

Data mentah Laporan UX Chrome (CrUX) tersedia di BigQuery, sebuah database di Google Cloud. Penggunaan BigQuery memerlukan project GCP dan pengetahuan dasar tentang SQL.
Dalam panduan ini, pelajari cara menggunakan BigQuery untuk menulis kueri terhadap set data CrUX untuk mengekstrak hasil yang bermakna tentang status pengalaman pengguna di web:
- Memahami bagaimana data diatur
- Menulis kueri dasar untuk mengevaluasi performa origin
- Menulis kueri lanjutan untuk melacak performa dari waktu ke waktu
Pengaturan data
Mulailah dengan melihat kueri dasar:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Untuk menjalankan kueri, masukkan ke editor kueri dan tekan tombol "Jalankan kueri":
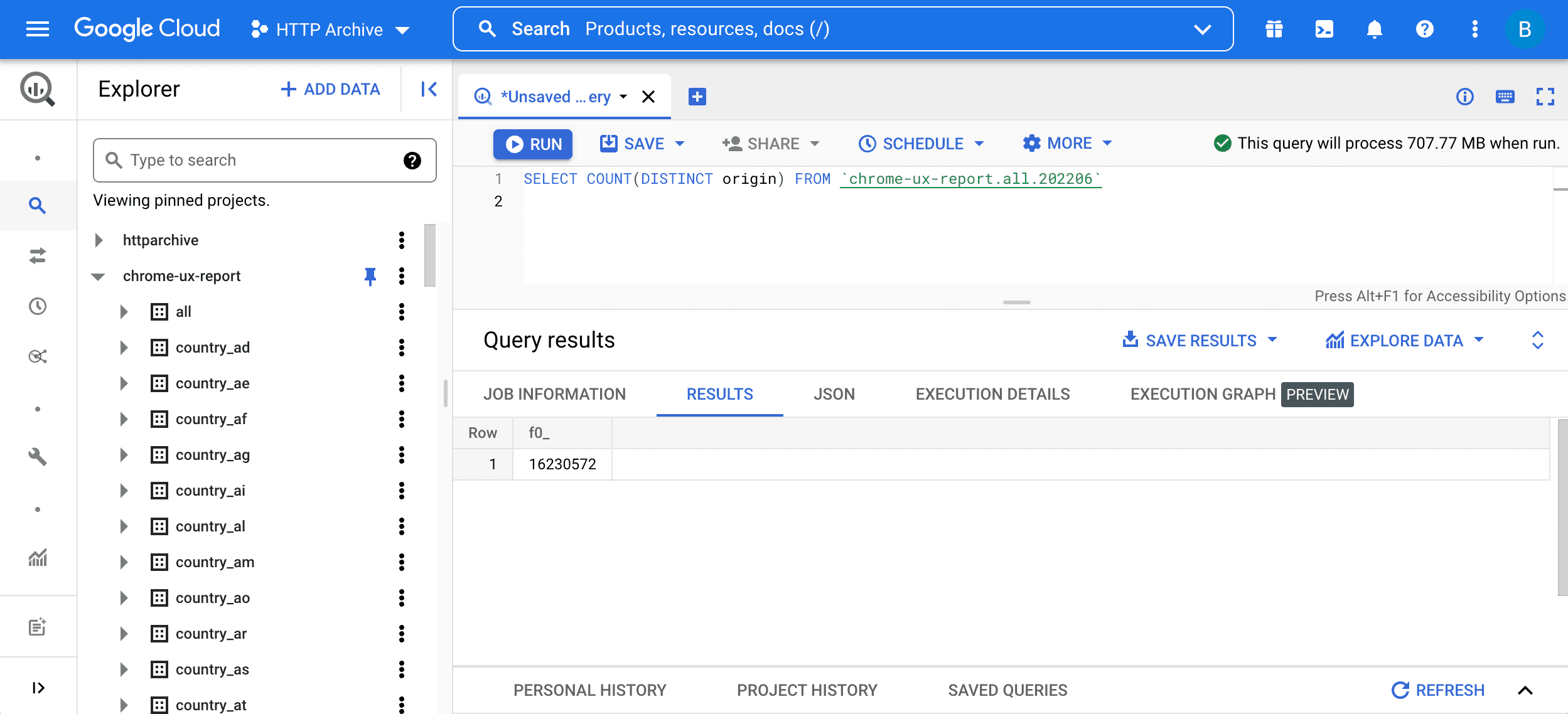
Ada dua bagian untuk kueri ini:
SELECT COUNT(DISTINCT origin)berarti melakukan kueri untuk jumlah origin dalam tabel. Secara kasar, dua URL merupakan bagian dari asal yang sama jika memiliki skema, host, dan port yang sama.FROM chrome-ux-report.all.202206menentukan alamat tabel sumber yang memiliki tiga bagian:- Nama project Cloud
chrome-ux-reporttempat semua data CrUX diatur - Set data
all, yang mewakili data di semua negara - Tabel
202206, tahun dan bulan data dalam format YYYYMM
- Nama project Cloud
Ada juga set data untuk setiap negara. Misalnya, chrome-ux-report.country_ca.202206 hanya mewakili data pengalaman pengguna yang berasal dari Kanada.
