

פורסם: 2 בדצמבר 2022, עדכון אחרון: 23 בינואר 2026
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)

צוות Chrome החזיר את הטעינה המקדימה המלאה של דפים עתידיים שסביר להניח שמשתמש ינווט אליהם.
היסטוריה קצרה של טרום-עיבוד (prerender)
בעבר, Chrome תמך ברמז המשאב <link rel="prerender" href="/next-page">, אבל הוא לא נתמך באופן נרחב מחוץ ל-Chrome, והוא לא היה API מאוד מפורט.
הוצאנו משימוש את העיבוד מראש מדור קודם באמצעות רמז הקישור rel=prerender, ועברנו לשימוש בשליפה מראש ללא מצב. במקום זאת, המערכת שולפת מראש את המשאבים שדרושים לדף העתידי, אבל לא מעבדת מראש את הדף באופן מלא ולא מריצה JavaScript. השליפה מראש ללא מצב עוזרת לשפר את ביצועי הדף על ידי שיפור טעינת המשאבים, אבל היא לא תספק טעינת דף מיידית כמו עיבוד מראש מלא.
צוות Chrome החזיר עכשיו את העיבוד המקדים המלא ל-Chrome. כדי למנוע סיבוכים בשימוש הקיים ולאפשר הרחבה עתידית של טרום-רנדור, מנגנון הטרום-רנדור החדש הזה לא ישתמש בתחביר <link rel="prerender"...>, שעדיין קיים עבור NoState Prefetch, במטרה להוציא אותו משימוש בשלב מסוים בעתיד.
איך מתבצע עיבוד מראש של דף?
יש ארבע דרכים לבצע טרום-עיבוד של דף, וכולן נועדו לזרז את הניווטים:
- כשמקלידים כתובת URL בסרגל הכתובות של Chrome (שנקרא גם "התיבה הרב-תכליתית"), Chrome עשוי לבצע טעינה מראש של הדף באופן אוטומטי, אם הוא בטוח במידה רבה שתבקרו בדף הזה, על סמך היסטוריית הגלישה הקודמת שלכם.
- כשמשתמשים בסרגל הסימניות, יכול להיות ש-Chrome יבצע באופן אוטומטי טרום-עיבוד של הדף כשמעבירים את מצביע העכבר מעל אחד מכפתורי הסימניות.
- כשמקלידים מונח חיפוש בסרגל הכתובות של Chrome, יכול להיות ש-Chrome יבצע באופן אוטומטי טרום-עיבוד של דף תוצאות החיפוש, אם מנוע החיפוש יורה לו לעשות זאת.
- אתרים יכולים להשתמש ב-Speculation Rules API כדי להגדיר באופן אוטומטי ל-Chrome אילו דפים לעבד מראש. האפשרות הזו מחליפה את הפעולה שבוצעה בעבר על ידי
<link rel="prerender"...>ומאפשרת לאתרים לבצע עיבוד מראש של דף באופן יזום על סמך כללי ספקולציה בדף. התגים יכולים להיות סטטיים בדפים, או להיות מוזרקים באופן דינמי על ידי JavaScript לפי שיקול דעתו של בעל הדף.
בכל אחד מהמקרים האלה, העיבוד מראש מתבצע כאילו הדף נפתח בכרטיסיית רקע בלתי נראית, ואז הוא "מופעל" על ידי החלפת הכרטיסייה שבחזית בדף שעבר עיבוד מראש. אם דף מופעל לפני שהוא עבר רינדור מראש באופן מלא, המצב הנוכחי שלו הוא 'העברה לחזית' והוא ממשיך להיטען, כך שעדיין אפשר לקבל יתרון משמעותי.
הדף שעבר עיבוד מראש נפתח במצב מוסתר, ולכן מספר ממשקי API שגורמים להתנהגויות פולשניות (לדוגמה, הנחיות) לא מופעלים במצב הזה, אלא מופעלים רק כשהדף מופעל. במקרים נדירים שבהם עדיין אי אפשר לעשות זאת, העיבוד מראש מבוטל. צוות Chrome עובד על חשיפת הסיבות לביטול טרום-רנדור כ-API, וגם על שיפור היכולות של DevTools כדי להקל על זיהוי של מקרים חריגים כאלה.
ההשפעה של עיבוד מראש
טרום-עיבוד מאפשר טעינת דף כמעט מיידית, כמו שרואים בסרטון הבא:
אתר הדוגמה הוא כבר אתר מהיר, אבל גם במקרה כזה אפשר לראות איך טרום-עיבוד משפר את חוויית המשתמש. לכן, יכולה להיות לכך גם השפעה ישירה על Core Web Vitals של אתר, עם LCP קרוב לאפס, CLS מופחת (כי כל CLS של טעינה מתרחש לפני התצוגה הראשונית) ו-INP משופר (כי הטעינה אמורה להסתיים לפני שהמשתמש מקיים אינטראקציה).
גם אם דף מופעל לפני שהוא נטען במלואו, התחלה מוקדמת של טעינת הדף אמורה לשפר את חוויית הטעינה. כשמפעילים קישור בזמן שהעיבוד מראש עדיין מתבצע, הדף שעבר עיבוד מראש יעבור למסגרת הראשית וימשיך להיטען.
עם זאת, טרום-הרינדור משתמש בזיכרון נוסף וברוחב פס נוסף ברשת. חשוב להיזהר שלא לבצע יותר מדי טרום-עיבוד, כי זה עלול לבזבז משאבים של המשתמשים. עיבוד מראש מתבצע רק כשיש סבירות גבוהה לניווט לדף.
בקטע מדידת הביצועים מוסבר איך למדוד את ההשפעה בפועל על הביצועים בניתוח הנתונים.
