


Blink fait référence à l'implémentation de la plate-forme Web par Chromium. Il englobe toutes les phases de rendu avant le compositing, qui se termine par le commit du moteur de composition. Pour en savoir plus sur l'architecture de rendu de Blink, consultez un article précédent de cette série.
Blink est né d'une fourchette de WebKit, qui est lui-même une fourchette de KHTML, qui date de 1998. Il contient certains des codes les plus anciens (et les plus critiques) de Chromium, et en 2014, il commençait à montrer son âge. Cette année-là, nous avons lancé un ensemble de projets ambitieux sous le nom de BlinkNG, dans le but de remédier aux lacunes de longue date de l'organisation et de la structure du code Blink. Cet article présente BlinkNG et les projets qui le constituent: pourquoi nous les avons réalisés, ce qu'ils ont accompli, les principes directeurs qui ont façonné leur conception et les possibilités d'améliorations futures qu'ils offrent.
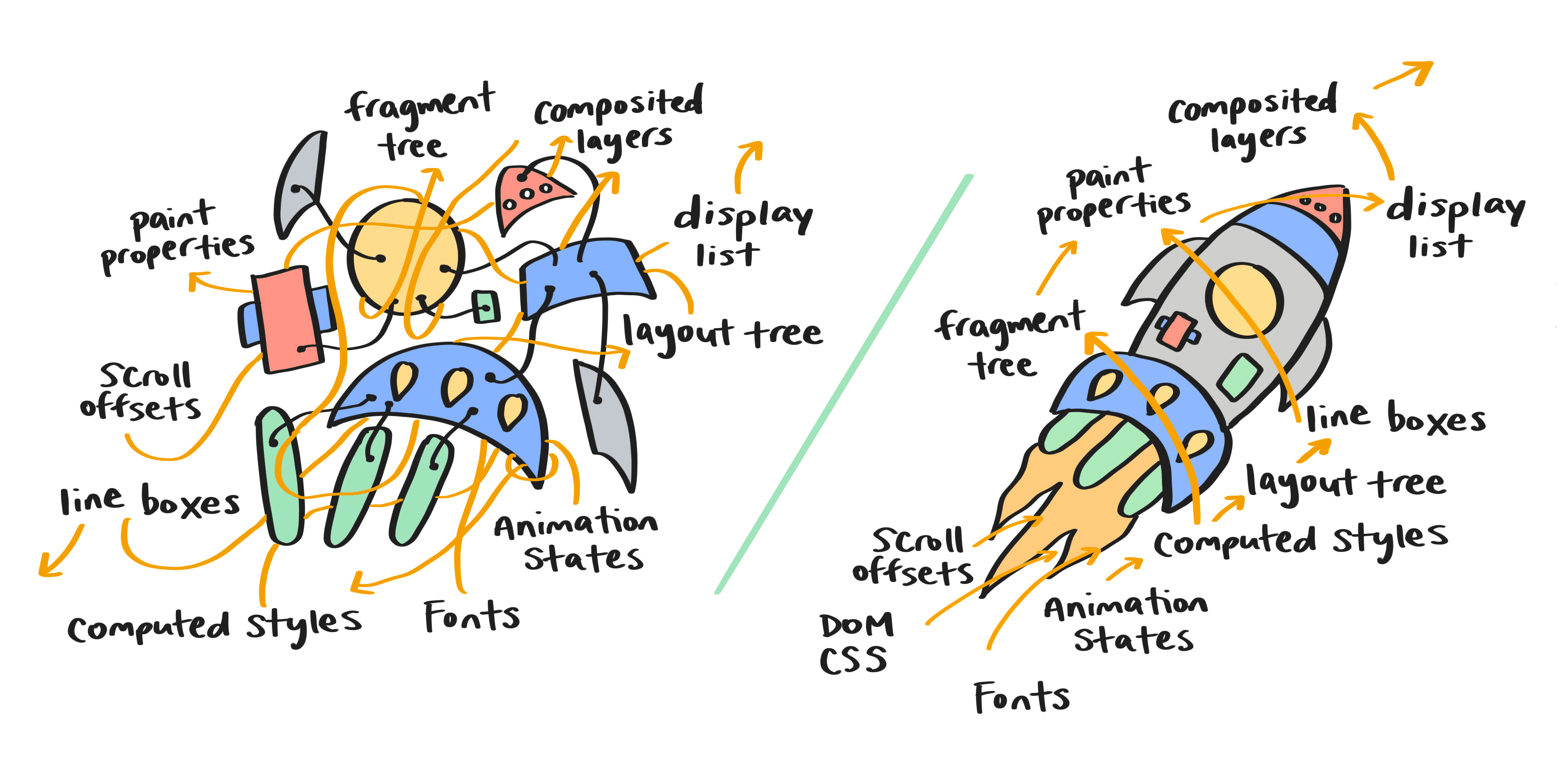
Rendu avant NG
Le pipeline de rendu dans Blink a toujours été conceptualisé en phases (style, mise en page, peinture, etc.), mais les barrières d'abstraction étaient poreuses. De manière générale, les données associées au rendu consistaient en des objets immuables et durables. Ces objets pouvaient être modifiés à tout moment (et l'étaient) et étaient fréquemment recyclés et réutilisés par des mises à jour de rendu successives. Il était impossible de répondre de manière fiable à des questions simples telles que:
- La sortie du style, de la mise en page ou de la peinture doit-elle être mise à jour ?
- Quand ces données auront-elles leur valeur "finale" ?
- Quand est-il possible de modifier ces données ?
- Quand cet objet sera-t-il supprimé ?
Voici quelques exemples:
Style générait des ComputedStyle en fonction des feuilles de style, mais ComputedStyle n'était pas immuable. Dans certains cas, il était modifié par les étapes ultérieures du pipeline.
Style génère un arbre de LayoutObject, puis mise en page annote ces objets avec des informations sur la taille et le positionnement. Dans certains cas, la mise en page modifie même la structure arborescente. Il n'y avait pas de séparation claire entre les entrées et les sorties de la mise en page.
