

Les données brutes du rapport sur l'expérience utilisateur Chrome (CrUX) sont disponibles dans BigQuery, une base de données sur Google Cloud. Pour utiliser BigQuery, vous devez disposer d'un projet GCP et de connaissances de base en SQL.
Dans ce guide, vous allez apprendre à utiliser BigQuery pour écrire des requêtes sur l'ensemble de données CrUX afin d'extraire des résultats instructifs sur l'état des expériences utilisateur sur le Web:
- Comprendre l'organisation des données
- Écrire une requête de base pour évaluer les performances d'une origine
- Écrire une requête avancée pour suivre les performances au fil du temps
Organisation des données
Commencez par examiner une requête de base:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Pour exécuter la requête, saisissez-la dans l'éditeur de requête, puis appuyez sur le bouton "Exécuter la requête" :
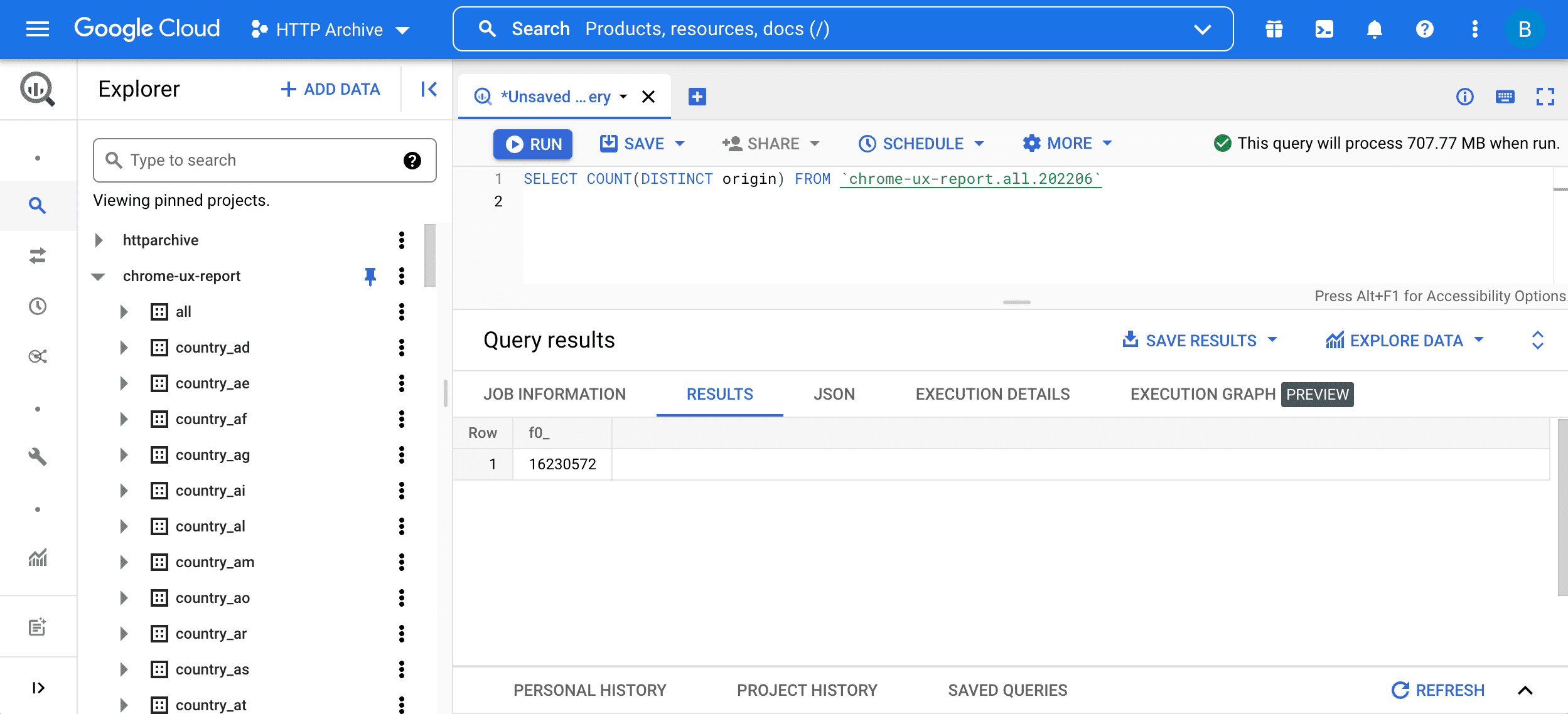
Cette requête se compose de deux parties:
