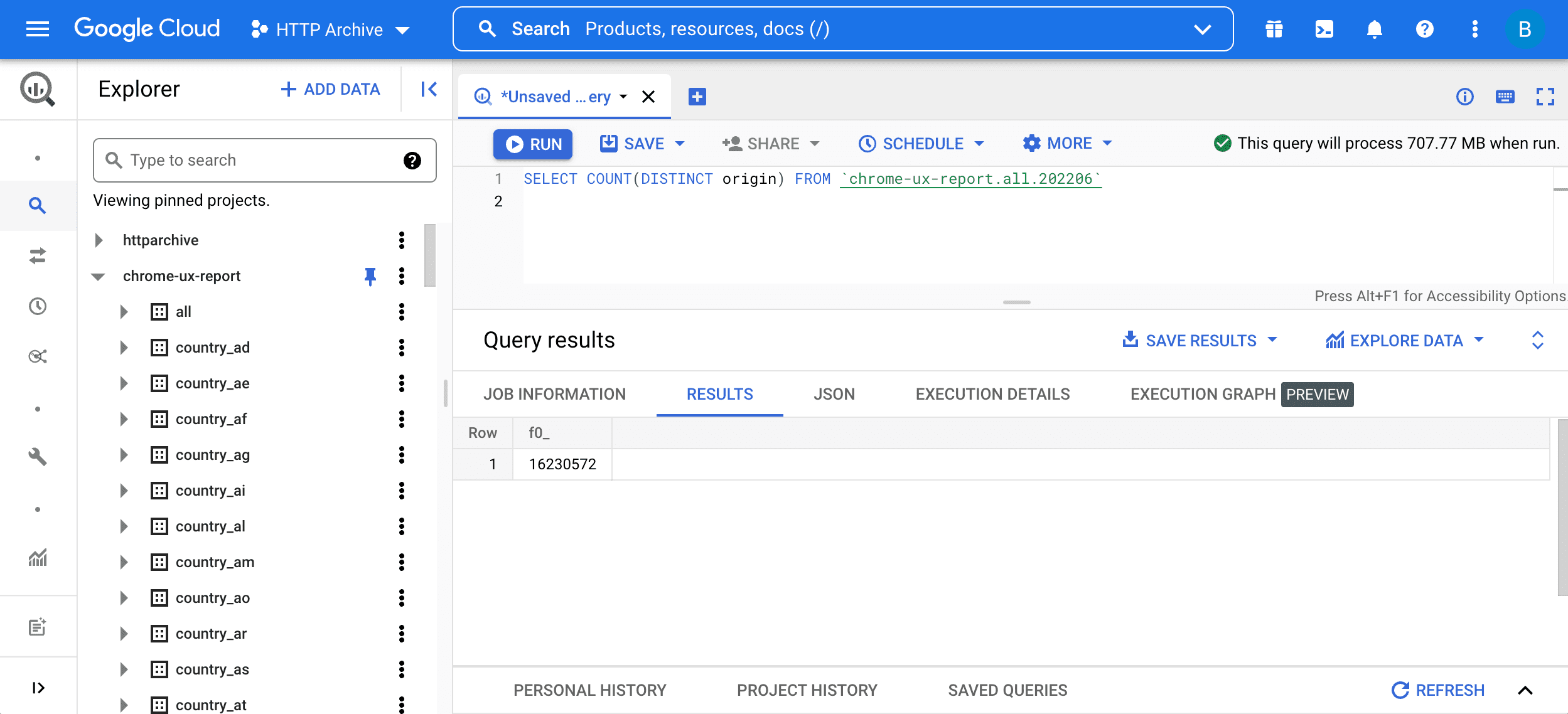
Deze query bestaat uit twee delen:
SELECT COUNT(DISTINCT origin)betekent dat er een query wordt uitgevoerd naar het aantal oorsprongen in de tabel. Grofweg gesproken maken twee URL's deel uit van dezelfde oorsprong als ze hetzelfde schema, dezelfde host en dezelfde poort hebben.FROM chrome-ux-report.all.202206specificeert het adres van de brontabel, die uit drie delen bestaat:- De Cloud-projectnaam
chrome-ux-reportwaarin alle CrUX-gegevens zijn georganiseerd - De dataset
all, die gegevens over alle landen vertegenwoordigt - Tabel
202206, het jaar en de maand van de gegevens in JJJJMM-formaat
- De Cloud-projectnaam
Er zijn ook datasets voor elk land. chrome-ux-report.country_ca.202206 geeft bijvoorbeeld alleen de gebruikerservaringsgegevens uit Canada weer.