Style générait des structures de données accessoires qui déterminaient le cours de la composition. Ces structures de données étaient modifiées sur place à chaque phase après style.
À un niveau inférieur, les types de données de rendu se composent principalement d'arbres spécialisés (par exemple, l'arbre DOM, l'arbre de style, l'arbre de mise en page et l'arbre de propriétés de peinture). Les phases de rendu sont implémentées sous forme d'explorations d'arbres récursives. Idéalement, une exploration d'arbre doit être contenue: lorsque vous traitez un nœud d'arbre donné, vous ne devez pas accéder à des informations en dehors du sous-arbre dont ce nœud est la racine. Ce n'était jamais vrai avant RenderingNG. Les parcours d'arborescence accèdent fréquemment aux informations des ancêtres du nœud en cours de traitement. Ce système était donc très fragile et sujet aux erreurs. Il était également impossible de commencer une exploration de l'arborescence à partir d'un autre nœud que la racine.
Enfin, de nombreux points d'entrée dans le pipeline de rendu étaient répartis dans le code: mises en page forcées déclenchées par JavaScript, mises à jour partielles déclenchées lors du chargement du document, mises à jour forcées pour préparer le ciblage par événement, mises à jour planifiées demandées par le système d'affichage et API spécialisées exposées uniquement au code de test, pour n'en citer que quelques-unes. Il y avait même quelques chemins récursifs et réentrants dans le pipeline de rendu (c'est-à-dire, des sauts au début d'une étape à partir du milieu d'une autre). Chacune de ces rampes d'accès avait son propre comportement particulier, et dans certains cas, la sortie du rendu dépendait de la manière dont la mise à jour du rendu était déclenchée.
Modifications apportées
BlinkNG est composé de nombreux sous-projets, grands et petits, dont l'objectif commun est d'éliminer les lacunes architecturales décrites précédemment. Ces projets partagent quelques principes directeurs conçus pour rendre le pipeline de rendu plus proche d'un pipeline réel:
- Point d'entrée uniforme: nous devons toujours entrer dans le pipeline au début.