הצגת החיזויים בסרגל הכתובות של Chrome
במקרה השימוש הראשון, אפשר לראות את החיזויים של Chrome לגבי כתובות URL בדף chrome://predictors:
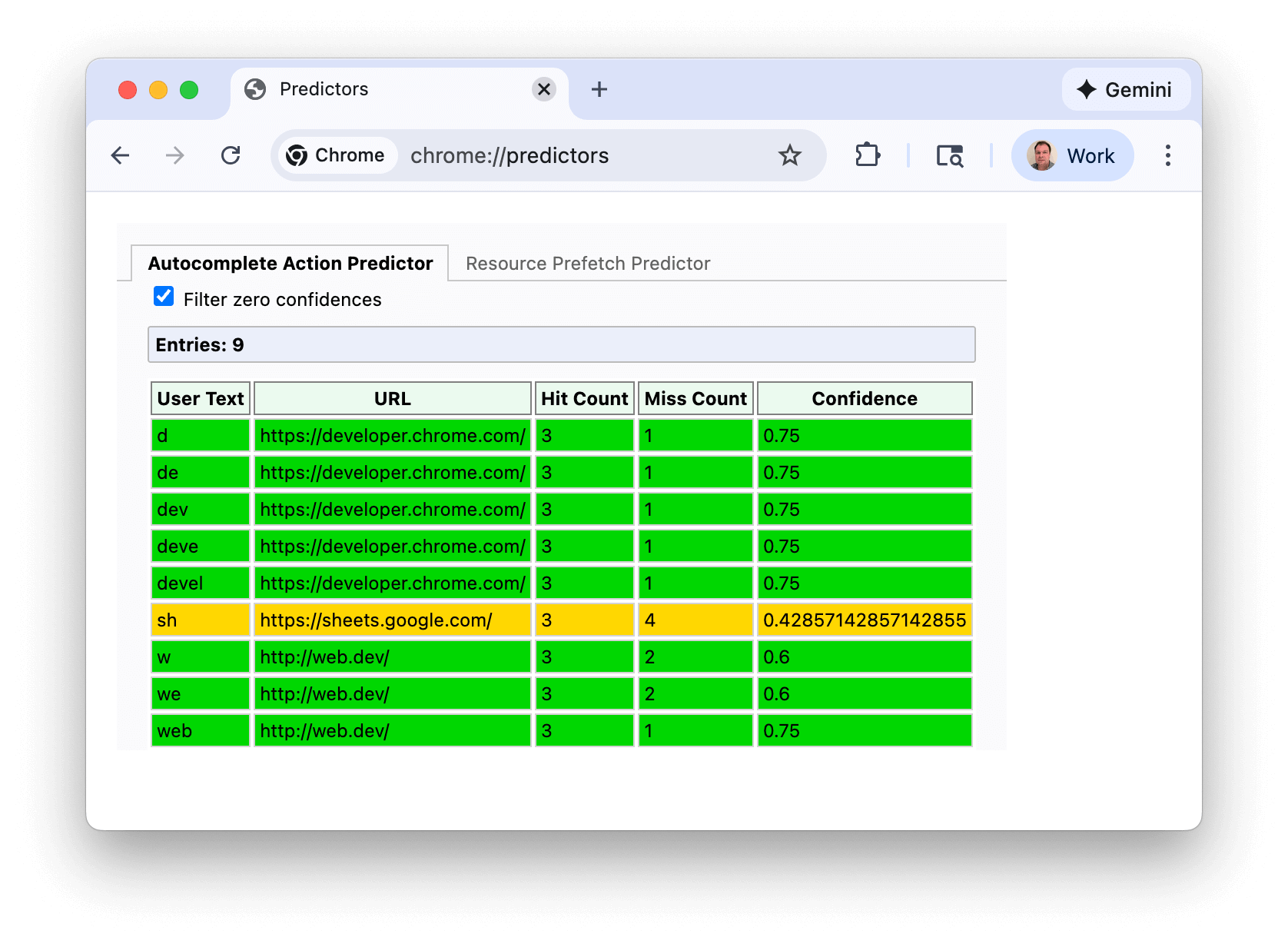
קווים ירוקים מציינים רמת מהימנות מספיק גבוהה להפעלת טרום-עיבוד. בדוגמה הזו, הקלדת האות s נותנת רמת סבירות סבירה (צהוב), אבל אחרי שמקלידים sh, ל-Chrome יש מספיק נתונים כדי להניח שכמעט תמיד עוברים אל https://sheets.google.com.
צילום המסך הזה נעשה בהתקנה חדשה יחסית של Chrome, והסינון בו הוא של תחזיות עם רמת מהימנות אפס. אבל אם תצפו בתחזיות שלכם, סביר להניח שתראו הרבה יותר רשומות, ואולי תצטרכו להקליד יותר תווים כדי להגיע לרמת מהימנות גבוהה מספיק.
התחזיות האלה גם מניעות את ההצעות בסרגל הכתובות שאולי שמתם לב אליהן:
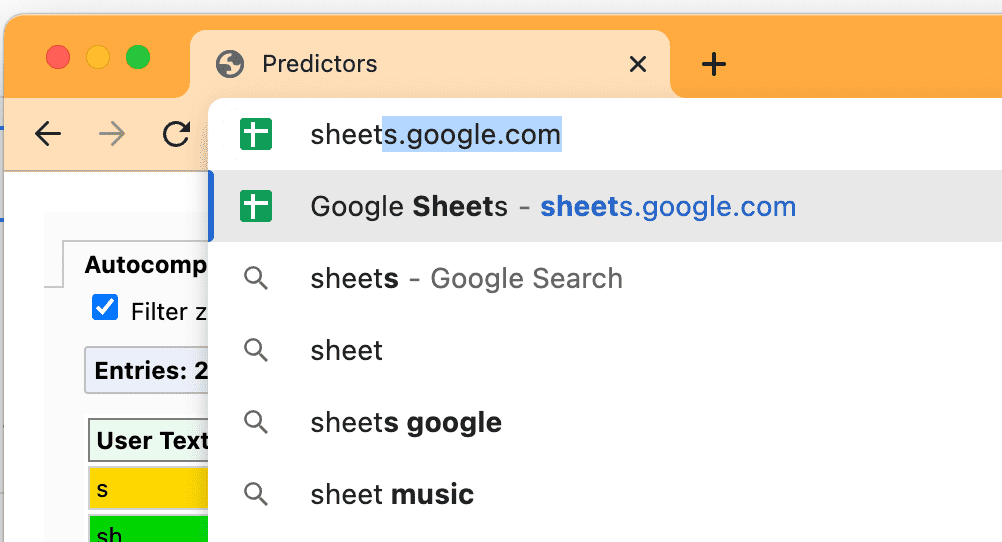
Chrome יעדכן באופן רציף את התחזיות שלו על סמך ההקלדה והבחירות שלכם.
- אם רמת הוודאות גבוהה מ-30% (מוצגת בצבע ענבר), Chrome מתחבר מראש לדומיין באופן יזום, אבל לא מבצע טרום-עיבוד של הדף.
- אם רמת המהימנות גבוהה מ-50% (מוצגת בירוק), Chrome יבצע טרום-עיבוד של כתובת ה-URL.
Speculation Rules API
באפשרות prerender של Speculation Rules API, מפתחי אתרים יכולים להוסיף הוראות JSON לדפים שלהם כדי ליידע את הדפדפן לגבי כתובות ה-URL שצריך לבצע להן prerender.
רשימת כתובות URL
כללי ספקולציות יכולים להתבסס על רשימות של כתובות URL:
<script type="speculationrules">
{
"prerender": [{
"urls": ["next.html", "next2.html"]
}]
}
</script>
כללים לגבי מסמכים
כללי ספקולציות יכולים להיות גם 'כללים של מסמך' באמצעות התחביר where. הדוח הזה מציג קישורים משוערים שנמצאו במסמך על סמך סלקטורים של href (מבוססים על URL Pattern API) או סלקטורים של CSS:
<script type="speculationrules">
{
"prerender": [{
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/wp-admin"}},
{ "not": {"href_matches": "/*\\?*(^|&)add-to-cart=*"}},
{ "not": {"selector_matches": ".do-not-prerender"}},
{ "not": {"selector_matches": "[rel~=nofollow]"}}
]
}
}]
}
</script>
להוטות
ההגדרה eagerness משמשת לציון המועד שבו ההשערות צריכות לפעול, וזה שימושי במיוחד לכללי מסמכים:
-
conservative: מדובר בניחוש לגבי מיקום הסמן או נקודת המגע. -
moderate: במחשב, מתבצעות ספקולציות אם מחזיקים את מצביע העכבר מעל קישור למשך 200 מילי-שניות (או באירועpointerdownאם הוא מתרחש מוקדם יותר, ובנייד שבו אין אירועhover). בנייד, החל מאוגוסט 2025, אנחנו משתמשים בהיוריסטיקה מורכבת של אזור התצוגה כדי לקבוע את הגודל של אזור התצוגה. היוריסטיקות מורכבות של אזור התצוגה מופעלות 500 אלפיות השנייה אחרי שהמשתמש הפסיק לגלול, עבור עוגנים שנמצאים בטווח של 30% מהמרחק האנכי מהמיקום הקודם של מצביע העכבר, כאשר העוגנים גדולים לפחות פי 0.5 מהעוגן הגדול ביותר באזור התצוגה. כפי שמתואר במסמך הזה. -
eager: בעבר, ההתנהגות של התכונה הזו הייתה זהה לזו שלimmediate, אבל היא השתנתה החל מ-Chrome 143. במחשב, אם מחזיקים את מצביע העכבר מעל קישור למשך 10 אלפיות השנייה, מתבצעות ספקולציות. בנייד, החל מינואר 2026, נתבסס על אוריסטיקה פשוטה של אזור התצוגה. היוריסטיקות פשוטות של אזור התצוגה מופעלות 50 אלפיות השנייה אחרי שהעוגן נכנס לאזור התצוגה. -
immediate: הערך הזה משמש לביצוע ספקולציה מוקדם ככל האפשר, כלומר ברגע שכללי הספקולציה נצפים.
