

Chrome UX レポート(CrUX)の元データは、Google Cloud 上のデータベースである BigQuery で利用できます。BigQuery を使用するには、GCP プロジェクトと SQL の基本的な知識が必要です。
このガイドでは、BigQuery を使用して CrUX データセットに対してクエリを作成し、ウェブ上のユーザー エクスペリエンスの状態に関する有益な結果を抽出する方法について説明します。
- データの整理方法を理解する
- 基本的なクエリを記述して送信元のパフォーマンスを評価する
- 高度なクエリを記述して、時間の経過に伴うパフォーマンスを追跡する
データ編成
まず、基本的なクエリを見てみましょう。
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
クエリを実行するには、クエリエディタにクエリを入力し、[クエリを実行] ボタンをクリックします。
![エディタに簡単なクエリを入力し、[実行] を押します。](https://developer.chrome.google.cn/static/docs/crux/guides/bigquery/image/enter-simple-query-edit-8e592aa68f55a.png?authuser=00&hl=ja)
このクエリには次の 2 つの部分があります。
SELECT COUNT(DISTINCT origin)は、テーブル内の出発地の数をクエリすることを意味します。大まかに言えば、2 つの URL のスキーム、ホスト、ポートが同じであれば、同じオリジンに属します。FROM chrome-ux-report.all.202206には、ソーステーブルのアドレスを指定します。このアドレスは 3 つの部分で構成されます。- すべての CrUX データが整理される Cloud プロジェクト名
chrome-ux-report - データセット
all: すべての国のデータを表します。 - テーブル
202206: データの年と月(YYYYMM 形式)
- すべての CrUX データが整理される Cloud プロジェクト名
各国のデータセットもあります。たとえば、chrome-ux-report.country_ca.202206 はカナダで発生したユーザー エクスペリエンス データのみを表します。
各データセットには、201710 以降の各月のテーブルがあります。前月の新しい表が定期的に公開されます。
データテーブルの構造(スキーマ)には、次のものが含まれます。
- オリジン(
origin = 'https://www.example.com'など)。そのウェブサイトのすべてのページのユーザー エクスペリエンスの集計分布を表します。 - ページの読み込み時の接続速度(例:
effective_connection_type.name = '4G')(2025 年 2 月をもって削除) - デバイスの種類(