- Étapes fonctionnelles: chaque étape doit avoir des entrées et des sorties bien définies, et son comportement doit être fonctionnel, c'est-à-dire déterministe et reproductible, et les sorties ne doivent dépendre que des entrées définies.
- Entrées constantes: les entrées de chaque étape doivent être effectivement constantes pendant l'exécution de l'étape.
- Sorties immuables: une fois une étape terminée, ses sorties doivent être immuables pour le reste de la mise à jour du rendu.
- Cohérence des points de contrôle: à la fin de chaque étape, les données de rendu produites jusqu'à présent doivent être dans un état cohérent.
- Déduplication du travail: ne calculez chaque élément qu'une seule fois.
Une liste complète des sous-projets BlinkNG serait une lecture fastidieuse, mais voici quelques-uns d'entre eux qui ont une importance particulière.
Cycle de vie des documents
La classe DocumentLifecycle suit notre progression dans le pipeline de rendu. Il nous permet d'effectuer des vérifications de base qui appliquent les invariants listés précédemment, par exemple:
- Si nous modifions une propriété ComputedStyle, le cycle de vie du document doit être
kInStyleRecalc. - Si l'état de DocumentLifecycle est
kStyleCleanou version ultérieure,NeedsStyleRecalc()doit renvoyer false pour tout nœud associé. - Lorsque vous entrez dans la phase de cycle de vie de la peinture, l'état du cycle de vie doit être
kPrePaintClean.
Au cours de l'implémentation de BlinkNG, nous avons systématiquement éliminé les chemins de code qui ne respectaient pas ces invariants et avons ajouté de nombreuses autres assertions dans le code pour nous assurer de ne pas régresser.
Si vous avez déjà exploré le code de rendu de bas niveau, vous vous êtes peut-être demandé : "Comment en suis-je arrivé là ?" Comme indiqué précédemment, il existe différents points d'entrée dans le pipeline de rendu. Auparavant, cela incluait les chemins d'appel récursifs et réentrants, ainsi que les endroits où nous entrions dans le pipeline à une phase intermédiaire, plutôt qu'au début. Au cours de BlinkNG, nous avons analysé ces chemins d'appel et déterminé qu'ils pouvaient tous être réduits à deux scénarios de base:
- Toutes les données de rendu doivent être mises à jour, par exemple lorsque vous générez de nouveaux pixels à afficher ou effectuez un test de contact pour le ciblage par événement.
- Nous avons besoin d'une valeur à jour pour une requête spécifique, à laquelle nous pouvons répondre sans mettre à jour toutes les données de rendu. Cela inclut la plupart des requêtes JavaScript, par exemple
node.offsetTop.
Il n'y a désormais que deux points d'entrée dans le pipeline de rendu, correspondant à ces deux scénarios. Les chemins de code réentrants ont été supprimés ou refactorisés, et il n'est plus possible d'accéder au pipeline à partir d'une phase intermédiaire. Cela a éliminé beaucoup de mystère sur le moment exact et la manière dont les mises à jour de rendu se produisent, ce qui facilite grandement la compréhension du comportement du système.
Style, mise en page et pré-peinture du pipeline
Collectivement, les phases de rendu avant paint sont responsables des éléments suivants:
- Exécution de l'algorithme de cascade de styles pour calculer les propriétés de style finales des nœuds DOM.
- Génération de l'arborescence de mise en page représentant la hiérarchie des cases du document.
- Détermination des informations de taille et de position pour toutes les zones.
- Arrondissement ou alignement de la géométrie sous-pixel sur les limites de pixel entier pour la peinture.
- Déterminer les propriétés des calques composites (transformation affine, filtres, opacité ou tout autre élément pouvant être accéléré par GPU).
- Déterminer le contenu qui a changé depuis la phase de peinture précédente et qui doit être peint ou repeint (invalidation de la peinture).
Cette liste n'a pas changé, mais avant BlinkNG, une grande partie de ce travail était effectuée de manière ad hoc, répartie sur plusieurs phases de rendu, avec de nombreuses fonctionnalités en double et des inefficacités intégrées. Par exemple, la phase style a toujours été principalement chargée de calculer les propriétés de style finales des nœuds. Toutefois, dans certains cas particuliers, nous n'avons pas déterminé les valeurs des propriétés de style finales avant la fin de la phase style. Il n'existait aucun point formel ou exécutable du processus de rendu où nous pouvions affirmer avec certitude que les informations de style étaient complètes et immuables.