SELECT COUNT(DISTINCT origin)permet d'interroger le nombre d'origines dans la table. En gros, deux URL appartiennent à la même origine si elles ont le même schéma, le même hôte et le même port.FROM chrome-ux-report.all.202206spécifie l'adresse de la table source, qui se compose de trois parties:- Nom du projet Cloud
chrome-ux-reportdans lequel toutes les données CrUX sont organisées - L'ensemble de données
all, qui représente les données de tous les pays - La table
202206, l'année et le mois des données au format AAAAMM
- Nom du projet Cloud
Des ensembles de données sont également disponibles pour chaque pays. Par exemple, chrome-ux-report.country_ca.202206 ne représente que les données sur l'expérience utilisateur provenant du Canada.
Chaque ensemble de données contient des tableaux pour chaque mois depuis 201710. De nouveaux tableaux pour le mois calendaire précédent sont publiés régulièrement.
La structure des tables de données (également appelée schéma) contient les éléments suivants:
- L'origine, par exemple
origin = 'https://www.example.com', qui représente la distribution globale de l'expérience utilisateur pour toutes les pages de ce site Web - Vitesse de connexion au moment du chargement de la page, par exemple
effective_connection_type.name = '4G'(supprimée depuis février 2025) - Type d'appareil (par exemple,
form_factor.name = 'desktop') - Les métriques UX elles-mêmes
Les données de chaque métrique sont organisées en tableau d'objets. En notation JSON, first_contentful_paint.histogram.bin se présente comme suit:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Chaque bin contient une heure de début et de fin en millisecondes, ainsi qu'une densité représentant le pourcentage d'expériences utilisateur dans cette plage de temps. En d'autres termes, 12, 34% des expériences FCP pour cette origine hypothétique, cette vitesse de connexion et ce type d'appareil sont inférieures à 100 ms. La somme de toutes les densités de bacs est de 100%.
Parcourez la structure des tables dans BigQuery.