Dalam setiap {i>dataset<i} terdapat tabel untuk setiap bulan sejak tahun 2017. Tabel baru untuk bulan kalender sebelumnya diterbitkan secara teratur.
Struktur tabel data (juga dikenal sebagai skema) berisi:
- Origin, misalnya
origin = 'https://www.example.com', yang merepresentasikan distribusi pengalaman pengguna gabungan untuk semua halaman di situs tersebut - Kecepatan koneksi pada saat pemuatan halaman, misalnya,
effective_connection_type.name = '4G' - Jenis perangkat, misalnya
form_factor.name = 'desktop' - Metrik UX itu sendiri
- first_paint (FP)
- first_contentful_paint (FCP)
- {i>dom_content_loading<i} (DCL)
- beban (OL)
- eksperimental.first_input_ delay (FID)
Data untuk setiap metrik diatur sebagai array objek. Dalam notasi JSON, first_contentful_paint.histogram.bin akan terlihat seperti ini:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Setiap kelompok berisi waktu mulai dan waktu berakhir dalam milidetik dan kepadatan yang mewakili persentase pengalaman pengguna dalam rentang waktu tersebut. Dengan kata lain, 12,34% pengalaman FCP untuk asal hipotesis, kecepatan koneksi, dan jenis perangkat ini kurang dari 100 md. Jumlah dari semua kepadatan tempat sampah adalah 100%.
Jelajahi struktur tabel di BigQuery.
Mengevaluasi performa
Kita dapat menggunakan pengetahuan tentang skema tabel untuk menulis kueri yang mengekstrak data performa ini.
SELECT
fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
effective_connection_type.name = '4G' AND
form_factor.name = 'phone' AND
fcp.start = 0
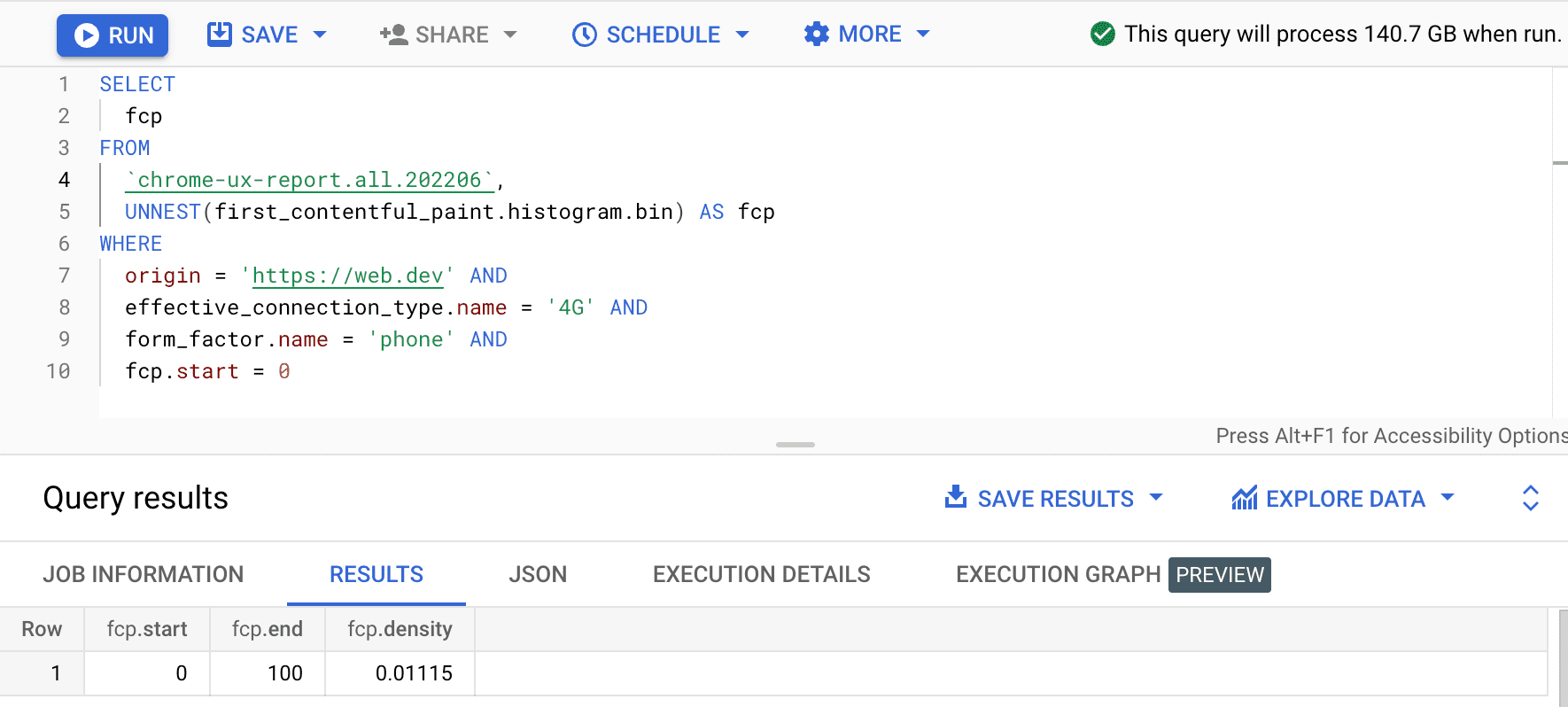