Un autre bon exemple de problème antérieur à BlinkNG est l'invalidation de la peinture. Auparavant, l'invalidation de la peinture était répartie dans toutes les phases de rendu menant à la peinture. Lorsque vous modifiez le code de style ou de mise en page, il était difficile de savoir quelles modifications de la logique d'invalidation de la peinture étaient nécessaires, et il était facile de commettre une erreur entraînant des bugs d'invalidation insuffisante ou excessive. Pour en savoir plus sur les subtilités de l'ancien système d'invalidation de la peinture, consultez l'article de cette série consacré à LayoutNG.
L'ancrage de la géométrie de mise en page au niveau des sous-pixels aux limites de pixels entiers pour la peinture est un exemple de cas où nous avons implémenté plusieurs fois la même fonctionnalité et effectué beaucoup de travail redondant. Le système de peinture utilisait un chemin de code d'ancrage au pixel et un chemin de code entièrement distinct chaque fois que nous avions besoin d'un calcul ponctuel et instantané des coordonnées d'ancrage au pixel en dehors du code de peinture. Inutile de dire que chaque implémentation avait ses propres bugs, et que les résultats n'étaient pas toujours identiques. Comme ces informations n'étaient pas mises en cache, le système effectuait parfois exactement le même calcul de manière répétée, ce qui entraînait une autre baisse des performances.
Voici quelques projets importants qui ont éliminé les déficits architecturaux des phases de rendu avant la peinture.
Project Squad: pipeline de la phase de style
Ce projet a permis de résoudre deux problèmes principaux de la phase de style qui empêchaient son pipeline de fonctionner correctement:
La phase de style produit deux principaux résultats: ComputedStyle, qui contient le résultat de l'exécution de l'algorithme de cascade CSS sur l'arborescence DOM, et un arbre de LayoutObjects, qui établit l'ordre des opérations pour la phase de mise en page. Conceptuellement, l'exécution de l'algorithme de cascade doit se produire strictement avant la génération de l'arborescence de mise en page. Toutefois, auparavant, ces deux opérations étaient entrelacées. Project Squad a réussi à diviser ces deux phases en phases distinctes et séquentielles.
Auparavant, ComputedStyle n'obtenait pas toujours sa valeur finale lors du calcul des styles. Dans certains cas, ComputedStyle était mis à jour lors d'une phase ultérieure du pipeline. Project Squad a refactorisé avec succès ces chemins de code afin que ComputedStyle ne soit jamais modifié après la phase de style.
LayoutNG: mise en pipeline de la phase de mise en page
Ce projet monumental, l'un des piliers de RenderingNG, a consisté à réécrire complètement la phase de rendu de la mise en page. Nous ne ferons pas justice à l'ensemble du projet ici, mais voici quelques aspects notables du projet BlinkNG global:
- Auparavant, la phase de mise en page recevait un arbre de
LayoutObjectcréé par la phase de style et annotait l'arbre avec des informations sur la taille et la position. Il n'y avait donc pas de séparation nette entre les entrées et les sorties. LayoutNG a introduit l'arborescence de fragments, qui est la sortie principale en lecture seule de la mise en page et sert d'entrée principale aux phases de rendu ultérieures. - LayoutNG a introduit la propriété de structuration dans la mise en page: lorsque vous calculez la taille et la position d'un
LayoutObjectdonné, vous ne regardez plus en dehors du sous-arbre enraciné sur cet objet. Toutes les informations nécessaires pour mettre à jour la mise en page d'un objet donné sont calculées à l'avance et fournies en entrée en lecture seule à l'algorithme. - Auparavant, il existait des cas particuliers où l'algorithme de mise en page n'était pas strictement fonctionnel: le résultat de l'algorithme dépendait de la mise à jour de mise en page la plus récente. LayoutNG a éliminé ces cas.
