



पब्लिश होने की तारीख: 16 मई, 2024
सकारात्मक और नकारात्मक समीक्षाओं से, खरीदार को खरीदारी का फ़ैसला लेने में मदद मिल सकती है.
बाहरी रिसर्च के मुताबिक, ऑनलाइन खरीदारी करने वाले 82% लोग, खरीदारी करने से पहले खराब समीक्षाएं देखते हैं. ये नकारात्मक समीक्षाएं, खरीदारों और कारोबारों के लिए फ़ायदेमंद होती हैं. नकारात्मक समीक्षाएं उपलब्ध होने से, खरीदारों को प्रॉडक्ट लौटाने की दर कम करने में मदद मिलती है. साथ ही, इससे मैन्युफ़ैक्चरर को अपने प्रॉडक्ट बेहतर बनाने में मदद मिलती है.
समीक्षा की क्वालिटी को बेहतर बनाने के लिए, यहां कुछ तरीके दिए गए हैं:
- समीक्षा सबमिट करने से पहले, उसकी जांच करें कि उसमें आपत्तिजनक कॉन्टेंट तो नहीं है. हम लोगों को आपत्तिजनक भाषा और अन्य काम की नहीं टिप्पणियां हटाने के लिए प्रोत्साहित कर सकते हैं, ताकि उनकी समीक्षा से अन्य लोगों को खरीदारी का बेहतर फ़ैसला लेने में मदद मिल सके.
- नकारात्मक: यह बैग बहुत खराब है और मुझे यह बिल्कुल पसंद नहीं है.
- काम के सुझावों के साथ खराब रेटिंग ज़िप बहुत टाइट हैं और मटीरियल घटिया लगता है. मैंने यह बैग वापस कर दिया है.
- समीक्षा में इस्तेमाल की गई भाषा के आधार पर, रेटिंग अपने-आप जनरेट होती है.
- यह तय करना कि समीक्षा नकारात्मक है या सकारात्मक.
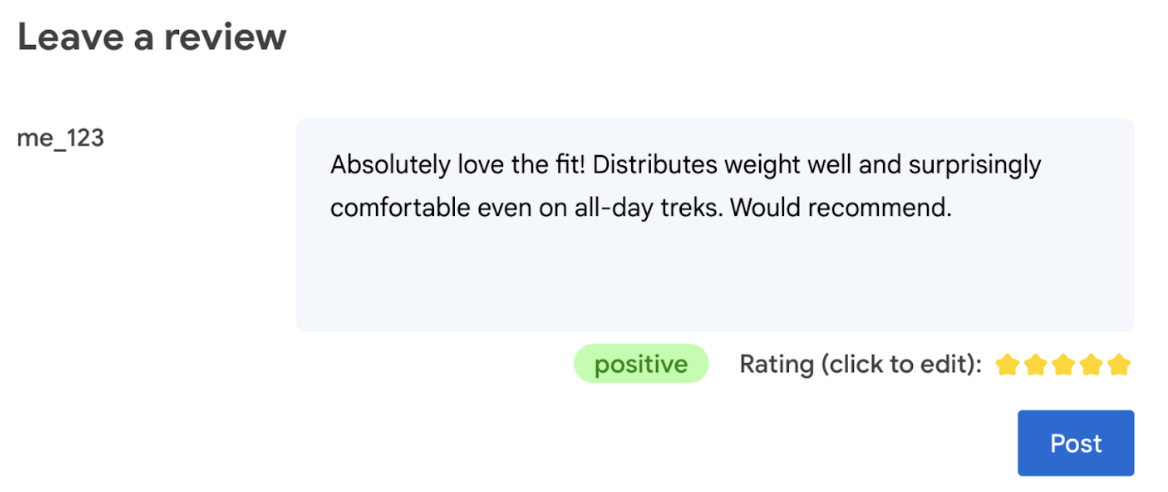
आखिरकार, प्रॉडक्ट की रेटिंग के बारे में फ़ैसला लेने का अधिकार उपयोगकर्ता के पास होना चाहिए.
इस कोडलैब में, क्लाइंट-साइड के समाधान दिए गए हैं. ये समाधान, डिवाइस पर और ब्राउज़र में काम करते हैं. इसके लिए, एआई डेवलपमेंट, सर्वर या एपीआई पासकोड के बारे में जानकारी होना ज़रूरी नहीं है.
