



Opublikowano: 16 maja 2024 r.
Opinie pozytywne i negatywne mogą wpływać na decyzję kupującego.
Z badań zewnętrznych wynika, że 82% kupujących online aktywnie szuka negatywnych opinii przed dokonaniem zakupu. Te negatywne opinie są przydatne dla klientów i firm, ponieważ ich dostępność może pomóc zmniejszyć odsetek zwrotów i ulepszyć produkty.
Oto kilka sposobów na poprawę jakości opinii:
- Sprawdzaj każdą opinię pod kątem toksyczności przed jej przesłaniem. Możemy zachęcać użytkowników do usuwania obraźliwych sformułowań i innych nieprzydatnych uwag, aby ich opinie jak najlepiej pomagały innym użytkownikom w podjęciu decyzji o zakupie.
- Negatywna: ta torba jest beznadziejna, nie znoszę jej.
- Negatywna z przydatną opinią Zamki są bardzo sztywne, a materiał wydaje się tani. Zwróciłem(-am) tę torbę.
- automatycznie generować ocenę na podstawie języka użytego w opinii;
- Określ, czy opinia jest negatywna czy pozytywna.
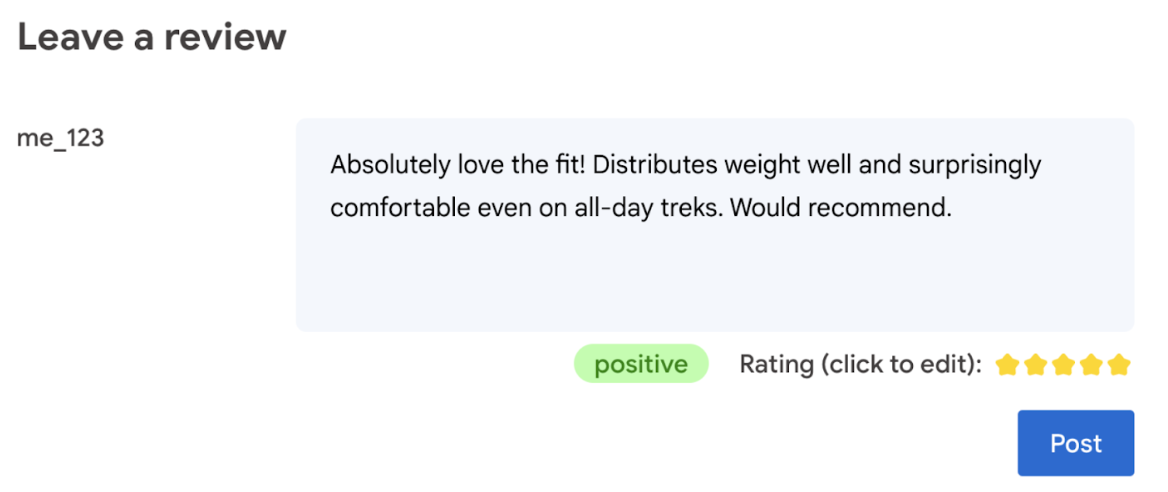
Ostatecznie to użytkownik powinien mieć ostatnie słowo w sprawie oceny produktu.
W tym ćwiczeniu znajdziesz rozwiązania po stronie klienta, na urządzeniu i w przeglądarce. Nie wymaga wiedzy na temat tworzenia AI, serwerów ani kluczy interfejsu API.
Wymagania wstępne
Sztuczna inteligencja po stronie serwera z rozwiązaniami takimi jak Gemini API czy OpenAI API oferuje solidne rozwiązania dla wielu aplikacji, ale w tym przewodniku skupimy się na sztucznej inteligencji po stronie klienta w internecie. Wnioskowanie AI po stronie klienta odbywa się w przeglądarce, co zwiększa wygodę użytkowników internetu, ponieważ eliminuje konieczność wysyłania zapytań do serwera.