Phase de pré-peinture
Auparavant, il n'y avait pas de phase de rendu pré-peinture formelle, mais un ensemble d'opérations post-mise en page. La phase de pré-peinture est née de la constatation qu'il existait quelques fonctions associées qui pouvaient être mieux implémentées en tant que parcours systématique de l'arborescence de mise en page une fois la mise en page terminée. Plus important encore:
- Émission d'invalidations de peinture: il est très difficile d'effectuer une invalidation de peinture correctement au cours de la mise en page, lorsque les informations sont incomplètes. Il est beaucoup plus facile de bien faire et peut être très efficace s'il est divisé en deux processus distincts: lors de la mise en forme et du style, le contenu peut être marqué d'un simple indicateur booléen comme "peut-être nécessite une invalidation de la peinture". Lors de l'exploration de l'arborescence avant la peinture, nous vérifions ces indicateurs et émettons des invalidations si nécessaire.
- Générer des arborescences de propriétés de peinture: processus décrit plus en détail ultérieurement.
- Calcul et enregistrement des emplacements de peinture en pixels: les résultats enregistrés peuvent être utilisés par la phase de peinture, ainsi que par tout code en aval qui en a besoin, sans calcul redondant.
Arbres d'établissements: géométrie cohérente
Les arborescences de propriétés ont été introduites dans RenderingNG pour gérer la complexité du défilement, qui sur le Web a une structure différente de tous les autres types d'effets visuels. Avant les arbres de propriétés, le compositeur de Chromium utilisait une seule hiérarchie de "couches " pour représenter la relation géométrique du contenu composite, mais cela s'est rapidement effondré à mesure que la complexité complète de fonctionnalités telles que position:fixed est devenue évidente. La hiérarchie des calques a vu apparaître des pointeurs non locaux supplémentaires indiquant le "parent de défilement" ou le "parent de découpe" d'un calque. Le code est alors devenu très difficile à comprendre.
Les arborescences de propriétés ont permis de résoudre ce problème en représentant les aspects de défilement et de découpe du contenu en dehors de la zone visible séparément de tous les autres effets visuels. Cela a permis de modéliser correctement la véritable structure visuelle et de défilement des sites Web. Ensuite, il nous a suffi d'implémenter des algorithmes au-dessus des arbres de propriétés, comme la transformation de l'espace d'écran des calques composites, ou de déterminer quelles calques étaient défilées et lesquelles ne l'étaient pas.
En fait, nous avons rapidement remarqué que de nombreuses autres parties du code posaient des questions géométriques similaires. (Vous trouverez une liste plus complète dans l'article sur les principales structures de données.) Plusieurs d'entre eux comportaient des implémentations en double de la même chose que le code du moteur de rendu. Tous présentaient un sous-ensemble différent de bugs, et aucun d'entre eux ne modélisait correctement la structure réelle d'un site Web. La solution est alors devenue claire: centraliser tous les algorithmes de géométrie au même endroit et refactoriser tout le code pour l'utiliser.
Ces algorithmes dépendent tous des arbres de propriétés. C'est pourquoi les arbres de propriétés sont une structure de données clé (c'est-à-dire utilisée tout au long du pipeline) de RenderingNG. Pour atteindre cet objectif de code de géométrie centralisé, nous avons dû introduire le concept d'arborescence de propriétés beaucoup plus tôt dans le pipeline (en pré-peinture) et modifier toutes les API qui en dépendaient pour qu'elles exigent l'exécution de la pré-peinture avant de pouvoir s'exécuter.
Cette histoire est un autre aspect du modèle de refactoring BlinkNG: identifier les calculs clés, les refactorer pour éviter de les dupliquer et créer des étapes de pipeline bien définies qui créent les structures de données qui les alimentent. Nous calculons les arbres de propriétés au moment exact où toutes les informations nécessaires sont disponibles. Nous nous assurons également que les arbres de propriétés ne peuvent pas changer pendant l'exécution des étapes de rendu ultérieures.