ज़रूरी शर्तें
सर्वर-साइड एआई के साथ समाधान (जैसे कि Gemini API या OpenAI API) कई ऐप्लिकेशन के लिए बेहतर समाधान उपलब्ध कराते हैं. हालांकि, इस गाइड में हम क्लाइंट-साइड वेब एआई पर फ़ोकस करेंगे. क्लाइंट-साइड पर एआई इन्फ़्रेंस ब्राउज़र में होता है. इससे वेब उपयोगकर्ताओं को बेहतर अनुभव मिलता है, क्योंकि सर्वर राउंड ट्रिप नहीं होती.
इस कोडलैब में, हम क्लाइंट-साइड एआई के लिए, आपके टूलबॉक्स में मौजूद चीज़ों को दिखाने के लिए अलग-अलग तकनीकों का इस्तेमाल करते हैं.
हम इन लाइब्रेरी और मॉडल का इस्तेमाल करते हैं:
- ज़हरीले कॉन्टेंट का विश्लेषण करने के लिए, TensforFlow.js का इस्तेमाल किया जाता है. TensorFlow.js, एक ओपन सोर्स मशीन लर्निंग लाइब्रेरी है. इसका इस्तेमाल वेब पर अनुमान लगाने और ट्रेनिंग देने, दोनों के लिए किया जा सकता है.
- भावनाओं का विश्लेषण करने के लिए, transformers.js. Transformers.js, Hugging Face की वेब एआई लाइब्रेरी है.
- स्टार रेटिंग के लिए, Gemma 2B का इस्तेमाल किया जाता है. Gemma, लाइटवेट और ओपन मॉडल है. इसे Google ने Gemini मॉडल में इस्तेमाल की गई रिसर्च और टेक्नोलॉजी का इस्तेमाल करके बनाया है. ब्राउज़र में Gemma को चलाने के लिए, हम इसे MediaPipe के एलएलएम इन्फ़रेंस एपीआई के एक्सपेरिमेंटल वर्शन के साथ इस्तेमाल करते हैं.
यूज़र एक्सपीरियंस और सुरक्षा से जुड़ी बातें
उपयोगकर्ताओं को बेहतर अनुभव और सुरक्षा देने के लिए, इन बातों का ध्यान रखें:
- उपयोगकर्ता को रेटिंग में बदलाव करने की अनुमति दें. आखिरकार, प्रॉडक्ट की रेटिंग के बारे में फ़ैसला लेने का अधिकार उपयोगकर्ता के पास होना चाहिए.
- उपयोगकर्ता को साफ़ तौर पर बताएं कि रेटिंग और समीक्षाएं अपने-आप जनरेट होती हैं.
- उपयोगकर्ताओं को ऐसी समीक्षा पोस्ट करने की अनुमति दें जिसे आपत्तिजनक के तौर पर क्लासिफ़ाई किया गया है. हालांकि, सर्वर पर इसकी दोबारा जांच करें. इससे लोगों को इस समस्या से बचने में मदद मिलती है कि किसी ऐसे रिव्यू को गलत तरीके से आपत्तिजनक के तौर पर क्लासिफ़ाई किया गया हो जो आपत्तिजनक नहीं है. इसे फ़ॉल्स पॉज़िटिव कहा जाता है. इसमें ऐसे मामले भी शामिल हैं जिनमें नुकसान पहुंचाने वाला कोई व्यक्ति, क्लाइंट-साइड की जांच को बायपास कर देता है.
- क्लाइंट-साइड पर आपत्तिजनक कॉन्टेंट की जांच करना मददगार होता है. हालांकि, इसे बायपास किया जा सकता है. पक्का करें कि आपने सर्वर-साइड पर भी जांच की हो.
TensorFlow.js की मदद से टॉक्सिसिटी का विश्लेषण करना
TensorFlow.js की मदद से, किसी उपयोगकर्ता की समीक्षा में आपत्तिजनक कॉन्टेंट का विश्लेषण तुरंत किया जा सकता है.
- TensorFlow.js लाइब्रेरी और टॉक्सिसिटी मॉडल को इंस्टॉल करें और इंपोर्ट करें.