W tym laboratorium kodowania używamy różnych technik, aby pokazać, jakie narzędzia masz do dyspozycji w przypadku AI po stronie klienta.
Korzystamy z tych bibliotek i modeli:
- TensforFlow.js do analizy toksyczności. TensorFlow.js to biblioteka open source do uczenia maszynowego, która umożliwia wnioskowanie i trenowanie w internecie.
- transformers.js do analizy sentymentu. Transformers.js to biblioteka AI do internetu od Hugging Face.
- Gemma 2B w przypadku ocen gwiazdkowych. Gemma to rodzina lekkich, otwartych modeli opartych na badaniach i technologii, których Google używało do tworzenia modeli Gemini. Aby uruchomić Gemmę w przeglądarce, używamy jej z eksperymentalnym interfejsem LLM Inference API MediaPipe.
Względy dotyczące wygody użytkownika i bezpieczeństwa
Aby zapewnić optymalne wrażenia użytkownika i bezpieczeństwo, należy wziąć pod uwagę kilka kwestii:
- Zezwalaj użytkownikom na edytowanie oceny. Ostatecznie to użytkownik powinien mieć ostatnie słowo w sprawie oceny produktu.
- Wyraźnie poinformuj użytkownika, że ocena i opinie są automatyczne.
- Zezwalaj użytkownikom na publikowanie opinii zaklasyfikowanych jako toksyczne, ale przeprowadzaj drugie sprawdzenie na serwerze. Zapobiega to frustrującej sytuacji, w której nieszkodliwa opinia jest błędnie klasyfikowana jako szkodliwa (fałszywie pozytywna). Dotyczy to również sytuacji, w których złośliwemu użytkownikowi uda się obejść weryfikację po stronie klienta.
- Sprawdzanie toksyczności po stronie klienta jest przydatne, ale można je obejść. Pamiętaj, aby sprawdzić też serwer.
Analizowanie toksyczności za pomocą TensorFlow.js
Szybko rozpoczniesz analizowanie toksyczności opinii użytkowników za pomocą TensorFlow.js.
- Zainstaluj i zaimportuj bibliotekę TensorFlow.js i model toksyczności.
- Ustaw minimalny poziom ufności prognozy. Wartość domyślna to 0,85, a w naszym przykładzie ustawiliśmy ją na 0,9.
- Załaduj model asynchronicznie.
- asynchroniczne klasyfikowanie opinii; Nasz kod identyfikuje prognozy przekraczające próg 0,9 w dowolnej kategorii.
Ten model może kategoryzować toksyczność w zakresie ataków na tożsamość, zniewag, wulgaryzmów i innych.
Na przykład:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Określanie sentymentu za pomocą Transformers.js
Zainstaluj i zaimportuj bibliotekę Transformers.js.
Skonfiguruj zadanie analizy sentymentu za pomocą specjalnego potoku. Gdy potok jest używany po raz pierwszy, model jest pobierany i zapisywany w pamięci podręcznej. Od tego momentu analiza nastawienia powinna przebiegać znacznie szybciej.
asynchroniczne klasyfikowanie opinii; Użyj niestandardowego progu, aby ustawić poziom ufności, który uważasz za przydatny w swojej aplikacji.
Na przykład:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Sugerowanie oceny za pomocą modeli Gemma i MediaPipe
Interfejs LLM Inference API umożliwia uruchamianie dużych modeli językowych (LLM) w całości w przeglądarce.
Ta nowa funkcja jest szczególnie przełomowa, biorąc pod uwagę wymagania LLM dotyczące pamięci i mocy obliczeniowej, które są ponad 100 razy większe niż w przypadku modeli po stronie klienta. Umożliwiają to optymalizacje w całym stosie internetowym, w tym nowe operacje, kwantyzacja, buforowanie i udostępnianie wag. Źródło: „Large Language Models On-Device with MediaPipe and TensorFlow Lite”
- Zainstaluj i zaimportuj interfejs MediaPipe LLM Inference API.