ערך ברירת המחדל של eagerness לכללי list הוא immediate. אפשר להשתמש באפשרויות eager, moderate ו-conservative כדי להגביל את כללי list לכתובות URL שמשתמש מקיים איתן אינטראקציה ברשימה ספציפית. עם זאת, במקרים רבים, עדיף להשתמש בכללי document עם תנאי where מתאים.
ערך ברירת המחדל של eagerness לכללי document הוא conservative. מסמך יכול לכלול הרבה כתובות URL, ולכן צריך להשתמש ב-immediate לכללי document בזהירות (אפשר לעיין גם בקטע מגבלות ב-Chrome בהמשך).
ההגדרה eagerness שבה כדאי להשתמש תלויה באתר שלכם. באתר סטטי קל משקל, יכול להיות שאין עלות גבוהה לניחוש מוקדם יותר, והוא יכול להועיל למשתמשים. באתרים עם ארכיטקטורות מורכבות יותר ומטענים כבדים יותר של דפים, כדאי להפחית את הבזבוז על ידי צמצום התדירות של הניחושים עד שתקבלו אותות חיוביים יותר לגבי כוונת המשתמשים.
האפשרות moderate היא פשרה, ואתרים רבים יכולים להפיק תועלת מכלל הניחוש הבא, שיבצע טרום-עיבוד לקישור כשמחזיקים את מצביע העכבר מעל הקישור למשך 200 מילישניות או באירוע pointerdown כהטמעה בסיסית – אך עוצמתית – של כללי ניחוש:
<script type="speculationrules">
{
"prerender": [{
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
שליפה מראש (prefetch)
אפשר להשתמש בכללי ספקולציה גם רק לשליפה מראש של דפים, בלי לבצע עיבוד מראש מלא. לרוב, זה יכול להיות צעד ראשון טוב בדרך לעיבוד מראש:
<script type="speculationrules">
{
"prefetch": [{
"urls": ["next.html", "next2.html"]
}]
}
</script>
Prerender until script
צוות Chrome עובד גם על הוספת prerender_until_script ל-Speculation Rules API (ראו: באג בהטמעה). זה יהיה שלב בין שליפה מראש לבין עיבוד מראש, והשימוש בו יהיה דומה:
<script type="speculationrules">
{
"prerender_until_script": [{
"urls": ["next.html", "next2.html"]
}]
}
</script>
בדומה ל-NoState prefetch, הפקודה הזו תבצע אחזור מראש של מסמך ה-HTML וגם של משאבי המשנה שזמינים ב-HTML. עם זאת, הוא ימשיך מעבר לכך ויתחיל גם לבצע טרום-עיבוד של הדף, ויפסיק כשהוא ייתקל בסקריפט הראשון.
כלומר, בדפים ללא JavaScript, או עם JavaScript רק בכותרת התחתונה, אפשר לבצע מראש כמעט את כל הרינדור של הדף. דפים עם סקריפטים ב-<head> לא יוכלו לעבור טרום-עיבוד, אבל עדיין ייהנו מאחזור משאבי המשנה.
כך אפשר להימנע מהסיכונים של תופעות לוואי לא רצויות כתוצאה מהרצת JavaScript, אבל עדיין ליהנות משיפור ביצועים משמעותי יותר מאשר רק prefetch.
מגבלות ב-Chrome
ב-Chrome יש מגבלות כדי למנוע שימוש יתר ב-Speculation Rules API:
| להוטות | שליפה מראש (prefetch) | עיבוד מראש |
|---|---|---|
immediate |
50 | 10 |
eager / moderate / conservative |
2 (FIFO) | 2 (FIFO) |
ההגדרות eager, moderate ו-conservative – שתלויות באינטראקציה של המשתמש – פועלות בשיטת נכנס ראשון, יוצא ראשון (FIFO): אחרי שמגיעים למגבלה, ספקולציה חדשה תגרום לביטול הספקולציה הכי ישנה ולהחלפתה בספקולציה החדשה יותר כדי לחסוך בזיכרון. אפשר להפעיל מחדש ספקולציה שבוטלה – למשל, על ידי העברת העכבר מעל הקישור הזה שוב – וכתוצאה מכך תתבצע ספקולציה מחדש על כתובת ה-URL הזו, והספקולציה הכי ישנה תבוטל. במקרה כזה, ההשערה הקודמת תאחסן במטמון את כל המשאבים שניתנים לאחסון במטמון במטמון ה-HTTP של כתובת ה-URL הזו, ולכן ההשערה הבאה תהיה זולה יותר. לכן הגדרנו את המגבלה על סף צנוע של 2. כללים של רשימה סטטית לא מופעלים על ידי פעולת משתמש, ולכן יש להם מגבלה גבוהה יותר, כי הדפדפן לא יכול לדעת אילו כללים נדרשים ומתי הם נדרשים.
בנוסף, ב-Chrome שוקלים להגדיל את המגבלה ל-5 בנייד עבור eager ו-moderate לפחות עבור שליפה מראש (prefetch), כי זהו היוריסטיקה פחות מדויקת. מפתחים שמשתמשים ב-eager יכולים לשקול להשתמש גם בכללי conservative, כדי שהניחוש יתבצע גם אם הקישור לא נבחר כאחד משני הקישורים הראשונים, במקרים שבהם יש כמה קישורים באזור התצוגה.
גם המגבלה של immediate היא דינמית, כך שהסרה של רכיב סקריפט של כתובת URL של immediate תיצור קיבולת על ידי ביטול הניחושים שהוסרו.list
Chrome גם ימנע שימוש בספקולציות בתנאים מסוימים, כולל:
- Save-Data.
- חיסכון באנרגיה כשהוא מופעל ורמת הטעינה של הסוללה נמוכה.
- מגבלות זיכרון.
- כשההגדרה 'טעינה מראש של דפים' מושבתת (היא מושבתת גם באופן מפורש על ידי תוספי Chrome כמו uBlock Origin).
- דפים שנפתחו בכרטיסיות ברקע.
בנוסף, Chrome לא מעבד iframe ממקורות שונים בדפים שעברו עיבוד מראש עד להפעלה.
כל התנאים האלה נועדו לצמצם את ההשפעה של ספקולציות מוגזמות במקרים שבהם הן עלולות לפגוע במשתמשים.
איך כוללים כללי ספקולציות בדף
אפשר לכלול כללי ניחוש באופן סטטי ב-HTML של הדף או להוסיף אותם באופן דינמי לדף באמצעות JavaScript:
- כללי ניחוש שכלולים באופן סטטי: לדוגמה, אתר חדשות או בלוג יכולים לבצע טרום-עיבוד של המאמר החדש ביותר, אם זה לרוב הניווט הבא עבור חלק גדול מהמשתמשים. לחלופין, אפשר להשתמש בכללי מסמך עם
moderateאוconservativeכדי לנחש את הפעולות הבאות של המשתמשים בזמן שהם מבצעים אינטראקציה עם קישורים. - כללי ניחוש שמוכנסים באופן דינמי: יכול להיות שהם מבוססים על לוגיקה של אפליקציה, מותאמים אישית למשתמש או מבוססים על היוריסטיקה אחרת.