Compositing après peinture: pipeline de peinture et compositing
La stratification consiste à déterminer quel contenu DOM est placé dans sa propre couche composite (qui représente à son tour une texture GPU). Avant RenderingNG, la stratification s'exécutait avant la peinture, et non après (consultez cette page pour connaître le pipeline actuel et notez l'ordre modifié). Nous décidions d'abord de quelle partie du DOM était affectée à quelle couche composite, puis nous dessinions des listes d'affichage pour ces textures. Naturellement, les décisions dépendaient de facteurs tels que les éléments DOM qui étaient animés ou défilaient, ou qui avaient des transformations 3D, et les éléments qui étaient peints par-dessus les autres.
Cela a causé des problèmes majeurs, car cela nécessitait plus ou moins des dépendances circulaires dans le code, ce qui est un gros problème pour un pipeline de rendu. Voyons pourquoi à l'aide d'un exemple. Supposons que nous devions invalider la peinture (ce qui signifie que nous devons redessiner la liste d'affichage, puis la rasteriser à nouveau). L'invalidation peut être nécessaire en raison d'une modification du DOM, ou d'un changement de style ou de mise en page. Mais bien sûr, nous ne souhaitons invalider que les parties qui ont effectivement changé. Cela impliquait de déterminer quelles couches composées étaient concernées, puis d'invalider une partie ou la totalité des listes d'affichage de ces couches.
Cela signifie que l'invalidation dépendait du DOM, du style, de la mise en page et des décisions de stratification précédentes (passé: pour le frame de rendu précédent). Mais la stratification actuelle dépend également de tous ces éléments. Et comme nous ne disposions pas de deux copies de toutes les données de stratification, il était difficile de faire la différence entre les décisions de stratification passées et futures. Nous avons donc fini par avoir beaucoup de code avec un raisonnement circulaire. Cela entraînait parfois un code illogique ou incorrect, voire des plantages ou des problèmes de sécurité, si nous n'étions pas très prudents.
Pour faire face à cette situation, nous avons introduit très tôt le concept de l'objet DisableCompositingQueryAsserts. Dans la plupart des cas, si le code tentait d'interroger des décisions de stratification précédentes, cela entraînait un échec d'assertion et le navigateur plantait s'il était en mode débogage. Cela nous a permis d'éviter d'introduire de nouveaux bugs. Dans chaque cas où le code avait légitimement besoin d'interroger les décisions de stratification précédentes, nous avons ajouté du code pour l'autoriser en allouant un objet DisableCompositingQueryAsserts.
Notre plan était de supprimer progressivement tous les objets DisableCompositingQueryAssert des sites d'appel, puis de déclarer le code sûr et correct. Cependant, nous avons découvert qu'un certain nombre d'appels étaient pratiquement impossibles à supprimer tant que la stratification avait eu lieu avant la peinture. (Nous n'avons finalement pu la supprimer que très récemment.) C'est la première raison découverte pour le projet Composite After Paint. Nous avons appris que, même si vous disposez d'une phase de pipeline bien définie pour une opération, si elle se trouve au mauvais endroit dans le pipeline, vous finirez par vous retrouver dans une impasse.
La deuxième raison du projet Composite After Paint était le bug de composition de base. Pour résumer ce bug, les éléments DOM ne sont pas une bonne représentation au format 1:1 d'un schéma de stratification efficace ou complet pour le contenu des pages Web. Et comme le compositing était antérieur à la peinture, il dépendait plus ou moins intrinsèquement des éléments DOM, et non des listes d'affichage ni des arborescences de propriétés. C'est très similaire à la raison pour laquelle nous avons introduit les arbres de propriétés. Tout comme avec les arbres de propriétés, la solution s'obtient directement si vous identifiez la bonne phase de pipeline, l'exécutez au bon moment et lui fournissez les structures de données clés appropriées. Comme pour les arbres de propriétés, cela a été une bonne occasion de garantir qu'une fois la phase de peinture terminée, sa sortie est immuable pour toutes les phases de pipeline ultérieures.
Avantages
Comme vous l'avez vu, un pipeline de rendu bien défini offre d'énormes avantages à long terme. Il y en a même plus que vous ne le pensez:
- Fiabilité considérablement améliorée: cette affirmation est assez simple. Un code plus clair avec des interfaces bien définies et compréhensibles est plus facile à comprendre, à écrire et à tester. Cela le rend plus fiable. Cela rend également le code plus sûr et plus stable, avec moins de plantages et moins de bugs "use-after-free".