Évaluer les performances
Nous pouvons utiliser nos connaissances du schéma de la table pour écrire une requête qui extrait ces données de performances.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
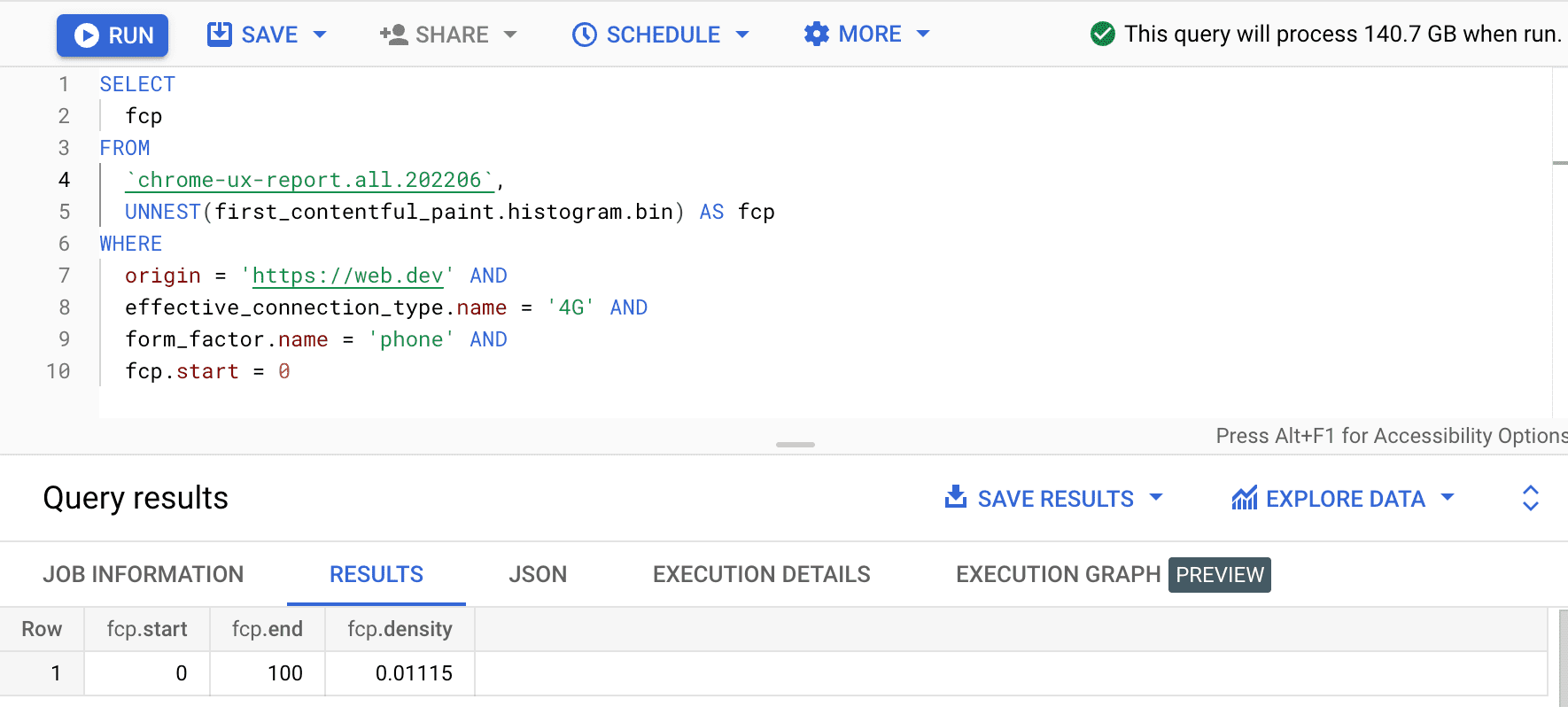
Le résultat est 0.01115, ce qui signifie que 1,115% des expériences utilisateur sur cette origine sont comprises entre 0 et 100 ms en 4G et sur un téléphone. Si nous souhaitons généraliser notre requête à n'importe quelle connexion et à n'importe quel type d'appareil, nous pouvons les omettre de la clause WHERE et utiliser la fonction d'agrégation SUM pour additionner toutes leurs densités de bacs respectives:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
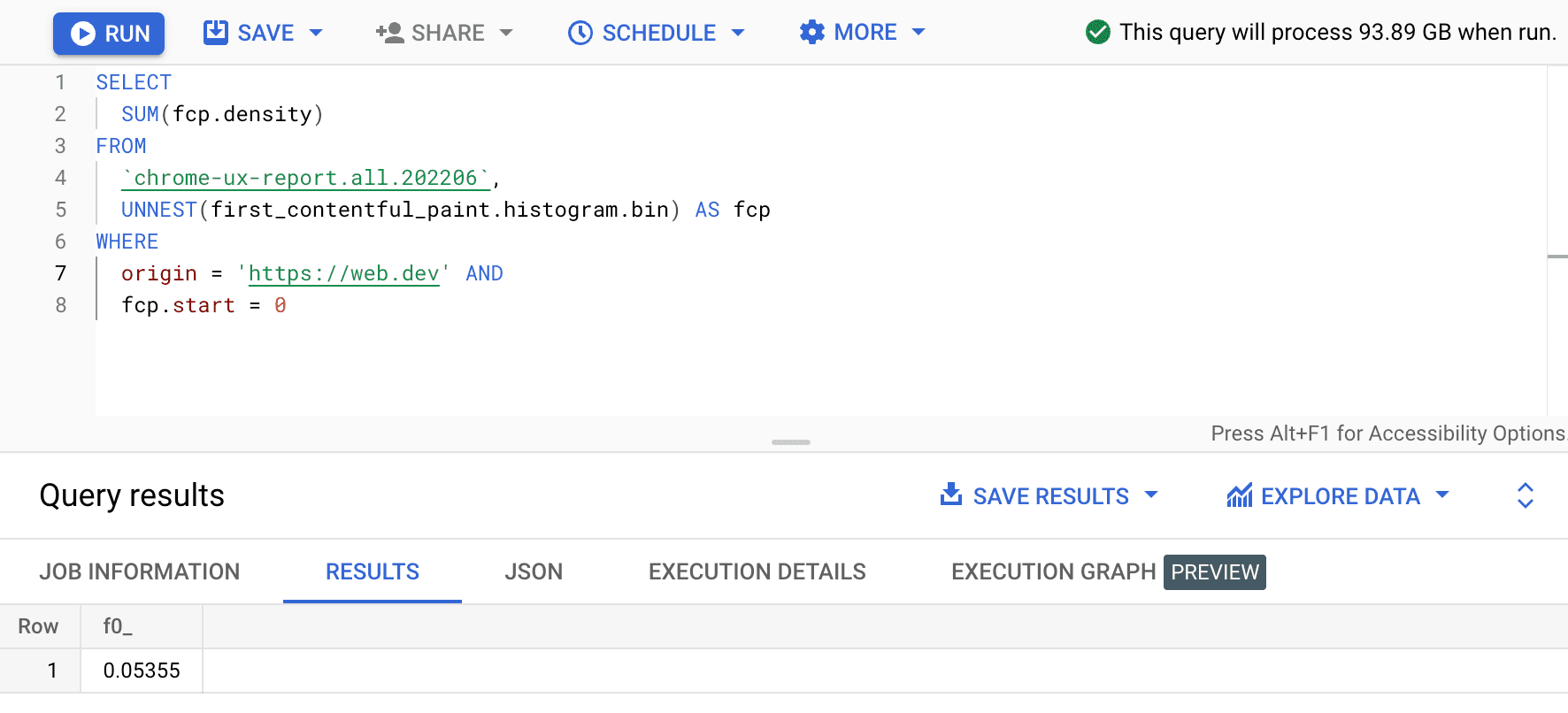
Le résultat est 0.05355, soit 5,355% pour tous les appareils et types de connexion. Nous pouvons modifier légèrement la requête et additionner les densités de tous les bacs compris dans la plage de FCP "rapide" de 0 à 1 000 ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