אם אתם מעדיפים הוספה דינמית על סמך פעולות כמו ריחוף מעל קישור או לחיצה על קישור – כמו שספריות רבות עשו בעבר עם <link rel=prefetch> – מומלץ לעיין בכללי המסמך, כי הם מאפשרים לדפדפן לטפל ברבים מתרחישי השימוש שלכם.
אפשר להוסיף כללי ספקולציה ב-<head> או ב-<body> של המסגרת הראשית. לא מתבצעת פעולה לפי כללי טעינה מראש ב-iframe, וכללי טעינה מראש בדפים שעברו טרום-עיבוד מופעלים רק אחרי שהדף מופעל.
כותרת ה-HTTP Speculation-Rules
אפשר גם להעביר כללים לניחוש באמצעות כותרת HTTP של Speculation-Rules, במקום לכלול אותם ישירות ב-HTML של המסמך. כך קל יותר לפרוס את המסמכים באמצעות רשתות CDN בלי לשנות את התוכן שלהם.
כותרת ה-HTTP Speculation-Rules מוחזרת עם המסמך, ומצביעה על מיקום של קובץ JSON שמכיל את כללי הניחוש:
Speculation-Rules: "/speculationrules.json"
למשאב הזה צריך להיות סוג ה-MIME הנכון, ואם הוא משאב חוצה מקורות, הוא צריך לעבור בדיקת CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
אם רוצים להשתמש בכתובות URL יחסיות, כדאי לכלול את המפתח "relative_to": "document" בכללי הניחוש. אחרת, כתובות URL יחסיות יהיו יחסיות לכתובת ה-URL של קובץ ה-JSON של כללי הניחוש. האפשרות הזו שימושית במיוחד אם אתם צריכים לבחור חלק מהקישורים או את כולם מאותו מקור.
שדה התג של כללי ספקולציות
אפשר גם להוסיף 'תגים' בתחביר JSON של כללי הניחוש ברמה הכוללת לכל כללי הניחוש בקבוצת כללים:
{
"tag": "my-rules",
"prefetch": [{
"urls": ["next.html"]
}],
"prerender": [{
"urls": ["next2.html"]
}]
}
או ברמת הכלל הספציפי:
{
"prefetch": [{
"tag": "my-prefetch-rules",
"urls": ["next.html"]
}],
"prerender": [{
"tag": "my-prerender-rules",
"urls": ["next2.html"]
}]
}
התג הזה משתקף בכותרת ה-HTTP Sec-Speculation-Tags, שאפשר להשתמש בה כדי לסנן כללי ניחוש בשרת. אם הספקולציה מכוסה על ידי כמה כללים, כפי שמוצג בדוגמה הבאה, כותרת ה-HTTP Sec-Speculation-Tags יכולה לכלול כמה תגים:
Sec-Speculation-Tags: null
Sec-Speculation-Tags: null, "cdn-prefetch"
Sec-Speculation-Tags: "my-prefetch-rules"
Sec-Speculation-Tags: "my-prefetch-rules", "my-rules", "cdn-prefetch"
חלק מרשתות ה-CDN מוסיפות כללי ניחוש באופן אוטומטי, אבל חוסמות ניחושים בדפים שלא נשמרו במטמון של שרת הקצה, כדי שהתכונה הזו לא תגרום לשימוש מוגבר בשרת המקור. התגים מאפשרים להם לזהות ספקולציות שהופעלו על ידי קבוצת הכללים שמוגדרת כברירת מחדל, אבל עדיין מאפשרים לכל כלל שנוסף על ידי האתר לעבור למקור.
תגי קבוצת הכללים מוצגים גם בכלי הפיתוח ל-Chrome.
שדה target_hint כללי ספקולציות
כללי הניחוש יכולים לכלול גם שדה target_hint, שמכיל שם או מילת מפתח תקפים של הקשר גלישה שמציינים איפה בדף צפוי התוכן שעבר טרום-עיבוד להיות מופעל:
<script type=speculationrules>
{
"prerender": [{
"target_hint": "_blank",
"urls": ["next.html"]
}]
}
</script>
ההצעה הזו מאפשרת לטפל בספקולציות של טרום-עיבוד עבור קישורי target="_blank":
<a target="_blank" href="next.html">Open this link in a new tab</a>
בשלב הזה, רק "target_hint": "_blank" ו-"target_hint": "_self" (ברירת המחדל אם לא מצוין אחרת) נתמכים ב-Chrome, ורק עבור prerender – לא נתמך prefetch.
התג target_hint נדרש רק לכללי ספקולציה של urls, כי לכללי מסמכים הערך של target ידוע מהקישור עצמו.
כללי ספקולציות ו-SPA
כללי הניחוש נתמכים רק בניווטים בדפים מלאים שמנוהלים על ידי הדפדפן, ולא באפליקציות של דף יחיד (SPA) או בדפים של מעטפת אפליקציה. בארכיטקטורות האלה לא מתבצעות אחזור של מסמכים, אלא אחזור של נתונים או דפים באמצעות API או אחזור חלקי שלהם. הנתונים או הדפים האלה מעובדים ומוצגים בדף הנוכחי. האפליקציה יכולה לבצע אחזור מראש של הנתונים שנדרשים למה שנקרא "מעברים רכים" מחוץ לכללי הניחוש, אבל היא לא יכולה לבצע עיבוד מראש שלהם.
אפשר להשתמש בכללי ספקולציה כדי לבצע עיבוד מראש של האפליקציה עצמה מדף קודם. כך אפשר לקזז חלק מהעלויות הנוספות של הטעינה הראשונית בחלק מאתרי ה-SPA. עם זאת, אי אפשר לבצע רינדור מראש של שינויים במסלול בתוך האפליקציה.
ניפוי באגים של כללי ספקולציות
כדי לראות תכונות חדשות בכלי פיתוח ל-Chrome שיעזרו לכם להציג ולנפות באגים ב-API החדש הזה, כדאי לעיין בפוסט הייעודי בנושא ניפוי באגים בכללי ספקולציה.
כמה כללי ספקולציות
אפשר גם להוסיף כמה כללי ניחוש לאותו דף, והם יצורפו לכללים הקיימים. לכן, כל הדרכים השונות הבאות יובילו לעיבוד מראש של one.html ושל two.html:
רשימת כתובות URL:
<script type="speculationrules">
{
"prerender": [{
"urls": ["one.html", "two.html"]
}]
}
</script>
כמה סקריפטים של speculationrules:
<script type="speculationrules">
{
"prerender": [{
"urls": ["one.html"]
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"urls": ["two.html"]
}]
}
</script>
כמה רשימות בתוך קבוצה אחת של speculationrules
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html"]
},
{
"urls": ["two.html"]
}
]
}
</script>
התמיכה של No-Vary-Search
כשמבצעים אחזור מראש או עיבוד מראש של דף, יכול להיות שפרמטרים מסוימים של כתובת URL (שנקראים טכנית פרמטרים של חיפוש) לא חשובים לדף שמועבר בפועל על ידי השרת, ומשמשים רק ל-JavaScript בצד הלקוח.
לדוגמה, מערכת Google Analytics משתמשת בפרמטרים של UTM למדידת קמפיינים, אבל בדרך כלל לא מציגה דפים שונים מהשרת. המשמעות היא שגם page1.html?utm_content=123 וגם page1.html?utm_content=456 יציגו את אותו דף מהשרת, כך שאפשר לעשות שימוש חוזר באותו דף מהמטמון.