- Couverture des tests étendue: au cours de BlinkNG, nous avons ajouté de nombreux nouveaux tests à notre suite. Cela inclut des tests unitaires qui fournissent une vérification ciblée des éléments internes, des tests de régression qui nous empêchent de réintroduire d'anciens bugs que nous avons corrigés (tant !) et de nombreux ajouts à la suite de tests de la plate-forme Web publique et gérée collectivement, que tous les navigateurs utilisent pour mesurer la conformité aux normes Web.
- Plus facile à étendre: si un système est décomposé en composants clairs, il n'est pas nécessaire de comprendre les autres composants à un niveau de détail donné pour progresser sur le système actuel. Cela permet à tous d'ajouter de la valeur au code de rendu sans avoir à être un expert, et de raisonner plus facilement sur le comportement de l'ensemble du système.
- Performances: optimiser des algorithmes écrits en code spaghetti est déjà assez difficile, mais il est presque impossible d'obtenir des résultats encore plus importants, comme le défilement et les animations avec threads universels ou les processus et threads pour l'isolation des sites sans un tel pipeline. Le parallélisme peut nous aider à améliorer considérablement les performances, mais il est également extrêmement complexe.
- Rendement et structuration: BlinkNG propose plusieurs nouvelles fonctionnalités qui permettent d'utiliser le pipeline de manières nouvelles et innovantes. Par exemple, que se passe-t-il si nous ne voulons exécuter le pipeline de rendu que jusqu'à l'expiration d'un budget ? Ou ignorer le rendu des sous-arbres qui ne sont pas pertinents pour l'utilisateur pour le moment ? C'est ce que permet la propriété CSS content-visibility. Que faire si vous souhaitez que le style d'un composant dépende de sa mise en page ? Il s'agit des requêtes de conteneur.
Étude de cas: Requêtes de conteneur
Les requêtes de conteneur sont une fonctionnalité de plate-forme Web très attendue (c'est la fonctionnalité la plus demandée par les développeurs CSS depuis des années). S'il est si génial, pourquoi n'existe-t-il pas encore ? En effet, l'implémentation de requêtes de conteneur nécessite une compréhension et un contrôle très précis de la relation entre le code de style et de mise en page. Voyons cela de plus près.
Une requête de conteneur permet aux styles appliqués à un élément de dépendre de la taille mise en page d'un ancêtre. Étant donné que la taille mise en page est calculée pendant la mise en page, cela signifie que nous devons exécuter le calcul des styles après la mise en page. Cependant, le calcul des styles s'exécute avant la mise en page. C'est ce paradoxe du poulet et de l'œuf qui nous a empêchés d'implémenter des requêtes de conteneur avant BlinkNG.
Comment pouvons-nous résoudre ce problème ? Ne s'agit-il pas d'une dépendance de pipeline rétrograde, c'est-à-dire du même problème que des projets tels que Composite After Paint ont résolu ? Pire encore, que se passe-t-il si les nouveaux styles modifient la taille de l'ancêtre ? Cela ne risque-t-il pas de créer une boucle infinie ?
En principe, la dépendance circulaire peut être résolue à l'aide de la propriété CSS contain, qui permet au rendu en dehors d'un élément de ne pas dépendre du rendu dans le sous-arbre de cet élément. Cela signifie que les nouveaux styles appliqués par un conteneur ne peuvent pas affecter sa taille, car les requêtes de conteneur nécessitent un structuration.
Mais ce n'était pas suffisant. Il a fallu introduire un type de structuration plus faible que la structuration par taille. En effet, il est courant de vouloir que le conteneur de requêtes de conteneur ne puisse se redimensionner que dans une seule direction (généralement un bloc) en fonction de ses dimensions intégrées. C'est pourquoi le concept de confinement de taille intégrée a été ajouté. Toutefois, comme vous pouvez le constater dans la très longue note de cette section, il n'a pas été clair pendant longtemps si la structuration de la taille en ligne était possible.