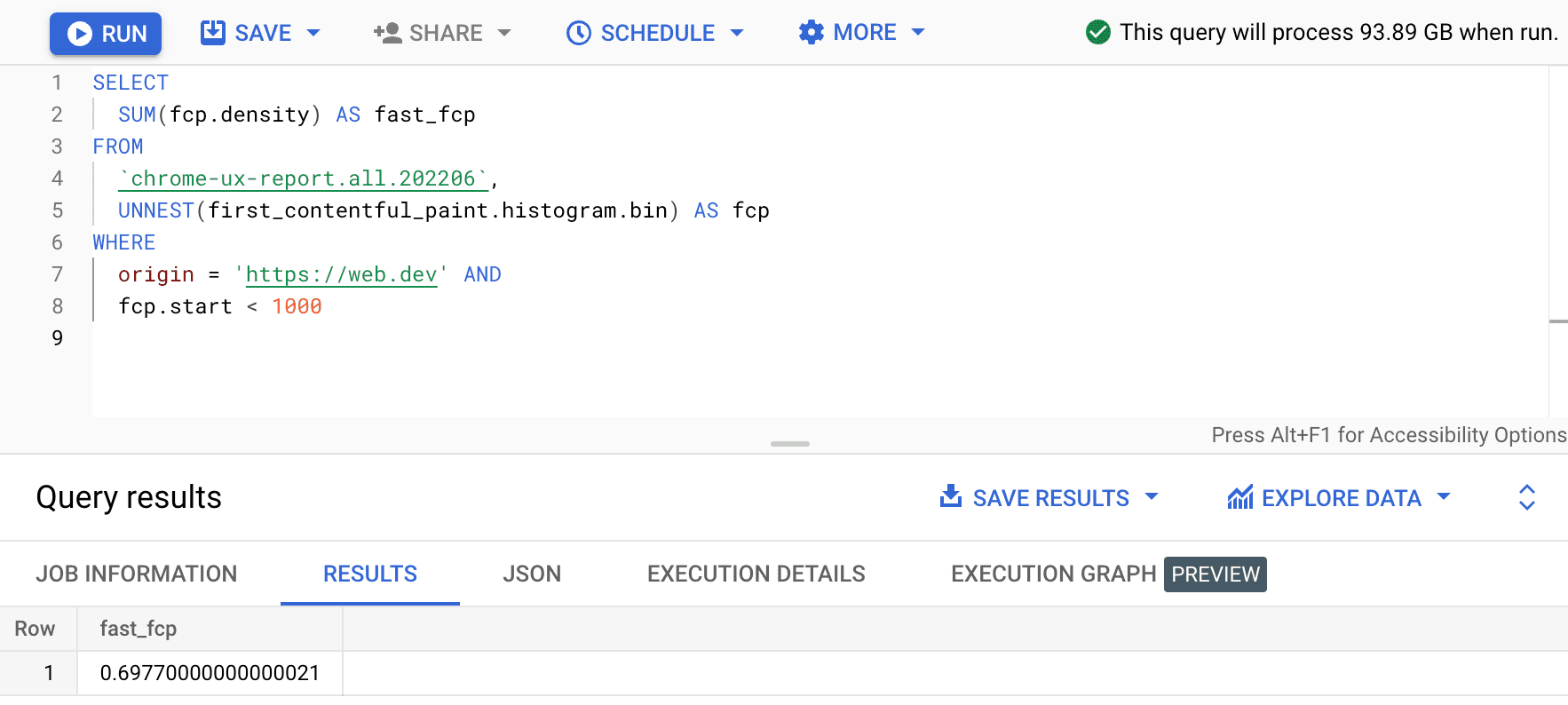
Nous obtenons ainsi 0.6977. En d'autres termes, 69,77% des expériences utilisateur FCP sur web.dev sont considérées comme "rapides" selon la définition de la plage FCP.
Suivre les performances
Maintenant que nous avons extrait les données de performances d'une origine, nous pouvons les comparer aux données historiques disponibles dans les anciennes tables. Pour ce faire, nous pouvons remplacer l'adresse de la table par un mois antérieur ou utiliser la syntaxe de caractère générique pour interroger tous les mois:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
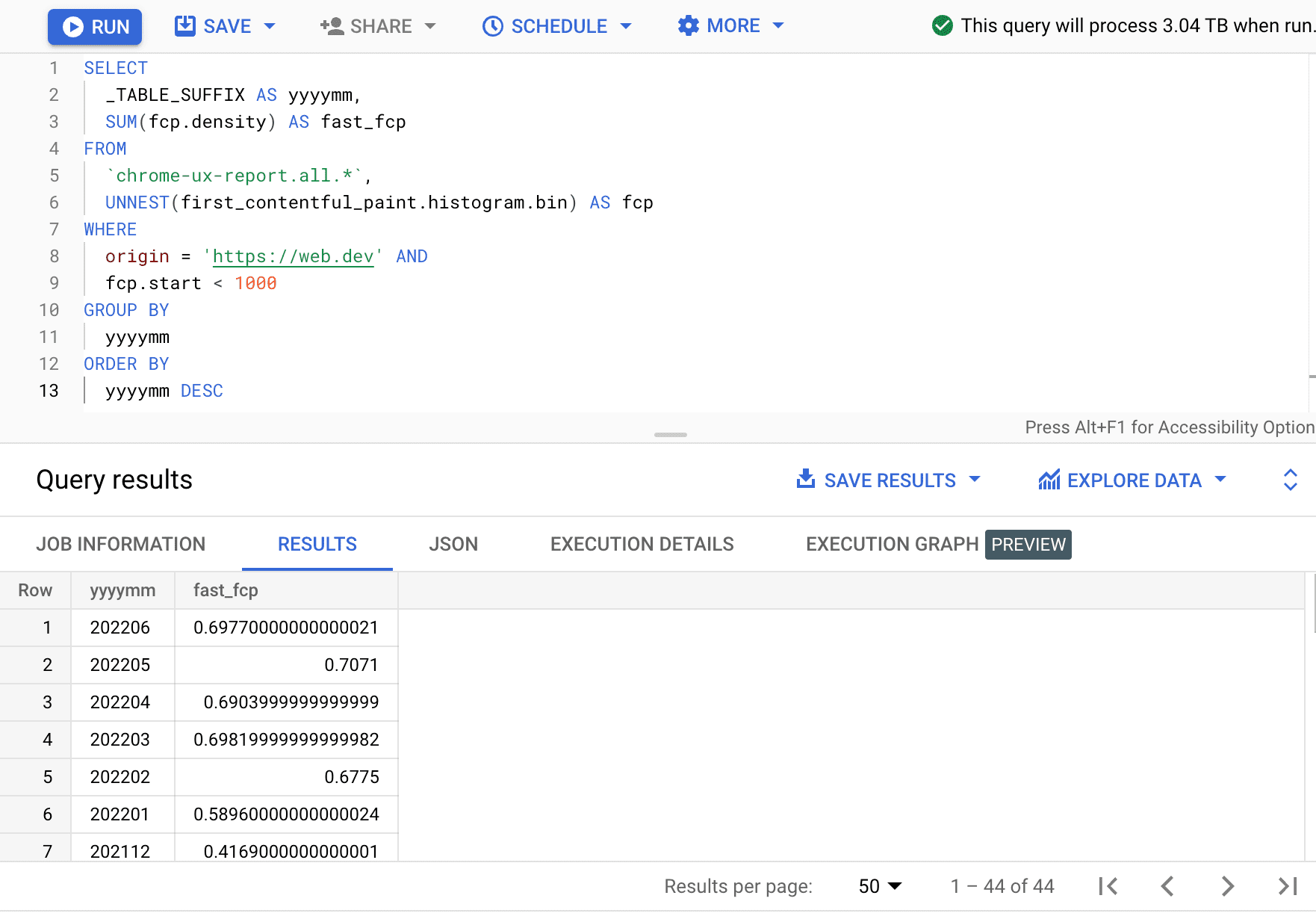
Ici, nous constatons que le pourcentage d'expériences FCP rapides varie de quelques points de pourcentage chaque mois.
| aaaamm | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| … | … |
Grâce à ces techniques, vous pouvez consulter les performances d'une origine, calculer le pourcentage d'expériences rapides et le suivre au fil du temps. Essayez ensuite d'effectuer une requête pour deux origines ou plus et de comparer leurs performances.
Questions fréquentes
Voici quelques-unes des questions fréquentes sur l'ensemble de données BigQuery CrUX:
Quand utiliser BigQuery plutôt que d'autres outils ?
BigQuery n'est nécessaire que lorsque vous ne pouvez pas obtenir les mêmes informations à partir d'autres outils, tels que le tableau de bord CrUX et PageSpeed Insights. Par exemple, BigQuery vous permet de découper les données de manière pertinente et même de les joindre à d'autres ensembles de données publics tels que l'archive HTTP pour effectuer une analyse de données avancée.
L'utilisation de BigQuery est-elle soumise à des limites ?
Oui, la limite la plus importante est que, par défaut, les utilisateurs ne peuvent interroger que 1 To de données par mois. Au-delà, le tarif standard de 5 $/To s'applique.
Où puis-je en savoir plus sur BigQuery ?
Pour en savoir plus, consultez la documentation BigQuery.