באופן דומה, אפליקציות עשויות להשתמש בפרמטרים אחרים של כתובות URL שמטופלים רק בצד הלקוח.
ההצעה No-Vary-Search מאפשרת לשרת לציין פרמטרים שלא גורמים להבדל במשאב שמועבר, ולכן מאפשרת לדפדפן לעשות שימוש חוזר בגרסאות של מסמך שנשמרו במטמון, ששונות רק בפרמטרים האלה. התכונה הזו נתמכת ב-Chrome (ובדפדפנים שמבוססים על Chromium) לניחושים של ניווט גם לגבי אחזור מראש וגם לגבי טרום-עיבוד.
כללי ניחוש תומכים בשימוש ב-expects_no_vary_search כדי לציין איפה צפויה לחזור כותרת HTTP No-Vary-Search. כך תוכלו למנוע הורדות מיותרות לפני שהתשובות מוצגות.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
בדוגמה הזו, קוד ה-HTML הראשוני של הדף /products זהה לשני מזהי המוצרים 123 ו-124. עם זאת, התוכן של הדף משתנה בסופו של דבר על סמך עיבוד בצד הלקוח באמצעות JavaScript כדי לאחזר נתוני מוצרים באמצעות פרמטר החיפוש id. לכן אנחנו מבצעים אחזור מראש של כתובת ה-URL הזו, והיא אמורה להחזיר כותרת HTTP No-Vary-Search שמראה שאפשר להשתמש בדף לכל פרמטר חיפוש id.
עם זאת, אם המשתמש ילחץ על אחד מהקישורים לפני שהטעינה מראש תושלם, יכול להיות שהדפדפן לא יקבל את הדף /products. במקרה כזה, הדפדפן לא יודע אם הוא יכיל את כותרת ה-HTTP No-Vary-Search. בשלב הזה, הדפדפן צריך להחליט אם לאחזר את הקישור שוב או להמתין לסיום השליפה מראש כדי לבדוק אם הוא מכיל כותרת HTTP No-Vary-Search. ההגדרה expects_no_vary_search מאפשרת לדפדפן לדעת שתגובת הדף צפויה להכיל כותרת HTTP No-Vary-Search, ולהמתין עד לסיום האחזור המקדים.
אפשר גם להוסיף כמה פרמטרים ל-expects_no_vary_search ולהפריד ביניהם ברווח (כי No-Vary-Search היא כותרת HTTP מובנית):
"expects_no_vary_search": "params=(\"param1\" \"param2\" \"param3\")"
הגבלות על כללי ספקולציות ושיפורים עתידיים
כללי הספקולציה מוגבלים לדפים שנפתחים באותה כרטיסייה, אבל אנחנו פועלים כדי לצמצם את ההגבלה הזו.
כברירת מחדל, טרום-עיבוד מוגבל לדפים מאותו מקור. אפשר להפעיל עיבוד מראש של דפים ממקורות שונים באותו אתר (לדוגמה, https://a.example.com יכול לבצע עיבוד מראש של דף ב-https://b.example.com). כדי להשתמש בדף המשוער (https://b.example.com בדוגמה הזו), צריך להוסיף כותרת HTTP Supports-Loading-Mode: credentialed-prerender. אם לא עושים את זה, Chrome מבטל את הניחוש.
יכול להיות שגרסאות עתידיות גם יאפשרו עיבוד מראש לדפים ממקורות שונים שלא נמצאים באותו אתר, כל עוד לא קיימים קובצי Cookie בדף שעבר עיבוד מראש והדף שעבר עיבוד מראש מביע הסכמה באמצעות כותרת HTTP דומה Supports-Loading-Mode: uncredentialed-prerender.
כללי טעינה מראש כבר תומכים בשליפות מראש ממקורות שונים. אין הגבלות על שליפות מראש ממקורות שונים באותו אתר. אפשר לבצע אחזור מראש ממקורות שונים באתרים שונים רק אם לא קיימים קובצי Cookie לדומיין ממקורות שונים. אם קיימים קובצי Cookie מהביקור הקודם של המשתמש באתר, לא יתבצע ניחוש והשגיאה תוצג בכלי הפיתוח.
בהתחשב במגבלות הנוכחיות, דפוס אחד שיכול לשפר את חוויית המשתמשים שלכם גם בקישורים פנימיים וגם בקישורים חיצוניים, איפה שאפשר, הוא לבצע עיבוד מראש של כתובות URL מאותו מקור ולנסות לאחזר מראש כתובות URL ממקורות שונים:
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}],
"prefetch": [{
"where": { "not": { "href_matches": "/*" } },
"eagerness": "moderate"
}]
}
</script>
ההגבלה למניעת ספקולציות בין מקורות שונים לגבי קישורים בין מקורות שונים נדרשת לצורך אבטחה. היא מהווה שיפור לעומת <link rel="prefetch"> ליעדים חוצי-מקורות, שגם לא ישלחו קובצי Cookie אבל עדיין ינסו לבצע אחזור מראש – מה שיוביל לאחזור מראש מיותר שצריך לשלוח מחדש, או גרוע מכך, לטעינה של הדף הלא נכון.
זיהוי תמיכה ב-Speculation Rules API
אפשר לזהות תמיכה ב-Speculation Rules API באמצעות בדיקות HTML רגילות:
if (HTMLScriptElement.supports && HTMLScriptElement.supports('speculationrules')) {
console.log('Your browser supports the Speculation Rules API.');
}
הוספה דינמית של כללי ספקולציה באמצעות JavaScript
זו דוגמה להוספת prerender כלל ניחוש באמצעות JavaScript:
if (HTMLScriptElement.supports &&
HTMLScriptElement.supports('speculationrules')) {
const specScript = document.createElement('script');
specScript.type = 'speculationrules';
specRules = {
prerender: [
{
urls: ['/next.html'],
},
],
};
specScript.textContent = JSON.stringify(specRules);
console.log('added speculation rules to: next.html');
document.body.append(specScript);
}
בדף ההדגמה הזה של עיבוד מראש אפשר לראות הדגמה של עיבוד מראש באמצעות Speculation Rules API, עם הוספה של JavaScript.
הוספת רכיב <script type = "speculationrules"> ישירות ל-DOM באמצעות innerHTML לא תרשום את כללי הניחוש מטעמי אבטחה, ולכן צריך להוסיף אותו כמו שמוצג למעלה. עם זאת, תוכן שמוכנס באופן דינמי באמצעות innerHTML שמכיל קישורים חדשים, יזוהה על ידי כללים קיימים בדף.
באופן דומה, עריכה ישירה של החלונית Elements ב-כלי פיתוח ל-Chrome כדי להוסיף את הרכיב <script type = "speculationrules"> לא רושמת את כללי הניחוש, ובמקום זאת צריך להפעיל את הסקריפט מהמסוף כדי להוסיף את הכללים באופן דינמי ל-DOM.