- Pobierz model. W tym przykładzie używamy modelu Gemma 2B pobranego z Kaggle. Gemma 2B to najmniejszy z otwartych modeli Google.
- Skieruj kod na właściwe pliki modelu za pomocą
FilesetResolver. Jest to ważne, ponieważ modele generatywnej AI mogą mieć określoną strukturę katalogów zasobów. - Załaduj i skonfiguruj model za pomocą interfejsu LLM MediaPipe. Przygotuj model do użycia: określ jego lokalizację, preferowaną długość odpowiedzi i preferowany poziom kreatywności za pomocą temperatury.
- Wpisz prompta (zobacz przykład).
- Poczekaj na odpowiedź modelu.
- Analizowanie oceny: wyodrębnij ocenę w gwiazdkach z odpowiedzi modelu.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
Przykładowy prompt
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
Wnioski
Nie jest wymagana specjalistyczna wiedza z zakresu AI/ML. Projektowanie prompta wymaga iteracji, ale reszta kodu to standardowe programowanie internetowe.
Modele po stronie klienta są dość dokładne. Jeśli uruchomisz fragmenty kodu z tego dokumentu, zobaczysz, że zarówno analiza toksyczności, jak i analiza sentymentu dają dokładne wyniki. Oceny Gemmy w większości przypadków były zgodne z ocenami modelu Gemini w przypadku kilku testowanych opinii referencyjnych. Aby potwierdzić tę dokładność, konieczne są dalsze testy.
Opracowanie promptu dla modelu Gemma 2B wymaga jednak pracy. Gemma 2B to mały model LLM, dlatego potrzebuje szczegółowego prompta, aby uzyskać zadowalające wyniki – znacznie bardziej szczegółowego niż w przypadku interfejsu Gemini API.
Wnioskowanie może być błyskawiczne. Jeśli uruchomisz fragmenty kodu z tego dokumentu, zauważysz, że wnioskowanie może być szybkie, a na niektórych urządzeniach nawet szybsze niż komunikacja z serwerem. Szybkość wnioskowania może się jednak znacznie różnić. Konieczne jest dokładne testowanie porównawcze na urządzeniach docelowych. Spodziewamy się, że wnioskowanie w przeglądarce będzie coraz szybsze dzięki WebGPU, WebAssembly i aktualizacjom bibliotek. Na przykład biblioteka Transformers.js dodaje obsługę WebGPU w wersji 3, co może wielokrotnie przyspieszyć wnioskowanie na urządzeniu.
Rozmiary pobieranych plików mogą być bardzo duże. Wnioskowanie w przeglądarce jest szybkie, ale wczytywanie modeli AI może być trudne. Aby korzystać ze sztucznej inteligencji w przeglądarce, zwykle potrzebujesz biblioteki i modelu, co zwiększa rozmiar pobierania aplikacji internetowej.
Model toksyczności TensorFlow (klasyczny model przetwarzania języka naturalnego) zajmuje tylko kilka kilobajtów, a modele generatywnej AI, takie jak domyślny model analizy nastawienia Transformers.js, osiągają rozmiar 60 MB. Duże modele językowe, takie jak Gemma, mogą mieć nawet 1,3 GB. Jest to znacznie więcej niż mediana rozmiaru strony internetowej wynosząca 2, 2 MB, która jest już znacznie większa niż zalecana w celu uzyskania optymalnej wydajności. Generatywna AI po stronie klienta jest przydatna w określonych sytuacjach.
Obszar generatywnej AI w internecie szybko się rozwija. W przyszłości mają się pojawić mniejsze modele zoptymalizowane pod kątem internetu.
Dalsze kroki
Chrome eksperymentuje z innym sposobem uruchamiania generatywnej AI w przeglądarce. Aby ją przetestować, możesz zarejestrować się w Programie wcześniejszego dostępu.