Hasilnya adalah 0.01115, yang berarti 1,115% pengalaman pengguna di jaringan asal ini memiliki waktu antara 0 hingga 100 md di jaringan 4G dan ponsel. Jika kita ingin menggeneralisasi kueri ke koneksi dan jenis perangkat apa pun, kita dapat menghilangkannya dari klausa WHERE dan menggunakan fungsi agregator SUM untuk menjumlahkan semua kepadatan bin masing-masing:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
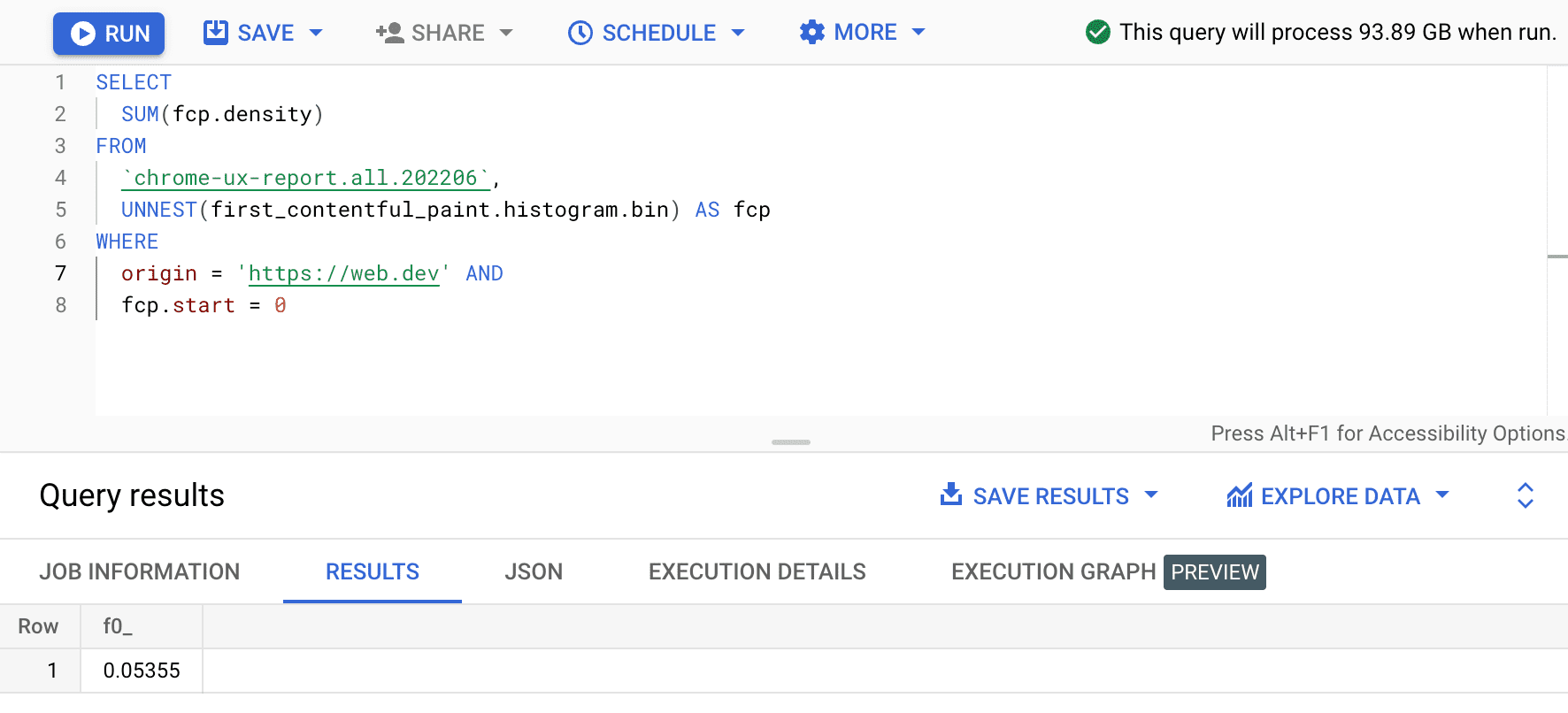
Hasilnya adalah 0.05355, atau 5,355% di semua perangkat dan jenis koneksi. Kita dapat sedikit memodifikasi kueri dan menambahkan kepadatan untuk semua bin yang berada dalam kisaran FCP "cepat" antara 0–1000 md:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
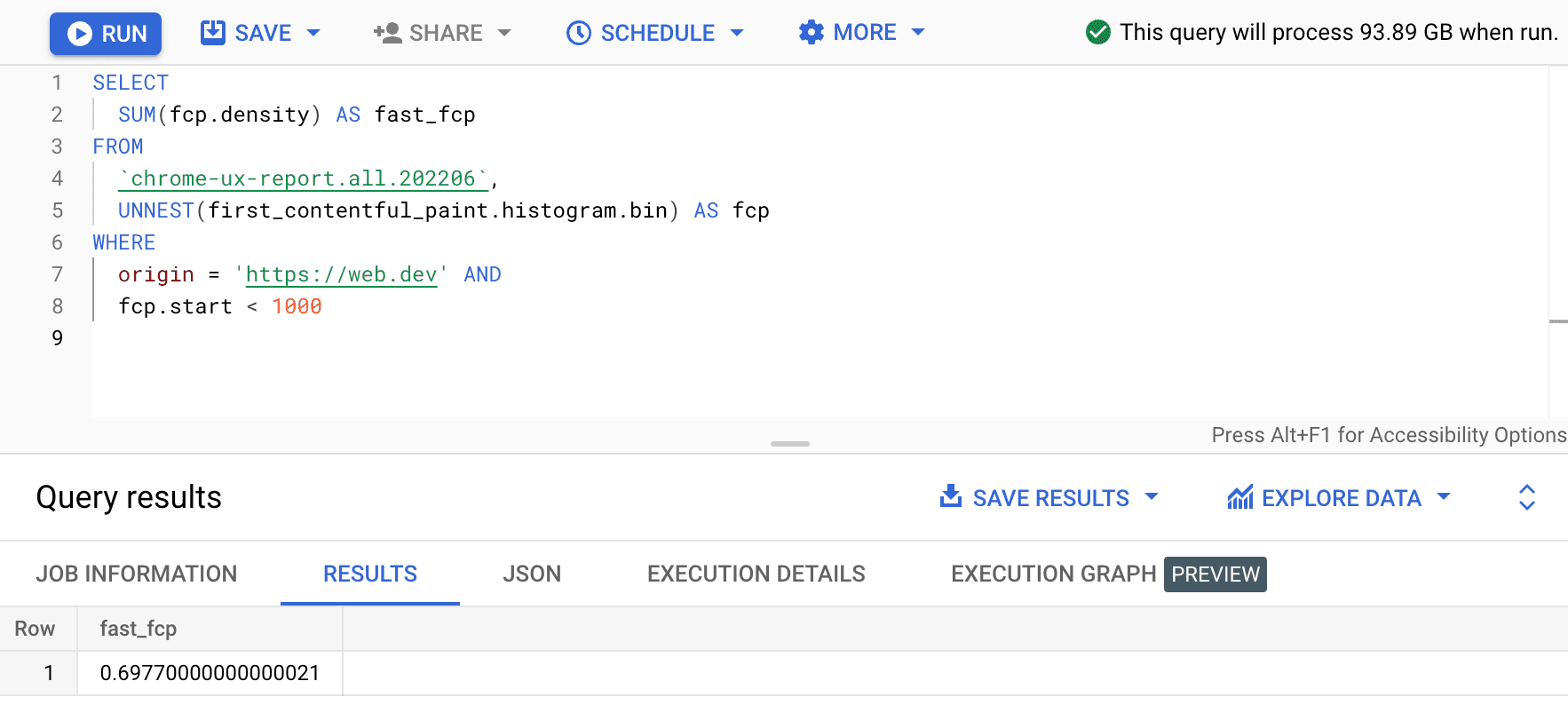
Ini memberi kita 0.6977. Dengan kata lain, 69,77% pengalaman pengguna FCP di web.dev dianggap "cepat" menurut definisi rentang FCP.
