



Published: May 16, 2024
Positive and negative reviews can inform a buyer's purchase decision.
According to external research, 82% of online shoppers actively seek negative reviews before making a purchase. These negative reviews are useful for customers and to businesses, as the availability of negative reviews can help reduce return rates and help makers improve their products.
Here are a few ways you could improve the review quality:
- Check each review for toxicity before it's submitted. We could encourage
users to remove offensive language, as well as other unhelpful remarks, so that
their review best helps other users make a better purchase decision.
- Negative: This bag sucks, and I hate it.
- Negative with useful feedback The zippers are very stiff and the material feels cheap. I returned this bag.
- Auto-generate a rating based on the language used in the review.
- Determine if the review is negative or positive.
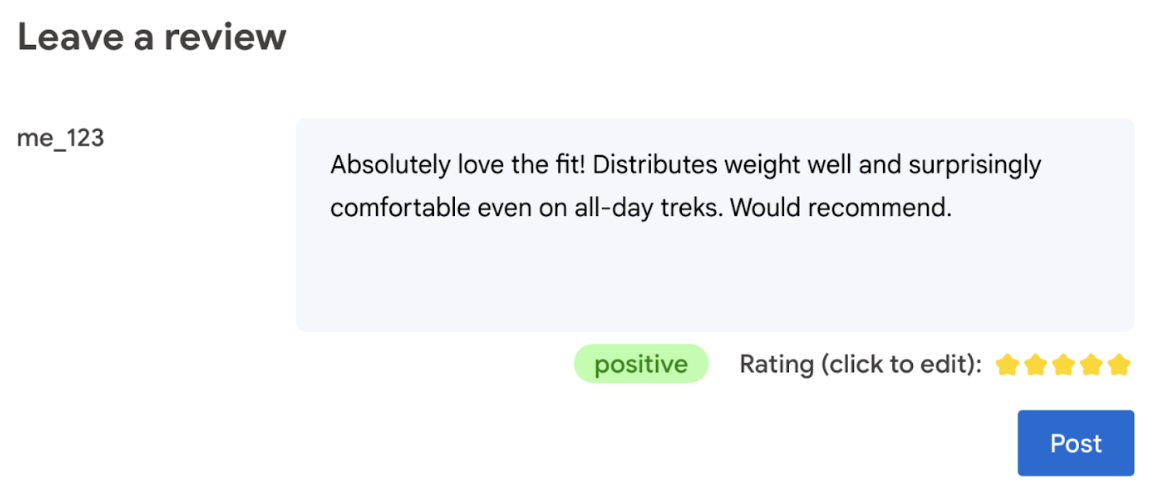
Ultimately, the user should have the final word on the product rating.
The following codelab offers client-side solutions, on-device and in the browser. No AI development knowledge, servers, or API keys required.
Prerequisites
While server-side AI with solutions (such as the Gemini API or OpenAI API) offer robust solutions for many applications, in this guide we focus on client-side web AI. Client-side AI inference occurs in the browser, to improve the experience for web users by removing server round trips.
In this codelab, we use a mix of techniques to show you what's in your toolbox for client-side AI.
We use the following libraries and models:
- TensforFlow.js for toxicity analysis. TensorFlow.js is an open source machine learning library for both inference and training on the web.
- transformers.js for sentiment analysis. Transformers.js is a web AI library from Hugging Face.
- Gemma 2B for star ratings. Gemma is a family of lightweight, open models built from the research and technology that Google used to create the Gemini models. To run Gemma in the browser, we use it with MediaPipe's experimental LLM Inference API.
UX and safety considerations
There are a few considerations to ensure optimal user experience and safety:
- Allow the user to edit the rating. Ultimately, the user should have the final word on the product rating.
- Make it clear to the user that the rating and reviews are automated.
- Allow users to post a review classified as toxic, but run a second check on the server. This prevents a frustrating experience where a non-toxic review is mistakenly classified as toxic (a false positive). This also covers cases where a malicious user manages to bypass the client-side check.
- A client-side toxicity check is helpful, but it can be bypassed. Ensure you run a check server-side as well.
Analyze toxicity with TensorFlow.js
It's quick to start analyzing toxicity of a user review with TensorFlow.js.
- Install and import the TensorFlow.js library and toxicity model.
- Set a minimum prediction confidence. The default is 0.85, and in our example, we've set it to 0.9.
- Load the model asynchronously.
- Classify the review asynchronously. Our code identifies predictions exceeding a threshold of 0.9 for any category.
This model can categorize toxicity across identity attack, insult, obscenity, and more.
For example:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Determine sentiment with Transformers.js
Install and import the Transformers.js library.
Set up the sentiment analysis task with a dedicated pipeline. When a pipeline is used for the first time, the model is downloaded and cached. From then on, sentiment analysis should be much faster.
Classify the review asynchronously. Use a custom threshold to set the level of confidence which you consider usable for your application.
For example:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Suggest a star rating with Gemma and MediaPipe
With the LLM Inference API, you can run large language models (LLMs) completely in the browser.
This new capability is particularly transformative considering the memory and compute demands of LLMs, which are over a hundred times larger than client-side models. Optimizations across the web stack make this possible, including new ops, quantization, caching, and weight sharing. Source: "Large Language Models On-Device with MediaPipe and TensorFlow Lite".
- Install and import the MediaPipe LLM inference API.
- Download a model. Here, we use Gemma 2B, downloaded from Kaggle. Gemma 2B is the smallest of Google's open-weight models.
- Point the code to the right model files, with the
FilesetResolver. This is important because generative AI models may have a specific directory structure for their assets. - Load and configure the model with MediaPipe's LLM interface. Prepare the model for use: specify its model location, preferred length of responses, and preferred level of creativity with the temperature.
- Give the model a prompt (see an example).
- Await the model's response.
- Parse for the rating: Extract the star rating from the model's response.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Example prompt
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Takeaways
No AI/ML expertise is required. Designing a prompt requires iterations, but the rest of the code is standard web development.
Client-side models are fairly accurate. If you run the snippets from this document, you'll observe that both the toxicity and sentiment analysis give accurate results. The Gemma ratings, for the most part, matched the Gemini model ratings for a few tested reference reviews. In order to validate that accuracy, more testing is required.
That said, designing the prompt for Gemma 2B takes work. Because Gemma 2B is a small LLM, it needs a detailed prompt to produce satisfying results—notably more detailed than what's required with the Gemini API.
Inference can be lightning fast. If you run the snippets from this document, you should observe that inference can get fast, potentially faster than server round trips, on a number of devices. That said, inference speed can vary greatly. Thorough benchmarking on target devices is needed. We expect browser inference to keep getting faster with WebGPU, WebAssembly, and library updates. For example, Transformers.js adds Web GPU support in v3, which can speed up on-device inference manyfold.
Download sizes can be very large. Inference in the browser is fast, but loading AI models can be a challenge. To perform in-browser AI, you typically need both a library and a model, which add to your web app's download size.
While the Tensorflow toxicity model (a classic natural language processing model) is only a few kilobytes, generative AI models like Transformers.js's default sentiment analysis model reaches 60MB. Large language models like Gemma can be as large as 1.3GB. This exceeds the median 2.2 mb web page size, which is already much larger than recommended for best performance, by far. Client-side generative AI is viable in specific scenarios.
The field of generative AI on the web is rapidly evolving! Smaller, web-optimized models are expected to emerge in the future.
Next steps
Chrome is experimenting with another way to run generative AI in the browser. You can sign up for the Early Preview Program to test it.