form_factor.name = 'desktop'など) - UX 指標自体
各指標のデータは、オブジェクトの配列として編成されます。JSON 表記では、first_contentful_paint.histogram.bin は次のようになります。
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
各ビンには、開始時間と終了時間(ミリ秒単位)と、その期間内のユーザー エクスペリエンスの割合を表す密度が含まれます。つまり、この仮想的な送信元、接続速度、デバイスタイプにおける FCP の 12.34% は 100 ミリ秒未満です。すべてのビンの密度の合計は 100% です。
パフォーマンスを評価する
テーブル スキーマに関する知識を使用して、このパフォーマンス データを抽出するクエリを作成できます。
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
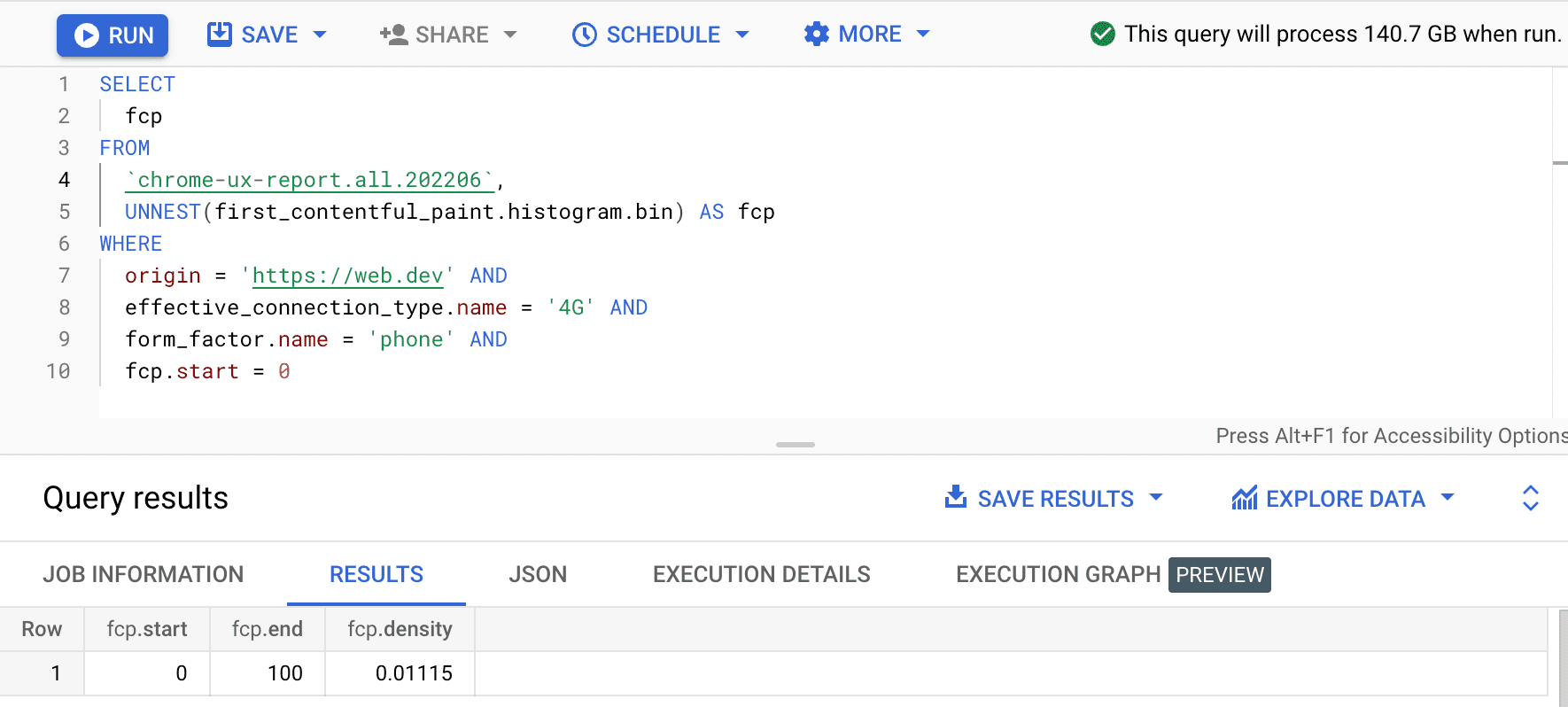
結果は 0.01115 です。つまり、このオリジンのユーザー エクスペリエンスの 1.115% は、4G とスマートフォンで 0 ~ 100 ms です。クエリを任意の接続とデバイスタイプに一般化するには、WHERE 句から接続とデバイスタイプを省略し、SUM 集計関数を使用して、それぞれのビン密度をすべて合計します。