Lacak performa
Setelah mengekstrak data performa tentang origin, kita dapat membandingkannya dengan data historis yang tersedia di tabel lama. Untuk melakukannya, kita dapat menulis ulang alamat tabel ke bulan sebelumnya, atau menggunakan sintaksis karakter pengganti untuk kueri semua bulan:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
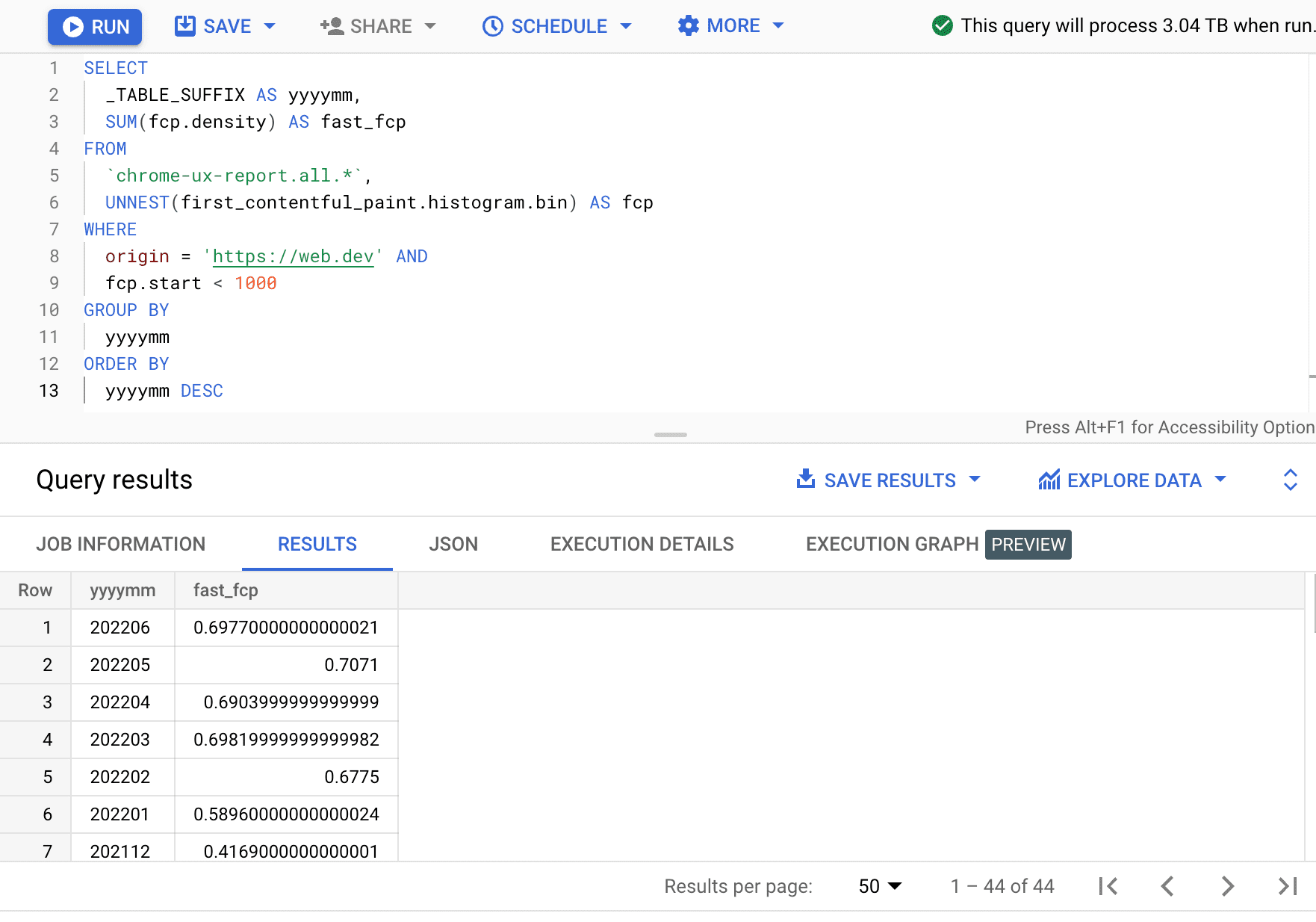
Di sini, kita melihat bahwa persentase pengalaman FCP cepat bervariasi beberapa persen setiap bulan.
| tttt | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| ... | ... |
Dengan teknik ini, Anda dapat mencari performa untuk sebuah origin, menghitung persentase pengalaman yang cepat, dan memantaunya dari waktu ke waktu. Sebagai langkah berikutnya, coba buat kueri untuk dua atau beberapa origin dan bandingkan performanya.
FAQ
Berikut adalah beberapa pertanyaan umum (FAQ) tentang {i>dataset<i} CrUX BigQuery:
Kapan saya harus menggunakan BigQuery dibandingkan alat lainnya?
BigQuery hanya diperlukan jika Anda tidak bisa mendapatkan informasi yang sama dari alat lain seperti Dasbor CrUX dan PageSpeed Insights. Misalnya, BigQuery memungkinkan Anda membagi data dengan cara yang bermakna dan bahkan menggabungkannya dengan set data publik lainnya seperti Arsip HTTP untuk melakukan beberapa penambangan data tingkat lanjut.
Apakah ada batasan untuk menggunakan BigQuery?
Ya, batasan paling penting adalah bahwa secara default pengguna hanya dapat membuat kueri data senilai 1 TB per bulan. Di luar itu, tarif standar $5/TB berlaku.
Di mana saya bisa mempelajari BigQuery lebih lanjut?
Lihat dokumentasi BigQuery untuk mengetahui informasi selengkapnya.