Il est une chose de décrire la structuration dans un langage de spécification abstrait, et une autre de l'implémenter correctement. Rappelons qu'un des objectifs de BlinkNG était d'appliquer le principe de structuration aux parcours d'arbre qui constituent la logique principale du rendu: lors de la traversée d'un sous-arbre, aucune information ne doit être requise en dehors du sous-arbre. Il se trouve (ce n'est pas tout à fait un hasard) qu'il est beaucoup plus simple et plus propre d'implémenter la structuration CSS si le code de rendu respecte le principe de structuration.
À venir: composition hors thread principal… et plus encore !
Le pipeline de rendu présenté ici est en réalité un peu en avance sur l'implémentation actuelle de RenderingNG. Il indique que la stratification est désactivée sur le thread principal, alors qu'elle est toujours activée. Toutefois, ce n'est qu'une question de temps, maintenant que Composite After Paint est disponible et que la stratification est effectuée après la peinture.
Pour comprendre pourquoi cela est important et où cela peut mener, nous devons examiner l'architecture du moteur de rendu d'un point de vue un peu plus élevé. L'un des obstacles les plus durables à l'amélioration des performances de Chromium est le fait simple que le thread principal du moteur de rendu gère à la fois la logique principale de l'application (c'est-à-dire l'exécution du script) et la majeure partie du rendu. Par conséquent, le thread principal est souvent saturé de travail, et la congestion du thread principal est souvent le goulot d'étranglement de l'ensemble du navigateur.
La bonne nouvelle est que ce n'est pas forcément le cas. Cet aspect de l'architecture de Chromium remonte aux débuts de KHTML, lorsque l'exécution monothread était le modèle de programmation dominant. Lorsque les processeurs multicœurs sont devenus courants sur les appareils grand public, l'hypothèse monothread était bien intégrée à Blink (anciennement WebKit). Nous voulions depuis longtemps introduire davantage de threads dans le moteur de rendu, mais c'était tout simplement impossible dans l'ancien système. L'un des principaux objectifs de Rendering NG était de nous sortir de ce gouffre et de permettre de déplacer le travail de rendu, en partie ou en totalité, vers un ou plusieurs autres threads.
Maintenant que BlinkNG est presque terminé, nous commençons à explorer ce domaine. Le commit non bloquant est une première tentative de modification du modèle de threads du moteur de rendu. Le commit du moteur de rendu (ou simplement commit) est une étape de synchronisation entre le thread principal et le thread du moteur de rendu. Lors du commit, nous créons des copies des données de rendu produites sur le thread principal, qui seront utilisées par le code de composition en aval exécuté sur le thread du compositeur. Pendant cette synchronisation, l'exécution du thread principal est arrêtée, tandis que le code de copie s'exécute sur le thread du moteur de rendu. Cela permet de s'assurer que le thread principal ne modifie pas ses données de rendu pendant que le thread du moteur de rendu les copie.
Le commit non bloquant élimine le besoin d'arrêter le thread principal et d'attendre la fin de la phase de commit. Le thread principal continue de travailler pendant que le commit s'exécute simultanément sur le thread du moteur de rendu. L'effet net du commit non bloquant sera une réduction du temps consacré au travail de rendu sur le thread principal, ce qui réduira la congestion sur le thread principal et améliorera les performances. Au moment de la rédaction de cet article (mars 2022), nous disposons d'un prototype fonctionnel du commit non bloquant et nous nous préparons à effectuer une analyse détaillée de son impact sur les performances.
La composition hors thread principal est en attente. Son objectif est de faire correspondre le moteur de rendu à l'illustration en déplaçant la mise en couches du thread principal vers un thread de travail. Comme pour le commit non bloquant, cela réduit la congestion sur le thread principal en diminuant sa charge de rendu. Un projet comme celui-ci n'aurait jamais été possible sans les améliorations architecturales de Composite After Paint.
D'autres projets sont en cours (jeu de mots intentionnel) ! Nous disposons enfin d'une base qui permet de tester la redistribution du travail de rendu, et nous sommes impatients de voir ce que nous pouvons faire !