- कम से कम अनुमानित कॉन्फ़िडेंस सेट करें. डिफ़ॉल्ट वैल्यू 0.85 होती है. इस उदाहरण में, हमने इसे 0.9 पर सेट किया है.
- मॉडल को एसिंक्रोनस तरीके से लोड करें.
- समीक्षा को एसिंक्रोनस तरीके से कैटगरी में बांटता है. हमारा कोड, किसी भी कैटगरी के लिए 0.9 से ज़्यादा थ्रेशोल्ड वाली अनुमानित वैल्यू की पहचान करता है.
यह मॉडल, पहचान पर हमला करने, अपमान करने, अश्लीलता दिखाने वगैरह के आधार पर, आपत्तिजनक कॉन्टेंट को अलग-अलग कैटगरी में बांट सकता है.
उदाहरण के लिए:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
Transformers.js की मदद से भावना का पता लगाना
Transformers.js लाइब्रेरी को इंस्टॉल करें और इंपोर्ट करें.
भावनाओं का विश्लेषण करने वाला टास्क, एक खास पाइपलाइन की मदद से सेट अप करें. जब किसी पाइपलाइन का पहली बार इस्तेमाल किया जाता है, तो मॉडल डाउनलोड हो जाता है और कैश मेमोरी में सेव हो जाता है. इसके बाद, भावनाओं का विश्लेषण बहुत तेज़ी से किया जा सकेगा.
समीक्षा को एसिंक्रोनस तरीके से कैटगरी में बांटता है. कस्टम थ्रेशोल्ड का इस्तेमाल करके, कॉन्फ़िडेंस का वह लेवल सेट करें जिसे आपको अपने ऐप्लिकेशन के लिए इस्तेमाल करना है.
उदाहरण के लिए:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
Gemma और MediaPipe की मदद से स्टार रेटिंग का सुझाव पाना
एलएलएम इन्फ़रेंस एपीआई की मदद से, लार्ज लैंग्वेज मॉडल (एलएलएम) को पूरी तरह से ब्राउज़र में चलाया जा सकता है.
यह नई सुविधा, एलएलएम की मेमोरी और कंप्यूटिंग की ज़रूरतों को पूरा करने के लिए खास तौर पर मददगार है. एलएलएम की ज़रूरतें, क्लाइंट-साइड मॉडल की तुलना में सौ गुना से भी ज़्यादा होती हैं. वेब स्टैक में किए गए ऑप्टिमाइज़ेशन की वजह से ऐसा हो पाता है. इनमें नए ऑप्स, क्वांटाइज़ेशन, कैश मेमोरी, और वज़न शेयर करना शामिल है. सोर्स: "Large Language Models On-Device with MediaPipe and TensorFlow Lite".
- MediaPipe LLM inference API को इंस्टॉल और इंपोर्ट करें.
- मॉडल डाउनलोड करें. यहां हमने Gemma 2B का इस्तेमाल किया है. इसे Kaggle से डाउनलोड किया गया है. Gemma 2B, Google के ओपन-वेट मॉडल में सबसे छोटा है.
FilesetResolverका इस्तेमाल करके, कोड को सही मॉडल फ़ाइलों पर ले जाएं. यह इसलिए ज़रूरी है, क्योंकि जनरेटिव एआई मॉडल के पास अपनी ऐसेट के लिए एक खास डायरेक्ट्री स्ट्रक्चर हो सकता है.- MediaPipe के एलएलएम इंटरफ़ेस की मदद से, मॉडल को लोड और कॉन्फ़िगर करें. मॉडल को इस्तेमाल करने के लिए तैयार करें: मॉडल की जगह, जवाबों की पसंदीदा लंबाई, और तापमान के साथ क्रिएटिविटी का पसंदीदा लेवल तय करें.
- मॉडल को कोई प्रॉम्प्ट दें (उदाहरण देखें).
- मॉडल के जवाब का इंतज़ार करें.
- रेटिंग के लिए पार्स करना: मॉडल के जवाब से स्टार रेटिंग निकालना.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
प्रॉम्प्ट का उदाहरण
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
सीखने वाली अहम बातें
इसके लिए, एआई/एमएल के बारे में जानकारी होना ज़रूरी नहीं है. प्रॉम्प्ट डिज़ाइन करने के लिए, कई बार बदलाव करने पड़ते हैं. हालांकि, बाकी कोड स्टैंडर्ड वेब डेवलपमेंट होता है.
