
robots.txt 文件可告知搜索引擎他们可以将您网站上的哪些网页
抓取。无效的 robots.txt 配置可能会导致以下两种问题:
- 它会阻止搜索引擎抓取公共网页,导致 内容在搜索结果中的出现频率。
- 它可能会导致搜索引擎抓取您可能不希望显示在搜索结果中的网页 结果。
Lighthouse robots.txt 审核失败的原因
Lighthouse 标志无效
robots.txt 文件:
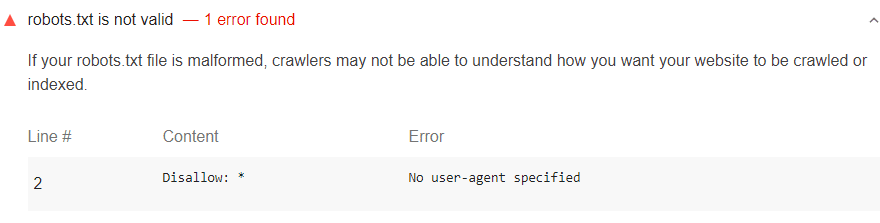
展开报告中的robots.txt无效审核
了解您的robots.txt有什么问题。
常见错误包括:
No user-agent specifiedPattern should either be empty, start with "/" or "*"Unknown directiveInvalid sitemap URL$ should only be used at the end of the pattern
Lighthouse 不会检查您的 robots.txt 文件是否
正确位置。该文件必须位于
您的域名或子域名。
如何解决与 robots.txt 相关的问题
确保 robots.txt 不会返回 HTTP 5XX 状态代码
如果您的服务器返回服务器错误(HTTP 状态代码
500 秒内)对于 robots.txt,搜索引擎不知道应将哪些网页
抓取。它们可能会停止抓取您的整个网站,而这会阻止新的
禁止将内容编入索引。
若要检查 HTTP 状态代码,请在 Chrome 中打开 robots.txt,然后
在 Chrome 开发者工具中检查请求。
使 robots.txt 小于 500 KiB
如果 robots.txt 的文件遭到删除,搜索引擎可能会中途停止处理它。
超过 500 KiB。这可能会使搜索引擎混淆,从而导致不正确
对您网站的抓取
为缩减robots.txt的大小,请减少关注已单独排除的网页等选项
更为广泛的模式。例如,如果您需要禁止 Google 抓取 PDF 文件,
而不是禁止逐个文件而是禁止所有包含
.pdf(通过使用 disallow: /*.pdf)。
修正所有格式错误
- 仅限与“name: value”匹配的空行、注释和指令格式为
允许在
robots.txt中使用。 - 请确保
allow和disallow值为空或者以/或*开头。 - 请勿在值中间使用
$(例如allow: /file$html)。
确保为“user-agent”设置一个值
用户代理名称用于告诉搜索引擎抓取工具要遵循哪些指令。您
必须为 user-agent 的每个实例提供一个值,以便搜索引擎知道
以及是否遵循相关指令集。
要指定特定的搜索引擎抓取工具,请使用 已发布的列表(例如,以下是 Google 的用于抓取的用户代理的列表。)
使用 * 可匹配所有原本不匹配的抓取工具。
user-agent: disallow: /downloads/
未定义用户代理。
user-agent: * disallow: /downloads/ user-agent: magicsearchbot disallow: /uploads/
定义了常规用户代理和 magicsearchbot 用户代理。
确保 user-agent 前没有 allow 或 disallow 指令
用户代理名称定义了 robots.txt 文件的各个部分。搜索引擎
抓取工具将根据这些部分确定要遵循的指令。将
指令 before 表示任何抓取工具都不会跟踪
。
# start of file disallow: /downloads/ user-agent: magicsearchbot allow: /
任何搜索引擎抓取工具都不会读取 disallow: /downloads 指令。
# start of file user-agent: * disallow: /downloads/
系统禁止所有搜索引擎抓取“/downloads”文件夹。
搜索引擎抓取工具只会遵循
特定用户代理名称。例如,如果您有针对
user-agent: * 和 user-agent: Googlebot-Image,Googlebot 图片将只会
请遵循 user-agent: Googlebot-Image 部分中的指令。
提供 sitemap 的绝对网址
站点地图文件是 让搜索引擎知道您网站上的网页的有效方式。站点地图文件通常包含一系列 您网站上的网址,以及这些网址上次出现的时间的相关信息 已更改。
如果您选择在robots.txt中提交站点地图文件,请务必
使用绝对网址。
sitemap: /sitemap-file.xml
sitemap: https://example.com/sitemap-file.xml