הוספת כללי ספקולציה באמצעות כלי לניהול תגים
כדי להוסיף כללי ניחוש באמצעות כלי לניהול תגים כמו Google Tag Manager (GTM), צריך להוסיף אותם באמצעות JavaScript, ולא להוסיף את הרכיב <script type = "speculationrules"> ישירות דרך GTM, מאותן סיבות שצוינו קודם:
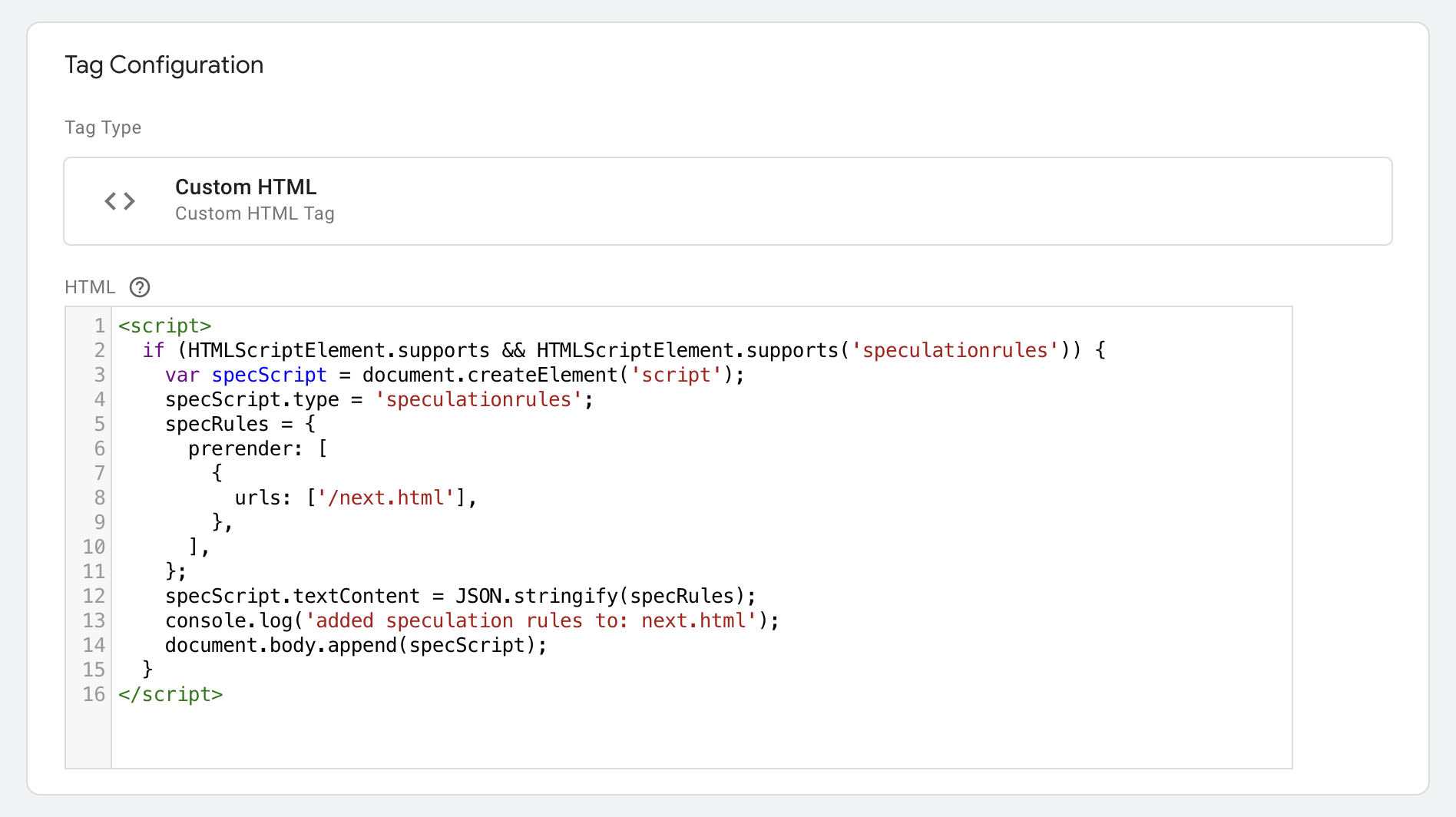
הערה: בדוגמה הזו נעשה שימוש ב-var כי GTM לא תומך ב-const.
ביטול כללי ספקולציות
הסרה של כללי ספקולציה תגרום לביטול העיבוד מראש. עם זאת, עד שזה יקרה, סביר להניח שכבר יבוזבזו משאבים על הפעלת הטרום-רנדור, ולכן מומלץ לא להשתמש בטרום-רנדור אם יש סיכוי שתצטרכו לבטל אותו. מצד שני, אפשר לעשות שימוש חוזר במשאבים שנשמרו במטמון, כך שביטולים לא בהכרח יבוזבזו לגמרי, ויכול להיות שהם עדיין יועילו לניווטים ולספקולציות עתידיות.
אפשר לבטל השערות גם באמצעות כותרת ה-HTTP Clear-Site-Data עם ההנחיות prefetchCache ו-prerenderCache.
האפשרות הזו שימושית כשמצב משתנה בשרת. לדוגמה, כשקוראים ל-API של 'הוספה לסל' או ל-API של התחברות או יציאה מהחשבון.
העדכון של המצב הזה אמור להתבצע בדפים שעברו עיבוד מראש באמצעות ממשקי API כמו Broadcast Channel API, אבל אם זה לא אפשרי או עד שהלוגיקה הזו תיושם, יכול להיות שיהיה קל יותר לבטל את הניחוש.
כללי ספקולציה ומדיניות אבטחת תוכן
מכיוון שכללי הניחוש משתמשים ברכיב <script>, גם אם הם מכילים רק JSON, צריך לכלול אותם ב-script-src Content-Security-Policy אם האתר משתמש בזה – באמצעות hash או nonce.
אפשר להוסיף inline-speculation-rules חדש ל-script-src כדי לתמוך ברכיבי <script type="speculationrules"> שמוחדרים מסקריפטים עם גיבוב או עם ערך חד-פעמי. התכונה הזו לא תומכת בכללים שכלולים ב-HTML הראשוני, ולכן צריך להחדיר כללים באמצעות JavaScript לאתרים שמשתמשים ב-CSP מחמיר.
זיהוי והשבתה של טרום-עיבוד
טרום-עיבוד בדרך כלל משפר את חוויית המשתמשים כי הוא מאפשר עיבוד מהיר של הדף – לעיתים קרובות באופן מיידי. הדבר מועיל גם למשתמש וגם לבעל האתר, כי דפים שעברו טרום-עיבוד מאפשרים חוויית משתמש טובה יותר, שאולי קשה להשיג בדרך אחרת.
עם זאת, יכול להיות שיהיו מקרים שבהם לא תרצו שהדפים יעברו רינדור מראש, למשל כשהמצב של הדפים משתנה – על סמך הבקשה הראשונית או על סמך JavaScript שמופעל בדף.
הפעלה והשבתה של טרום-עיבוד ב-Chrome
הטעינה מראש מופעלת רק למשתמשי Chrome שההגדרה 'טעינה מראש של דפים' מופעלת אצלם ב-chrome://settings/performance/. בנוסף, הרינדור מראש מושבת גם במכשירים עם זיכרון נמוך, או אם מערכת ההפעלה נמצאת במצב חיסכון בנתונים או במצב חיסכון באנרגיה. אפשר לעיין בקטע ההגבלות ב-Chrome.
זיהוי והשבתה של טרום-עיבוד בצד השרת
דפים שעברו עיבוד מראש יישלחו עם כותרת ה-HTTP Sec-Purpose:
Sec-Purpose: prefetch;prerender
בדפים שנשלפו מראש באמצעות Speculation Rules API, הכותרת הזו תוגדר לערך prefetch בלבד:
Sec-Purpose: prefetch
השרתים יכולים להגיב על סמך הכותרת הזו כדי לרשום בקשות ספקולטיביות ביומן, להחזיר תוכן שונה או למנוע טרום-עיבוד. אם מוחזר קוד תגובה סופי שלא מציין הצלחה – כלומר, לא בטווח 200-299 אחרי הפניות אוטומטיות – הדף לא יעבור עיבוד מראש וכל דף שבוצע לו אחזור מראש יימחק. חשוב גם לציין שתגובות 204 ו-205 לא תקפות גם לטרום-עיבוד, אבל הן תקפות לאחזור מראש.