Binnen elke dataset zijn er tabellen voor elke maand sinds 201710. Regelmatig worden nieuwe tabellen voor de voorgaande kalendermaand gepubliceerd.
De structuur van de gegevenstabellen (ook wel schema genoemd) bevat:
- De oorsprong, bijvoorbeeld
origin = 'https://www.example.com', die de totale distributie van de gebruikerservaring voor alle pagina's op die website weergeeft - De verbindingssnelheid op het moment dat de pagina wordt geladen, bijvoorbeeld
effective_connection_type.name = '4G'( verwijderd vanaf februari 2025 ) - Het apparaattype, bijvoorbeeld
form_factor.name = 'desktop' - De UX-metrieken zelf
De gegevens voor elke metriek worden georganiseerd als een array van objecten. In JSON-notatie zou first_contentful_paint.histogram.bin er ongeveer zo uitzien:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Elke bin bevat een start- en eindtijd in milliseconden en een dichtheid die het percentage gebruikerservaringen binnen dat tijdsbestek weergeeft. Met andere woorden: 12,34% van de FCP-ervaringen voor deze hypothetische oorsprong, verbindingssnelheid en apparaattype duurt minder dan 100 ms. De som van alle bindichtheden is 100%.
Bekijk de structuur van de tabellen in BigQuery.
Prestaties evalueren
We kunnen onze kennis van het tabelschema gebruiken om een query te schrijven die deze prestatiegegevens extraheert.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
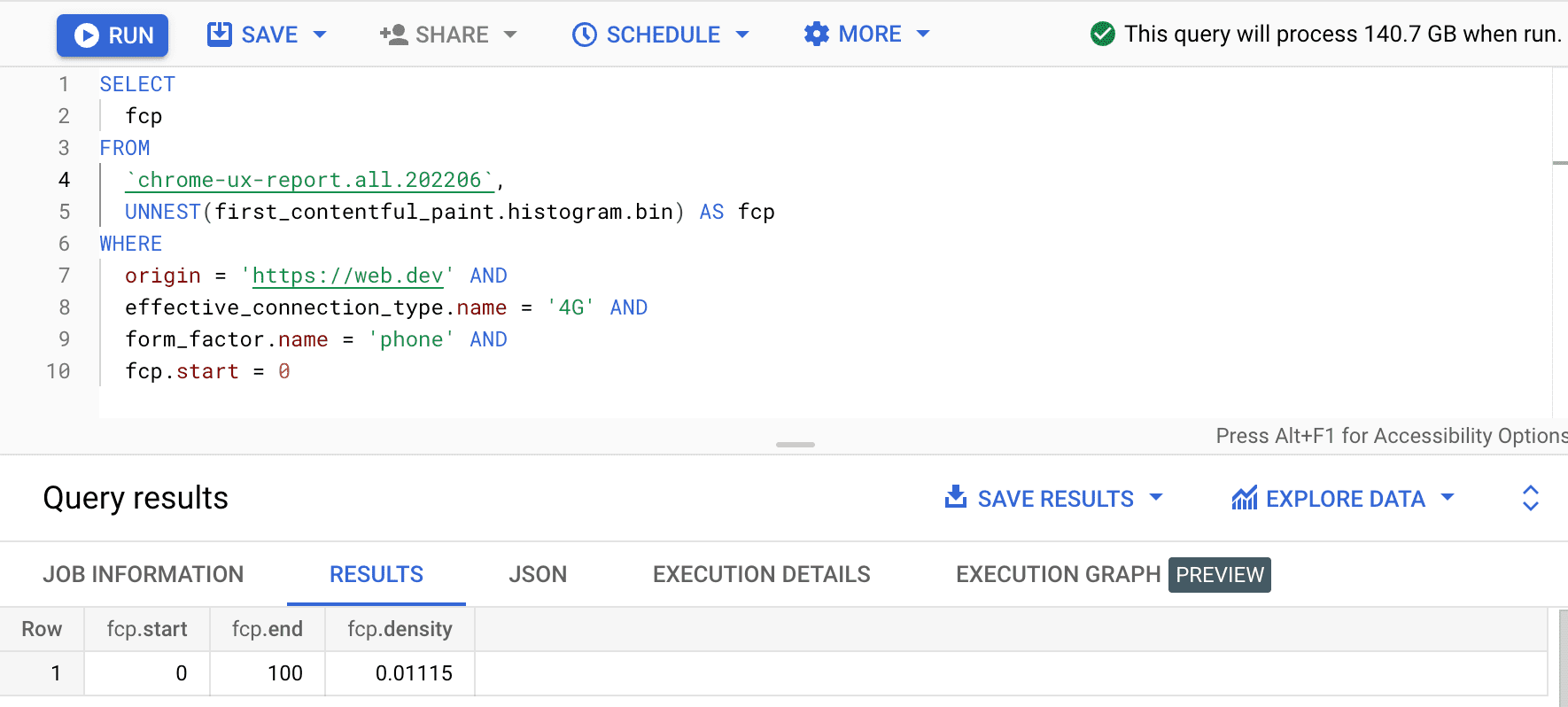
Het resultaat is 0.01115 , wat betekent dat 1,115% van de gebruikerservaringen op deze oorsprong tussen 0 en 100 ms liggen op 4G en op een telefoon. Als we onze query