



Publicado em: 16 de maio de 2024
As avaliações positivas e negativas podem influenciar a decisão de compra de um comprador.
De acordo com uma pesquisa externa, 82% dos compradores on-line procuram ativamente avaliações negativas antes de fazer uma compra. Essas avaliações negativas são úteis para clientes e empresas, já que a disponibilidade delas pode ajudar a reduzir as taxas de devolução e melhorar os produtos.
Confira algumas maneiras de melhorar a qualidade das avaliações:
- Verifique cada avaliação quanto à toxicidade antes do envio. Podemos incentivar os usuários a remover linguagem ofensiva e outras observações inúteis para que a avaliação ajude outros usuários a tomar uma decisão de compra melhor.
- Negativa: essa bolsa é horrível, não gostei dela.
- Negativo com feedback útil Os zíperes são muito rígidos e o material parece barato. Devolvi esta bolsa.
- Gerar automaticamente uma classificação com base no idioma usado na avaliação.
- Determine se a avaliação é negativa ou positiva.
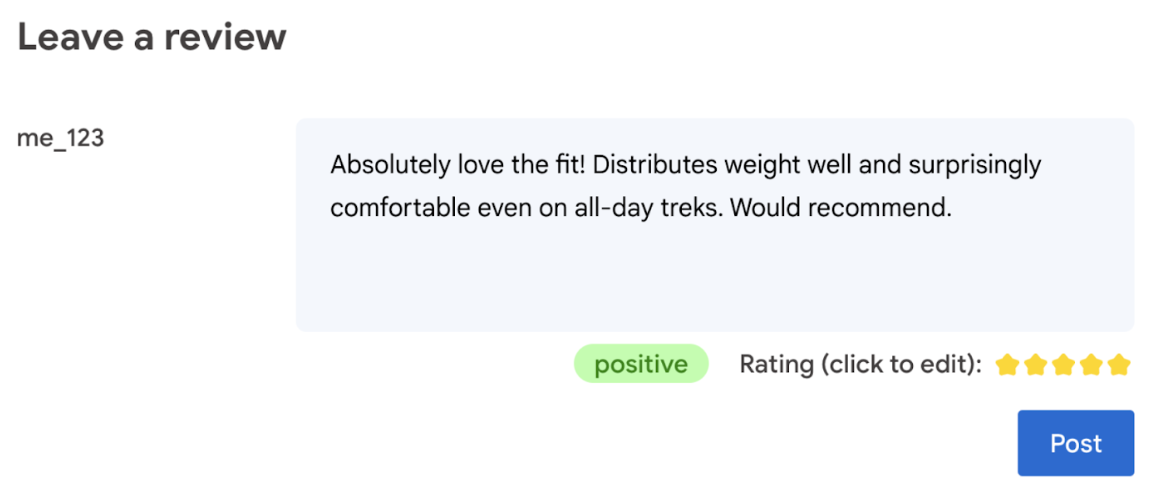
Em última análise, o usuário deve ter a palavra final sobre a classificação do produto.
O codelab a seguir oferece soluções do lado do cliente, no dispositivo e no navegador. Não é necessário ter conhecimento de desenvolvimento de IA, servidores ou chaves de API.
Pré-requisitos
Embora a IA do lado do servidor com soluções (como a API Gemini ou a API OpenAI) ofereça soluções robustas para muitos aplicativos, neste guia, vamos nos concentrar na IA da Web do lado do cliente. A inferência de IA do lado do cliente ocorre no navegador para melhorar a experiência dos usuários da Web removendo as viagens de ida e volta do servidor.
Neste codelab, usamos uma combinação de técnicas para mostrar o que está na sua caixa de ferramentas para IA do lado do cliente.
Usamos as seguintes bibliotecas e modelos:
- TensforFlow.js para análise de toxicidade. O TensorFlow.js é uma biblioteca de machine learning de código aberto para inferência e treinamento na Web.
- transformers.js para análise de sentimentos. O Transformers.js é uma biblioteca de IA da Web do Hugging Face.
- Gemma 2B para notas com estrelas. O Gemma é uma família de modelos abertos e leves criados com base na pesquisa e na tecnologia que o Google usou para criar os modelos do Gemini. Para executar o Gemma no navegador, usamos o modelo com a API experimental de inferência de LLM do MediaPipe.
Considerações sobre UX e segurança
Há algumas considerações para garantir a melhor experiência e segurança do usuário:
- Permitir que o usuário edite a classificação. Em última análise, o usuário deve ter a palavra final sobre a classificação do produto.
- Deixe claro para o usuário que a classificação e as avaliações são automáticas.
- Permita que os usuários postem uma avaliação classificada como tóxica, mas faça uma segunda verificação no servidor. Isso evita uma experiência frustrante em que uma avaliação não tóxica é classificada por engano como tóxica (um falso positivo). Isso também inclui casos em que um usuário malicioso consegue burlar a verificação do lado do cliente.