אם אתם לא רוצים שדף מסוים יעבור טרום-עיבוד, הדרך הכי טובה לוודא שזה לא יקרה היא להחזיר קוד תגובה שאינו 2XX (למשל 503). עם זאת, כדי לספק את חוויית המשתמש הטובה ביותר, מומלץ לאפשר עיבוד מראש, אבל לדחות כל פעולה שצריכה לקרות רק כשהדף מוצג בפועל, באמצעות JavaScript.
זיהוי טרום-עיבוד ב-JavaScript
document.prerendering API יחזיר true בזמן שהדף עובר עיבוד מראש. דפים יכולים להשתמש בשיטה הזו כדי למנוע פעילויות מסוימות במהלך הטרום-רנדור, או לדחות אותן עד שהדף מופעל בפועל.
אחרי שמפעילים מסמך שעבר עיבוד מראש, הערך של PerformanceNavigationTiming's activationStart מוגדר גם הוא לזמן שונה מאפס שמייצג את הזמן שחלף בין תחילת העיבוד מראש לבין ההפעלה בפועל של המסמך.
אפשר להשתמש בפונקציה כדי לבדוק אם הדפים עברו עיבוד מראש או עברו עיבוד מראש, כמו בדוגמה הבאה:
function pagePrerendered() {
return (
document.prerendering ||
self.performance?.getEntriesByType?.('navigation')[0]?.activationStart > 0
);
}
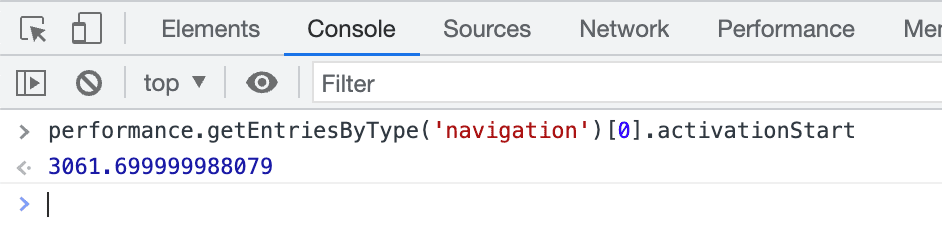
הדרך הכי קלה לבדוק אם דף עבר טרום-עיבוד (מלא או חלקי) היא לפתוח את כלי הפיתוח אחרי שהדף מופעל ולהקליד performance.getEntriesByType('navigation')[0].activationStart במסוף. אם מוחזר ערך שאינו אפס, אתם יודעים שהדף עבר טרום-עיבוד:
כשהמשתמש מפעיל את הדף על ידי צפייה בו, האירוע prerenderingchange מופעל ב-document. לאחר מכן אפשר להשתמש באירוע הזה כדי להפעיל פעילויות שהיו מופעלות כברירת מחדל בטעינת הדף, אבל אתם רוצים להשהות אותן עד שהמשתמש צופה בדף בפועל.
באמצעות ממשקי ה-API האלה, קוד JavaScript של ממשק הקצה יכול לזהות דפים שעברו עיבוד מראש ולפעול בהתאם.
ההשפעה על ניתוח הנתונים
מערכת Analytics משמשת למדידת השימוש באתר, למשל באמצעות Google Analytics למדידת צפיות בדפים ואירועים. או על ידי מדידה של מדדי הביצועים של הדפים באמצעות מעקב אחרי משתמשים אמיתיים (RUM).
צריך לבצע טרום-עיבוד של דפים רק כשיש סבירות גבוהה שהמשתמש יטען את הדף. לכן, האפשרויות של טעינה מראש בסרגל הכתובות של Chrome מופעלות רק כשיש סיכוי גבוה מאוד (מעל 80% מהזמן).
עם זאת – במיוחד כשמשתמשים ב-Speculation Rules API – יכול להיות שלדפים שעברו טרום-עיבוד תהיה השפעה על ניתוח הנתונים, ובעלי האתרים יצטרכו להוסיף קוד נוסף כדי להפעיל את ניתוח הנתונים רק לדפים שעברו טרום-עיבוד בהפעלה, כי יכול להיות שלא כל ספקי ניתוח הנתונים יעשו זאת כברירת מחדל.
אפשר להשיג את זה באמצעות Promise שממתין לאירוע prerenderingchange אם המסמך עובר עיבוד מראש, או שמבצע פעולה באופן מיידי אם הוא מוצג כרגע:
// Set up a promise for when the page is activated,
// which is needed for prerendered pages.
const whenActivated = new Promise((resolve) => {
if (document.prerendering) {
document.addEventListener('prerenderingchange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenActivated;
// Initialise your analytics
}
initAnalytics();
גישה חלופית היא להשהות את פעילויות ניתוח הנתונים עד שהדף מוצג בפעם הראשונה. כך אפשר לטפל גם במקרה של עיבוד מראש וגם במקרים שבהם כרטיסיות נפתחות ברקע (לדוגמה, באמצעות לחיצה ימנית ואפשרות הפתיחה בכרטיסייה חדשה):
// Set up a promise for when the page is first made visible
const whenFirstVisible = new Promise((resolve) => {
if (document.hidden) {
document.addEventListener('visibilitychange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenFirstVisible;
// Initialise your analytics
}
initAnalytics();
יכול להיות שזה הגיוני לניתוח נתונים ולתרחישי שימוש דומים, אבל במקרים אחרים יכול להיות שתרצו לטעון יותר תוכן, ולכן כדאי להשתמש ב-document.prerendering וב-prerenderingchange כדי לטרגט באופן ספציפי דפים שמוצגים מראש.
השהיית תוכן אחר במהלך טרום-הרינדור
אפשר להשתמש באותם ממשקי API שצוינו קודם כדי להשהות תוכן אחר במהלך שלב הטרום-עיבוד. אלה יכולים להיות חלקים ספציפיים של JavaScript או רכיבי סקריפט שלמים שאתם מעדיפים שלא יפעלו במהלך שלב הטרום-עיבוד.
לדוגמה, אם נתון הסקריפט הבא:
<script src="https://example.com/app/script.js" async></script>
אפשר לשנות את זה לרכיב סקריפט שמוסיף את עצמו באופן דינמי, ומוסיף את עצמו רק על סמך הפונקציה הקודמת whenActivated:
async function addScript(scriptUrl) {
await whenActivated;
const script = document.createElement('script');
script.src = 'scriptUrl';
document.body.appendChild(script);
}
addScript('https://example.com/app/script.js');
האפשרות הזו יכולה להיות שימושית כדי לעכב סקריפטים נפרדים שכוללים ניתוח נתונים, או כדי לעבד תוכן על סמך מצב או משתנים אחרים שיכולים להשתנות במהלך הביקור. לדוגמה, יכול להיות שהמלצות, סטטוס התחברות או סמלים של עגלת קניות לא יוצגו כדי לוודא שמוצג המידע העדכני ביותר.
יכול להיות שהמקרים האלה יקרו יותר פעמים כשמשתמשים בטרום-עיבוד, אבל הם יכולים לקרות גם בדפים שנטענים בכרטיסיות ברקע (כמו שצוין קודם), ולכן אפשר להשתמש בפונקציה whenFirstVisible במקום בפונקציה whenActivated.