willen generaliseren naar elke verbinding en elk apparaattype, kunnen we deze weglaten uit de WHERE -component en de aggregatorfunctie SUM gebruiken om al hun respectievelijke bin-dichtheden op te tellen:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
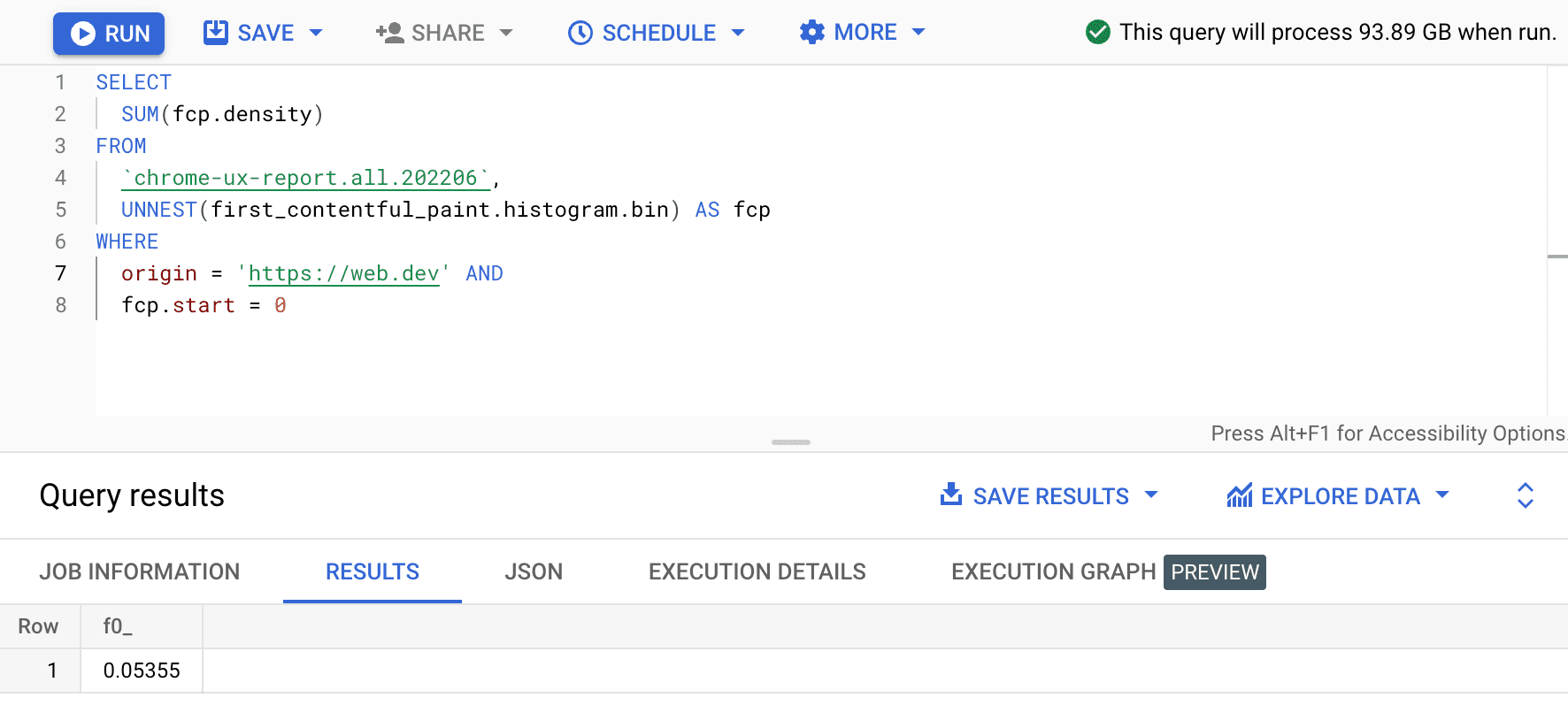
Het resultaat is 0.05355 , oftewel 5,355% voor alle apparaten en verbindingstypen. We kunnen de query enigszins aanpassen en de dichtheden optellen voor alle bins die zich in het "snelle" FCP-bereik van 0–1000 ms bevinden:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
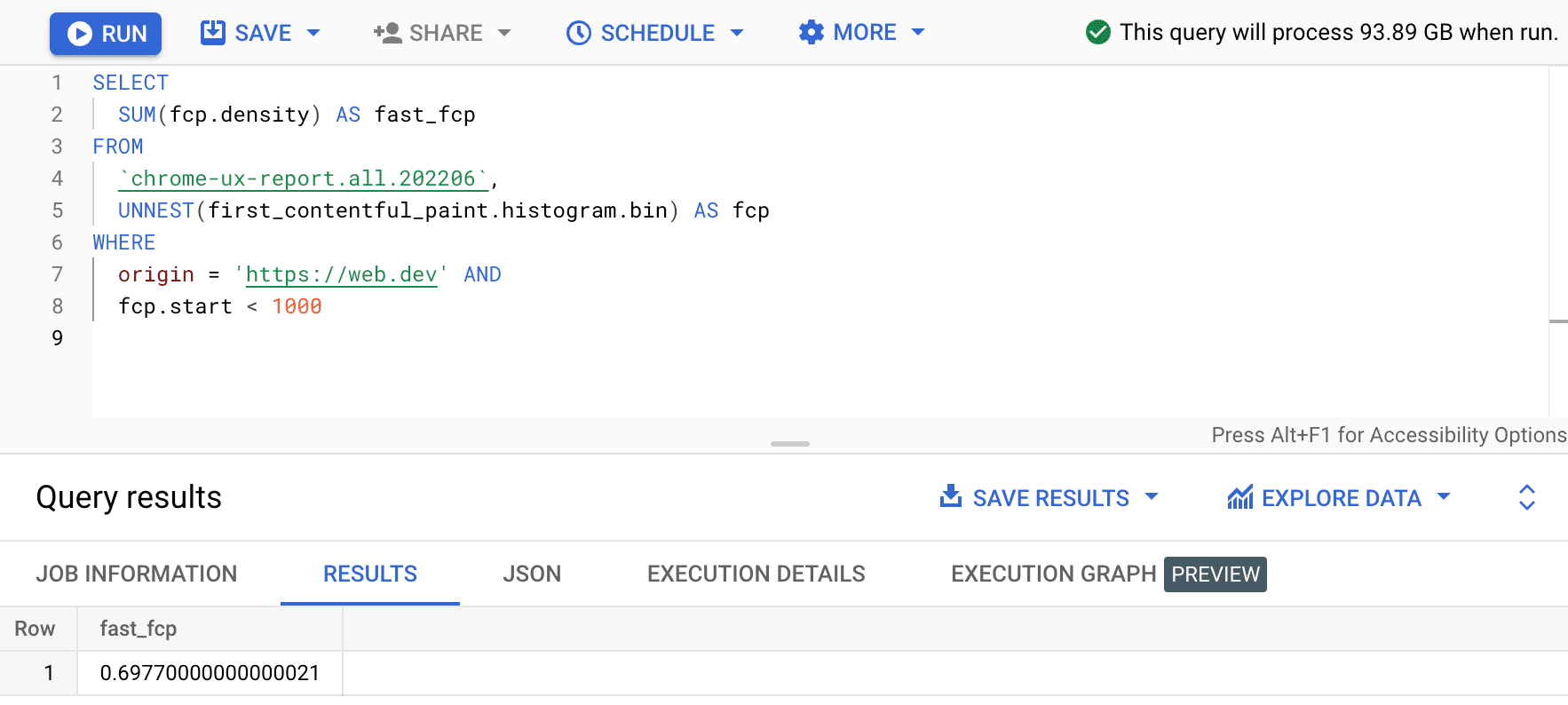
Dit geeft ons 0.6977 . Met andere woorden: 69,77% van de FCP-gebruikerservaringen op web.dev wordt als 'snel' beschouwd volgens de FCP-bereikdefinitie.
Volg prestaties