- Uma verificação de toxicidade do lado do cliente é útil, mas pode ser ignorada. Faça uma verificação do lado do servidor também.
Analisar a toxicidade com o TensorFlow.js
É rápido começar a analisar a toxicidade de uma avaliação do usuário com o TensorFlow.js.
- Instale e importe a biblioteca do TensorFlow.js e o modelo de toxicidade.
- Defina uma confiança mínima de previsão. O padrão é 0,85, e no nosso exemplo, definimos como 0,9.
- Carregue o modelo de maneira assíncrona.
- Classifique a avaliação de forma assíncrona. Nosso código identifica previsões que excedem um limite de 0,9 para qualquer categoria.
Esse modelo pode categorizar a toxicidade em ataques à identidade, insultos, obscenidades e muito mais.
Exemplo:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Determinar o sentimento com o Transformers.js
Instale e importe a biblioteca Transformers.js.
Configure a tarefa de análise de sentimento com um pipeline dedicado. Quando um pipeline é usado pela primeira vez, o modelo é baixado e armazenado em cache. A partir daí, a análise de sentimentos será muito mais rápida.
Classifique a avaliação de forma assíncrona. Use um limite personalizado para definir o nível de confiança que você considera utilizável para seu aplicativo.
Exemplo:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Sugerir uma classificação por estrelas com o Gemma e o MediaPipe
Com a API LLM Inference, é possível executar modelos de linguagem grandes (LLMs) completamente no navegador.
Essa nova capacidade é especialmente transformadora considerando as demandas de memória e computação dos LLMs, que são mais de cem vezes maiores que os modelos do lado do cliente. As otimizações em toda a pilha da Web tornam isso possível, incluindo novas operações, quantização, armazenamento em cache e compartilhamento de ponderações. Fonte: "Modelos de linguagem grandes no dispositivo com MediaPipe e TensorFlow Lite".
- Instale e importe a API MediaPipe LLM Inference.
- Baixe um modelo. Aqui, usamos o Gemma 2B, baixado do Kaggle. O Gemma 2B é o menor dos modelos de peso aberto do Google.
- Aponte o código para os arquivos de modelo certos com o
FilesetResolver. Isso é importante porque os modelos de IA generativa podem ter uma estrutura de diretório específica para os recursos. - Carregue e configure o modelo com a interface LLM do MediaPipe. Prepare o modelo para uso: especifique a localização, o tamanho preferido das respostas e o nível de criatividade com a temperatura.
- Dê um comando ao modelo (veja um exemplo).
- Aguarde a resposta do modelo.
- Analise a classificação: extraia a classificação por estrelas da resposta do modelo.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Exemplo de comando
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Aprendizados
Não é necessário ter experiência em IA/ML. Criar um comando requer iterações, mas o restante do código é desenvolvimento web padrão.
Os modelos do lado do cliente são bastante precisos. Se você executar os snippets deste documento, vai notar que as análises de toxicidade e sentimento fornecem resultados precisos. As classificações do Gemma, na maior parte, corresponderam às do modelo do Gemini para algumas avaliações de referência testadas. Para validar essa precisão, mais testes são necessários.
No entanto, criar o comando para o Gemma 2B exige trabalho. Como o Gemma 2B é um LLM pequeno, ele precisa de um comando detalhado para produzir resultados satisfatórios, principalmente mais detalhados do que o necessário com a API Gemini.
A inferência pode ser muito rápida. Se você executar os snippets deste documento, vai observar que a inferência pode ser rápida, possivelmente mais rápida do que as viagens de ida e volta do servidor, em vários dispositivos. No entanto, a velocidade de inferência pode variar muito. É necessário fazer um comparativo detalhado nos dispositivos de destino. Esperamos que a inferência do navegador fique cada vez mais rápida com o WebGPU, o WebAssembly e as atualizações de biblioteca. Por exemplo, o Transformers.js adiciona suporte à Web GPU na v3, que pode acelerar a inferência no dispositivo várias vezes.
Os tamanhos de download podem ser muito grandes. A inferência no navegador é rápida, mas carregar modelos de IA pode ser um desafio. Para realizar a IA no navegador, geralmente é necessário uma biblioteca e um modelo, o que aumenta o tamanho do download do seu web app.
Enquanto o modelo de toxicidade do TensorFlow (um modelo clássico de processamento de linguagem natural) tem apenas alguns kilobytes, os modelos de IA generativa, como o modelo de análise de sentimento padrão do Transformers.js, chegam a 60 MB. Modelos de linguagem grandes, como o Gemma, podem ter até 1,3 GB. Isso excede a mediana de 2, 2 MB de tamanho de página da Web, que já é muito maior do que o recomendado para uma performance ideal. A IA generativa do lado do cliente é viável em cenários específicos.
O campo da IA generativa na Web está evoluindo rapidamente. Espera-se que modelos menores e otimizados para a Web surjam no futuro.
Próximas etapas
O Chrome está testando outra maneira de executar a IA generativa no navegador. Inscreva-se no Programa de pré-lançamento para testar.