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
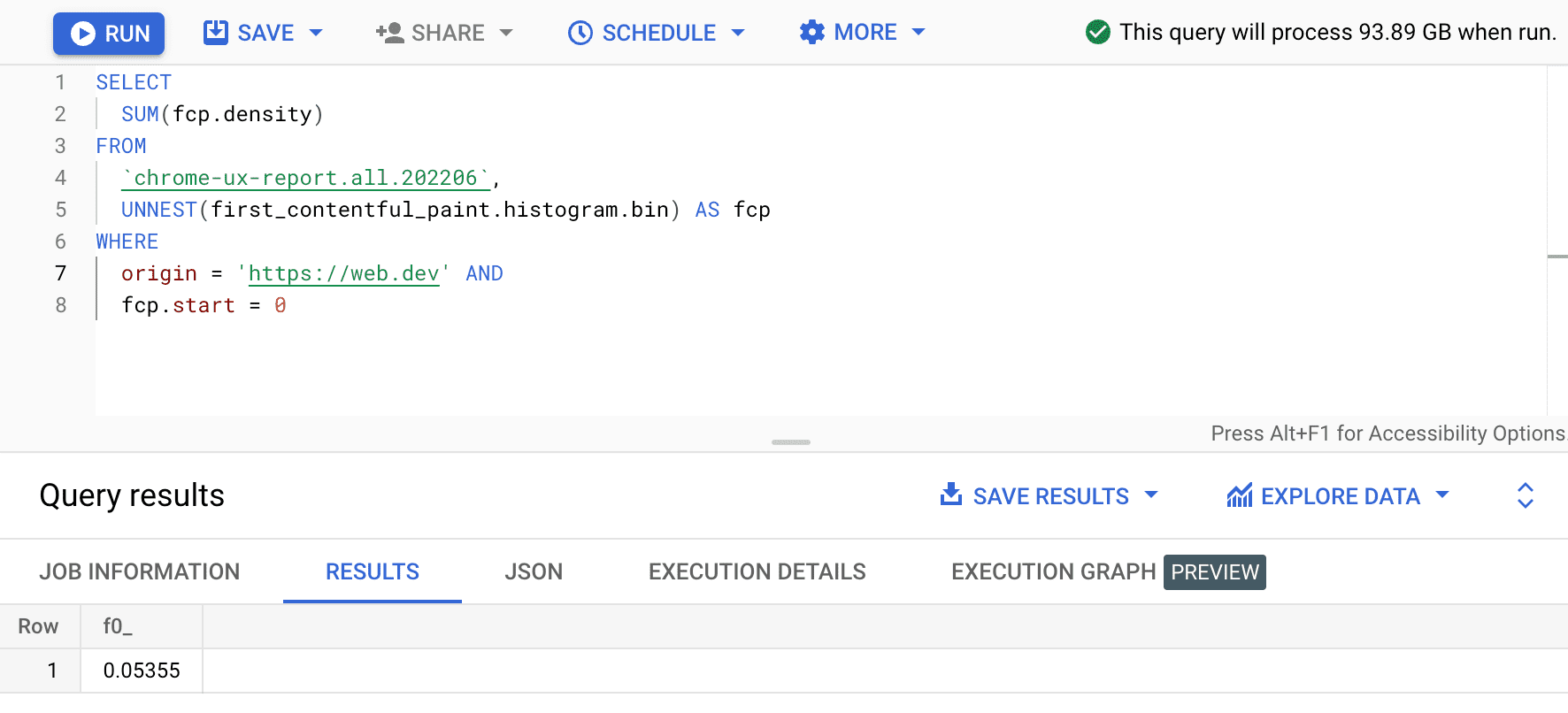
結果は 0.05355 で、すべてのデバイスと接続タイプで 5.355% です。クエリを少し変更して、0 ~ 1,000 ms の「高速」FCP 範囲内のすべてのビンの密度を合計できます。
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
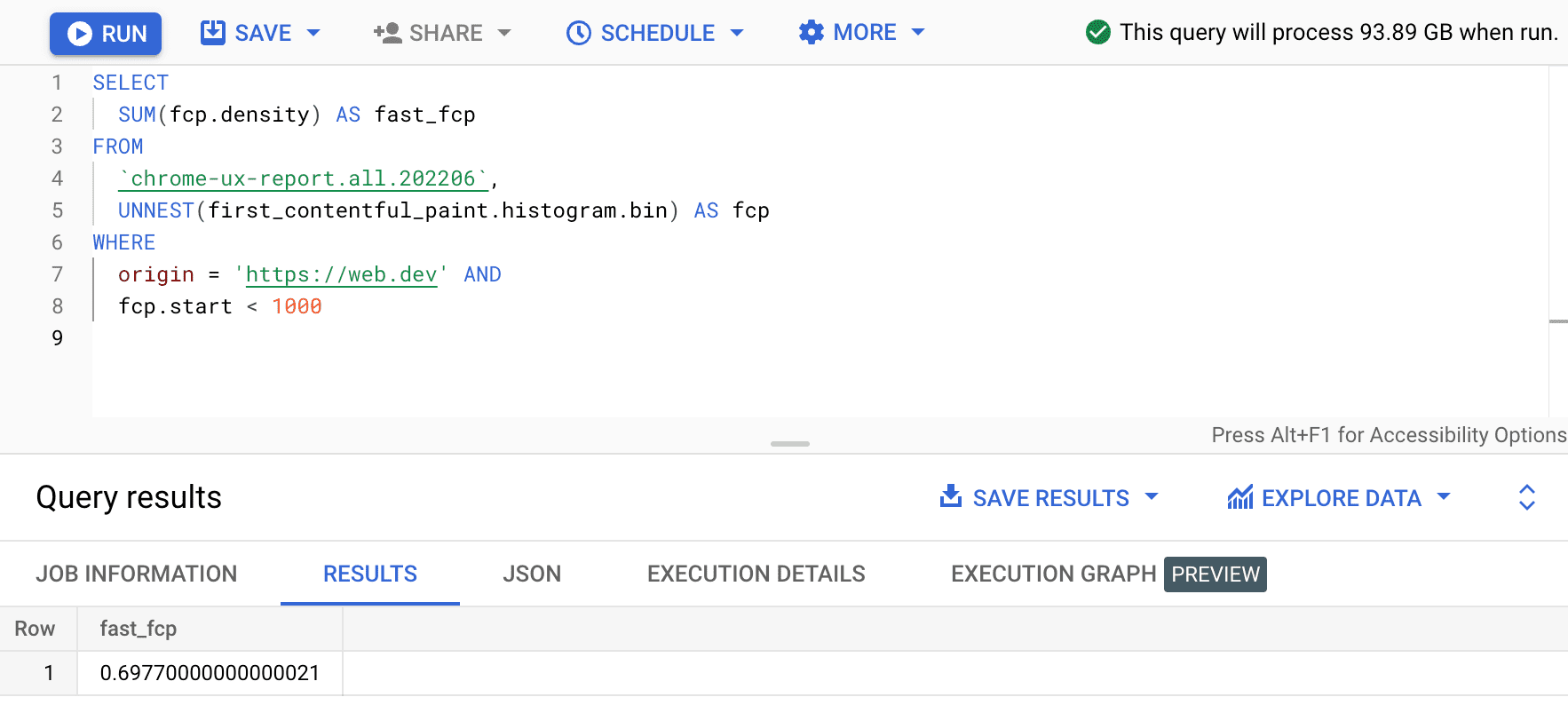
これにより、0.6977 が得られます。つまり、web.dev の FCP ユーザー エクスペリエンスの 69.77% は、FCP の範囲の定義に基づいて「高速」と見なされます。
パフォーマンスのトラッキング
オリジンに関するパフォーマンス データを抽出したので、古いテーブルにある過去のデータと比較できます。これを行うには、テーブルのアドレスを前の月に書き換えるか、ワイルドカード構文を使用してすべての月をクエリします。
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
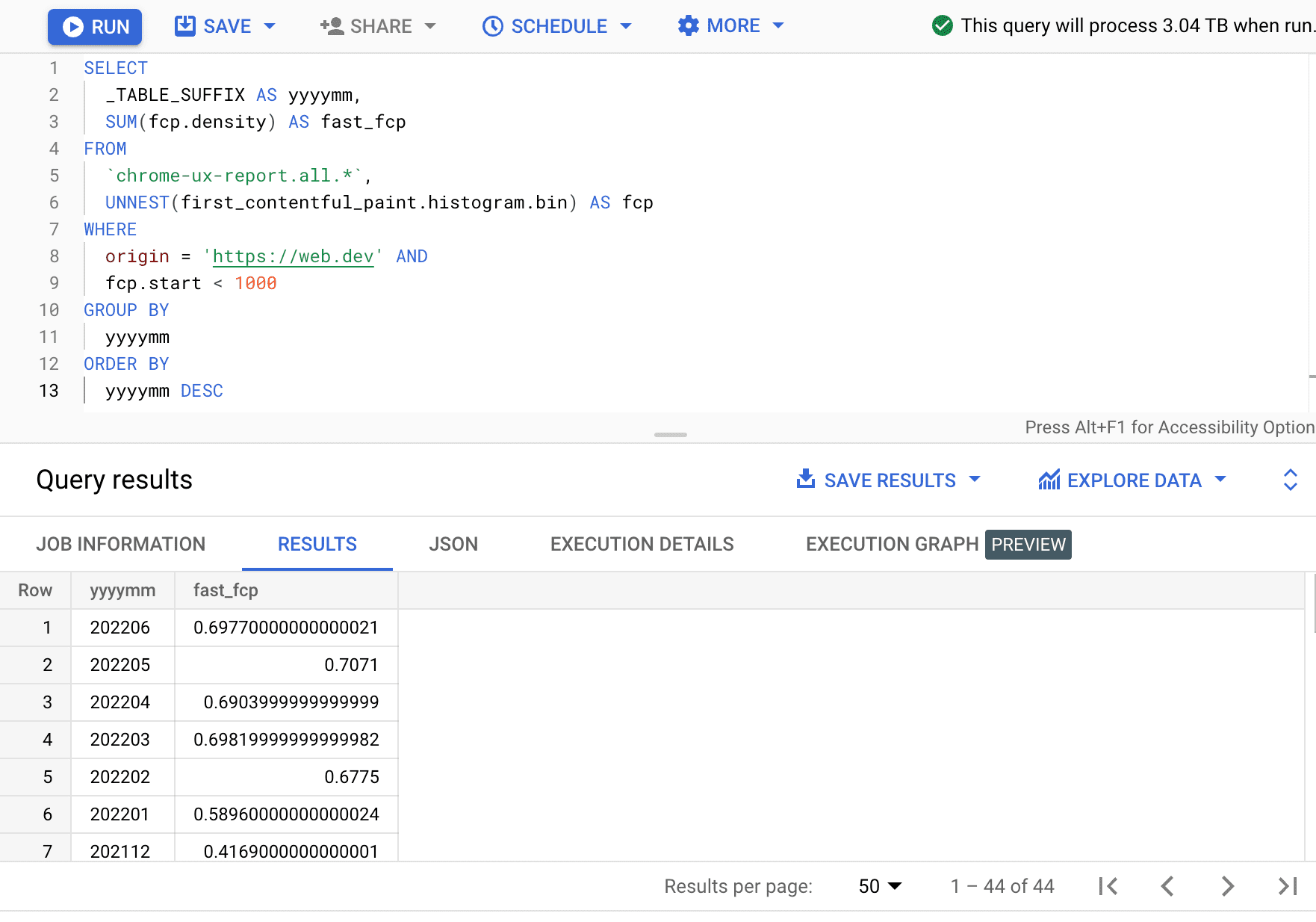
高速 FCP の割合は、月ごとに数パーセントポイントずつ変動しています。
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
これらの手法を使用すると、オリジンのパフォーマンスを調べ、高速エクスペリエンスの割合を計算し、その推移を追跡できます。次のステップとして、2 つ以上のオリジンをクエリして、パフォーマンスを比較してみてください。
よくある質問
CrUX BigQuery データセットに関するよくある質問を以下に示します。
他のツールではなく BigQuery を使用するのはどのような場合ですか?
BigQuery は、CrUX ダッシュボードや PageSpeed Insights などの他のツールから同じ情報を取得できない場合にのみ必要です。たとえば、BigQuery ではデータを意味のある方法でスライスしたり、HTTP Archive などの他の一般公開データセットと結合して高度なデータマイニングを行ったりできます。
BigQuery の使用に制限はありますか?
はい。最も重要な制限事項は、デフォルトではユーザーが 1 か月あたりクエリできるデータ量が 1 TB に制限されていることです。1 TB を超えると、1 TB あたり 5 米ドルの標準料金が適用されます。
BigQuery の詳細をどこで確認できますか?
詳細については、BigQuery のドキュメントをご覧ください。