क्लाइंट-साइड मॉडल काफ़ी सटीक होते हैं. इस दस्तावेज़ में दिए गए स्निपेट चलाने पर, आपको पता चलेगा कि टॉक्सिसिटी और सेंटीमेंट एनालिसिस, दोनों के सटीक नतीजे मिलते हैं. ज़्यादातर मामलों में, Gemma की रेटिंग, Gemini मॉडल की रेटिंग से मेल खाती हैं. ऐसा, कुछ रेफ़रंस समीक्षाओं की जाँच करने पर पता चला. इसकी पुष्टि करने के लिए, हमें और टेस्टिंग करनी होगी.
हालांकि, Gemma 2B के लिए प्रॉम्प्ट डिज़ाइन करने में समय लगता है. Gemma 2B एक छोटा एलएलएम है. इसलिए, इससे बेहतर नतीजे पाने के लिए, आपको प्रॉम्प्ट में ज़्यादा जानकारी देनी होगी. यह जानकारी, Gemini API के लिए ज़रूरी जानकारी से ज़्यादा होनी चाहिए.
जवाब बहुत तेज़ी से मिल सकता है. इस दस्तावेज़ में दिए गए स्निपेट चलाने पर, आपको दिखेगा कि कई डिवाइसों पर अनुमान लगाने की प्रोसेस तेज़ हो सकती है. यह प्रोसेस, सर्वर राउंड ट्रिप की तुलना में ज़्यादा तेज़ हो सकती है. हालांकि, अनुमान लगाने की स्पीड में काफ़ी अंतर हो सकता है. टारगेट किए गए डिवाइसों पर, पूरी तरह से बेंचमार्किंग करना ज़रूरी है. हमें उम्मीद है कि WebGPU, WebAssembly, और लाइब्रेरी के अपडेट की मदद से, ब्राउज़र के अनुमान लगाने की प्रोसेस और तेज़ होती रहेगी. उदाहरण के लिए, Transformers.js ने v3 में WebGPU के साथ काम करने की सुविधा जोड़ी है. इससे डिवाइस पर अनुमान लगाने की प्रोसेस को कई गुना तेज़ किया जा सकता है.
डाउनलोड किए जाने वाले आइटम का साइज़ बहुत ज़्यादा हो सकता है. ब्राउज़र में अनुमान लगाने की प्रोसेस तेज़ होती है, लेकिन एआई मॉडल लोड करना मुश्किल हो सकता है. ब्राउज़र में एआई का इस्तेमाल करने के लिए, आम तौर पर आपको लाइब्रेरी और मॉडल, दोनों की ज़रूरत होती है. इससे आपके वेब ऐप्लिकेशन का डाउनलोड साइज़ बढ़ जाता है.
Tensorflow टॉक्सिसिटी मॉडल (नैचुरल लैंग्वेज प्रोसेसिंग का क्लासिक मॉडल) का साइज़ सिर्फ़ कुछ किलोबाइट है. वहीं, Transformers.js के डिफ़ॉल्ट सेंटीमेंट एनालिसिस मॉडल जैसे जनरेटिव एआई मॉडल का साइज़ 60 एमबी तक होता है. Gemma जैसे लार्ज लैंग्वेज मॉडल का साइज़ 1.3 जीबी तक हो सकता है. यह औसत 2.2 एमबी वेब पेज के साइज़ से ज़्यादा है. यह साइज़, बेहतर परफ़ॉर्मेंस के लिए सुझाए गए साइज़ से पहले ही बहुत ज़्यादा है. क्लाइंट-साइड जनरेटिव एआई, कुछ खास मामलों में इस्तेमाल किया जा सकता है.
वेब पर जनरेटिव एआई की टेक्नोलॉजी तेज़ी से बेहतर हो रही है! आने वाले समय में, वेब के लिए ऑप्टिमाइज़ किए गए छोटे मॉडल उपलब्ध हो सकते हैं.
अगले चरण
Chrome, ब्राउज़र में जनरेटिव एआई को चलाने के लिए, एक नए तरीके पर एक्सपेरिमेंट कर रहा है. इसे आज़माने के लिए, Early Preview Program के लिए साइन अप करें.