Nu we prestatiegegevens over een oorsprong hebben geëxtraheerd, kunnen we deze vergelijken met de historische gegevens die beschikbaar zijn in oudere tabellen. Om dat te doen, kunnen we het tabeladres herschrijven naar een eerdere maand, of we kunnen de wildcard-syntaxis gebruiken om alle maanden te bevragen:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
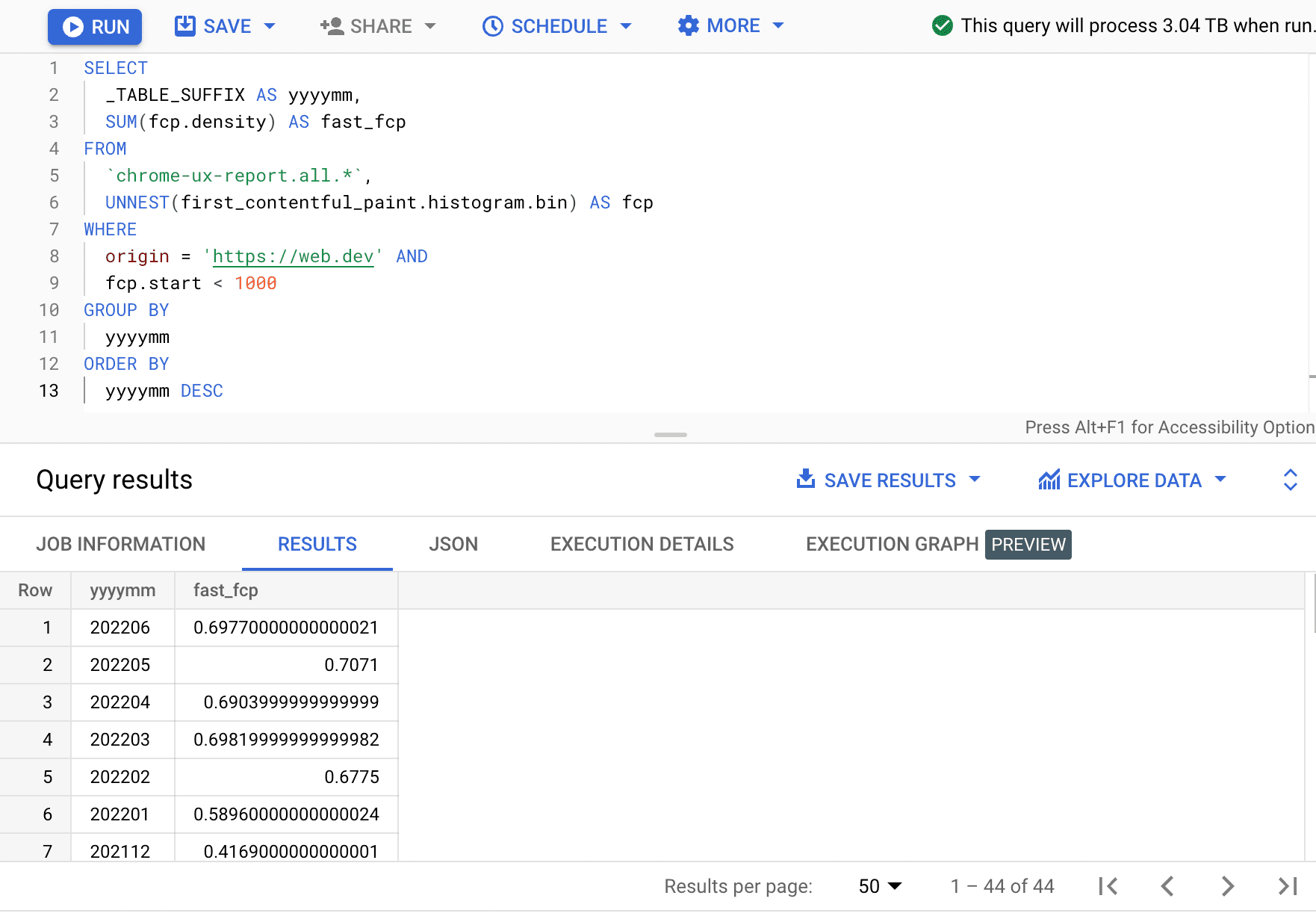
Hier zien we dat het percentage snelle FCP-ervaringen elke maand met een paar procentpunten varieert.
| jjjjmm | snelle_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| ... | ... |
Met deze technieken kunt u de prestaties van een oorsprong opzoeken, het percentage snelle ervaringen berekenen en deze in de loop van de tijd volgen. Probeer vervolgens query's uit te voeren voor twee of meer oorsprongen en hun prestaties te vergelijken.
Veelgestelde vragen
Dit zijn enkele veelgestelde vragen over de CrUX BigQuery-dataset:
Wanneer zou ik BigQuery gebruiken in plaats van andere tools?
BigQuery is alleen nodig wanneer je dezelfde informatie niet kunt halen uit andere tools zoals het CrUX Dashboard en PageSpeed Insights. Met BigQuery kun je de data bijvoorbeeld op zinvolle manieren opsplitsen en zelfs koppelen aan andere openbare datasets zoals het HTTP Archive voor geavanceerde datamining.
Zijn er beperkingen aan het gebruik van BigQuery?
Ja, de belangrijkste beperking is dat gebruikers standaard slechts 1 TB aan data per maand kunnen opvragen. Daarboven geldt het standaardtarief van $ 5/TB.
Waar kan ik meer informatie over BigQuery vinden?
Raadpleeg de BigQuery-documentatie voor meer informatie.