במקרים רבים, מומלץ לבדוק את המצב גם בשינויים כלליים ב-visibilitychange – לדוגמה, כשחוזרים לדף שהיה ברקע, צריך לעדכן את מוני עגלת הקניות במספר הפריטים העדכני בעגלה. לכן, זו לא בעיה שקשורה ספציפית לטרום-עיבוד, אלא שהטרום-עיבוד פשוט הופך בעיה קיימת לברורה יותר.
אחת הדרכים שבהן Chrome מצמצם את הצורך בהוספת תגי עטיפה לסקריפטים או לפונקציות באופן ידני היא השהיה של ממשקי API מסוימים, כפי שצוין קודם. בנוסף, לא מתבצע רינדור של iframe של צד שלישי, ולכן רק תוכן שמוצג מעל ה-iframe הזה צריך להיות מושהה באופן ידני.
למדוד ביצועים
כדי למדוד מדדי ביצועים, מערכת הניתוח צריכה לקבוע אם עדיף למדוד אותם על סמך זמן ההפעלה ולא על סמך זמן טעינה של דף שדוחות ממשקי ה-API של הדפדפן.
המדדים הבסיסיים של חוויית המשתמש (Core Web Vitals) נמדדים על ידי Chrome באמצעות הדוח על חוויית המשתמש ב-Chrome (CrUX), והם נועדו למדוד את חוויית המשתמש. לכן המדדים האלה נמדדים על סמך זמן ההפעלה. לדוגמה, לעיתים קרובות זה יוביל ל-LCP של 0 שניות, מה שמראה שזו דרך מצוינת לשפר את מדדי ה-Core Web Vitals.
החל מגרסה 3.1.0, הספרייה web-vitals עודכנה כדי לטפל בניווטים שעברו עיבוד מראש באותו אופן שבו Chrome מודד את Core Web Vitals. בנוסף, בגרסה הזו, אם הדף עבר טרום-עיבוד מלא או חלקי, המערכת מסמנת את הניווטים שעברו טרום-עיבוד במדדים האלה באמצעות מאפיין Metric.navigationType.
מדידת טרום-רינדורים
כדי לראות אם דף מסוים עבר טרום-עיבוד, אפשר לחפש רשומה של PerformanceNavigationTiming עם ערך שונה מאפס activationStart. אפשר לתעד את זה באמצעות מאפיין מותאם אישית, או בדרך דומה כשמתעדים את הצפיות בדף, למשל באמצעות הפונקציה pagePrerendered שמתוארת למעלה:
// Set Custom Dimension for Prerender status
gtag('set', { 'dimension1': pagePrerendered() });
// Initialise GA - including sending page view by default
gtag('config', 'G-12345678-1');
כך תוכלו לראות בניתוח הנתונים כמה ניווטים עברו טרום-עיבוד בהשוואה לסוגים אחרים של ניווטים, וגם ליצור קורלציה בין מדדי ביצועים או מדדים עסקיים לבין סוגי הניווטים השונים האלה. דפים שנטענים מהר יותר משמחים את המשתמשים, ולעיתים קרובות יש לכך השפעה אמיתית על מדדים עסקיים, כפי שאפשר לראות במחקרים שלנו.
כשמודדים את ההשפעה העסקית של עיבוד מראש של דפים לצורך ניווט מהיר בין דפים, אפשר להחליט אם כדאי להשקיע יותר מאמץ בשימוש בטכנולוגיה הזו כדי לאפשר עיבוד מראש של יותר ניווטים, או לבדוק למה דפים לא עוברים עיבוד מראש.
מדידת שיעורי ההצלחה
בנוסף למדידת ההשפעה של דפים שנכנסים אליהם אחרי טרום-רנדור, חשוב גם למדוד דפים שעברו טרום-רנדור ולא נכנסים אליהם בהמשך. יכול להיות שאתם מבצעים יותר מדי טרום-עיבוד, ומשתמשים במשאבים יקרי ערך של המשתמש ללא תועלת רבה.
אפשר למדוד את זה על ידי הפעלת אירוע ניתוח נתונים כשמוסיפים כללי ניחוש – אחרי שבודקים אם הדפדפן תומך בעיבוד מראש באמצעות HTMLScriptElement.supports('speculationrules') – כדי לציין שהתבקש עיבוד מראש. (הערה: רק בגלל שהתבקש עיבוד מראש, לא אומר שהעיבוד מראש התחיל או הסתיים. כמו שצוין קודם, עיבוד מראש הוא רמז לדפדפן, והוא יכול לבחור לא לעבד מראש דפים על סמך הגדרות המשתמש, שימוש נוכחי בזיכרון או היוריסטיקות אחרות).
אחרי כן, תוכלו להשוות בין מספר האירועים האלה לבין מספר הצפיות בדפים שבוצעו בפועל לפני הרינדור. אפשרות אחרת היא להפעיל אירוע נוסף בהפעלה, אם זה מקל על ההשוואה.
אפשר להעריך את 'שיעור ההצלחה של ההיט' על סמך ההבדל בין שני הנתונים האלה. בדפים שבהם אתם משתמשים ב-Speculation Rules API כדי לבצע טרום-עיבוד של הדפים, אתם יכולים לשנות את הכללים בהתאם כדי לשמור על שיעור פגיעה גבוה. כך תוכלו לשמור על האיזון בין שימוש במשאבי המשתמשים כדי לעזור להם לבין שימוש מיותר במשאבים.
חשוב לזכור שיכול להיות שמתבצע רינדור מראש של חלק מהדפים בגלל הרינדור מראש של סרגל הכתובות, ולא רק בגלל כללי הניחוש. אם רוצים להבדיל בין הניווטים האלה, אפשר לבדוק את document.referrer (שיהיה ריק בניווטים בסרגל הכתובות, כולל ניווטים בסרגל הכתובות שעברו טרום-עיבוד).
חשוב לבדוק גם דפים שלא מתבצע בהם טרום-רנדור, כי יכול להיות שהדפים האלה לא עומדים בדרישות לטרום-רנדור, גם לא מסרגל הכתובות. יכול להיות שאתם לא נהנים מהשיפור הזה בביצועים. צוות Chrome מתכנן להוסיף כלי בדיקה נוסף כדי לבדוק את הזכאות לטרום-עיבוד, אולי בדומה לכלי הבדיקה של מטמון הדפדפן, וגם להוסיף API כדי להסביר למה טרום-העיבוד נכשל.
השפעה על תוספים
בפוסט הייעודי בנושא תוספים ל-Chrome: הרחבת ה-API לתמיכה בניווט מיידי מפורטים שיקולים נוספים שיוצרי תוספים צריכים לקחת בחשבון לגבי דפים שעברו עיבוד מראש.
משוב
צוות Chrome מפתח באופן פעיל את התכונה 'עיבוד מראש', ויש תוכניות רבות להרחבת היקף התכונות שזמינות בגרסה 108 של Chrome. נשמח לקבל משוב על מאגר GitHub או על השימוש בכלי למעקב אחר בעיות. אנחנו מצפים לשמוע על מחקרי מקרה של ה-API החדש והמעניין הזה ולשתף אותם.
קישורים רלוונטיים
- Speculation Rules Codelab
- ניפוי באגים בכללי ספקולציות
- חדש: NoState Prefetch
- מפרט Speculation Rules API
- מאגר GitHub של ניחוש ניווט
- תוספים ל-Chrome: הרחבת ה-API לתמיכה בניווט מיידי
תודות
תמונה ממוזערת מאת Marc-Olivier Jodoin ב-Unsplash